
Prefacio
Manual de usuario de ATLAS.ti
Copyright © por ATLAS.ti Scientific Software Development GmbH, Berlín. Todos los derechos reservados.
Versión del documento: 26.1.1+34607 (2026-07-13 17:07:51)
Copiar o duplicar este documento o cualquier parte del mismo constituye una infracción de la ley aplicable. Ninguna parte de este manual puede reproducirse ni transmitirse en forma alguna ni por ningún medio, ya sea electrónico o mecánico, incluida, entre otras, la fotocopia, sin el permiso escrito de ATLAS.ti GmbH.
Marcas comerciales: ATLAS.ti es una marca registrada de ATLAS.ti Scientific Software Development GmbH. Adobe Acrobat es una marca comercial de Adobe Systems Incorporated; Microsoft, Windows, Excel y otros productos de Microsoft mencionados en este documento son marcas comerciales de Microsoft Corporation en los Estados Unidos y/o en otros países. Google Earth es una marca comercial de Google, Inc. Todos los demás nombres de productos y las marcas comerciales registradas y no registradas mencionadas en este documento se utilizan únicamente con fines identificativos y siguen siendo propiedad exclusiva de sus respectivos propietarios.
Actualice siempre a las versiones más recientes de ATLAS.ti cuando se le notifique durante el inicio de la aplicación.
Acerca de este manual
Este manual describe los conceptos y las funciones de ATLAS.ti.
No es necesario leer el manual secuencialmente de principio a fin. Puede omitir las secciones que describen conceptos con los que ya está familiarizado, ir directamente a las secciones que describen funciones de su interés, o simplemente utilizarlo como guía de referencia para consultar información sobre determinadas funciones clave.
Para los usuarios que no tienen conocimiento previo de ATLAS.ti, se recomienda especialmente leer la primera parte de este manual para familiarizarse con los conceptos que utiliza ATLAS.ti y obtener una visión general de las funciones disponibles. Estos son los capítulos:
- El principio VISE
- ATLAS.ti - La mesa de trabajo del conocimiento, y
- Pasos principales para trabajar con ATLAS.ti.
Además, para configurar un proyecto, se recomienda leer:
- Pasos principales para trabajar con ATLAS.ti
- Iniciar ATLAS.ti
- La interfaz de ATLAS.ti
- Agregar documentos
- Gestión de proyectos
Para todo el trabajo básico, como crear citas, codificar y escribir memos, consulte los capítulos bajo el encabezado principal:
- Administradores de entidades
- Exploración de datos
- Trabajo con citas
- Codificación de datos
- Autocodificación de datos
- Trabajo con comentarios y memos
- Trabajo con grupos
Las funciones avanzadas se describen en:
La secuencia de los capítulos sigue los pasos necesarios para iniciar y trabajar en un proyecto de ATLAS.ti: en primer lugar, se explican los conceptos principales que utiliza ATLAS.ti; a continuación, se ofrece una visión general de todas las herramientas disponibles. Estas partes introductorias y de orientación más teórica son seguidas por capítulos de orientación más práctica que proporcionan instrucciones paso a paso. Aprenderá a gestionar sus datos y a configurar e iniciar un proyecto. Una vez configurado el proyecto, cobran relevancia las funciones básicas, como la codificación, la búsqueda de texto, la autocodificación, la escritura de memos, etc. Las funciones de nivel conceptual, como el editor de redes, la Herramienta de consulta y las herramientas de coocurrencia, se basan en el trabajo a nivel de datos (al menos en la mayoría de los casos) y, por tanto, se describen al final.
La sección Recursos útiles ofrece algunos consejos útiles sobre cómo obtener ayuda y dónde encontrar más información sobre el software.
Tutorial en vídeo: Novedades de ATLAS.ti 22
Cómo utilizar este manual
Este manual está destinado a:
- Quienes no tienen conocimiento previo de ATLAS.ti
- Quienes han trabajado con una versión anterior.
Se asume cierta familiaridad general con los conceptos y procedimientos relativos al sistema operativo Windows y a la informática en general (p. ej., archivos, carpetas, rutas).
Este es en gran medida un documento técnico. No debe esperar de este manual ninguna discusión detallada sobre los aspectos metodológicos de la investigación cualitativa, más allá de comentarios superficiales.
Recursos útiles para empezar
Para quienes buscan una instrucción detallada sobre los aspectos metodológicos, el Centro de Formación de ATLAS.ti ofrece una amplia oferta de eventos de formación dedicados a ATLAS.ti en todo el mundo, tanto a través de cursos en línea como de seminarios presenciales en casi todas las partes del mundo. Visite el Centro de Formación en https://training.atlasti.com.
Cuenta de ATLAS.ti y activación de licencia
Para más información sobre la Gestión de licencias multiusuario, consulte nuestra Guía para titulares de licencias y administradores.
Solicitar una versión de prueba
Haga clic en "Prueba ATLAS.ti gratis". Se le pedirá que inicie sesión en my.atlasti.com con una cuenta de ATLAS.ti existente, o puede crear una en pocos segundos y confirmar su dirección de correo electrónico.
Una vez que haya iniciado sesión, su licencia de prueba gratuita se activará automáticamente y aparecerá visible en su cuenta.
También puede seguir las instrucciones paso a paso aquí: https://atlasti.com/video-tutorials/atlas-ti-frequently-asked-questions#get-your-free-trial-of-atlas-ti
Si no desea descargar el software de inmediato, siempre puede hacerlo más tarde desde su cuenta de ATLAS.ti. Para ello, seleccione Mis aplicaciones.
La versión de prueba gratuita es válida durante un período de 20 días naturales después de solicitar la licencia de prueba. Durante estos 20 días, puede utilizar el software en su capacidad completa durante 5 (cinco) días completos. Estos 5 días no tienen que ser consecutivos, es decir, pueden espaciarse como se desee. Una vez que caduque la versión de prueba gratuita, el programa pasa a una versión restringida que aún permite ver proyectos de cualquier tamaño y crear y usar proyectos de tamaño limitado (10 documentos, 50 citas, 25 códigos, 2 memos).
Puede iniciar la compra de una licencia completa desde su cuenta de ATLAS.ti. Después de activar la licencia, el programa se puede volver a usar con toda su capacidad. También puede continuar trabajando en su proyecto sin pérdida de datos.
No puede volver a instalar una versión de prueba en el mismo ordenador.
Activar una licencia
Necesita realizar una conexión en línea al menos una vez para activar su licencia. Una vez que la cuenta está activada, puede trabajar sin conexión y no se requiere ninguna conexión en línea adicional. Tenga en cuenta que si utiliza un puesto que forma parte de una licencia multiusuario, bloqueará el puesto si está sin conexión.
Si ha adquirido una licencia individual en la tienda web de ATLAS.ti, su licencia se ha añadido a su cuenta. El siguiente paso es activarla.
Del mismo modo, si es miembro de un equipo de usuarios bajo una licencia multiusuario, habrá recibido una clave de licencia, un código de invitación o un enlace de invitación de la persona que gestiona la licencia.
El sistema de gestión de licencias de ATLAS.ti asigna los puestos de la licencia multiusuario de forma dinámica. Esto significa que se le asigna el primer puesto libre de su licencia. Si todos los puestos están ocupados, se le asignará el siguiente puesto que quede disponible.
Inicie sesión en su cuenta de ATLAS.ti.
Vaya a Gestión de licencias (la página predeterminada) e introduzca la clave de licencia o el código de invitación que le proporcionó el titular/gestor de la licencia.
Haga clic en Activar licencia.
Inicie ATLAS.ti en su ordenador y haga clic en Buscar licencia actualizada y siga las instrucciones en pantalla para completar algunos pasos sencillos de activación.
Su instalación está ahora activada y puede comenzar a usar ATLAS.ti.
Acceder a su cuenta desde ATLAS.ti
En la pantalla de inicio, haga clic en el avatar de usuario. Si aún no ha añadido una imagen, mostrará las dos primeras letras del nombre de su cuenta.
![]()
Haga clic en Administrar cuenta. Esto le llevará a la pantalla de inicio de sesión. Introduzca su información de acceso (correo electrónico y contraseña) para acceder a su cuenta.
Cerrar sesión
Es importante entender que la instalación de ATLAS.ti es independiente de la licencia del software. Puede tener ATLAS.ti instalado en tantos ordenadores como desee. Una licencia de usuario único le da derecho a usarlo en dos ordenadores, por ejemplo, su ordenador de escritorio en la oficina y su portátil en casa; o su ordenador Windows y su Mac; o la versión en la nube y una versión de escritorio. Si desea usar ATLAS.ti en un tercer ordenador, o si obtiene un ordenador nuevo, asegúrese de cerrar sesión en el ordenador que ya no vaya a utilizar. Si ha sido invitado a usar una licencia multiusuario, tendrá un puesto durante el tiempo que use ATLAS.ti.
Hay dos formas de cerrar sesión para liberar un puesto:
Haga clic en el avatar de usuario en la pantalla de bienvenida y haga clic en Cerrar sesión.
Si olvidó cerrar sesión en ATLAS.ti, siempre puede acceder a su cuenta de usuario a través de un navegador web:
Vaya a https://my.atlasti.com/. Introduzca su dirección de correo electrónico y contraseña para iniciar sesión.
Seleccione la opción Cerrar sesión en la parte inferior izquierda, encima de su avatar, en su cuenta de ATLAS.ti.
Trabajo sin conexión
Al iniciar ATLAS.ti, se comprueba si tiene una licencia válida. Si sabe que no tendrá acceso en línea durante un período determinado, puede configurar su licencia para trabajar sin conexión durante un período específico.
Si tiene una licencia que no caduca, el período máximo sin conexión es de cuatro meses. Si tiene una licencia de arrendamiento, el período máximo depende de la fecha de caducidad de su arrendamiento. Esto significa que si su licencia caduca en 1 mes, no puede establecer el período sin conexión en 3 meses adicionales.
Una vez transcurrido el período, deberá conectarse de nuevo a Internet para verificar su licencia.
Versión limitada tras la caducidad de la licencia
Una vez que caduca el período de prueba o una licencia de tiempo limitado, el programa se convierte en una versión limitada. Puede abrir, leer y revisar proyectos, pero solo puede guardar proyectos que no superen un determinado límite (véase a continuación). Por tanto, aún puede usar ATLAS.ti como versión de solo lectura.
No puede volver a instalar una versión de prueba en el mismo ordenador.
Restricciones de la versión limitada
- 10 documentos primarios
- 50 citas
- 25 códigos
- 2 memos
- 2 vistas de red
- la copia de seguridad automática está deshabilitada
Introducción
ATLAS.ti es una potente mesa de trabajo para el análisis cualitativo de grandes volúmenes de datos textuales, gráficos, de audio y de vídeo. Ofrece una variedad de herramientas para llevar a cabo las tareas asociadas a cualquier enfoque sistemático de los datos no estructurados, es decir, datos que no pueden analizarse de manera significativa mediante enfoques formales y estadísticos. En el curso de dicho análisis cualitativo, ATLAS.ti le ayuda a explorar los fenómenos complejos ocultos en sus datos. Para hacer frente a la complejidad inherente de las tareas y los datos, ATLAS.ti ofrece un entorno potente e intuitivo que le mantiene centrado en los materiales analizados. Ofrece herramientas para gestionar, extraer, comparar, explorar y reensamblar fragmentos significativos de grandes cantidades de datos de formas creativas, flexibles y sistemáticas.
Tutorial en vídeo: Descripción general de ATLAS.ti 22 para Mac.
El principio VISE
Los principios fundamentales de la filosofía de ATLAS.ti se resumen mejor en el acrónimo VISE, que corresponde a:
- Visualización (Visualization)
- Inmersión (Immersion)
- Serendipia (Serendipity)
- Exploración (Exploration)
Visualización
El componente de visualización del programa apoya directamente la forma en que los seres humanos piensan, planifican y abordan soluciones de manera creativa y sistemática.
Se dispone de herramientas para visualizar las propiedades y relaciones complejas entre las entidades acumuladas durante el proceso de extracción de significado y estructura de los datos analizados.
El proceso está diseñado para mantener las operaciones necesarias cerca de los datos a los que se aplican. El enfoque visual de la interfaz le mantiene centrado en los datos, y con frecuencia las funciones que necesita están a tan solo unos clics de distancia.
Inmersión
Otro aspecto fundamental del diseño del software es ofrecer herramientas que le permitan sumergirse por completo en sus datos. No importa en qué parte del software se encuentre, siempre tiene acceso a los datos de origen. Leer y releer sus datos, verlos de diferentes maneras y anotar sus pensamientos e ideas mientras lo hace son aspectos importantes del proceso analítico. Y es a través de este compromiso con los datos que se desarrollan percepciones creativas.
Serendipia
El Diccionario Webster define la serendipia como un aparente don para hacer descubrimientos afortunados de forma accidental. Otros significados son: accidentes afortunados, descubrimientos casuales. En el contexto de los sistemas de información, cabría añadir: encontrar algo sin haberlo buscado activamente.
El término serendipia puede equipararse con un enfoque intuitivo de los datos. Una operación típica que se apoya en el efecto de la serendipia es la navegación exploratoria. Este método de búsqueda de información es una actividad genuinamente humana: cuando pasa un día en la biblioteca local (o en la World Wide Web), a menudo comienza buscando libros específicos (o palabras clave). Pero al cabo de un momento, generalmente se encuentra cada vez más involucrado en hojear libros que no eran exactamente lo que tenía en mente originalmente, pero que conducen a descubrimientos interesantes.
Algunos ejemplos de herramientas y procedimientos que ofrece ATLAS.ti para aprovechar el concepto de serendipia son las herramientas de búsqueda y codificación, las nubes de palabras y las listas de palabras, el Lector de citas, el área de margen interactivo o la funcionalidad de hipertexto.
Exploración
La exploración está estrechamente relacionada con los principios anteriores. A través de un enfoque exploratorio pero sistemático de sus datos (en contraposición a un mero manejo burocrático), se asume que especialmente las actividades constructivas como la construcción de teorías se beneficiarán enormemente. El concepto general del programa, incluido el proceso de familiarizarse con sus particularidades, es especialmente propicio para un enfoque exploratorio y orientado al descubrimiento.
Áreas de aplicación
ATLAS.ti sirve como una potente utilidad para el análisis cualitativo de datos textuales, gráficos, de audio y de vídeo. El contenido de estos materiales no está limitado en modo alguno a ningún campo específico de la investigación científica o académica.
Su énfasis está en el análisis cualitativo, más que cuantitativo, es decir, en la determinación de los elementos que componen el material de datos primario y la interpretación de su significado. Un término relacionado sería "gestión del conocimiento", que enfatiza la transformación de datos en conocimiento útil.
ATLAS.ti puede ser de gran ayuda en cualquier campo donde se lleve a cabo este tipo de análisis de datos blandos. Si bien ATLAS.ti fue diseñado originalmente pensando en el científico social, actualmente se utiliza en áreas que no se habían anticipado realmente. Dichas áreas incluyen la psicología, la literatura, la medicina, la ingeniería de software, la investigación de experiencia de usuario, el control de calidad, la criminología, la administración, la lingüística textual, la estilística, la elicitación del conocimiento, la historia, la geografía, la teología y el derecho, por mencionar solo algunas de las más destacadas.
Cada día surgen nuevos campos que también pueden aprovechar plenamente las capacidades del programa para trabajar con datos gráficos, de audio y de vídeo. Algunos ejemplos:
- Antropología: microgestos, mímica, mapas, ubicaciones geográficas, observaciones, notas de campo
- Arquitectura: planos anotados
- Arte / Historia del arte: descripciones interpretativas detalladas de pinturas o explicaciones educativas de estilos
- Administración de empresas: análisis de entrevistas, informes, páginas web
- Criminología: análisis de cartas, huellas dactilares, fotografías, datos de vigilancia
- Geografía y geografía cultural: análisis de mapas, ubicaciones
- Grafología: microcomentarios sobre características de la escritura
- Aseguramiento de calidad industrial: análisis de interacciones usuario-sistema grabadas en vídeo
- Medicina y práctica sanitaria: análisis de imágenes de rayos X, tomografías computarizadas, muestras de microscopio, datos de vídeo de atención al paciente, formación del personal sanitario mediante datos de vídeo
- Estudios de medios de comunicación: análisis de películas, programas de televisión, comunidades en línea
- Turismo: mapas, ubicaciones, reseñas de visitantes
Son una realidad muchas más aplicaciones de una amplia variedad de campos académicos y profesionales. El objetivo fundamental de diseño al crear ATLAS.ti fue desarrollar una herramienta que apoye eficazmente al intérprete humano, especialmente en el manejo de cantidades relativamente grandes de material de investigación, notas y teorías asociadas.
Aunque ATLAS.ti facilita muchas de las actividades implicadas en el análisis e interpretación de datos cualitativos (en particular, la selección, el etiquetado de datos y la anotación), su propósito no es automatizar completamente estos procesos. La interpretación automática de textos no puede captar la complejidad, la falta de explicitud o la contextualidad del conocimiento científico o cotidiano. De hecho, ATLAS.ti fue diseñado para ser más que una sola herramienta; piense en él como una mesa de trabajo profesional que ofrece una amplia selección de herramientas eficaces para una variedad de problemas y tareas.
ATLAS.ti - La mesa de trabajo del conocimiento
La imagen de ATLAS.ti como una mesa de trabajo del conocimiento es más que una simple analogía vívida. El trabajo analítico implica elementos tangibles: el material de investigación requiere trabajo detallado, ensamblaje, reelaboración, diseños complejos y algunas herramientas especiales. Una mesa de trabajo bien equipada le proporciona los instrumentos necesarios para analizar y evaluar a fondo, buscar y consultar sus datos, y para capturar, visualizar y compartir sus hallazgos.
Algunos términos básicos
Para entender cómo ATLAS.ti maneja los datos, visualice su proyecto completo como un contenedor inteligente que realiza un seguimiento de todos sus datos. Este contenedor es su proyecto de ATLAS.ti.
El proyecto realiza un seguimiento de las rutas a sus datos de origen y almacena los códigos, grupos de códigos, redes, etc. que desarrolla durante su trabajo. Sus archivos de datos de origen se copian y almacenan en un repositorio. La opción estándar es que ATLAS.ti gestione los documentos por usted en su base de datos interna. Si trabaja con archivos de audio o vídeo de mayor tamaño, pueden vincularse a su proyecto para preservar el espacio en disco. Todos los archivos que asigne al proyecto (excepto los vinculados externamente) se copian, es decir, se realiza un duplicado para uso exclusivo de ATLAS.ti. Sus archivos originales permanecen intactos y sin modificaciones en su ubicación original.
El proyecto reside en su ordenador, para garantizar tanto la privacidad de los datos como la disponibilidad sin conexión. Además, puede subir sus proyectos a la nube de proyectos de ATLAS.ti directamente desde ATLAS.ti, para compartirlos con colegas, acceder a ellos desde varios ordenadores o simplemente como copia de seguridad. Consulte Nube de proyectos para más detalles.
Sus datos de origen pueden consistir en documentos de texto (como transcripciones de entrevistas o grupos focales, informes, notas de observación); imágenes (fotos, capturas de pantalla, diagramas), grabaciones de audio (entrevistas, transmisiones, música), clips de vídeo (material audiovisual), archivos PDF (artículos, folletos, informes, artículos o capítulos de libros para una revisión bibliográfica), datos geográficos (datos de localización mediante Open Street Map) y comentarios de redes sociales.
Una vez que sus distintos documentos se han agregado o vinculado a un proyecto de ATLAS.ti, puede comenzar su trabajo real. Por lo general, las primeras etapas del proyecto implican la codificación de diferentes fuentes de datos.
Seleccionar segmentos de interés en sus datos y codificarlos es la actividad básica al utilizar ATLAS.ti, y es la base de todo lo demás que hará. En términos prácticos, la codificación se refiere al proceso de asignar códigos a segmentos de información que son de interés para sus objetivos de investigación. Hemos modelado esta función para que corresponda con la práctica tradicional de marcar (subrayar o resaltar) y anotar pasajes de texto en un libro u otros documentos.
En sus fundamentos conceptuales centrales, ATLAS.ti se ha basado deliberadamente en lo que podría denominarse el paradigma del papel y el lápiz. La interfaz de usuario está diseñada en consecuencia, y muchos de sus procesos se basan en —y, por tanto, se pueden entender mejor mediante— esta analogía.
Gracias a este principio de diseño altamente intuitivo, pronto apreciará el área de margen como uno de sus espacios de trabajo más centrales y preferidos, aunque ATLAS.ti casi siempre ofrece una variedad de formas para realizar cualquier tarea.
Pasos generales al trabajar con ATLAS.ti
La siguiente secuencia de pasos no es, por supuesto, obligatoria, pero describe un flujo de trabajo habitual:
-
Cree un proyecto, un contenedor de ideas destinado a reunir sus datos, todos sus hallazgos, códigos, memos y estructuras bajo un único nombre. Consulte Crear un nuevo proyecto.
-
A continuación, agregue documentos, archivos de texto, gráficos, audio y vídeo, o documentos geográficos a su proyecto de ATLAS.ti. Consulte Agregar documentos.
-
Organice sus documentos. Consulte Trabajo con grupos.
-
Lea y seleccione pasajes de texto o identifique áreas en una imagen o seleccione segmentos en la línea de tiempo de un archivo de audio o vídeo que sean de interés, asigne palabras clave (códigos) y escriba comentarios y memos que reflejen su reflexión sobre los datos. Construya un sistema de codificación. Consulte Trabajo con comentarios y memos y Codificación de datos - Conceptos básicos.
-
Compare segmentos de datos en función de los códigos que ha asignado; si es necesario, agregue más archivos de datos al proyecto. Consulte, por ejemplo, Recuperación de datos codificados.
-
Consulte los datos en función de sus preguntas de investigación utilizando las diferentes herramientas que ofrece ATLAS.ti. Las palabras clave a tener en cuenta son: recuperación simple, recuperaciones de códigos complejas mediante la Herramienta de consulta, recuperaciones simples o complejas en combinación con variables a través del botón de ámbito, aplicación de filtros globales, las herramientas de coocurrencia de códigos (explorador de árbol y tabla), la tabla de código-documento y la exportación de datos para análisis estadístico adicional. Consulte Análisis de datos y Exportación de datos para análisis estadístico adicional.
-
Conceptualice sus datos más a fondo construyendo redes a partir de los códigos y otras entidades que haya creado. Estas redes, junto con sus códigos y memos, forman el marco para la teoría emergente. Consulte Trabajo con redes.
-
Finalmente, elabore un informe escrito basado en los memos que ha escrito a lo largo de las diversas fases de su proyecto y en las redes que ha creado. Consulte Trabajo con comentarios y memos y Exportación de redes.
Para lectura adicional sobre el trabajo con ATLAS.ti, consulte El blog de investigación de ATLAS.ti y Las actas de la conferencia de ATLAS.ti.
Conceptos principales y características
Debe estar familiarizado con los conceptos de documentos, citas, códigos y memos como base general al trabajar con ATLAS.ti, complementados por una variedad de aspectos especiales como grupos, redes y las herramientas analíticas.
Todo lo que sea relevante para su análisis formará parte de su proyecto de ATLAS.ti en el dominio digital. Por ejemplo, los datos que está analizando, las citas como su unidad de análisis, los códigos, los vínculos conceptuales, los comentarios y los memos, todos forman parte de él. Una ventaja obvia de este concepto de contenedor es que el usuario solo tiene que tratar y pensar en una sola entidad. Activar el proyecto de ATLAS.ti es la simple selección de un único archivo; todo el material asociado se activa automáticamente.
El nivel más básico de un proyecto de ATLAS.ti consiste en los documentos que está analizando, seguidos de cerca por las citas (= selecciones de esos documentos). En el siguiente nivel, los códigos hacen referencia a las citas. Y los comentarios y memos están presentes en todas partes. Su proyecto de ATLAS.ti puede convertirse en una entidad altamente conectada, una densa red de datos primarios, memos y códigos asociados, e interrelaciones entre los códigos y los datos. Para encontrar su camino a través de esta red, ATLAS.ti proporciona potentes herramientas de navegación, recuperación y edición.
Puede acceder a información sobre cada una de estas herramientas mediante los enlaces que aparecen a continuación:
Documentos y grupos de documentos
Tutorial en vídeo: Organización de los datos del proyecto – Creación de grupos de documentos
Los documentos representan los datos que ha añadido a un proyecto de ATLAS.ti. Pueden ser materiales de texto, imagen, audio, vídeo o geográficos que desee analizar. El trabajo con datos de texto incluye la importación de datos de encuestas, la importación de datos desde un gestor de referencias para una revisión bibliográfica, el uso de datos de entrevistas o grupos de discusión, informes en formato de texto o PDF, notas de observación, etc. Para más información, consulte Formatos de archivo admitidos.
Los grupos de documentos cumplen una función especial, ya que pueden considerarse como variables cuasi dicotómicas. Es posible agrupar a todas las entrevistadas en un grupo de documentos denominado «género::femenino», a todos los entrevistados en un grupo denominado «género::masculino». Lo mismo puede hacerse para diferentes profesiones, estado civil, niveles de educación, etc. Consulte Trabajo con grupos para más información.
Los grupos de documentos pueden utilizarse posteriormente en el análisis para restringir las búsquedas basadas en códigos, como: «Muéstrame todos los segmentos de datos codificados con "actitud hacia el medio ambiente", pero solo para las mujeres que viven en Londres en comparación con las mujeres que viven en el campo».
También puede utilizar los grupos de documentos como filtro, por ejemplo para reducir otros tipos de salida, como un recuento de frecuencias de códigos en un grupo concreto de documentos.
Esto se explica con más detalle en la sección Tabla código-documento.
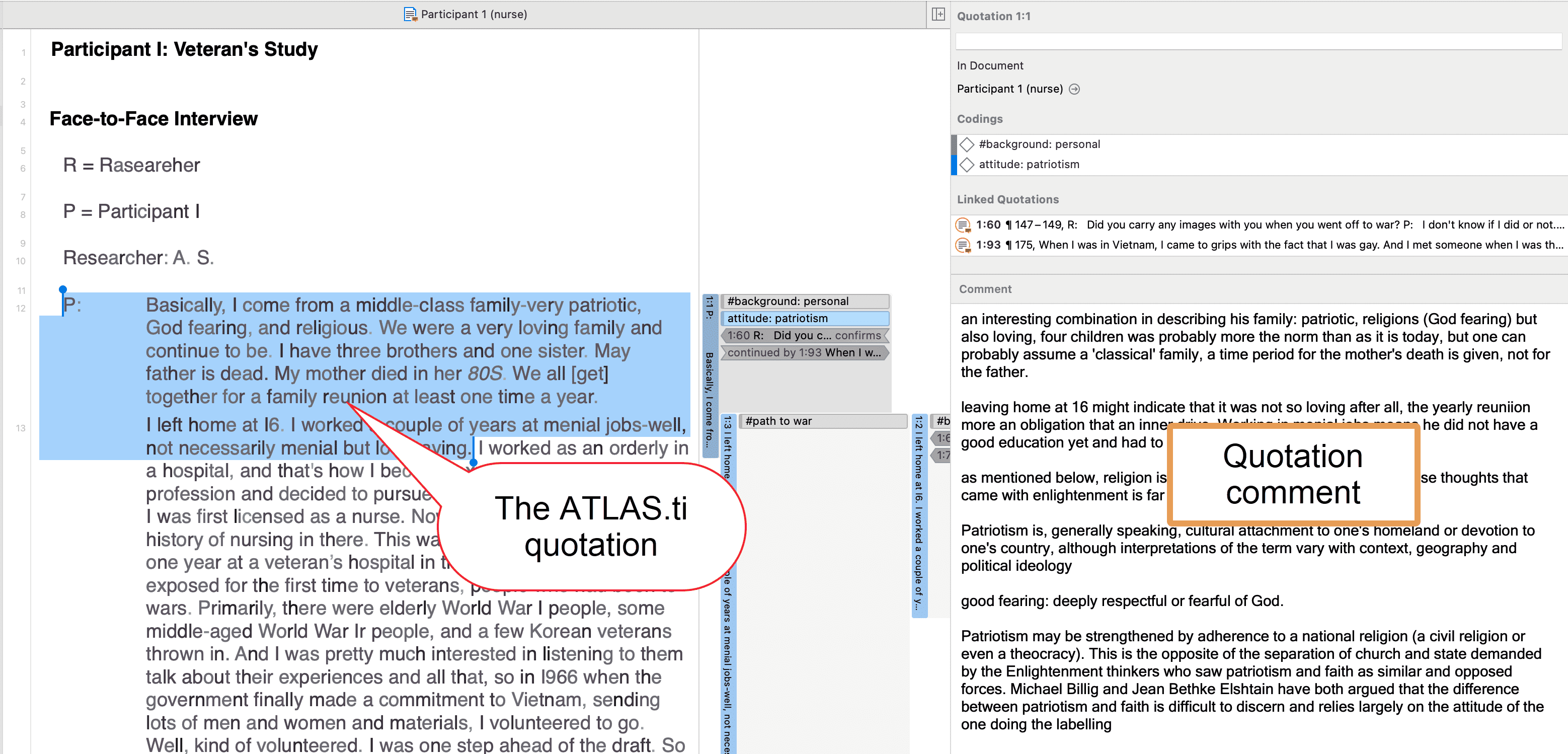
Citas
Tutorial en vídeo: Trabajo con citas
Una cita es un segmento de un documento que se considera interesante o importante.
Normalmente, las citas son creadas manualmente por el investigador. Sin embargo, para palabras, frases o información estructural repetitivas, como las unidades de interlocutor, se pueden utilizar las herramientas de Buscar y codificar. Con cualquiera de estas herramientas es posible segmentar los datos automáticamente y asignarles un código.
Aunque la creación de citas forma parte casi siempre de una tarea más amplia, como la codificación o la escritura de memos, las citas también pueden crearse sin codificar. Se denominan citas «libres».
Si, por ejemplo, utiliza el análisis del discurso o un enfoque interpretativo del análisis, o si trabaja con datos de vídeo, las citas libres pueden ser su punto de partida para el análisis, en lugar de codificar los datos de inmediato. Consulte Trabajo con citas y El nivel de citas de ATLAS.ti.
Códigos
El término código se utiliza de muchas formas. En primer lugar, nos gustaría definir qué significa ese término en la investigación cualitativa y, a continuación, en ATLAS.ti.
Codificar significa que adjuntamos etiquetas a segmentos de datos que describen de qué trata cada segmento. Mediante la codificación, planteamos preguntas analíticas sobre nuestros datos desde [...]. La codificación destila los datos, los organiza y nos proporciona un manejo analítico para hacer comparaciones con otros segmentos de datos.
Charmaz (2014:4)
La codificación es la estrategia que mueve los datos desde un texto difuso y desordenado hacia ideas organizadas sobre lo que está ocurriendo.
(Richards y Morse, 2013:167)
Desde una perspectiva metodológica
-
Los códigos capturan el significado de los datos.
-
Los códigos sirven como manejadores de ocurrencias específicas en los datos que no pueden encontrarse mediante técnicas simples de búsqueda de texto.
-
Los códigos se utilizan como dispositivos de clasificación en diferentes niveles de abstracción para crear conjuntos de unidades de información relacionadas con el fin de realizar comparaciones.
La longitud de un código debe ser limitada y no demasiado extensa. Si lo que desea son anotaciones textuales, debería utilizar en su lugar comentarios de citas.
Mantenga los nombres de los códigos breves y concisos. Utilice el panel de comentarios para elaboraciones más extensas.
Desde una perspectiva técnica
Los códigos son fragmentos cortos de texto que hacen referencia a otros fragmentos de texto, datos gráficos, de audio o de vídeo. Su finalidad es clasificar unidades de datos.
En el ámbito de los sistemas de recuperación de información, los términos «etiqueta», «palabra clave» o «etiquetado» se utilizan a menudo en lugar de «código» o «codificación».
Puede encontrar más información en las secciones Codificación de datos y Trabajo con códigos.
Referencias
Charmaz, Kathy (2014). Constructing Grounded Theory: A Practical Guide Through Qualitative Analysis. London: Sage.
Richards, Lyn and Janice M. Morse (2013, 3ed). Readme first: for a user's guide to Qualitative Methods. Los Angeles: Sage.
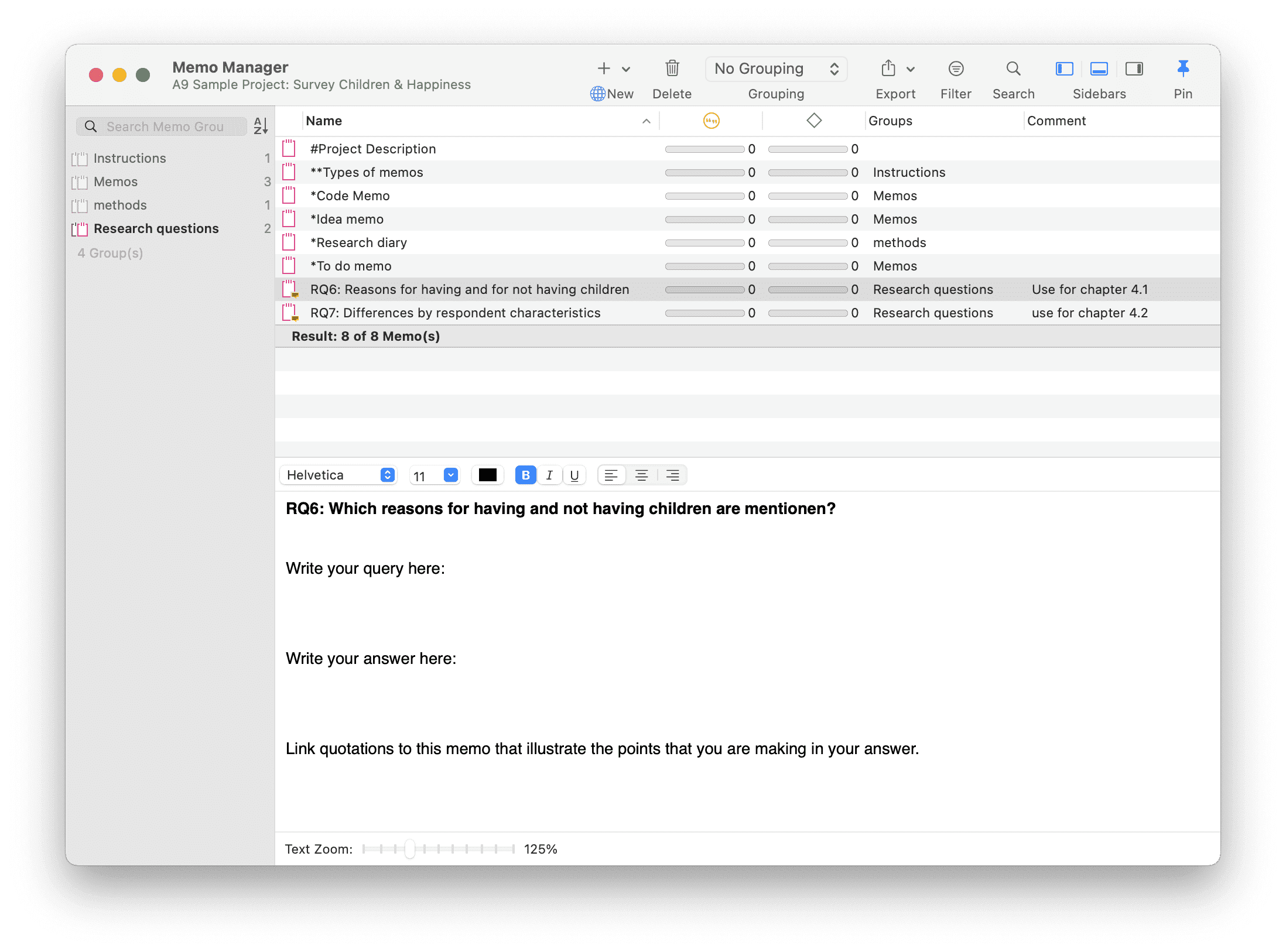
Memos
Tutorial en vídeo: Uso de memos en las primeras etapas de un proyecto
La escritura es una parte importante del análisis en la investigación cualitativa. Al utilizar software, es fácil caer en la trampa de los códigos. Recuerde siempre que codificar los datos es solo un medio para un fin: pensar, recuperar y consultar los datos (Corbin y Strauss, 2015; Richards, 2009; Richards y Morse, 2013).
Los memos son algo más que una nota garabateada en el margen:
Los memos [...] son documentos de trabajo y en constante evolución. Cuando un analista se sienta a escribir un memo o hacer un diagrama, se produce un cierto grado de análisis. El propio acto de escribir memos y hacer diagramas obliga al analista a reflexionar sobre los datos. Y es en esa reflexión donde ocurre el análisis (Corbin y Strauss, 2008: 118).
Escribir es pensar. Es natural creer que primero es necesario tener claro en la mente lo que se intenta expresar antes de poder escribirlo. Sin embargo, la mayor parte del tiempo ocurre lo contrario. Puede creer que tiene una idea clara, pero solo cuando la escribe puede estar seguro de que así es (o, lamentablemente, a veces de que no lo es) (Gibbs, 2005).
Los memos representan así el trabajo analítico en curso, y más adelante pueden utilizarse como elementos constitutivos del informe de investigación (véase Friese, 2019). Probablemente no es casualidad que Juliet Corbin dedique un amplio espacio a la escritura de memos en la tercera edición de Basics of Qualitative Research; su intención es mostrar a los lectores cómo puede hacerse. En una conferencia en el congreso CAQD 2008 sobre el libro, vinculó la escasa calidad de muchos proyectos de investigación cualitativa actuales a la falta de uso de memos. En la misma línea, Birks et al. (2008) dedica un artículo de revista completo a la escritura de memos, criticando la exploración limitada de su valor en la mayoría de las metodologías cualitativas.
Freeman (2017) señala que uno de los desafíos que enfrentan los investigadores noveles es comprender que la escritura es inseparable del análisis. Nos gustaría animarle a hacerlo: escriba mucho ya mientras codifica y más adelante cuando consulte los datos. Si lo hace, descubrirá por qué es útil; pero hay que hacerlo. Como señaló Freeman: El reto para los investigadores noveles es: «Necesitar hacer análisis para entender el análisis» (2017:3).
Si necesita más información sobre cómo escribir memos, consulte, por ejemplo, la tercera edición de Basics of Qualitative Research de Corbin y Strauss (2008/2014), Wolcott (2009), Charmaz (2014) o Friese (2019).
En términos técnicos,
-
Un memo en ATLAS.ti puede ser independiente, o puede estar vinculado a citas, códigos y otros memos.
-
Los memos pueden ordenarse por tipo (metodológico, teórico, descriptivo, etc.), lo que resulta útil para organizarlos y clasificarlos, o mediante la creación de grupos de memos.
-
Los memos también pueden incluirse en el análisis como datos secundarios convirtiéndolos en un documento. Entonces también pueden codificarse.
Para más información, consulte Trabajo con comentarios y memos.
Referencias
Birks, Melanie; Chapman, Ysanne and Francis, Karin (2008). Memoing in qualitative research: probing data and processes, Journal of Research in Nursing, 13, 68–75.
Charmaz, Kathy (2014). Constructing Grounded Theory: A Practical Guide Through Qualitative Analysis. London: Sage.
Corbin, Juliet and Strauss, Anselm (2008/2015). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory (3rd and 4th ed.). Thousand Oaks, CA: Sage.
Freeman, Melissa (2017). Modes of Thinking for Qualitative Data Analysis. NY: Routledge.
Friese, Susanne (2019). Qualitative Data Analysis with ATLAS.ti (3. ed.), London: Sage.
Gibbs, Graham (2005). Writing as analysis. Online QDA.
Richards, Lyn and Morse, Janice M. (2013). Readme First for a User's Guide to Qualitative Methods.
Richards, Lyn (2009). Handling qualitative data: a practical guide (2. ed), London: Sage.
Wolcott, Harry E. (2009). Writing Up Qualitative Research. London: Sage.
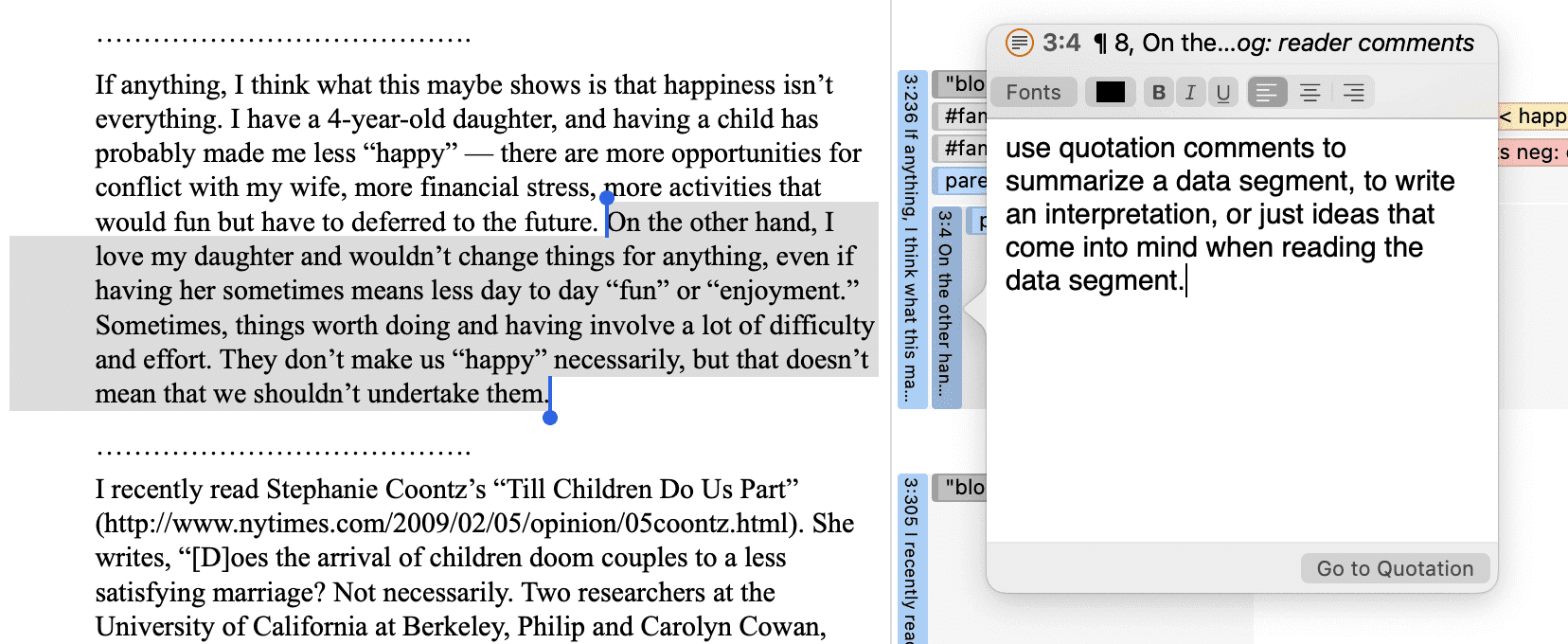
Comentarios
Es posible escribir comentarios para todas las entidades en ATLAS.ti. Los comentarios, a diferencia de los memos, están siempre directamente vinculados a la entidad para la que se escriben. Los memos son entidades independientes que tienen un nombre y un tipo. Los memos pueden agruparse y también pueden tener sus propios comentarios.
Escribir comentarios es similar a garabatear notas en el margen de un papel o pegar notas adhesivas en los objetos. Los comentarios pueden escribirse para documentos, citas, códigos, memos, redes, todo tipo de grupos y para relaciones.
Consulte Trabajo con memos y comentarios para más información.
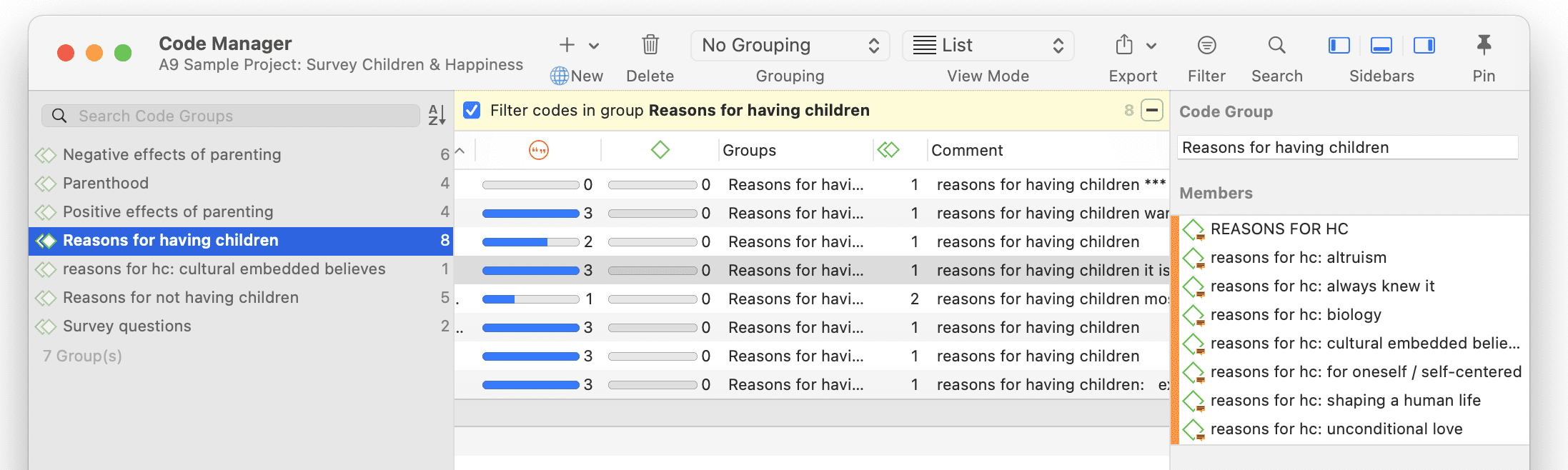
Grupos
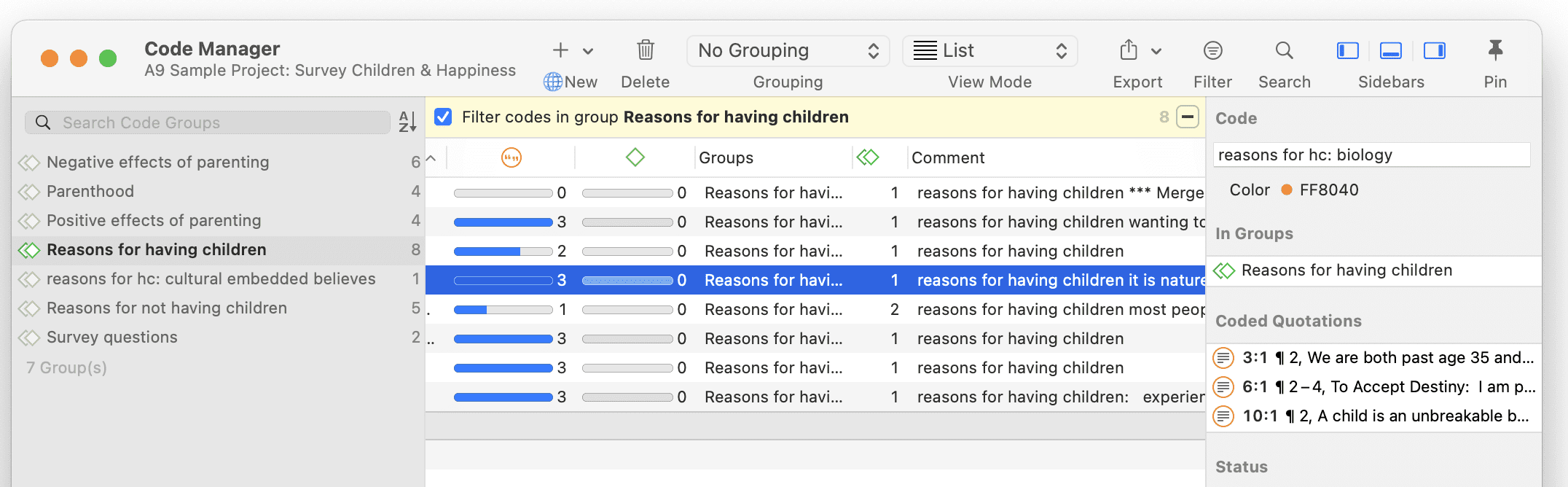
Los grupos en ATLAS.ti son dispositivos de filtro.
Los grupos de documentos pueden considerarse como atributos o variables. Es posible combinarlos mediante operadores lógicos como AND y OR; por ejemplo, para recuperar y analizar datos de encuestadas que viven en Nueva York. Esta sería una combinación AND de dos grupos de documentos.
Los grupos de códigos sirven como filtro para los códigos. Pueden utilizarse, por ejemplo, para filtrar todos los códigos que deben agregarse si se ha codificado de forma muy detallada y en el proceso se han generado demasiados códigos.
Los grupos de códigos no son un tipo de código de orden superior. NO se recomienda utilizarlos como categorías. Para más información, consulte Construcción de un sistema de códigos.
Para más información sobre los grupos, consulte Trabajo con grupos.
Redes
Las redes le permiten conceptualizar sus datos conectando conjuntos de elementos relacionados en un diagrama visual. Con la ayuda de las redes puede expresar relaciones entre códigos y citas; y puede vincular otras entidades como memos, documentos y grupos. Las propias redes también pueden ser "nodos" dentro de una red.
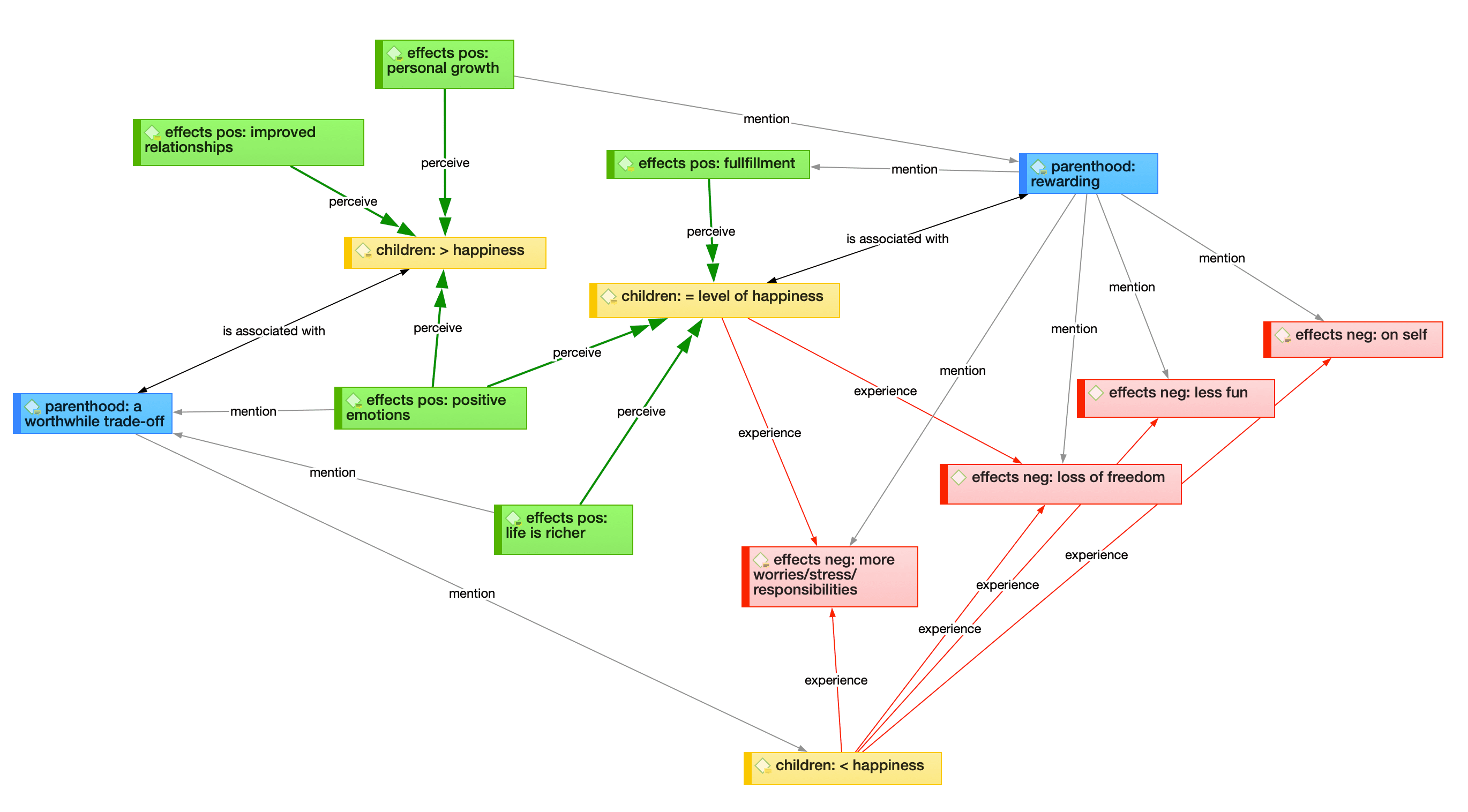
Nodos, vínculos y relaciones
Un nodo es cualquier entidad que se muestra en una red. Puede cambiar su aspecto y moverlos dentro del editor de redes.
Un vínculo es una línea que le permite conectar dos entidades.
Las relaciones le permiten nombrar los vínculos entre dos códigos o entre dos citas.
Administrador de redes
El Administrador de redes contiene una lista de todas las redes guardadas que ha creado. Puede usarse para acceder a una red, eliminar redes existentes o escribir y editar comentarios. Consulte Administrador de redes.
Organización de redes en carpetas
Las redes pueden organizarse en carpetas. Las carpetas pueden estar dentro de otras carpetas. Puede haber proyectos que requieran diferentes niveles de organización de redes. A continuación se muestra un ejemplo con tres niveles.
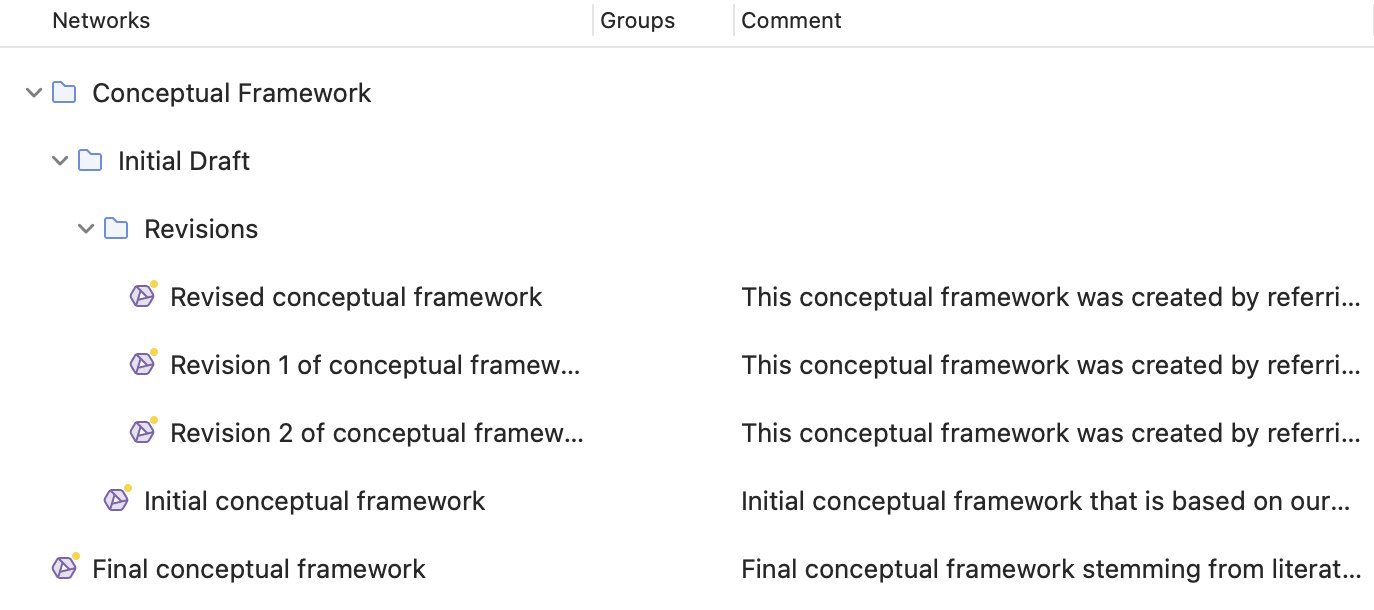
A diferencia de los grupos, una red no puede estar en más de una carpeta. La estructura de carpetas es jerárquica; los grupos no.
Cómo crear carpetas
En la cinta de opciones del Administrador de redes, haga clic en Nuevo y seleccione Carpeta.
O:
Seleccione una o más redes, haga clic derecho y seleccione la opción Nueva carpeta desde la selección del menú contextual.
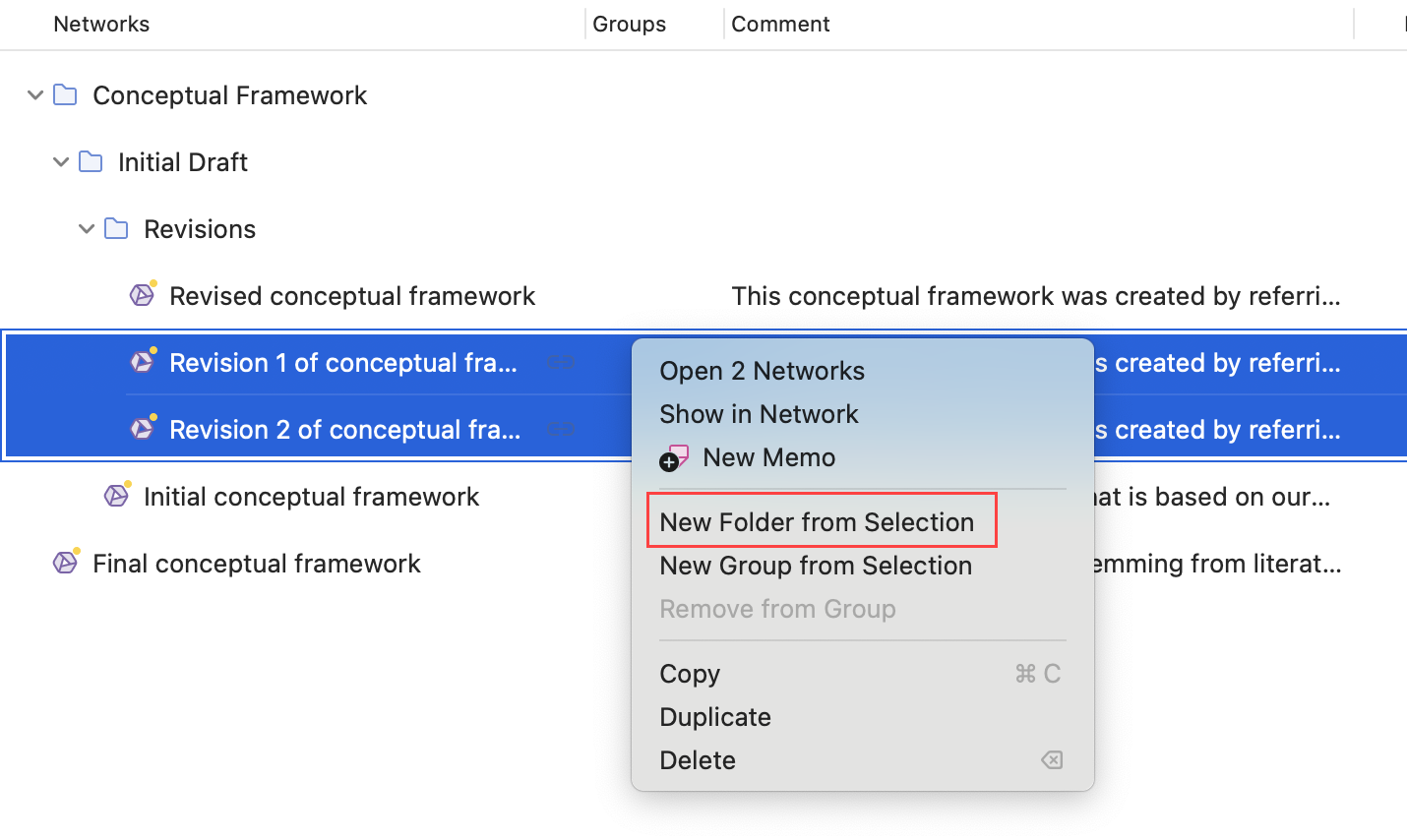
Si elimina una carpeta, todo el contenido de la carpeta también se elimina.
Editor de redes
El editor de redes muestra y ofrece todas las capacidades de edición para construir y perfeccionar redes. Además, permite la creación visual y la navegación de estructuras de hipertexto.
Administrador de vínculos
El Administrador de vínculos ofrece una vista general de todos los vínculos código-código y de todos los hipervínculos que ha creado. Consulte Administrador de vínculos.
Administrador de relaciones
El Administrador de relaciones le permite modificar relaciones existentes o crear nuevas relaciones. Consulte Crear nuevas relaciones.
Para más información sobre la función de redes, consulte Trabajar con redes.
Herramientas para explorar datos de texto
Tutorial en vídeo: Memos al inicio del proyecto ATLAS.ti 22 Mac
ATLAS.ti ofrece una serie de herramientas para explorar los datos de texto:
- Nubes de palabras y listas de palabras para documentos, citas y códigos. Consulte Creación de listas y nubes de palabras.
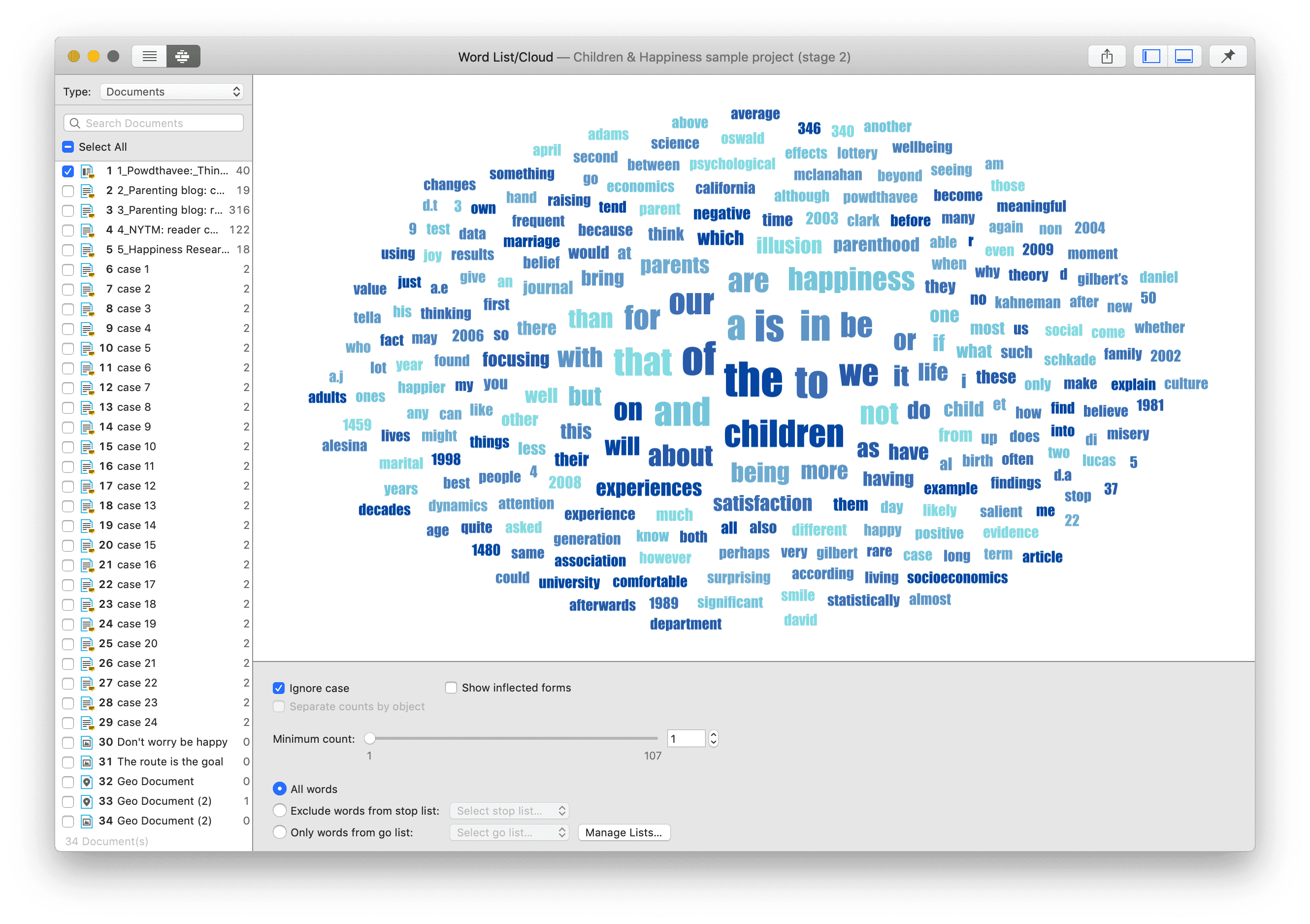
- las Herramientas de Buscar y codificar. Estas herramientas ofrecen una combinación de búsqueda de texto y autocodificación:
- Búsqueda de texto: busca palabras, fragmentos de palabras e incluso sinónimos. También son posibles combinaciones lógicas mediante los operadores AND y OR. Consulte Búsqueda de texto.
- Búsqueda experta: la búsqueda experta permite realizar búsquedas avanzadas mediante expresiones regulares (RegEx). Con RegEx es posible utilizar la coincidencia de patrones para buscar cadenas de caracteres específicas en lugar de construir múltiples consultas literales. Consulte Búsqueda experta.
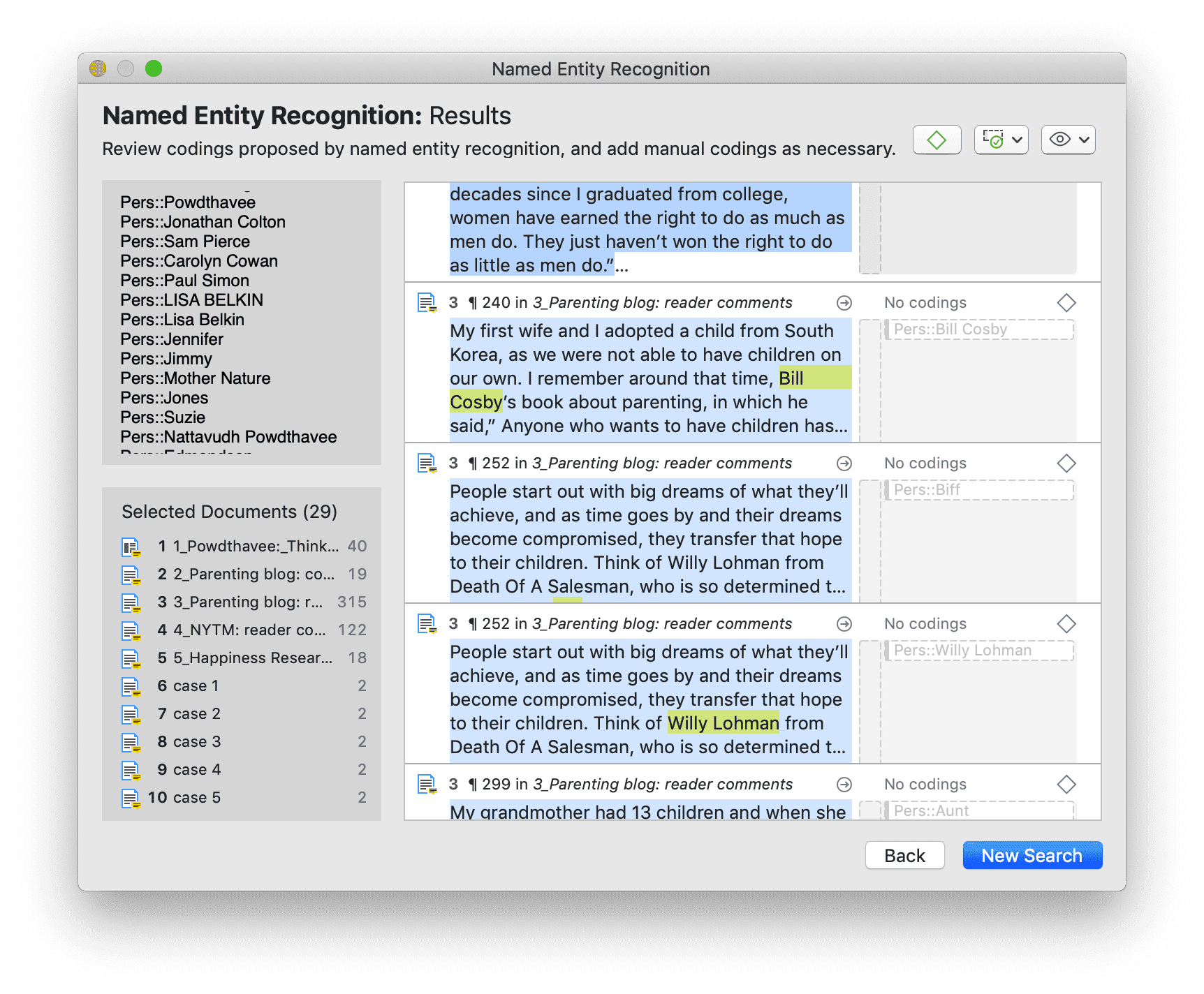
- Reconocimiento de entidades nombradas (NER): busca y clasifica entidades nombradas en el texto en categorías predefinidas como personas, organizaciones, ubicaciones u otras. Es posible revisar todos los resultados y codificarlos con las categorías sugeridas. Consulte Reconocimiento de entidades nombradas.
- Análisis de sentimientos: es la interpretación y clasificación de enunciados positivos, negativos y neutros en datos de texto mediante técnicas de análisis textual. Los modelos de análisis de sentimientos detectan la polaridad dentro de un texto (por ejemplo, una opinión positiva o negativa) en el documento completo, párrafo, oración o cláusula. Tiene múltiples aplicaciones. Por ejemplo, puede utilizarse para el análisis de la satisfacción del cliente o para todo tipo de evaluaciones, como también la evaluación de cursos por parte del alumnado. Consulte Análisis de sentimientos.
Análisis
Tutorial en vídeo: Herramientas de co-ocurrencia de códigos y análisis
ATLAS.ti contiene múltiples herramientas analíticas especializadas y de gran potencia para ayudar a interpretar los datos.
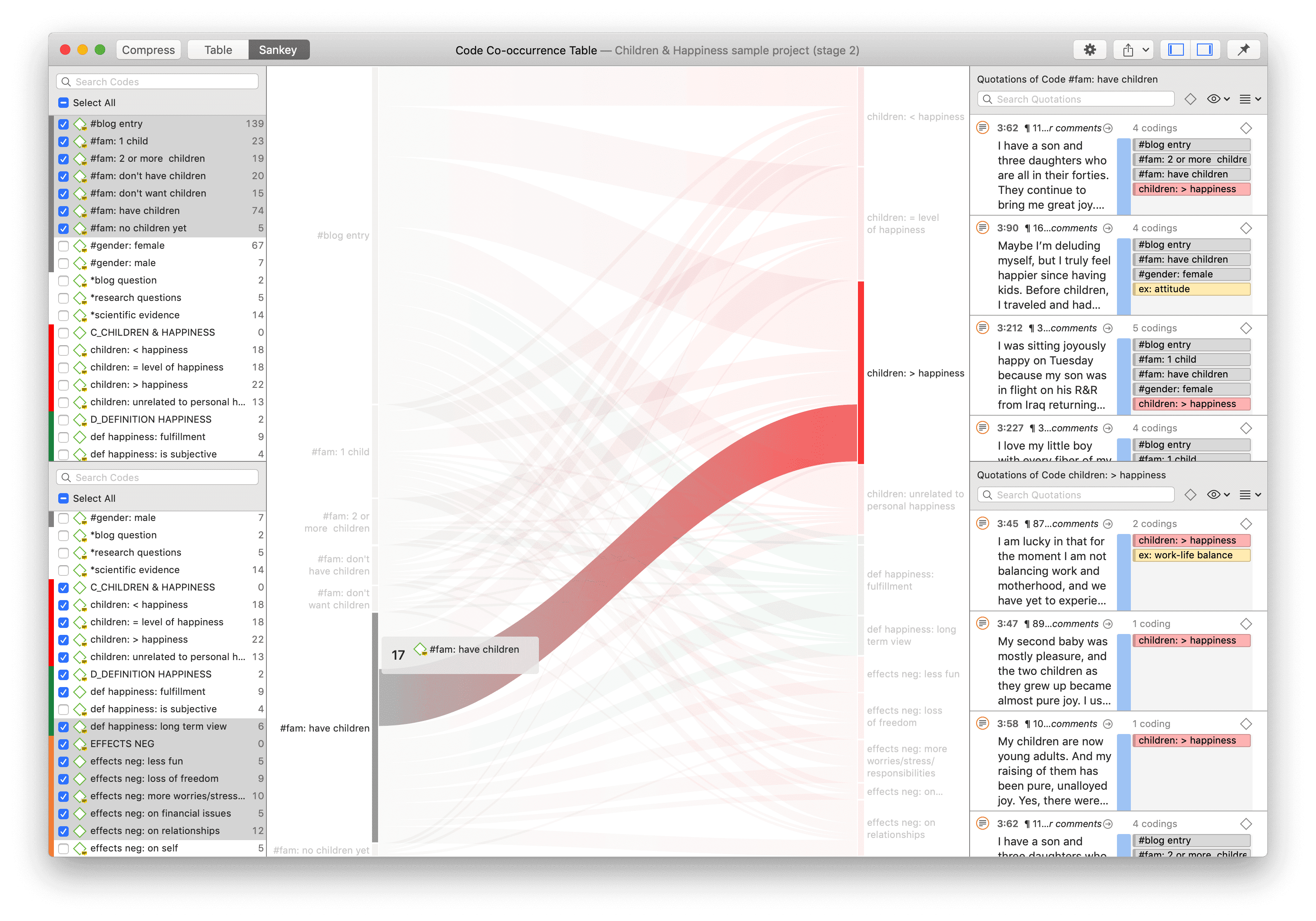
Tabulación cruzada de códigos (co-ocurrencia de códigos)
Las herramientas de análisis de co-ocurrencia muestran dónde se han aplicado códigos de forma superpuesta. En lugar de determinar los códigos usted mismo, puede consultar a ATLAS.ti qué códigos se solapan. El resultado puede visualizarse en forma de vista de árbol o de tabla. La tabla proporciona un recuento de frecuencias del número de co-ocurrencias y un coeficiente que mide la fuerza de la relación. Dado que un coeficiente solo es apropiado para determinados tipos de datos, su visualización puede activarse o desactivarse. También es posible acceder directamente a los datos de cada co-ocurrencia. Consulte Herramientas de co-ocurrencia de códigos.
Tabla código-documento
La tabla código-documento cuenta la frecuencia de los códigos por documento. También están disponibles recuentos agregados basados en grupos de códigos y grupos de documentos. Opcionalmente, las celdas de la tabla también pueden contener el recuento de palabras de las citas por código y por documento o grupo de documentos. La tabla puede exportarse a Excel. Consulte Tabla código-documento.
Herramienta de consulta
Para solicitudes de búsqueda más complejas, dispone de la Herramienta de consulta. Aquí puede formular solicitudes de búsqueda basadas en combinaciones de códigos mediante uno o varios de los 14 operadores disponibles: booleanos, semánticos y de proximidad. Consulte La herramienta de consulta.
Filtros globales
Los filtros globales son una herramienta de análisis de gran potencia. Los filtros globales afectan al proyecto completo y permiten comparar y contrastar los datos de múltiples formas distintas. Los efectos y conexiones que antes permanecían ocultos ahora son visibles y emergen patrones. Para más información, consulte Aplicación de filtros globales.
Códigos inteligentes
Un código inteligente es una consulta almacenada que, en el mejor de los casos, ofrece respuesta a una pregunta y suele estar compuesto por varios códigos combinados. Consulte Trabajo con códigos inteligentes.
Grupos inteligentes
Los grupos inteligentes son una combinación de grupos. Por ejemplo, si desea comparar las respuestas de encuestadas de zonas rurales con las de encuestadas de zonas urbanas, crearía dos grupos inteligentes que utilizaría directamente en una tabla código-documento o como filtro en una consulta de códigos. Los grupos de códigos inteligentes pueden utilizarse cuando se necesita frecuentemente una combinación de determinados códigos. Consulte Trabajo con códigos inteligentes.
Nube de proyectos
Los proyectos en ATLAS.ti residen principalmente en su equipo, para garantizar tanto la privacidad de los datos como la disponibilidad sin conexión. Además, puede optar por cargar sus proyectos a la nube de proyectos de ATLAS.ti directamente desde la aplicación, para compartirlos con colegas, acceder a ellos desde varios equipos o simplemente como copia de seguridad.
Tenga en cuenta que esta función se encuentra aún en fase beta. Esto significa que habrá cambios en las próximas semanas y meses, y es posible que no todo funcione con la misma fluidez de siempre. Si tiene algún comentario, no dude en utilizar el formulario de comentarios integrado en la aplicación (accesible cuando tiene un proyecto abierto).
Cada proyecto que cree comenzará en su equipo. Para cargarlo a la nube, haga clic en los tres puntos situados a la derecha del nombre del proyecto en la lista de proyectos y elija "Cargar". Se le pedirá confirmación.
ATLAS.ti siempre solicitará confirmación antes de cargar por primera vez un proyecto a la nube. Si decide hacerlo, sus proyectos se almacenarán con cifrado de extremo a extremo en nuestros servidores europeos. Para obtener más información sobre privacidad, consulte nuestra política de privacidad. Y si sus requisitos de privacidad son tales que no puede utilizar nuestra nube, no se preocupe. Su proyecto permanecerá de forma segura en su equipo hasta que usted decida lo contrario.
Un proyecto de ATLAS.ti puede encontrarse en uno de los siguientes estados:
- En este equipo: El proyecto no está presente en la nube de ATLAS.ti.
- En la nube: El proyecto está en la nube, pero no está presente en este equipo. Es necesario descargarlo para poder trabajar en él.
- Tanto en este equipo como en la nube: Los proyectos que existen tanto en la nube como en este equipo mostrarán uno de los siguientes estados:
- Ambas versiones están sincronizadas.
- La versión en este equipo es más reciente. Después de realizar cambios en un proyecto, este se encontrará en este estado. Simplemente haga clic en los tres puntos y elija "Cargar" para enviar los cambios a la nube.
- La versión en la nube es más reciente. Esto significa que ha trabajado en este proyecto desde otro equipo. Deberá descargar la versión más reciente antes de continuar. Tenga en cuenta que la nube de proyectos de ATLAS.ti no está diseñada para trabajar simultáneamente en el mismo proyecto desde dos equipos. Asegúrese siempre de haber terminado en un equipo antes de continuar el trabajo en otro.

El almacenamiento en la nube de proyectos está vinculado a la misma cuenta de ATLAS.ti utilizada para el licenciamiento o para iniciar sesión en ATLAS.ti Web.
Durante el período beta, cada usuario dispone de 500 MB de almacenamiento gratuito en la nube. Esto es suficiente para varios proyectos que contengan cientos de documentos de texto cada uno. Tenga en cuenta que otros tipos de documentos, especialmente el video, pueden ocupar mucho espacio. Puede liberar espacio eliminando proyectos de la nube o borrando documentos de gran tamaño de un proyecto que tenga en la nube.
Cómo usar
En la lista de proyectos, haga clic en los tres puntos situados a la derecha del nombre del proyecto para ver las opciones disponibles. Además de las opciones habituales como abrir, renombrar, etc., encontrará comandos específicos de la nube según el estado del proyecto.
Puede cargar un proyecto que no esté en la nube o cuya versión en su equipo sea más reciente. Esto colocará la versión más reciente del proyecto en la nube de ATLAS.ti.
Para un proyecto que está en la nube pero que no está presente o está desactualizado en su equipo, puede descargarlo para tener la versión más reciente disponible localmente.
ATLAS.ti siempre abrirá la versión local de un proyecto. Si ha trabajado en un proyecto desde otro equipo, asegúrese de cargarlo allí después de guardarlo. Antes de trabajar en un proyecto, asegúrese de tener disponible localmente la versión más reciente.
También puede optar por eliminar un proyecto de la nube, lo que mantendrá la copia local en su equipo, o eliminar el proyecto de su equipo, en cuyo caso seguirá disponiendo de una copia en la nube. Para eliminar completamente un proyecto tanto de su equipo como de la nube, utilice ambas opciones de forma sucesiva.
Compartir proyectos
Para compartir un proyecto con colegas, haga clic en los tres puntos y elija "Invitar miembro…". Introduzca la dirección de correo electrónico de la cuenta de ATLAS.ti de la persona con quien desea compartir el proyecto. ATLAS.ti generará un enlace de invitación. Copie este enlace y envíelo a su colega. Tenga en cuenta que el enlace es personalizado y solo puede ser utilizado por la persona para quien fue generado.
Compartir un enlace a su proyecto creará una copia del mismo. Esa copia será completamente independiente de su proyecto y será privada para la persona a quien se la envíe. Por lo tanto, el invitado podrá realizar cualquier cambio sin preocuparse por interferir con su trabajo (y viceversa). Cuando llegue el momento de que su colega le devuelva su trabajo, podrá invitarle a su proyecto, lo que generará una copia para usted. Una vez aceptada la invitación, podrá ver (y trabajar en) el trabajo realizado por su colega y, si lo desea, fusionarlo con su proyecto. De esta manera, dispone de máxima flexibilidad: al evaluar el trabajo de los estudiantes, probablemente desee ver todo su trabajo de forma independiente, mientras que en un proyecto real de equipo, puede que prefiera fusionar el trabajo de los colegas después de revisarlo.
Consulte Trabajo en equipo para obtener información detallada sobre cómo funciona el trabajo en equipo con ATLAS.ti, independientemente de si utiliza la nube de ATLAS.ti para compartir proyectos o la funcionalidad clásica de exportación/importación.
Limitaciones actuales
Al ser una función en fase beta, cabe esperar algunas limitaciones. No todas las interacciones están tan pulidas como nos gustaría, y también hay funcionalidades que aún faltan, además de posibles errores. Este es un buen momento para enviarnos sus comentarios, ya sean críticas, elogios o sugerencias.
Tenga en cuenta que en su forma actual, compartir proyectos no significa que usted y un colega vayan a trabajar sobre la misma instancia del proyecto, como puede estar acostumbrado de ATLAS.ti Web. Compartir un proyecto creará una copia independiente del proyecto para su colega. Tampoco hay todavía mucha funcionalidad de gestión de proyectos en equipo. Si tiene flujos de trabajo específicos para los que le gustaría ver un soporte más explícito, háganos saber.
Si bien los proyectos en la nube de ATLAS.ti pueden trabajarse sin restricciones independientemente de si se utiliza un PC con Windows o un Mac, actualmente estos proyectos no son accesibles desde ATLAS.ti Web. Las aplicaciones de escritorio de ATLAS.ti tampoco mostrarán los proyectos de ATLAS.ti Web.
Herramientas de equipo
Con frecuencia, los investigadores trabajan en equipos para recopilar y analizar datos. ATLAS.ti está especialmente diseñado para el trabajo colaborativo. Un conjunto de herramientas y funciones especiales facilitan el trabajo eficiente en equipo. Para más información, consulte el capítulo sobre Trabajo en equipo.
Para la codificación colaborativa en tiempo real, puede consultar la versión web de ATLAS.ti. Los proyectos de ATLAS.ti web pueden importarse a la versión de escritorio para aprovechar las herramientas de análisis avanzado y la función de redes.
Nube de proyectos (Beta)
Los proyectos en ATLAS.ti residen principalmente en su equipo, para garantizar tanto la privacidad de los datos como la disponibilidad sin conexión. Además, puede cargar sus proyectos en la nube de proyectos de ATLAS.ti directamente desde la aplicación: para compartirlos con colegas, acceder a ellos desde varios equipos o simplemente como copia de seguridad. Consulte Nube de proyectos para más información.
Fusión de proyectos
Cuando se trabaja en equipos, normalmente se divide el proyecto en subproyectos. En la versión de escritorio es necesario trabajar de forma asíncrona. La herramienta de fusión de proyectos une de nuevo todos los subproyectos. Para más información, consulte Fusión de proyectos.
Limpieza de codificaciones redundantes
Las codificaciones redundantes son citas superpuestas o incluidas que están asociadas al mismo código. Este tipo de codificaciones puede ser resultado de la codificación habitual, pero también puede aparecer de forma inadvertida durante un proceso de fusión al trabajar en equipo. El Analizador de codificaciones encuentra todas las codificaciones redundantes y ofrece los procedimientos adecuados para corregirlas. Consulte Búsqueda de codificaciones redundantes.
Iconos de codificador en el área de margen
Es posible cambiar la vista del área de margen para mostrar un icono por cada usuario en lugar del icono del código. De este modo, al navegar por los datos, se puede ver quién aplicó cada código.
Acuerdo intercodificadores
ATLAS.ti permite la comparación cualitativa y cuantitativa de las codificaciones de distintos codificadores. Si desea calcular un coeficiente, ATLAS.ti ofrece las siguientes opciones: porcentaje de acuerdo, Holsti y la familia de coeficientes alfa de Krippendorff. Consulte Acuerdo intercodificadores.
Administración de usuarios
ATLAS.ti crea automáticamente un nombre de usuario para cada usuario al iniciar sesión. Cada entidad que se crea queda marcada con ese nombre de usuario. Esto es un requisito previo para el trabajo colaborativo, de modo que se pueda ver y comparar quién hizo qué. Es posible cambiar el nombre de los usuarios existentes, crear nuevas cuentas de usuario, eliminar usuarios y cambiar de usuario. Consulte Cuentas de usuario para más información.
Tenga en cuenta que el trabajo en equipo síncrono no es compatible con la versión de escritorio. Cada miembro del equipo trabaja en su propio archivo de proyecto, y estos deben fusionarse periódicamente.
Use ATLAS.ti Web si desea trabajar con su equipo en el mismo proyecto al mismo tiempo.
Exportación
Word / PDF
Existen opciones de salida para cada una de las entidades principales en ATLAS.ti: Documentos, citas, códigos y memos, así como en las distintas herramientas. Todos los informes son configurables por el usuario y se puede decidir qué tipo de contenido incluir. Consulte Creación de informes.
Exportación a Excel
En cada Administrador y lista de citas encontrará una opción de exportación a Excel. Además, los resultados de la Tabla de co-ocurrencia de códigos y la Tabla código-documento pueden exportarse en formato Excel.
Consulte Creación de informes en Excel.
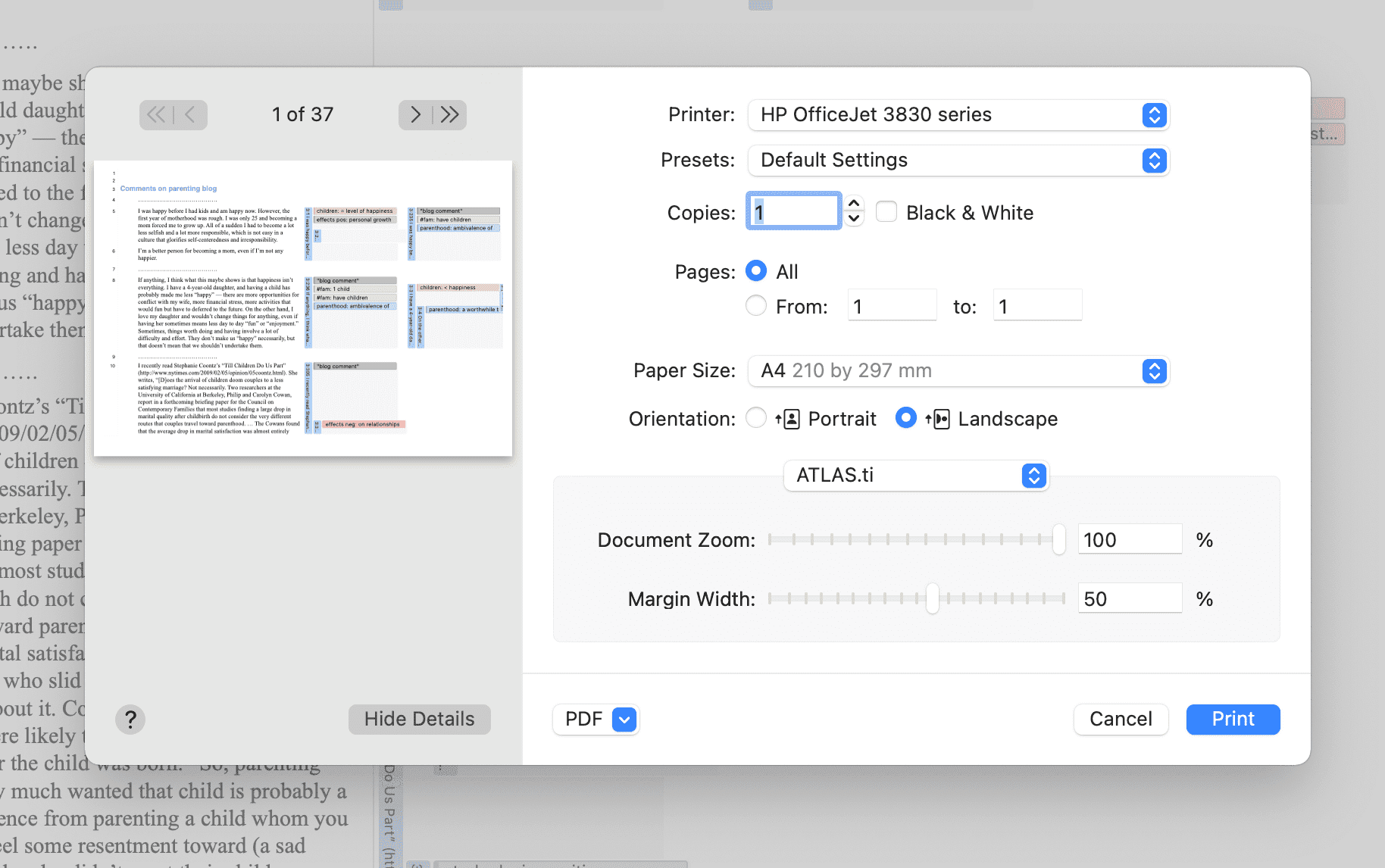
Impresión de documentos con margen
Es posible imprimir o exportar documentos de texto codificados en formato PDF tal como aparecen en pantalla, incluida la numeración de párrafos. Consulte Imprimir con margen.
 .
.
Formato de intercambio QDPX para proyectos
El formato QDPX es un estándar QDA-XML para el intercambio de proyectos entre diferentes paquetes CAQDAS. El formato de intercambio de proyectos se lanzó el 18 de marzo de 2019. Puede consultar todos los programas participantes en el siguiente sitio web: https://www.qdasoftware.org. Consulte Intercambio universal de datos QDPX.
Exportación a SPSS / PSPP
Es posible exportar los datos codificados como archivo de sintaxis SPSS. Este archivo también puede utilizarse en la versión básica gratuita PSPP. Al ejecutarse en SPSS o PSPP, las citas se convierten en casos y los códigos y grupos de códigos en variables. Además, se proporciona información de identificación adicional en forma de variables, como el nombre y el número del documento para cada caso, la posición de inicio y fin, y la fecha de creación. Estas variables permiten agregar los datos en SPSS si es necesario. Consulte Exportación a SPSS.
Si necesita una salida menos detallada, consulte Tabla código-documento. La tabla proporciona una salida ya agregada por documentos o grupos de documentos.
Exportación estadística genérica para R, SAS, STATA, etc.
Es posible exportar los datos codificados como archivo Excel para su posterior análisis en cualquier paquete estadístico. Las citas se convierten en casos y los códigos y grupos de códigos en variables. Además, se proporciona información de identificación adicional en forma de variables, como el nombre y el número del documento para cada caso, la posición de inicio y fin, y la fecha de creación. Consulte Exportación genérica para análisis estadístico posterior.
Archivos de imagen
-
Las redes pueden guardarse en varios formatos de archivo gráfico (jpg, png, tiff, gif, bmp). Consulte Exportación de redes.
-
Las nubes de palabras pueden exportarse como archivos jpg. Consulte Nubes de palabras.
-
Los resultados de la co-ocurrencia de códigos y la tabla código-documento pueden visualizarse en forma de diagramas Sankey. Consulte Visualización de la tabla de co-ocurrencia de códigos y Visualización de la tabla código-documento.
Pasos principales para trabajar con ATLAS.ti
Gestión de datos y proyectos
Un primer aspecto importante, aunque a menudo descuidado, de un proyecto es la gestión de datos y proyectos. El primer paso es la preparación de los datos. Encontrará más información sobre los formatos de archivo compatibles en la sección Formatos de archivo compatibles.
Además de analizar sus datos, también gestiona contenido digital, y es importante saber cómo lo hace el software. Para información detallada, consulte la sección sobre Gestión de proyectos.
Si trabaja en equipo, lea la siguiente sección: Trabajo en equipo.
Dos modos principales de trabajo
Existen dos modos principales de trabajo con ATLAS.ti: el nivel de datos y el nivel conceptual. El nivel de datos incluye actividades como la segmentación de archivos de datos; la codificación de pasajes de texto, imagen, audio y vídeo; y la escritura de comentarios y memos. El nivel conceptual se centra en la consulta de datos y las actividades de construcción de modelos, como la vinculación de códigos en redes, además de la escritura de más comentarios y memos.
La figura siguiente ilustra los pasos principales, comenzando con la creación de un proyecto, la adición de documentos, la identificación de elementos de interés en los datos y su codificación. Los memos y comentarios pueden escribirse en cualquier etapa del proceso, aunque posiblemente se produce un desplazamiento de la escritura de comentarios hacia una escritura de memos más extensa durante las etapas posteriores del análisis. Una vez codificados los datos, están listos para ser consultados mediante las diversas herramientas de análisis proporcionadas. Los conocimientos obtenidos pueden luego visualizarse utilizando la función de red de ATLAS.ti.
Algunos pasos deben realizarse en secuencia. Por ejemplo, la lógica dicta que no se puede consultar nada ni buscar coocurrencias si los datos aún no han sido codificados. Pero aparte de eso, no hay reglas estrictas.
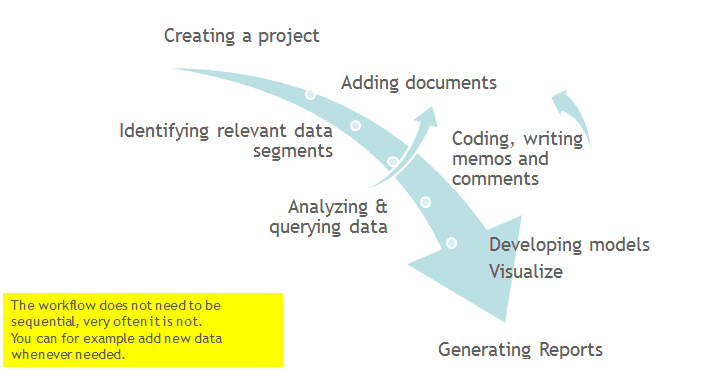
Trabajo a nivel de datos
Las actividades a nivel de datos incluyen explorar los datos mediante nubes de palabras y listas de palabras, segmentar los datos asignados a un proyecto en citas, añadir comentarios a los pasajes correspondientes toma de notas / anotación, vincular segmentos de datos entre sí —lo que en ATLAS.ti se denomina hipervínculo— y codificar segmentos de datos y memos para facilitar su recuperación posterior. El acto de comparar segmentos destacables conduce a una fase de conceptualización creativa que implica un trabajo interpretativo de nivel superior y la construcción de teorías.
ATLAS.ti le asiste en todas estas tareas y proporciona una visión general completa de su trabajo, así como funciones rápidas de búsqueda, recuperación y navegación.
Dentro de ATLAS.ti, las ideas iniciales a menudo se expresan mediante su asignación a un código o memo, al que también se asignan ideas similares o selecciones de texto. ATLAS.ti proporciona al investigador un medio altamente eficaz para recuperar rápidamente todas las selecciones de datos y notas relevantes para una idea.
Trabajo a nivel conceptual
Más allá de la codificación y la recuperación simple de datos, ATLAS.ti le permite consultar sus datos de muchas maneras diferentes, combinando consultas de códigos complejas con variables, explorando las relaciones entre códigos y visualizando sus hallazgos mediante la herramienta de red.
ATLAS.ti le permite conectar visualmente pasajes seleccionados, memos y códigos en diagramas que esbozan gráficamente relaciones complejas. Esta función transforma virtualmente su espacio de trabajo basado en texto en un entorno gráfico donde puede construir conceptos y teorías basadas en relaciones entre códigos, segmentos de datos o memos.
Este proceso a veces descubre otras relaciones en los datos que no eran evidentes antes y aún le permite volver instantáneamente a sus notas o selecciones de datos primarios. Para más detalles, consulte Consulta de datos y Trabajo con redes.
Pantalla de bienvenida
Al abrir ATLAS.ti, verá la pantalla de bienvenida. Está dividida en tres partes:
Pantalla de bienvenida (lado izquierdo)
En el lado izquierdo encontrará información sobre la licencia, puede crear un nuevo proyecto o importar un proyecto existente.

Pantalla de bienvenida (sección central)
En la sección central puede ver y acceder a todos sus proyectos. Puede ordenar los proyectos por última vez utilizado, nombre y última vez guardado.
Menú contextual para proyectos
El menú secundario para proyectos tiene las siguientes opciones: abrir un proyecto, cambiar el nombre de un proyecto, duplicar un proyecto y eliminar un proyecto.
Si elimina un proyecto, se elimina de forma permanente. No puede recuperarse. Si aún desea tener acceso al proyecto en un momento posterior, asegúrese de exportarlo primero y almacenar un archivo bundle del proyecto en una ubicación segura.
Pantalla de bienvenida (lado derecho)
En el lado derecho de la pantalla de bienvenida tiene acceso a información y recursos útiles:
- Noticias sobre talleres actuales, actualizaciones, boletines informativos, artículos interesantes, etc.
- Recursos: Manual de usuario y proyectos de muestra
- Tutorial en vídeo: Aprenda ATLAS.ti rápidamente viendo nuestros tutoriales en vídeo que le guían a través de todo el proceso, desde la creación del proyecto hasta el análisis y la elaboración de informes, paso a paso.
Si prefiere usar este espacio para ver la lista de sus proyectos, puede hacer clic en el botón con la flecha hacia la derecha.
Si desea ver de nuevo la pantalla con las noticias y recursos, haga clic en el botón con la flecha hacia la izquierda.
Crear un nuevo proyecto
Tutorial en video: Crear un proyecto y agregar datos.
Si acaba de iniciar ATLAS.ti,
En la ventana de apertura, en el lado izquierdo de la pantalla, haga clic en el botón: Crear nuevo proyecto.
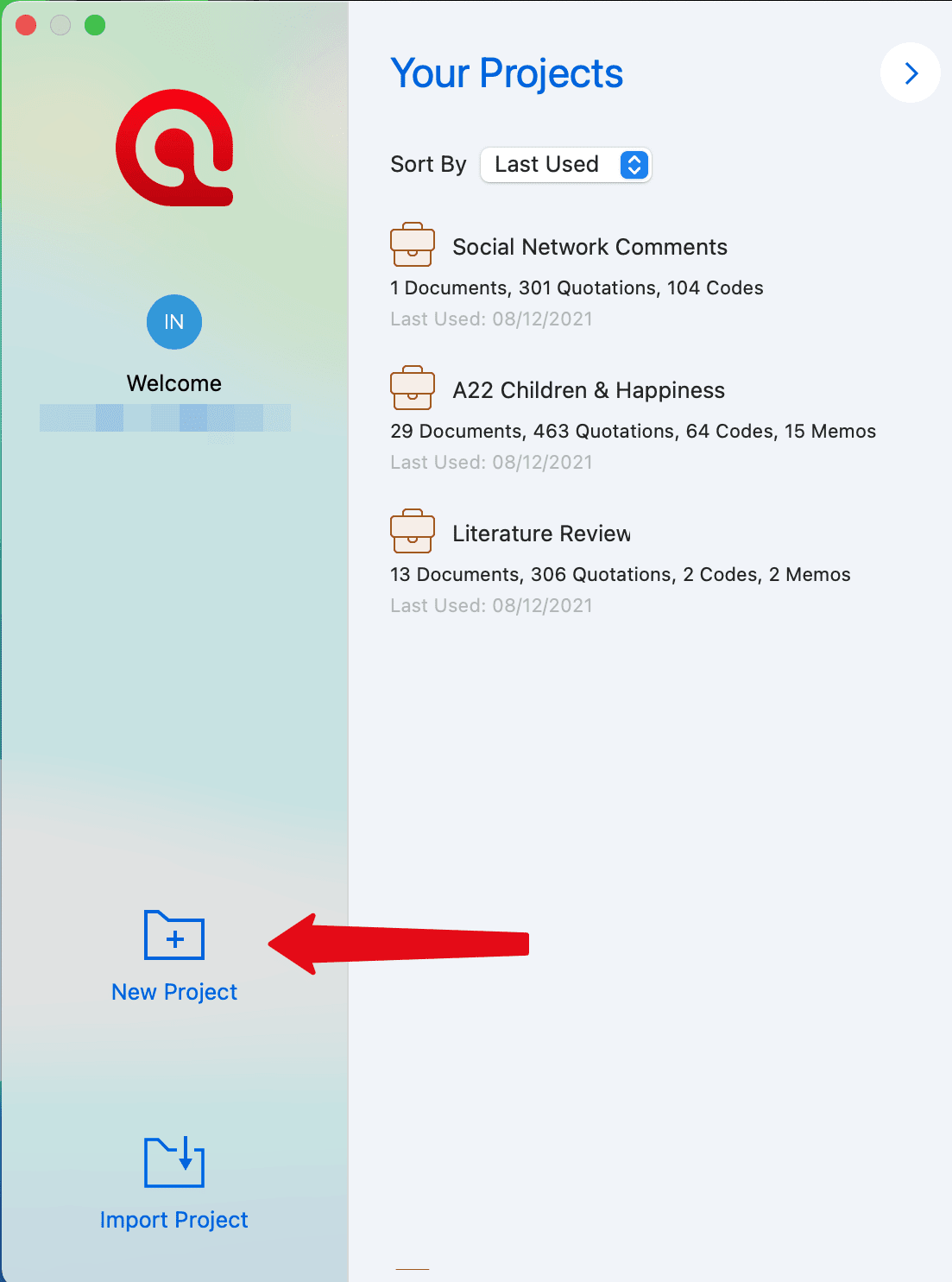
Introduzca un nombre para el proyecto y haga clic en Crear.
Si ya tiene un proyecto abierto,
En el menú principal, seleccione Proyecto > Nuevo. Introduzca un nombre para el proyecto y haga clic en Crear.
Importar un proyecto existente
Cómo importar proyectos
Si acaba de iniciar ATLAS.ti,
Seleccione la opción Importar proyecto en el lado derecho de la pantalla de apertura.
Si ATLAS.ti ya está abierto,
Haga doble clic en un archivo de paquete de proyecto en su equipo. Esto abrirá ATLAS.ti si aún no está abierto y podrá importar el proyecto.
O bien:
Seleccione Proyecto > Importar proyecto. Cambie el nombre del proyecto si es necesario.
Opciones
- Tiene la opción de cambiar el nombre del proyecto antes de importarlo. Esto es útil para el trabajo en proyectos en equipo y si no desea sobrescribir una versión existente.
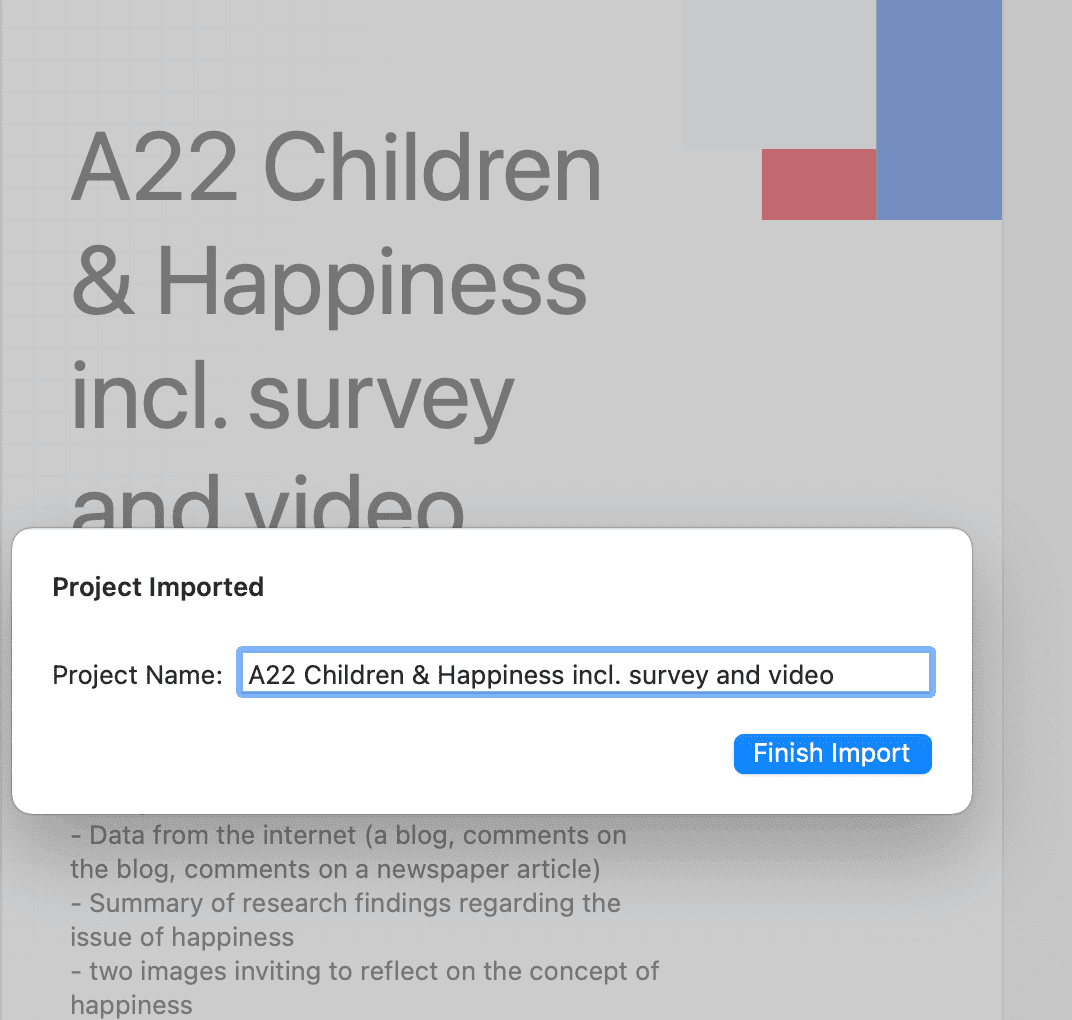
Si el proyecto contiene archivos multimedia vinculados
Si el proyecto contiene archivos multimedia vinculados y los archivos no se han incluido en el paquete, puede volver a vincularlos. Para ello es necesario que disponga de una copia del archivo en su equipo, o de un archivo accesible en una unidad externa o en un servidor.
Formatos de archivo de proyecto
Puede importar proyectos exportados con ATLAS.ti 8 o versiones más recientes. Los proyectos pueden moverse sin problemas entre Windows y Mac sin ninguna pérdida.
Además, se pueden importar proyectos creados con ATLAS.ti Web, así como proyectos creados con ATLAS.ti Mobile en iPad o Android.
ATLAS.ti es un orgulloso colaborador del estándar REFI QDPX independiente del proveedor, y puede importar proyectos escritos en este formato, independientemente de la aplicación con la que se hayan creado.
La interfaz de ATLAS.ti
Al abrir un proyecto, verá el menú en la parte superior, el navegador de proyectos en el lado izquierdo y un inspector en el lado derecho. El inspector muestra más información sobre la entidad activa en ese momento. Al abrir un proyecto recién, esta es el propio proyecto.
Debajo del menú principal, verá una barra de herramientas que permite el acceso rápido al Administrador de documentos, citas, códigos, memos y redes.

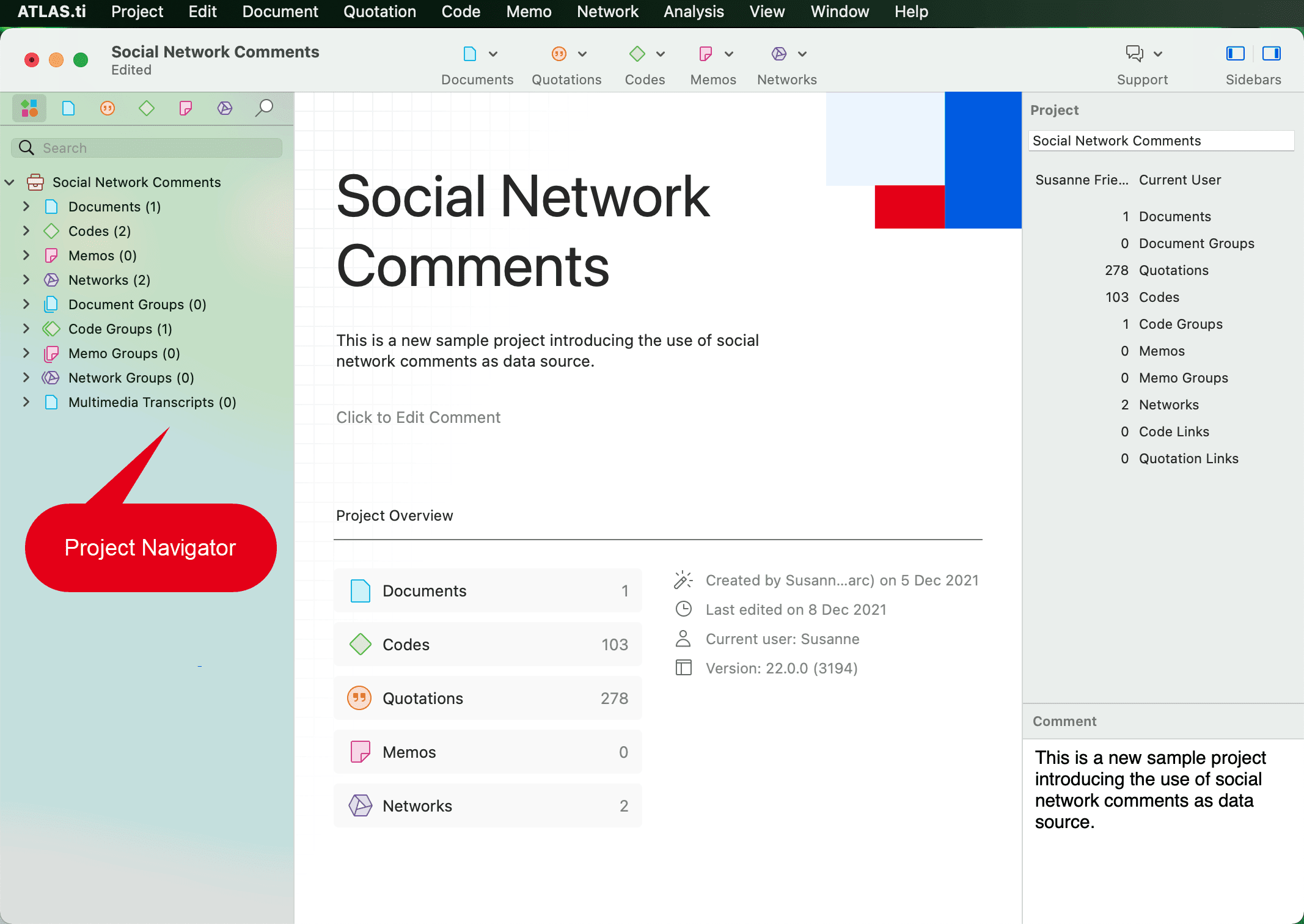
También puede usar la opción Diseño para mostrar u ocultar los paneles del Navegador y el Inspector.
El menú principal
El menú Proyecto da acceso a todas las funciones relacionadas con el proyecto:
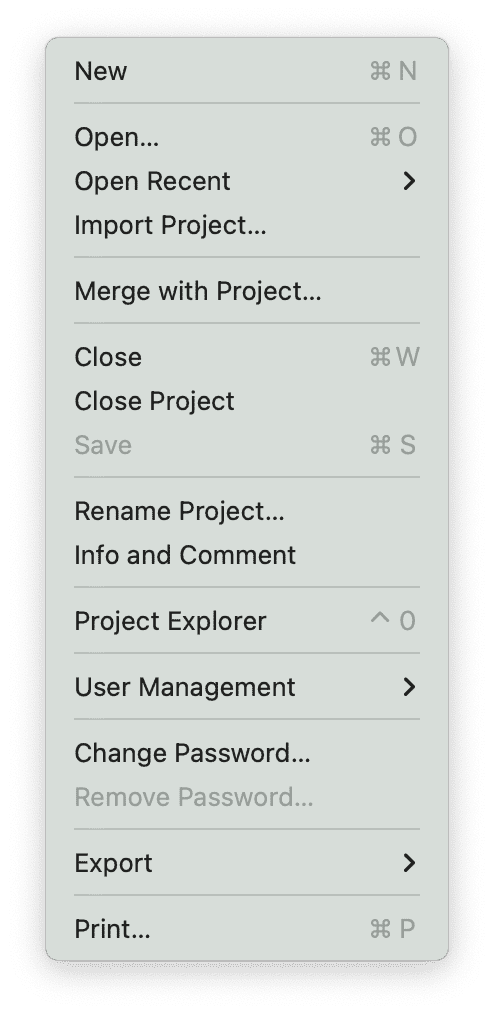
- abrir, cerrar o cambiar el nombre de un proyecto
- importar un proyecto
- gestión de usuarios
- fusionar proyectos
- exportación de proyectos
- exportación de proyectos para intercambio universal de datos
- exportación de datos para análisis estadístico adicional
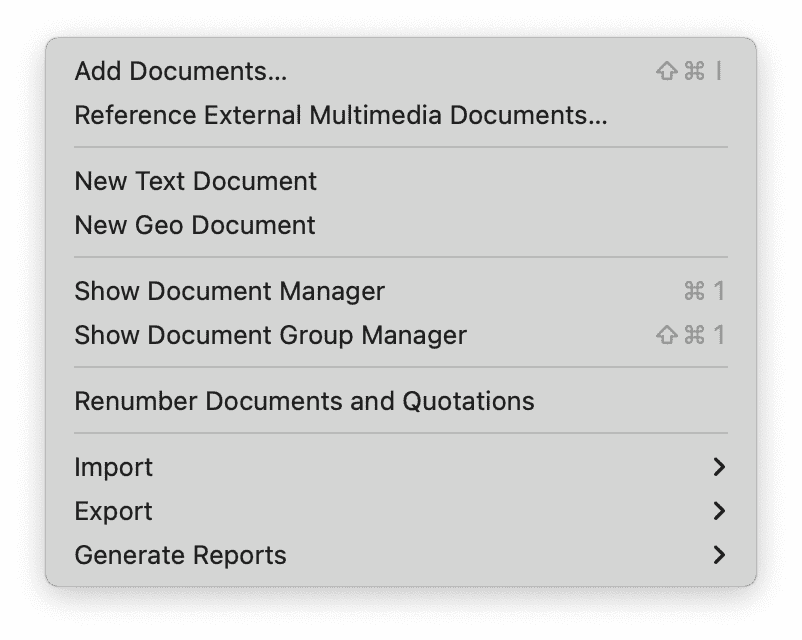
El menú Documento da acceso a todas las funciones relacionadas con los documentos:
- Agregar documentos
- Agregar un documento geográfico
- Importar datos de encuestas
- Importar datos de gestores de referencias
- Importar comentarios de redes sociales
- Mostrar el Administrador de documentos
- Renumerar documentos y citas
- Importar grupos de documentos
- Exportar grupos de documentos
- Generar informes
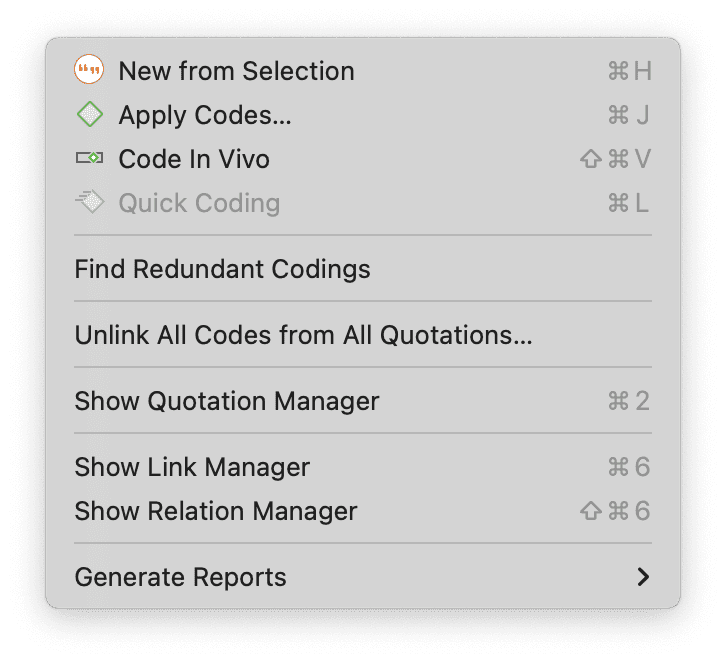
El menú Cita da acceso a todas las funciones relacionadas con las citas:
- Crear citas
- Aplicar códigos
- Buscar codificaciones redundantes
- Desvincular todos los códigos de todas las citas
- Mostrar el Administrador de citas
- Mostrar el Administrador de vínculos
- Mostrar el Administrador de relaciones
- Generar informes
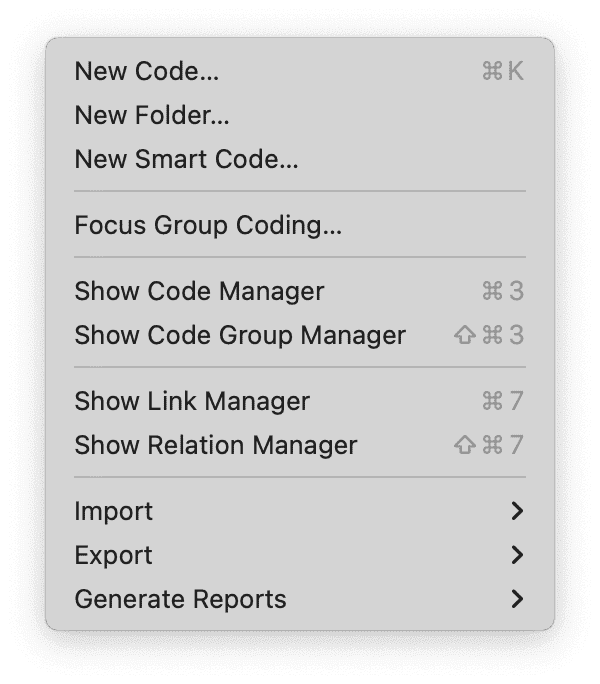
El menú Código da acceso a todas las funciones relacionadas con los códigos:
- Crear un nuevo código
- Crear un nuevo código inteligente
- Codificación de grupos focales
- Mostrar el Administrador de códigos
- Mostrar el Administrador de vínculos
- Mostrar el Administrador de relaciones
- Importar y exportar un libro de códigos
- Generar informes
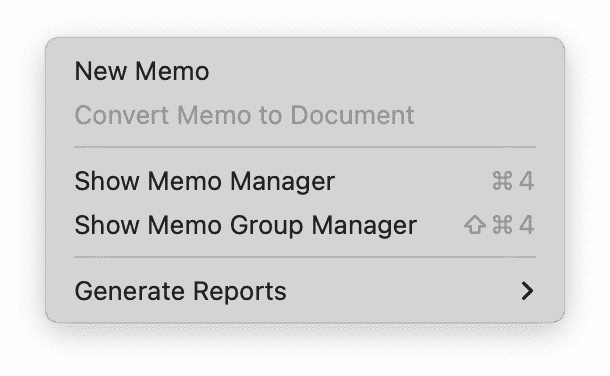
El menú Memo da acceso a todas las funciones relacionadas con los memos:
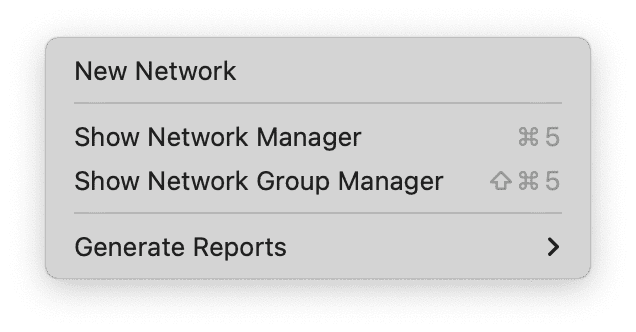
El menú Red da acceso a todas las funciones relacionadas con las redes:
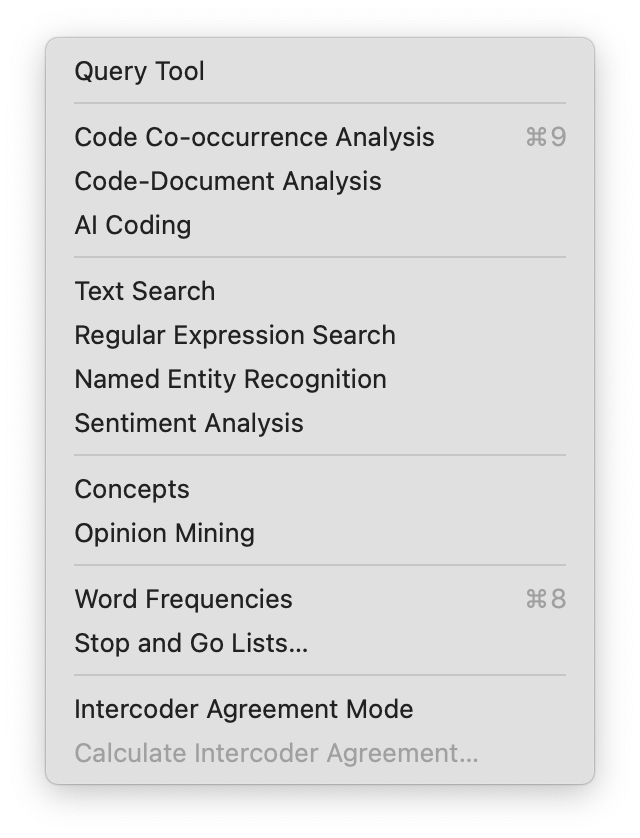
El menú Análisis da acceso a todas las funciones analíticas que necesita después de haber codificado los datos. También encontrará la opción de Lista de palabras / Nube de palabras en este menú:
- La Herramienta de consulta
- Herramientas de coocurrencia de códigos
- Herramientas de análisis de código-documento
- Búsqueda de texto
- Búsqueda con expresiones regulares
- Reconocimiento de entidades nombradas
- Análisis de sentimientos
- Tablas de conceptos
- Crear listas de palabras y nubes
- Acceder a listas de inclusión y exclusión
- Codificación con IA
- Codificación intencional con IA
- Resúmenes con IA
- IA conversacional
- Establecer el modo de acuerdo entre codificadores
- Abrir la herramienta de análisis de acuerdo entre codificadores
Navegación por el software
Esta página le guía sobre cómo trabajar con las diversas entidades y funciones en el espacio de trabajo principal. Si desea seguir los pasos, puede abrir el proyecto de muestra Sustainability.
Después de descargar el archivo bundle del proyecto, impórtelo. Consulte Importar un proyecto existente.
Al abrir un proyecto, el Navegador de proyectos se abre automáticamente en el lado izquierdo. Desde las ramas principales puede acceder a los documentos, códigos, memos, redes y todos los grupos. Si busca algo en particular, puede introducir un término de búsqueda en el campo de búsqueda. Si abre las ramas de las distintas entidades, solo se mostrarán los elementos que contengan el término de búsqueda.
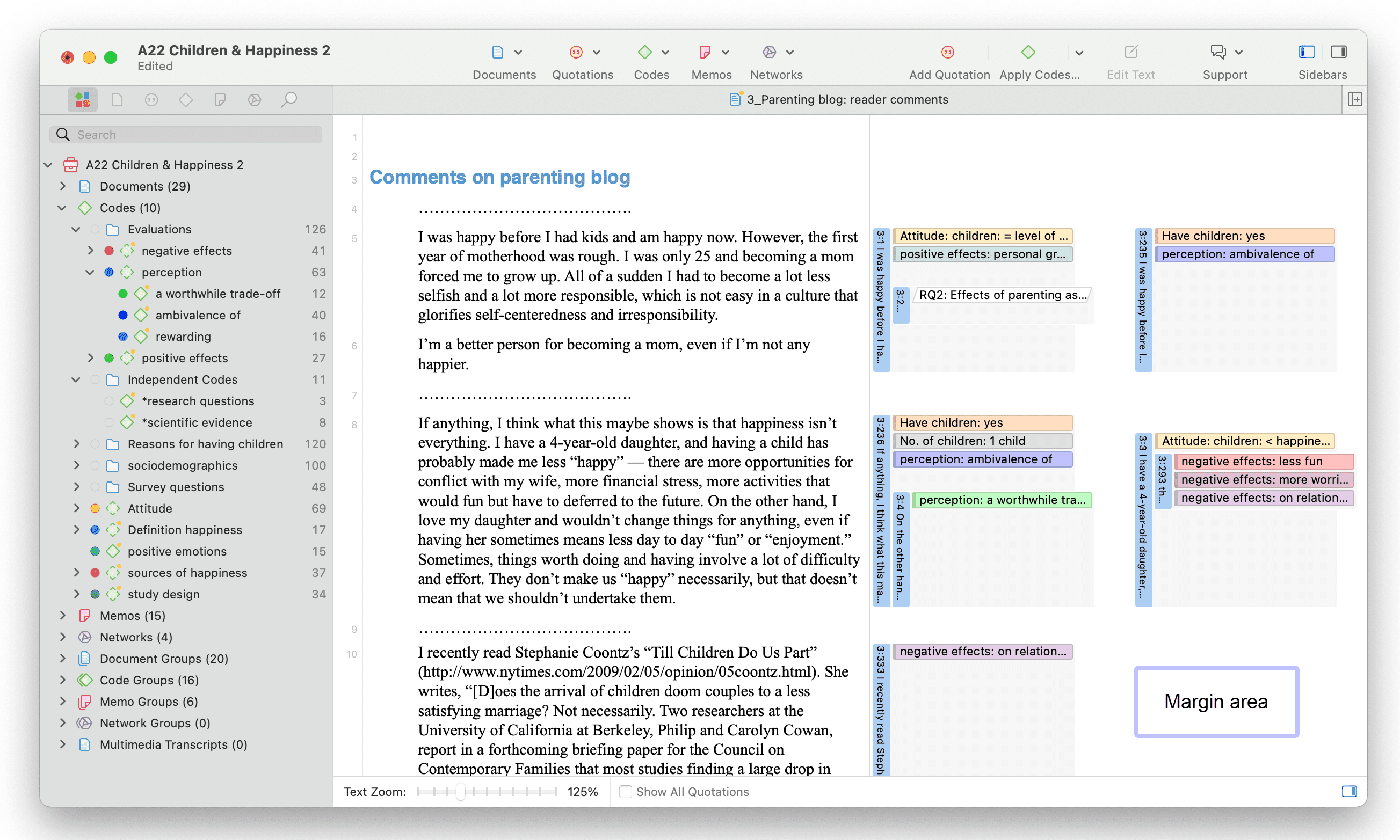
Para abrir una rama, haga clic en el triángulo situado delante de cada entidad.
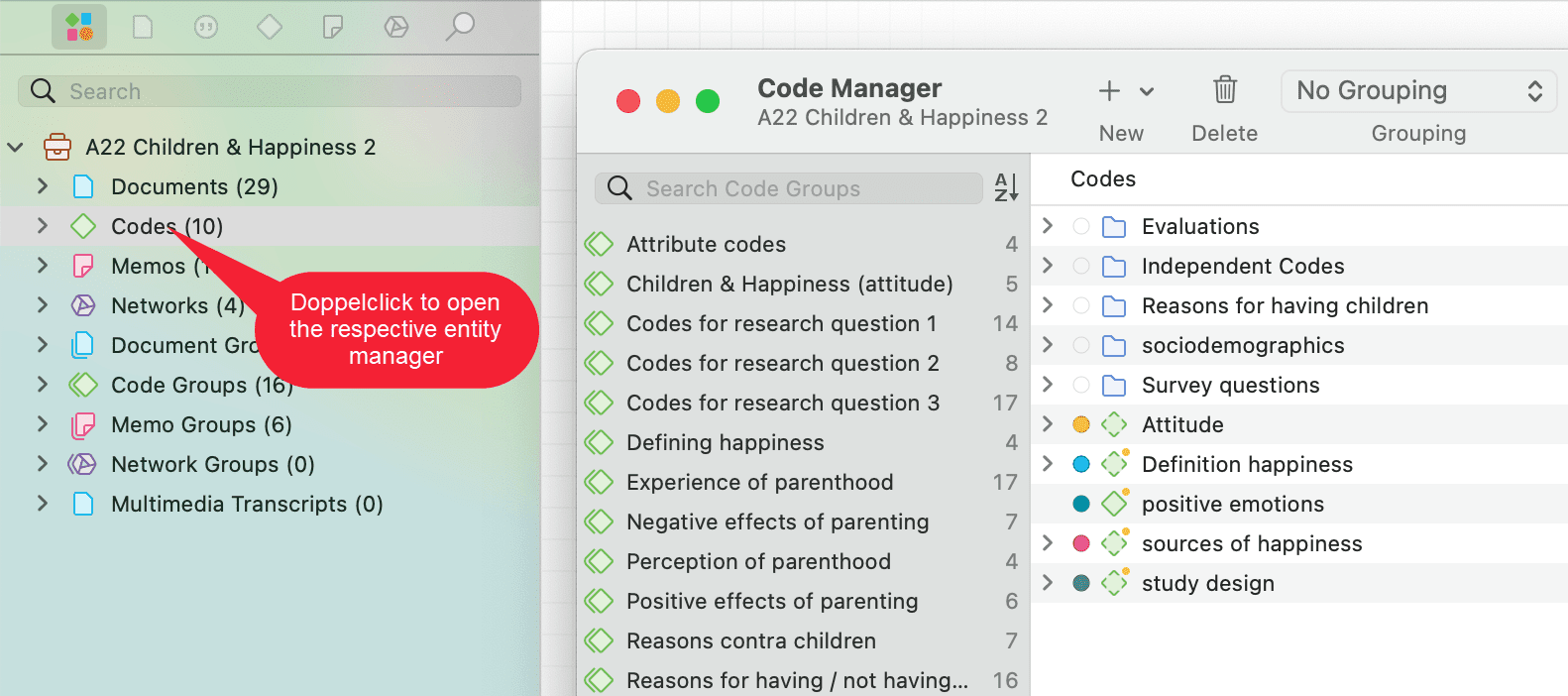
Al hacer doble clic en una rama principal, se abre el administrador correspondiente del tipo de entidad seleccionada. Consulte Administradores de entidades.
-
En la rama principal Documentos, verá todos los documentos. Debajo de cada documento puede acceder a todas las citas de ese documento.
-
En la rama principal Códigos, verá las carpetas, categorías, subcódigos y códigos independientes. Para más información, consulte: Conceptos básicos
-
En la rama principal Memos, verá la lista de todos los memos. En el siguiente nivel, verá todas las entidades vinculadas, que en el caso de los memos pueden ser otros memos, citas y códigos.
-
En la rama principal Redes, verá la lista de todas las redes. En el siguiente nivel, verá todas las entidades que se encuentran en la red.
-
En las ramas Grupos, verá la lista de todos los grupos y, debajo de cada grupo, la lista de todos los miembros del grupo seleccionado.
Si una entidad tiene un comentario, esto se indica mediante un punto amarillo adjunto al icono de la entidad.
Navegadores
Además del Navegador de proyectos que contiene todos los elementos del proyecto, puede abrir navegadores que contienen solo un tipo de entidad. Los navegadores están disponibles para documentos, citas, memos y redes.
Para abrir uno de los navegadores, haga clic en el icono situado encima del campo de búsqueda.
Los navegadores de entidad individual se abren en pestañas junto al Navegador de proyectos. Cada navegador también tiene un campo de búsqueda en la parte superior. Esto facilita el trabajo con listas largas.
Menús contextuales
Cada elemento del panel de navegación tiene un menú contextual, lo que significa que al hacer clic derecho se abre un menú sensible al contexto. Dependiendo de la entidad en la que haga clic, cada menú contextual será ligeramente diferente.
Barra de herramientas
Encima del espacio de trabajo principal verá una barra de herramientas que le da acceso rápido a los cinco tipos de entidades principales: documentos, citas, códigos, memos y redes. Cada icono de entidad tiene un menú desplegable que le da acceso a las opciones más utilizadas en relación con cada tipo de entidad.
Menú desplegable para documentos
- Abrir el Administrador de documentos
- Abrir el Administrador de grupos de documentos
- Agregar documentos
- Agregar un nuevo documento de texto, por ejemplo si desea transcribir sus datos en ATLAS.ti
- Importar transcripción
- Agregar un nuevo documento geográfico
- Buscar y codificar
- Mostrar conceptos
- Mostrar minería de opiniones
- Mostrar frecuencias de palabras (Lista de palabras / Nube)
- Codificación de grupos focales
- Codificación con IA
- Codificación intencional con IA
- Resúmenes con IA
- IA conversacional
Menú desplegable para citas
- Abrir el Administrador de citas
- Abrir el Administrador de vínculos
- Abrir el Administrador de relaciones
Menú desplegable para códigos
- Abrir el Administrador de códigos
- Abrir el Administrador de grupos de códigos
- Abrir el Administrador de vínculos
- Abrir el Administrador de relaciones
- Crear nuevos códigos
- Nueva carpeta
- Buscar y codificar
- Mostrar frecuencias de palabras (Lista de palabras / Nube)
- Mostrar conceptos
- Mostrar minería de opiniones
- Resúmenes con IA
Menú desplegable para memos
- Agregar un nuevo memo
- Abrir el Administrador de memos
- Abrir el Administrador de grupos de memos
Menú desplegable para redes
- Crear una nueva red
- Abrir el Administrador de redes
- Abrir el Administrador de grupos de redes
Ventanas acopladas y flotantes
-
Todos los documentos, memos y redes se abren en el área principal y están acoplados.
-
Todos los administradores y herramientas de análisis se abren en una ventana flotante. Si desea que una ventana flotante permanezca encima y no desaparezca en segundo plano al abrir otra cosa, puede anclarla a la pantalla haciendo clic en el icono de chincheta (Siempre encima) en la parte superior derecha de la ventana, bajo Diseño.
Trabajo con pestañas y regiones
Si abre varios documentos, o un documento, un memo y una red, estos se muestran en pestañas. Si desea verlos uno junto al otro, puede abrir una segunda región:
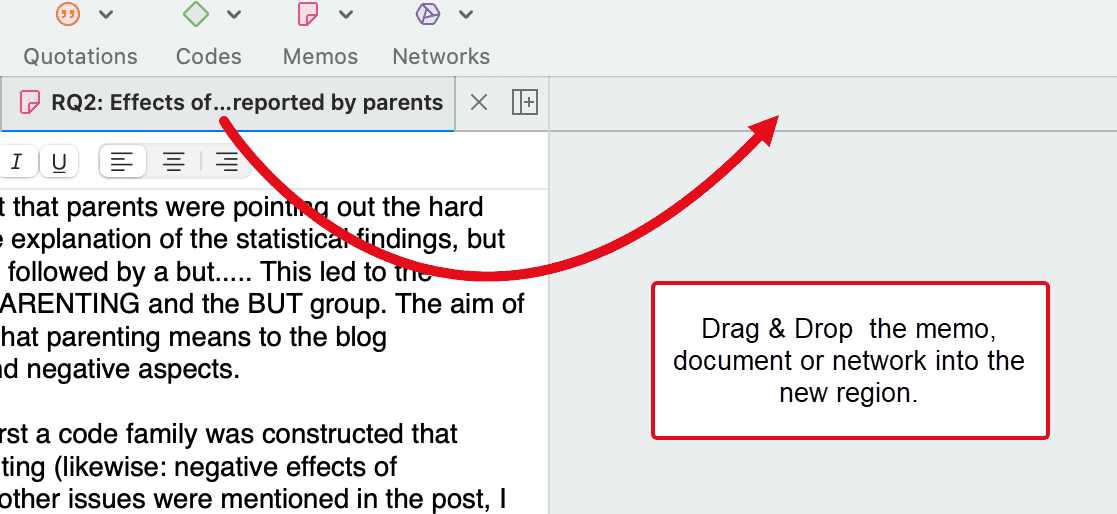
Haga clic en el botón + como se muestra en la captura de pantalla a continuación para abrir una nueva región:
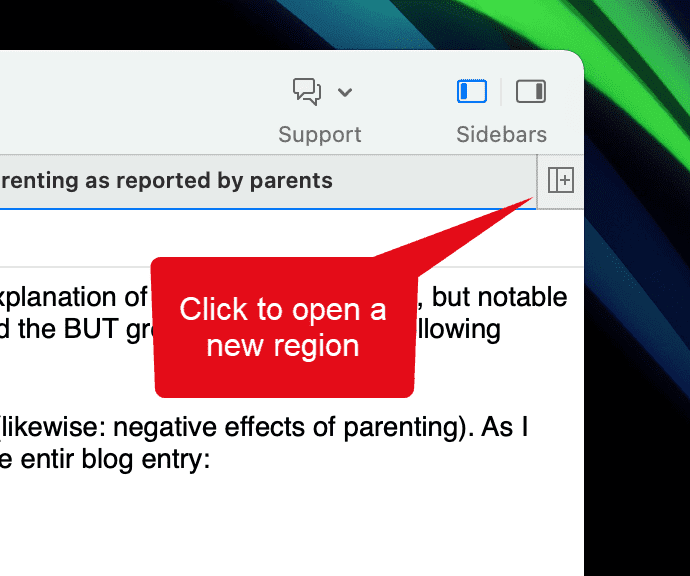
Seleccione uno de los elementos en pestañas y arrástrelo y suéltelo en la región vacía. Si lo arrastra hacia el lado derecho hasta que vea una barra de color, el elemento se mostrará junto al resto de elementos. Si lo arrastra hacia la parte superior de la región, el elemento se mostrará debajo del resto de elementos.
Los seis tipos de entidades principales
Los seis tipos de entidades principales en ATLAS.ti son:
Cada tipo de entidad tiene su propio administrador. Consulte Administradores de entidades. Los Administradores de entidades permiten acceder a las entidades y ofrecen diversas opciones y funciones.
Para abrir un administrador, haga doble clic en el botón de la cinta.
Los Administradores de entidades son ventanas secundarias o dependientes del editor principal. Las ventanas secundarias tienen algunas propiedades comunes:
-
Están estrechamente relacionadas con la ventana principal: esta «conoce» los cambios producidos en la ventana secundaria, como la selección de un elemento, y viceversa.
-
Pueden redimensionarse y posicionarse de forma independiente respecto a su ventana principal.
-
Se minimizan cuando se minimiza la ventana principal y se restauran junto con ella.
-
Se cierran cuando se cierra la ventana principal.
-
Sin embargo, las ventanas secundarias NO se mueven junto con la ventana principal.
Funciones adicionales
Es posible copiar el contenido de cualquier entidad —ya sea el nombre de un documento, el nombre de un grupo, un código, el nombre de un memo o de una cita, o un nodo de una red— y pegarlo en un editor o en una red.
Si se copia el nombre de una entidad desde una lista y se pega en un editor, se pega el nombre.
Si se copia un nodo y se pega en un editor, se pega el nombre del nodo.
Si se copia el nombre de una entidad y se pega en una red, se pega como nodo. Si ya existen vínculos, se mostrarán de inmediato.
Administradores de entidades
Existe un administrador independiente para cada uno de los seis tipos de entidades: Documentos, Citas, Códigos, Memos, Redes y Vínculos. Los Administradores de entidades permiten acceder a las entidades y ofrecen diversas opciones y funciones. Dado que existen diferencias entre los distintos tipos de entidades, encontrará una sección dedicada a cada uno de los administradores.
Abrir un administrador de entidades
Para abrir, por ejemplo, el Administrador de documentos, haga doble clic en la rama principal Documentos del Explorador de proyectos, o seleccione el Administrador de documentos en el menú desplegable de Documentos de la barra de herramientas.
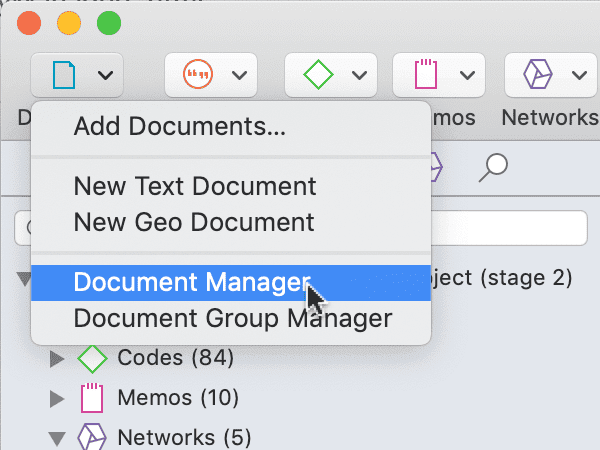
El Administrador de citas puede abrirse desde la barra de herramientas o el menú Cita.
El Administrador de vínculos para citas puede abrirse desde el menú Cita.
El Administrador de vínculos para códigos puede abrirse desde el menú Código.
Todos los administradores se abren como ventanas flotantes.
Cada administrador contiene una lista de las entidades que gestiona, junto con información detallada sobre ellas. En la parte inferior de la lista se muestra una vista previa del elemento seleccionado.
En el lateral derecho se encuentra un inspector, que proporciona más información sobre el elemento seleccionado. La parte inferior del inspector contiene el campo de comentario donde puede escribir, revisar y editar comentarios. Encontrará más información sobre cómo escribir comentarios y memos aquí.
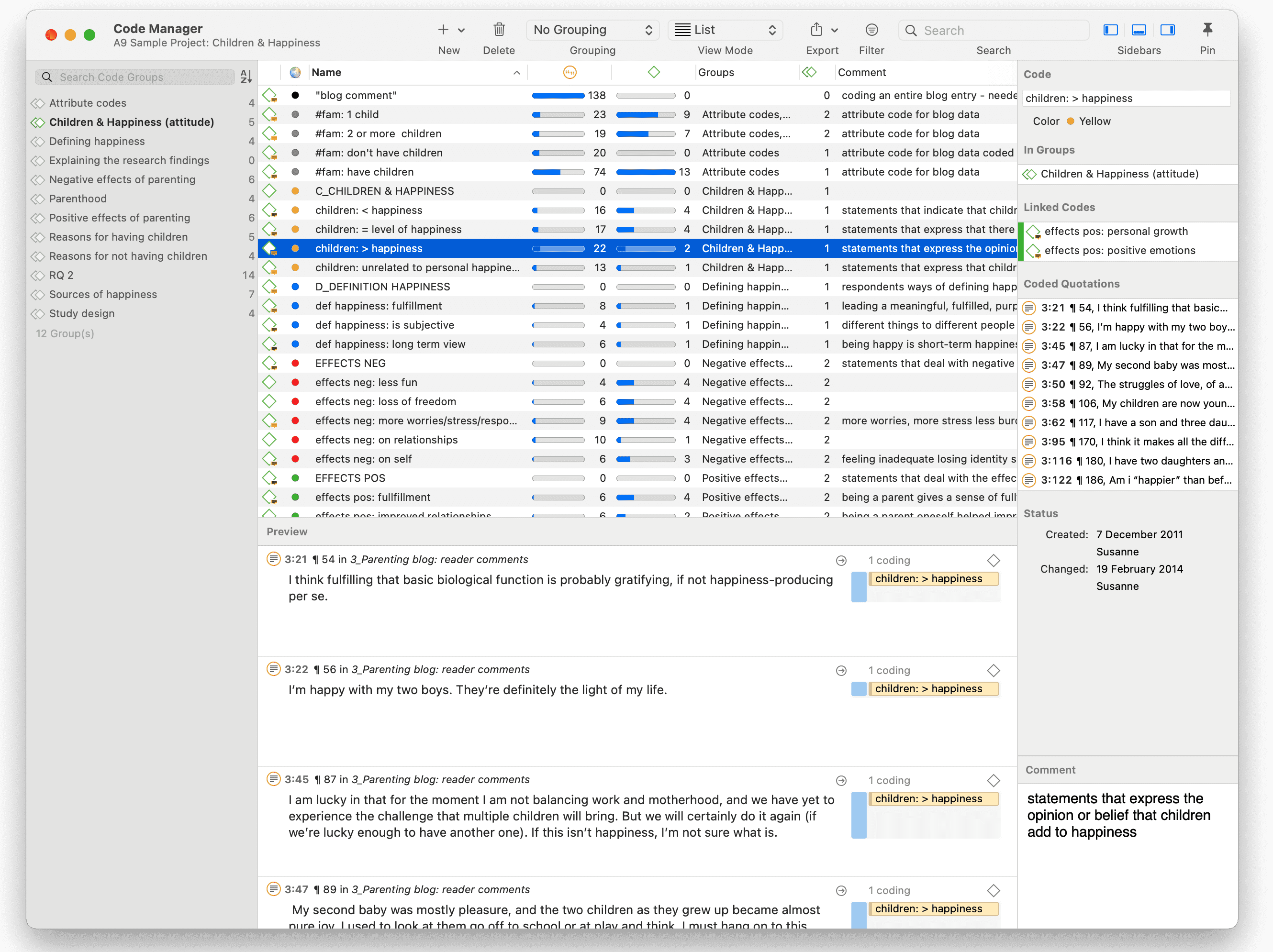
Otro elemento común es el área de filtros en el lateral izquierdo, que puede utilizarse para acceder rápidamente a los elementos enumerados en los administradores y filtrarlos mediante grupos o códigos. Proporciona acceso inmediato a actividades fundamentales como seleccionar códigos y grupos, crear grupos y grupos inteligentes, y establecer filtros locales y globales. Esto permite una integración mucho más eficaz en el flujo de trabajo y ahorra muchos movimientos de ratón y clics. Al seleccionar varias entidades, puede combinarlas con los operadores «AND» y «OR». Consulte Consultas booleanas simples en el Administrador de citas.
Todos los administradores ofrecen un botón más para agregar nuevos elementos y una papelera para eliminar uno o varios elementos seleccionados.
Seleccionar elementos en un administrador de entidades
Un clic único con el botón izquierdo del ratón selecciona y resalta un elemento en cada uno de los administradores de entidades.
Hacer doble clic en un elemento selecciona la entidad e inicia un procedimiento que depende del tipo y el estado de la entidad.
Para selecciones múltiples, puede utilizar las técnicas de selección estándar con la tecla Cmd o Mayús.
Para saltar a una entrada específica de la lista, primero seleccione un elemento y luego escriba la primera, segunda y siguientes letras de una palabra para saltar a la entrada correspondiente de la lista. Por ejemplo, si varios códigos comienzan con las dos letras «em», como en «emociones», escribir «em» saltará al primero de los códigos que comiencen por «em». Cada carácter adicional escrito avanza el foco a la siguiente entrada de la lista, a menos que no se encuentre un nombre coincidente.
Evite pausas prolongadas entre la introducción de caracteres. Tras un tiempo de espera definido por el sistema, el siguiente carácter inicia una nueva búsqueda hacia adelante.
La barra divisora
El tamaño relativo del panel lateral, la lista, la vista previa y el inspector puede modificarse arrastrando la barra divisora entre los paneles. El cursor cambia cuando el ratón se mueve sobre la barra divisora. Puede cambiar el tamaño de los paneles adyacentes arrastrando la barra divisora hasta la posición deseada.
Menús contextuales
Los paneles de lista y de texto ofrecen menús contextuales emergentes. Los menús contextuales contienen una parte de los comandos que también se encuentran en los menús.
Buscar
En la parte superior del panel lateral y de las listas de entidades, encontrará un campo de búsqueda.
Utilice el campo de búsqueda para buscar documentos, citas, códigos o memos en los administradores correspondientes.
Si introduce un término de búsqueda, en la lista se mostrarán todos los objetos que lo contengan. Por ejemplo, si introduce el término «niños» en el administrador de códigos, se mostrarán todos los códigos que incluyan la palabra «niños» en algún lugar del nombre del código.
Recuerde eliminar el término de búsqueda si desea ver todos los elementos de nuevo.
Ordenar
Los administradores de entidades permiten ordenar y filtrar de forma cómoda. Con un clic en el encabezado de una columna, todos los elementos se ordenan en orden ascendente o descendente según las entradas de la columna seleccionada.
Agrupar
Los elementos de cada administrador pueden agruparse según determinados criterios. Todos los elementos de todos los administradores pueden agruparse por usuario creador o modificador. Los códigos del administrador de códigos pueden agruparse, por ejemplo, por grupos, por documentos, o por códigos regulares e inteligentes. Los documentos pueden agruparse por tipo de documento, los hipervínculos por relación, origen o destino, y así sucesivamente.
Filtrar
Todos los administradores tienen una opción de filtro (véase el icono de filtro en la barra de herramientas). Un filtro puede ser tan sencillo como filtrar todos los elementos con comentario, o tan complejo como buscar todas las citas codificadas con CódigoA que coocurran con CódigoB anidado en CódigoC. En la sección sobre consulta de datos en el Administrador de citas se explica cómo construir una consulta.
El Administrador de documentos
El Administrador de documentos le ayuda a organizar sus datos, agrupar documentos o filtrarlos.
Inspector: En el inspector de la derecha, puede cambiar el nombre del documento, escribir un comentario para el documento (Trabajar con comentarios y memos), y ver a qué grupos de documentos está asignado el documento. Además, puede revisar la fecha de creación y modificación.
Filtro
Haga clic en uno o más grupos de documentos en el área de filtro de la izquierda para establecer un filtro local. Esto significa que solo se filtran los elementos del administrador.
Si desea filtrar todo el proyecto, haga clic derecho en un grupo de documentos para establecer un filtro global. Consulte Aplicar filtros globales para el análisis de datos.
Barra de herramientas del Administrador de documentos

De izquierda a derecha:
Nuevo: Agrega un nuevo documento a su proyecto. Consulte Agregar documentos.
Eliminar elimina el/los documento(s) seleccionado(s) del proyecto. Esta es una eliminación permanente. También significa que se elimina toda la codificación realizada en el/los documento(s). Puede revertir la acción usando Deshacer, pero solo dentro de la sesión activa actual.
Agrupación: Puede ver la lista de documentos de diferentes formas. Puede agruparlos por códigos, grupos de códigos, grupos de documentos, tipo de documento o usuario creador/modificador:
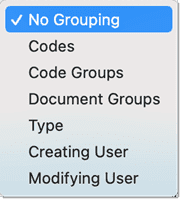
Debajo verá un Administrador de documentos donde la lista de documentos está agrupada por grupos de documentos:
En Modo de vista, puede cambiar entre la vista de lista (predeterminada) y la vista de mapa de árbol.
A continuación se muestra un ejemplo de cómo aparece la vista de mapa de árbol:
Exportar: Tiene la opción de exportar una hoja de cálculo para Numbers o Excel, o un informe como archivo de texto (Word, PDF). Los informes de texto son personalizables. Consulte Crear informes. Mediante la opción de hoja de cálculo obtiene un informe WYSIWYG del administrador. Puede excluir columnas haciendo clic en cualquiera de los encabezados de columna y seleccionando lo que debe incluirse en el informe.
Filtrar: Mediante el filtro, puede consultar sus documentos de diversas formas. Para más detalles consulte Operadores disponibles para consultas. Para más información sobre cómo crear consultas, consulte Consultar datos en el Administrador de citas.
Exportar: Los informes pueden crearse como archivo de texto (Word, PDF), hoja de cálculo o imagen. Consulte Crear informes.
Diseño: En Diseño, tiene opciones para activar o desactivar grupos e inspector. En vista previa, puede cambiar entre ver la vista previa del documento o los gráficos. Si hace clic en el 'pin' (Siempre visible), la ventana permanece en primer plano.
Organización de documentos en carpetas
Los documentos pueden organizarse en carpetas. Las carpetas pueden estar dentro de otras carpetas. Puede haber proyectos que requieran diferentes niveles de organización de documentos. A continuación se muestra un ejemplo con tres niveles:
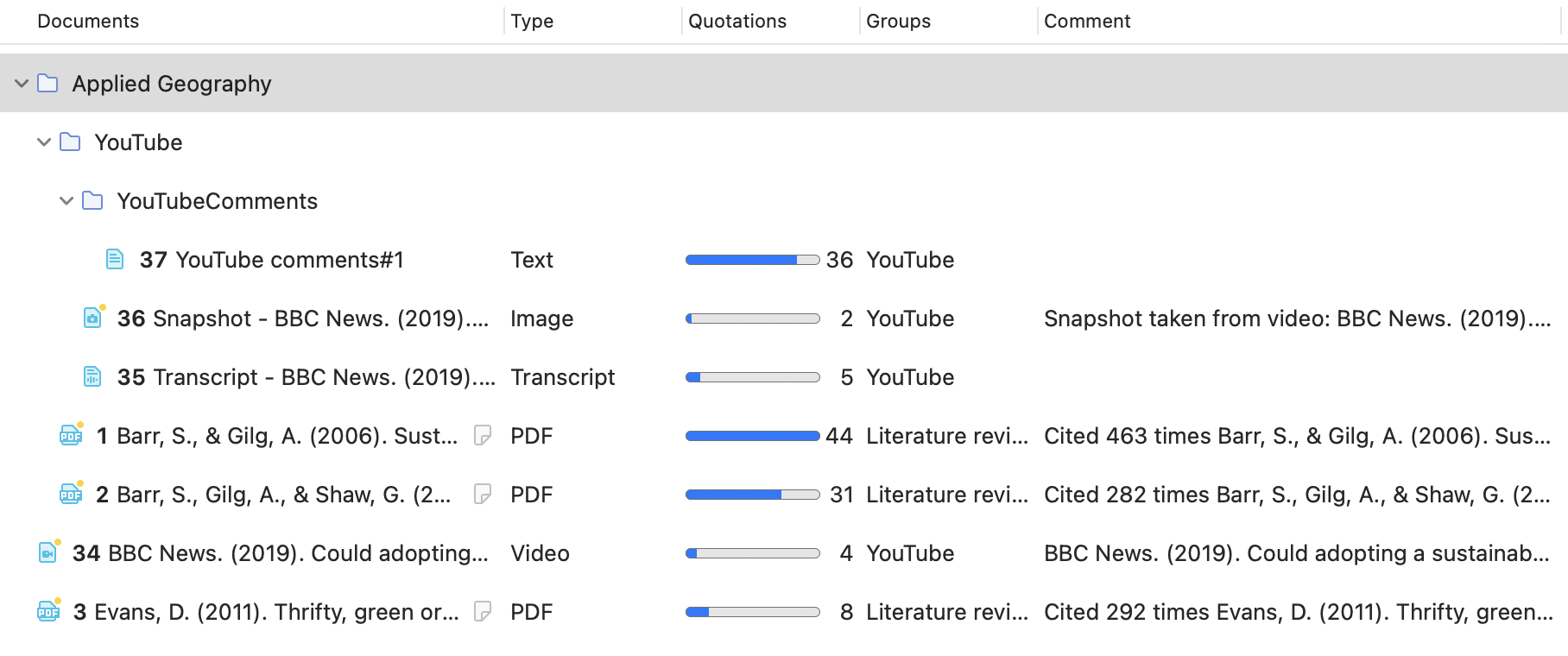
A diferencia de los grupos, un documento no puede estar en más de una carpeta. La estructura de carpetas es jerárquica; los grupos no.
Cómo crear carpetas
Seleccione uno o más documentos, haga clic derecho y seleccione la opción Nueva carpeta desde la selección del menú contextual.
Si elimina una carpeta, todo el contenido de la carpeta también se elimina.
Administrador de citas
El Administrador de citas puede utilizarse para recuperar y revisar datos por códigos, crear códigos inteligentes, escribir comentarios, crear informes o abrir redes. Al trabajar con datos multimedia y geodatos, resulta útil renombrar las citas con títulos para segmentos de audio o video, o con nombres de ubicación para geodatos. Consulte Trabajar con citas.
Referencia de cita
ID: El ID consta de dos números, lo que se explica mejor con un ejemplo: un ID 3:10 significa que la cita proviene del documento 3 y es la décima cita creada en ese documento. Las citas se numeran en orden cronológico y no en orden secuencial.
Referencia: La referencia indica la ubicación de la cita en el documento, por ejemplo, párrafo 12 - 13. Para documentos de audio y video, la referencia indica la posición de inicio en h:m:s. Para citas geográficas, se proporciona la geolocalización.
Agregar nombres a las citas
Nombre: El campo de nombre está inicialmente vacío. Puede introducir un nombre para cada cita, por ejemplo, para añadir un título, una descripción para una cita de imagen o una geolocalización. Consulte también Trabajar con citas.
Comportamiento de selección
Un clic único selecciona una cita. Si ha escrito un comentario para la cita seleccionada, este se muestra en la parte inferior de la ventana.
Un doble clic en una cita carga su documento (si no está ya cargado) y muestra su contenido en contexto.
Selección múltiple: Puede seleccionar más de una cita a la vez, ya sea para eliminarlas, adjuntar códigos, abrir una red sobre ellas o crear resultados.
Arrastrar y soltar
Al arrastrar una o más citas sobre otras citas, se crean hipervínculos. Consulte Trabajar con hipervínculos para obtener más información.
Filtro
Haga clic en uno o más códigos en el área de filtros de la izquierda para ver solo las citas vinculadas al(los) código(s) seleccionado(s).
Barra de herramientas del Administrador de citas

Nuevo: Agregar un nuevo documento al proyecto. Consulte Agregar documentos.
Eliminar: Quita la(s) cita(s) seleccionada(s) del proyecto. Esta es una eliminación permanente. Puede revertir la acción mediante Deshacer, pero solo durante la sesión activa actual.
Agrupación: Puede ver la lista de citas de distintas formas. Puede agruparlas por códigos, grupos de códigos, documentos, grupos de documentos, tipo de documento o usuario creador o modificador.
Modo de vista: Puede cambiar entre Detalles, Vista previa pequeña, Vista previa grande y Mostrar margen.
Exportar: Tiene la opción de exportar una hoja de cálculo para Numbers o Excel, o un informe como archivo de texto (Word, PDF). Los informes de texto son personalizables. Consulte Crear informes. Mediante la opción de hoja de cálculo, obtiene un informe WYSIWYG del administrador. Puede excluir columnas haciendo clic en cualquiera de los encabezados de columna y seleccionando qué debe incluirse en el informe.
Filtro: Mediante el filtro, puede consultar sus datos. Puede buscar citas basándose en códigos y en su ubicación en documentos o grupos de documentos. Además, también puede buscar texto dentro de las citas y combinar esto con una consulta de código. Para obtener más detalles, consulte Consultar datos en el Administrador de citas.
Buscar: Introduzca algunas letras en el campo de búsqueda y ATLAS.ti buscará todas las citas que contengan la secuencia de letras introducida.
Diseño: En el diseño, tiene opciones para activar o desactivar códigos, vista previa e inspector. Si hace clic en el «pin» (Siempre en primer plano), la ventana permanece en primer plano.
Administrador de códigos
El Administrador de códigos se utiliza con frecuencia para:
- crear y modificar códigos
- codificar segmentos de datos mediante arrastrar y soltar
- establecer colores de código
- recuperar segmentos de datos codificados
- organizarlos en grupos de códigos
- fusionar y dividir códigos
- filtrarlos
- revisarlos en redes
- revisar su contenido mediante nubes de palabras, listas de palabras y mapas de árbol
- crear informes.
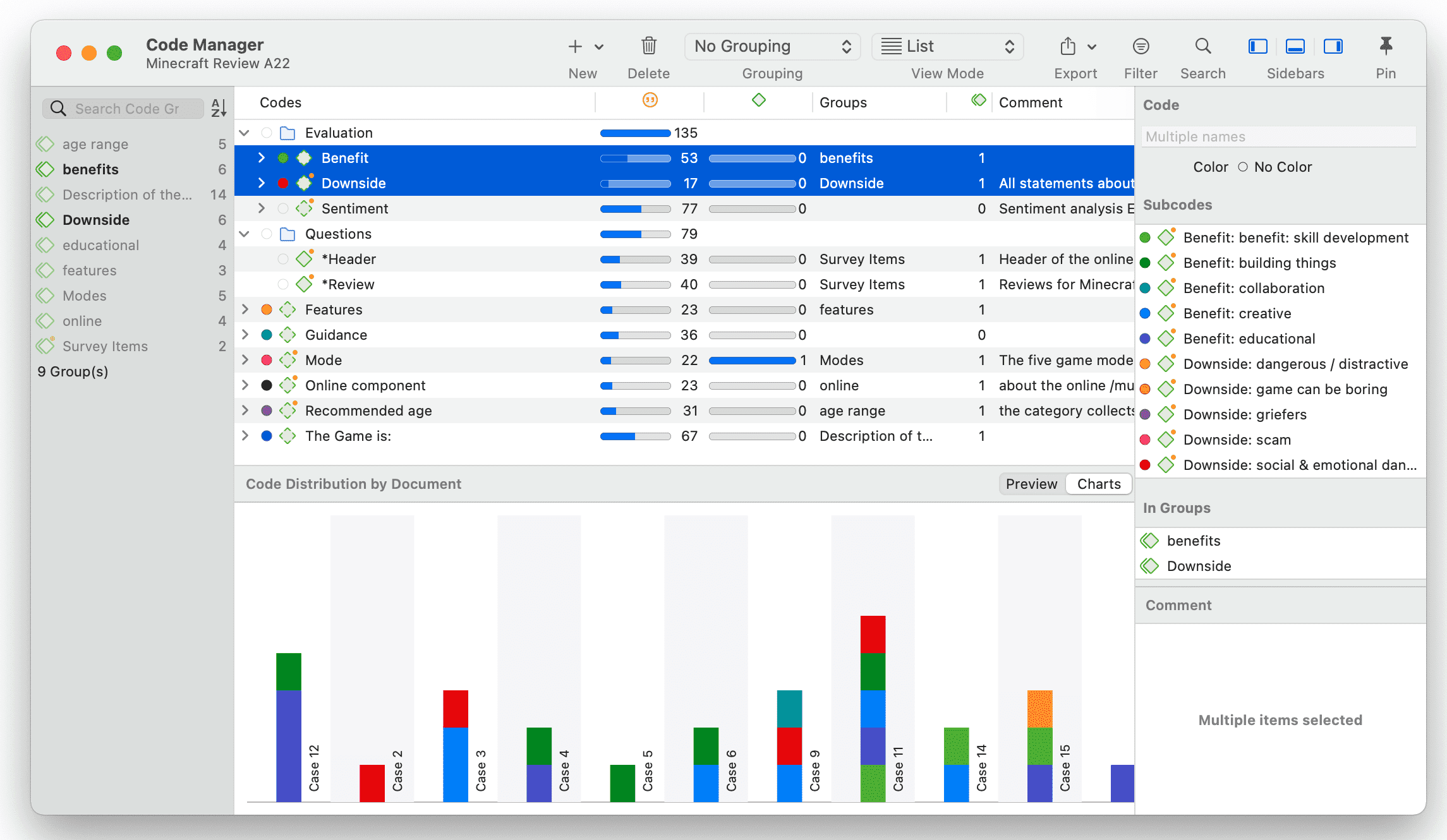
En el panel inferior, debajo de la lista de códigos, puede ver una vista previa de citas para un código seleccionado o un gráfico. Para obtener más información sobre el gráfico, consulte Distribución de códigos en documentos.
Para cambiar entre la vista previa de citas y la vista de gráfico, seleccione Vista previa o Gráficos en el control segmentado de la esquina superior derecha del panel inferior.
Información útil
Enraizamiento: Frecuencia o enraizamiento del código. Muestra cuántas citas están vinculadas a un código.
Densidad: Número de vínculos con otros códigos. Consulte Vincular nodos.
Colores: Si agrega colores a los códigos, se mostrará un círculo de color delante del icono y el nombre del código. Los colores de los códigos también afectan a la visualización de los nodos de código en las redes. Consulte Trabajar con redes.
Si no desea ver todas las columnas, haga clic derecho en el encabezado de una columna y deseleccione las que no quiera ver.
Comportamiento de selección
Un doble clic en un código abre la lista de citas vinculadas en el Lector de citas. Puede navegar por la lista de citas y verlas resaltadas en el contexto de su documento. Si solo hay una cita vinculada a un código, esta se resaltará inmediatamente en el contexto de su documento.
Clic único: Selecciona un código. Si ha escrito una definición para el código seleccionado, esta se muestra en el panel de comentarios del inspector a la derecha. Una vez seleccionado, el código puede utilizarse para codificar mediante arrastrar y soltar, o puede agregarlo a un grupo de códigos también mediante arrastrar y soltar.
Selección múltiple: Puede seleccionar más de un código a la vez manteniendo pulsada la tecla Ctrl o Mayús. Esto resulta útil para:
- eliminar varios códigos
- codificar un segmento de datos con varios códigos
- abrir una red que incluya todos los códigos seleccionados
- crear informes basados en los códigos seleccionados
- asignar varios códigos a un grupo de códigos o quitarlos de un grupo
- crear un nuevo grupo de códigos basado en los códigos seleccionados
Arrastrar y soltar
Puede utilizar el Administrador de códigos como herramienta conveniente para codificar arrastrando códigos sobre un fragmento de datos resaltado. Si arrastra códigos sobre otro código dentro del mismo panel de lista, se crearán vínculos entre códigos. Si arrastra un código sobre otro código en el área del margen, este será reemplazado.
Filtro
Haga clic en uno o más grupos de códigos en el área de filtros de la izquierda para establecer un filtro local. Esto significa que solo se filtran los elementos del administrador. Si desea filtrar todo su proyecto, deberá establecer un filtro global. Consulte Aplicar filtros globales para el análisis de datos.
Barra de herramientas del Administrador de códigos

De izquierda a derecha:
Nuevo: Agregar un nuevo código, código inteligente, carpeta de códigos, grupo de códigos o grupo de códigos inteligente al proyecto.
Eliminar: Quita el(los) código(s) seleccionado(s) del proyecto. Esta es una eliminación permanente. Puede revertir la acción mediante Deshacer, pero solo durante la sesión activa actual.
Agrupación: Puede ver la lista de códigos de distintas formas. Puede agruparlos por grupos de códigos, códigos inteligentes, documentos, grupos de documentos, o usuario creador o modificador.
Modo de vista: Puede ver los códigos como lista (predeterminado), gráfico de barras, nube de códigos o mapa de árbol:
Lista de códigos como gráfico de barras
Seleccione el elemento de menú Gráfico de barras para visualizar la lista de códigos como gráfico de barras:
Lista de códigos como nube
Seleccione el elemento de menú Nube para visualizar la lista de códigos como nube de palabras:

Lista de códigos como mapa de árbol
Seleccione el elemento de menú Mapa de árbol para visualizar la lista de códigos como mapa de árbol:
Al hacer clic derecho en un código en las vistas de gráfico de barras, nube o mapa de árbol, se abre el mismo menú contextual que en la vista de lista. Esto permite realizar las mismas acciones, por ejemplo, renombrar códigos, establecer un color, dividir códigos, o abrir una red con uno o varios códigos.
Exportar
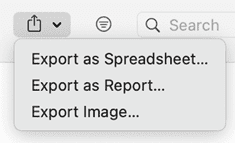
-
Puede exportar la lista de códigos como hoja de cálculo para Numbers o Excel. Al exportar una hoja de cálculo, obtiene un informe WYSIWYG del administrador. Puede excluir columnas haciendo clic en cualquiera de los encabezados de columna y seleccionando qué debe incluirse en el informe.

-
Otra opción es crear un informe personalizable como archivo de texto (consulte Crear informes).
-
Las vistas de nube y gráfico de barras pueden exportarse como imagen en formato PNG.
-
También puede exportar un libro de códigos en formato XLSX o QDC.
Filtro
Mediante el filtro, puede consultar sus códigos. Por ejemplo, puede buscar códigos creados por un usuario concreto, buscar códigos con comentarios o buscar códigos vinculados con otros códigos. Para obtener más detalles sobre cómo construir una consulta, consulte Consultar datos en el Administrador de citas.
Buscar
Introduzca algunas letras en el campo de búsqueda y ATLAS.ti buscará todos los códigos que contengan esa secuencia de letras.
Diseño
En el diseño, tiene opciones para activar o desactivar códigos, vista previa e inspector. Si hace clic en el pin (Siempre en primer plano), la ventana permanece en primer plano.
Administrador de memos
El Administrador de memos se utiliza para llevar un registro de su escritura. Puede crear, leer y revisar, comentar, ordenar y organizar, y agrupar sus memos. Otras opciones son ver un memo y su conexión en una red, o convertir un memo en un documento para su posterior análisis.
Enraizamiento: Número de citas a las que está conectado un memo.
Densidad: Número de códigos y otros memos a los que está conectado el memo.
Doble clic abre el editor de memos como ventana flotante. Esta ventana puede acoplarse a la región activa actual.
Ctrl + Clic abre el menú contextual, que permite abrir la lista de citas vinculadas a un memo (entre otras opciones).
Arrastrar y soltar
Puede adjuntar un memo a una cita arrastrándolo sobre la cita en el documento o en el área al margen.
Un memo también puede arrastrarse a una cita, código u otro memo en el Explorador de proyectos o en cualquier otra lista. A la inversa, también puede arrastrar citas, códigos o memos desde cualquier lista o desde el área al margen a un memo para vincularlo.
Filtro
Haga clic en uno o más grupos de memos en el área de filtro de la izquierda para establecer un filtro local. Esto significa que solo se filtran los elementos del administrador.
Organización de memos en carpetas
Los memos pueden organizarse en carpetas. Las carpetas pueden estar dentro de otras carpetas. Puede haber proyectos que requieran diferentes niveles de organización de memos. A continuación se muestra un ejemplo con tres niveles:
A diferencia de los grupos, un memo no puede estar en más de una carpeta. La estructura de carpetas es jerárquica; los grupos no.
Cómo crear carpetas
Seleccione uno o más memos, haga clic derecho y seleccione la opción Nueva carpeta desde la selección del menú contextual.
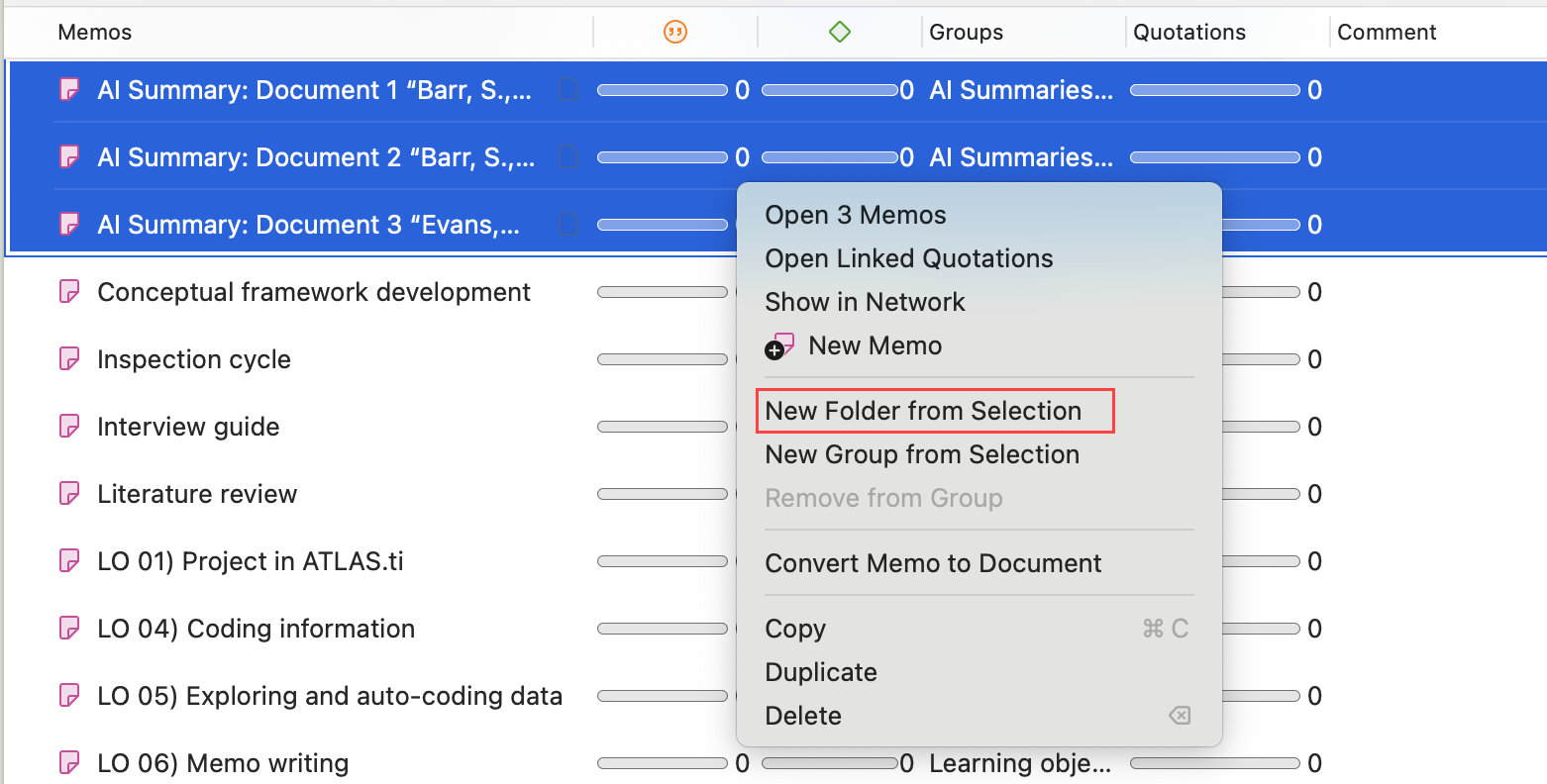
Si elimina una carpeta, todo el contenido de la carpeta también se elimina.
Administrador de redes
El Administrador de redes se utiliza frecuentemente para crear y abrir redes, renombrarlas, comentarlas y agruparlas.
Organización de redes en carpetas
Las redes pueden organizarse en carpetas. Las carpetas pueden estar dentro de otras carpetas. Puede haber proyectos que requieran diferentes niveles de organización de redes. A continuación se muestra un ejemplo con tres niveles:
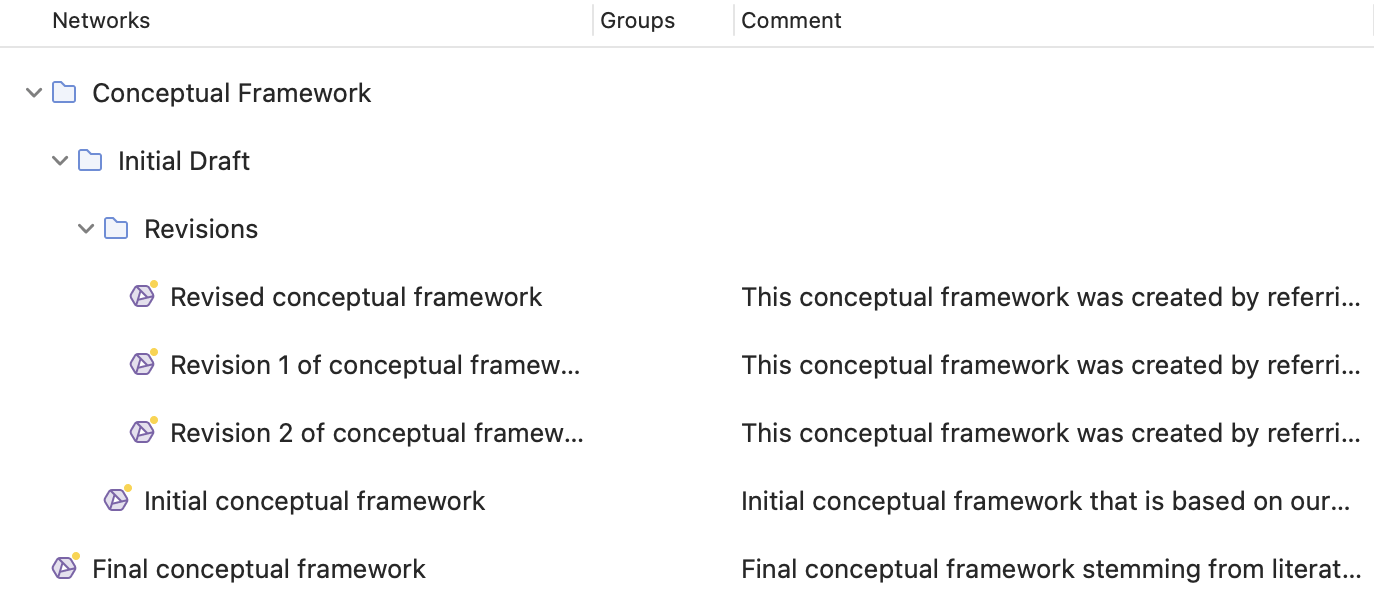
A diferencia de los grupos, una red no puede estar en más de una carpeta. La estructura de carpetas es jerárquica; los grupos no.
Cómo crear carpetas
Seleccione una o más redes, haga clic derecho y seleccione la opción Nueva carpeta desde la selección del menú contextual.
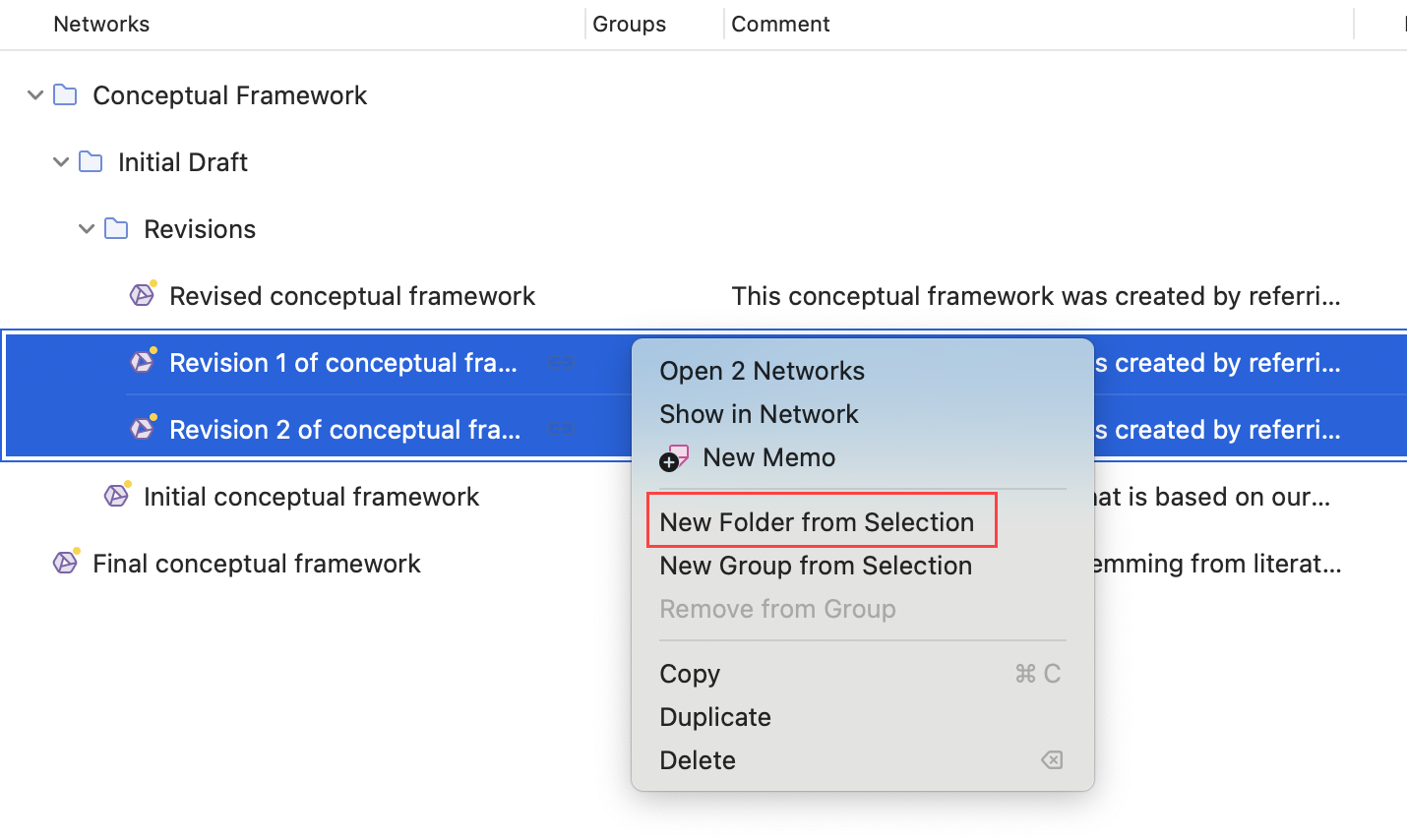
Si elimina una carpeta, todo el contenido de la carpeta también se elimina.
Administrador de relaciones
El Administrador de relaciones se utiliza para revisar las propiedades de las relaciones existentes, editar relaciones existentes o crear nuevas relaciones. Puede cambiar entre las relaciones para vínculos código-código y las relaciones para hipervínculos. Como la información de las columnas y las opciones de la cinta son las mismas para ambos, a continuación encontrará una única descripción. Para obtener más información, consulte Trabajar con redes.
Puede acceder al Administrador de relaciones para códigos a través del menú Código, y al Administrador de relaciones para hipervínculos a través del menú Cita.
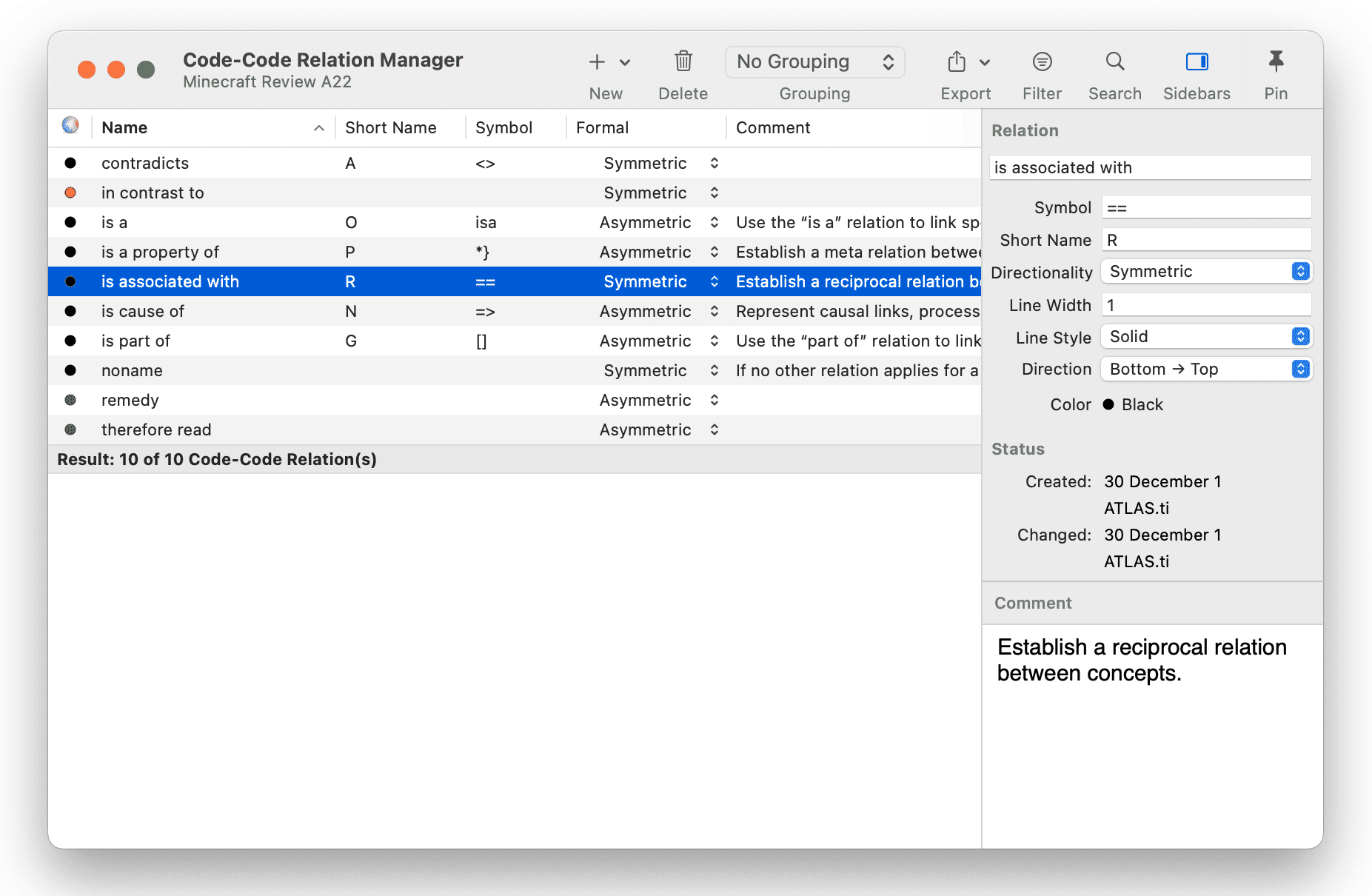
Nombre: Puede mostrar el nombre completo, el nombre abreviado o el nombre simbólico de todas las relaciones en una red.
Formal: La propiedad formal de una relación: simétrica, asimétrica o transitiva. Consulte Acerca de las relaciones.
Comentario: Descripción breve del tipo de relación.
Para obtener más información, consulte Crear nuevas relaciones.
Administrador de vínculos
El Administrador de vínculos lista todos los vínculos código-código existentes y todos los hipervínculos existentes (vínculos entre dos citas). Se utiliza con frecuencia para revisar, modificar o comentar estos vínculos. Puede cambiar entre la vista de la lista de vínculos código-código y la lista de hipervínculos.
Columnas del Administrador de vínculos para vínculos código-código
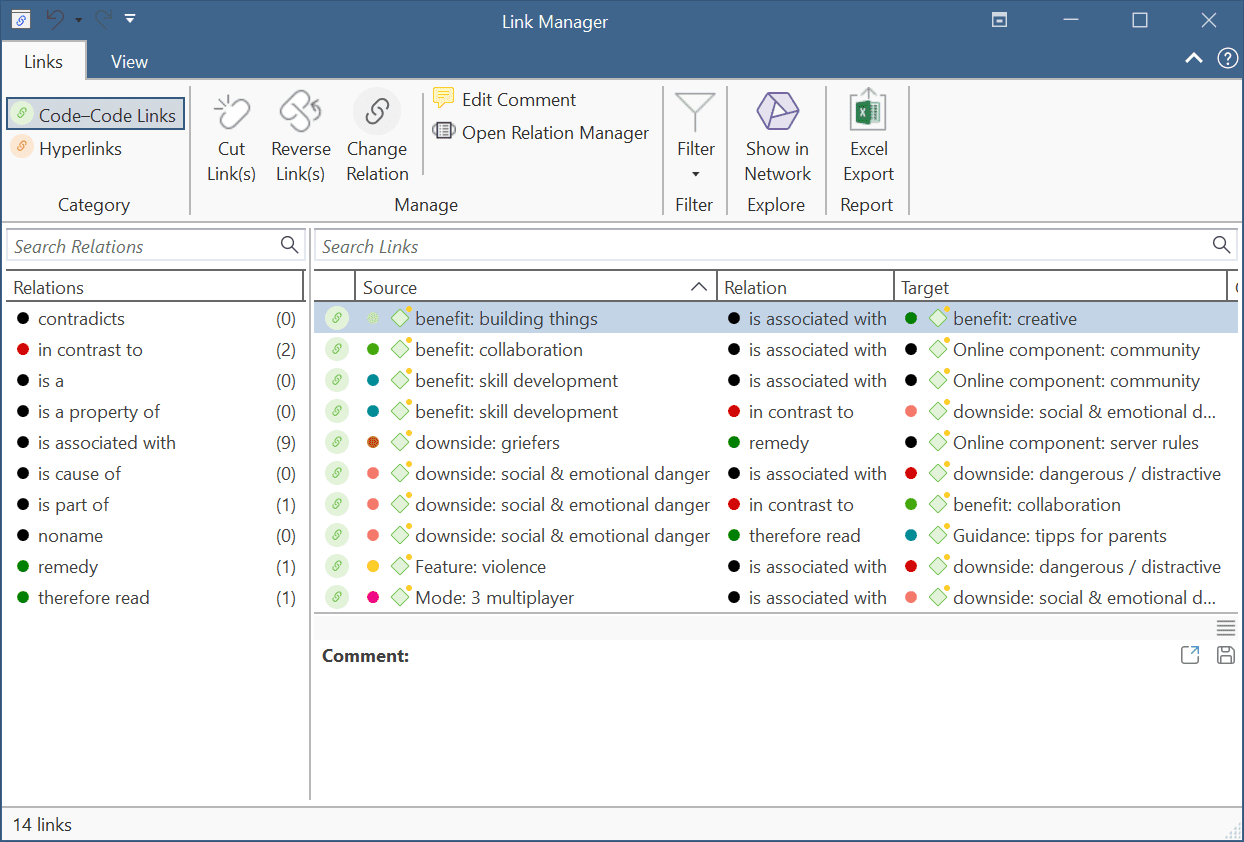
La información proporcionada para cada vínculo código-código consiste en:
Origen: La posición de inicio de un vínculo. Esto es relevante para los vínculos dirigidos (asimétricos y transitivos).
Relación: Las relaciones pueden utilizarse para nombrar un vínculo. Esto es posible para los vínculos código-código y para los vínculos entre citas (hipervínculos). Consulte la sección sobre Trabajar con redes para obtener más detalles.
Destino: La posición final de un vínculo.
Creado por: El nombre del usuario que creó el vínculo.
Modificado por: El nombre del usuario que modificó el vínculo.
Creado / Modificado: Fecha y hora en que se creó y modificó el vínculo.
En el panel lateral izquierdo se puede ver la lista de todas las relaciones disponibles y cuántas veces se han utilizado (número entre paréntesis). Haga clic en una o más relaciones en el panel lateral para filtrar la lista de vínculos.
Columnas del Administrador de vínculos para hipervínculos
La información proporcionada para cada hipervínculo consiste en:
Origen: La posición de inicio de un hipervínculo. Esto es relevante para los vínculos dirigidos (asimétricos y transitivos).
Relación: Las relaciones pueden utilizarse para nombrar un hipervínculo. Consulte la sección sobre Trabajar con hipervínculos para obtener más detalles.
Destino: La posición final de un hipervínculo.
Creado por: El nombre del usuario que creó el hipervínculo.
Modificado por: El nombre del usuario que modificó el hipervínculo.
Creado / Modificado: Fecha y hora en que se creó y modificó el hipervínculo.
En el panel lateral izquierdo se puede ver la lista de todas las relaciones disponibles para hipervínculos y cuántas veces se han utilizado (es decir, número entre paréntesis). Si hace clic en una o más relaciones, todos los hipervínculos se filtrarán por las relaciones seleccionadas.
Cinta del Administrador de vínculos
La cinta es la misma para los vínculos código-código y los hipervínculos.
De izquierda a derecha:
Cortar vínculo(s): Corta el vínculo entre los códigos o citas seleccionados.
Invertir vínculo(s): Cambia el origen y el destino del vínculo seleccionado.
Cambiar relación: Cambia la relación de un vínculo seleccionado.
Editar comentario: Abre un editor de texto para escribir o editar un comentario para un vínculo seleccionado.
Abrir Administrador de relaciones: Puede acceder al Administrador de relaciones desde aquí si desea crear o modificar una relación. Consulte Crear nuevas relaciones.
Filtro: Puede filtrar los vínculos seleccionando una relación en el área de filtros de la izquierda. El botón Filtro en la cinta ofrece algunas opciones adicionales: puede invertir el filtro o filtrar por vínculos creados hoy, creados esta semana, creados por usted, o por todos los vínculos que tengan un comentario.
Abrir red: Abre una red con el(los) vínculo(s) seleccionado(s). Consulte Abrir red ad hoc.
Exportar a Excel: Puede exportar la información que ve en el administrador como tabla de Excel.
Pestaña Vista
Como la pestaña Vista es la misma en todos los administradores, se describe aquí: Administrador de entidades.
Formatos de archivo admitidos
En principio, ATLAS.ti admite la mayoría de los formatos textuales, gráficos y multimedia. Para algunos formatos, su compatibilidad depende del estado del sistema Windows. Antes de decidir usar un formato de datos poco común, debe verificar si dicho formato está disponible y si su sistema Windows lo admite correctamente.
Documentos textuales
Se admiten los siguientes formatos de archivo:
| Formato | Tipo de archivo |
|---|---|
| MS Word | .doc; .docx; .rtf |
| Open Office | .odt |
| HyperText Markup Language | .htm; .html |
| Texto sin formato | .txt |
| Otro | .ooxml |
Los documentos de texto pueden editarse en ATLAS.ti. Esto es útil para corregir errores de transcripción, cambiar el formato o agregar información faltante. Al agregar un documento de texto vacío a un proyecto de ATLAS.ti, también puede transcribir sus datos directamente en ATLAS.ti. Sin embargo, se recomienda usar una herramienta de transcripción dedicada o utilizar transcripciones automáticas. Puede agregar transcripciones con marcas de tiempo y sincronizarlas con el archivo de audio o vídeo original. Para ello, utilice Transcripciones multimedia.
Transcripciones
ATLAS.ti es compatible con prácticamente todas las aplicaciones y servicios de transcripción, y también permite transcribir dentro de ATLAS.ti o importar transcripciones escritas por el usuario.
Además, ATLAS.ti incluye transcripción con tecnología de IA, que permite transcribir archivos de audio y vídeo automáticamente dentro de la plataforma. Tenga en cuenta que los minutos de transcripción con IA no están incluidos en la versión de prueba, pero los minutos adquiridos sí pueden utilizarse durante la prueba.
Consulte Transcripción para obtener más información.
Archivos PDF (texto y gráficos)
Los archivos PDF son perfectos cuando se necesita conservar el diseño original. Cuando se creó el formato PDF, su objetivo era preservar el mismo diseño tanto en pantalla como en impresión.
Si el archivo PDF tiene anotaciones, estas se muestran en ATLAS.ti. Sin embargo, no pueden editarse.
Al preparar archivos PDF, debe asegurarse de que se trate de un PDF de texto y no de imagen. Si utiliza este último, ATLAS.ti lo tratará como un archivo gráfico y no podrá buscarlo ni recuperar texto.
Al escanear un texto desde papel, es necesario usar software de reconocimiento de caracteres (OCR, que suele incluirse con el escáner) para crear un archivo PDF de texto. Otra opción es aplicar el reconocimiento de caracteres en el software lector/escritor de PDF.
Cuando recupera texto de un segmento PDF codificado, el resultado será texto enriquecido. Por lo tanto, puede perder el diseño original. Esto se debe a la naturaleza del formato PDF mencionada anteriormente: es un formato de diseño y no está pensado para el procesamiento de texto.
PDF con anotaciones / Archivos Word con comentarios
Si ha hecho anotaciones en archivos Word o PDF, ATLAS.ti convertirá el área resaltada en una cita. El texto de la anotación se agregará como comentario a la cita.
Si agregó dibujos o comentarios manuscritos, estos se importarán como citas de imagen (en ATLAS.ti Windows, actualmente solo se admite para documentos PDF).
-
Los comentarios importados de Word se codificarán con el código Comentarios importados.
-
Los comentarios importados de documentos PDF se codificarán con el código Anotaciones importadas.
Documentos PDF con anotaciones importados en ATLAS.ti


Documento Word con comentarios
Quizás primero leyó una transcripción en Word y escribió ideas iniciales de codificación como comentarios en el margen. Si agrega esta transcripción a ATLAS.ti, todos los segmentos comentados ya estarán marcados como citas.
Si selecciona una cita, puede leer el comentario que escribió en el inspector del lado derecho. A partir de sus comentarios, puede comenzar con su trabajo de codificación. Revise cada cita, abra la herramienta de codificación y cree nuevos códigos o aplique los existentes.
Otra opción es preparar una tabla Excel basada en los comentarios escritos e importarla como lista de códigos inicial. Consulte Importar un libro de códigos.
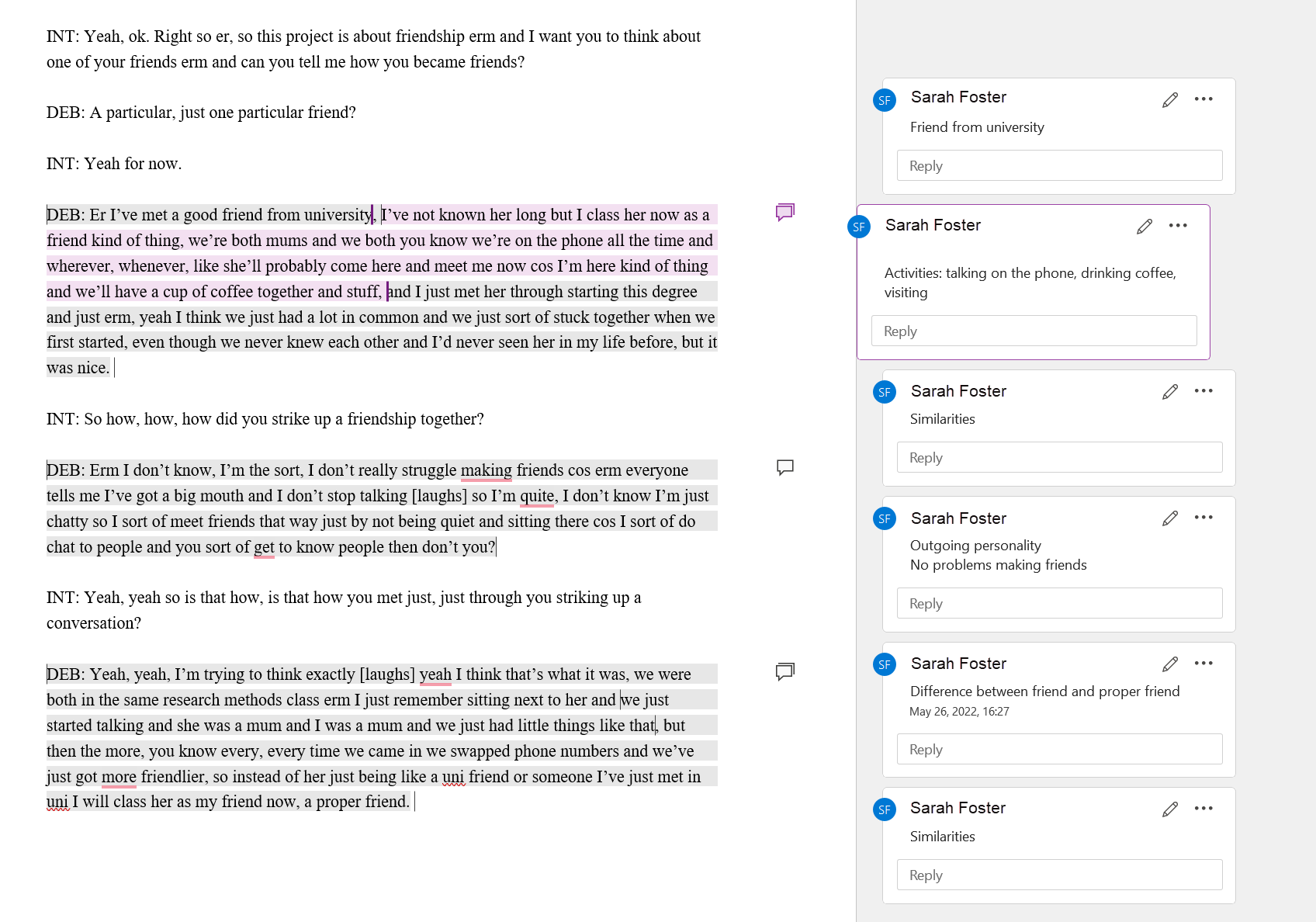
En la imagen siguiente puede ver cómo se ve este documento al importarlo en ATLAS.ti:
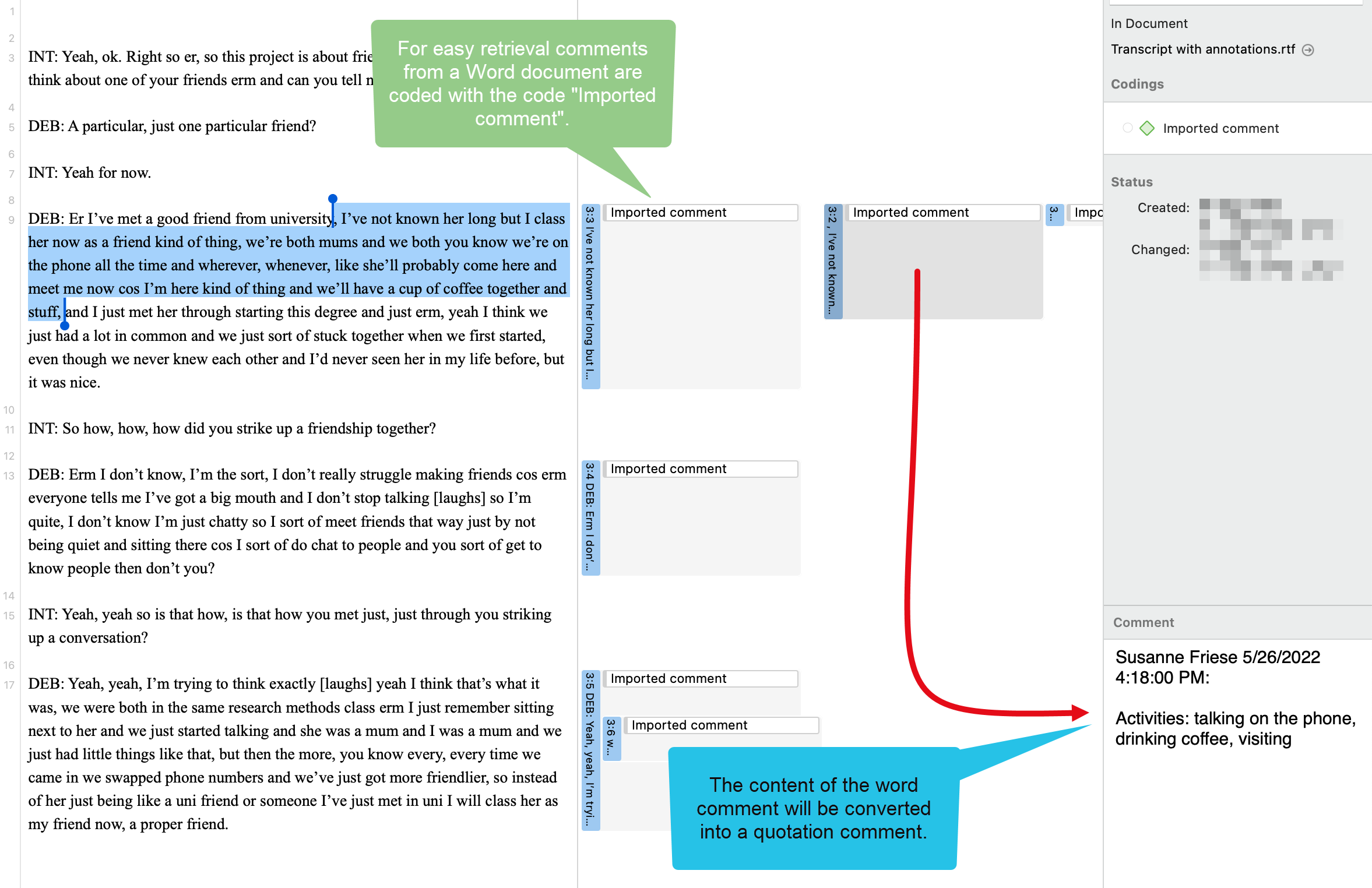
Archivos PDF (libros electrónicos, PowerPoint, hojas de cálculo, Visio, Draw)
Los siguientes tipos de archivo se convertirán en archivos PDF al agregarlos a un proyecto de ATLAS.ti:
- Libros electrónicos (.mobi)
- Hojas de cálculo Excel (.xls y .xlsx) y LibreOffice Calc (.ods)
- PowerPoint (.ppt y .pptx)
- Presentaciones LibreOffice Impress (.odp)
- Documentos Visio (.vsd y .vsdx) y LibreOffice Draw (.odg)
Imágenes
Los formatos de archivo gráfico admitidos son: bmp, gif, jpeg, jpg, png, tif y tiff.
Recomendación de tamaño: Las cámaras digitales y los escáneres suelen crear imágenes con una resolución que supera significativamente la resolución de la pantalla. Al preparar un archivo gráfico para su uso con ATLAS.ti, utilice software de procesamiento de imágenes para reducir el tamaño de manera que los gráficos se muestren cómodamente en la pantalla del equipo. ATLAS.ti redimensiona las imágenes si son demasiado grandes, pero esto requiere recursos informáticos adicionales y ocupa espacio innecesario en el disco duro.
Para redimensionar una imagen manualmente, puede usar la función de zoom mediante la rueda del ratón o el botón de zoom en ATLAS.ti.
Documentos de audio y vídeo
Los formatos de archivo de audio admitidos son: aac, m4a, mp3, mp4.
Los formatos de archivo de vídeo admitidos son: avi, m4v, mov, mp4.
Para archivos de audio, se recomienda usar archivos *.mp3 con audio AAC, y para archivos de vídeo, archivos *.mp4 con audio AAC y vídeo H.264. Estos pueden reproducirse tanto en la versión para Windows como en la versión para Mac.
Dado que los archivos de vídeo pueden ser bastante grandes, se recomienda vincular los archivos de vídeo a un proyecto de ATLAS.ti en lugar de importarlos. Consulte Agregar documentos para obtener más información.
Documentos geográficos
Cuando desee trabajar con datos geográficos, solo necesita agregar un nuevo documento geográfico a su proyecto de ATLAS.ti. Esto abre Apple Maps.
Para navegar a una región o ubicación específica en el mapa, introduzca una dirección o nombre de lugar en el campo de búsqueda. Para obtener más información, consulte Trabajar con documentos geográficos.
Comentarios de redes sociales
ATLAS.ti importa archivos Excel generados por exportcomments.com. Puede usar el servicio de forma gratuita para exportar hasta 100 comentarios por enlace. Por una pequeña tarifa, puede usar el servicio durante tres días para descargar los datos que necesita. Esto también permite exportar comentarios anidados.
Las redes sociales admitidas son:
- YouTube
- TikTok
- VK
- Twitch
- Discord
Para obtener más información, consulte Importar datos de redes sociales.
Datos de encuestas
La opción de importación de encuestas permite importar datos mediante una hoja de cálculo Excel (archivos .xls o .xlsx). Su principal finalidad es apoyar el análisis de preguntas abiertas. Sin embargo, esta opción también puede usarse para otros datos basados en casos que puedan prepararse fácilmente en forma de tabla Excel.
Además de las respuestas a las preguntas abiertas, también pueden importarse atributos de datos (variables). Estos se convertirán en grupos de documentos en ATLAS.ti. Para obtener más información, consulte Trabajar con datos de encuestas.
Datos de gestor de referencias
Para facilitar la revisión de literatura con ATLAS.ti, puede importar artículos desde gestores de referencias. El requisito es usar un gestor de referencias que pueda exportar datos en formato XML de Endnote, como Endnote, Mendeley, Zotero o Reference Manager.
Si su gestor de referencias no puede exportar datos en formato XML de Endnote, puede exportar datos en formato RIS o BIB y usar la versión gratuita de Mendeley o Zotero para generar el resultado en XML para ATLAS.ti.
Consulte Trabajar con datos de gestor de referencias.
Agregar documentos
Tutorial en video: Crear un proyecto y agregar datos.
Qué ocurre al agregar documentos a un proyecto
Todos los documentos que se agregan a un proyecto se copian, y las copias pasan a ser archivos internos de ATLAS.ti. Esto significa, en sentido estricto, que ATLAS.ti ya no necesita los archivos originales. Sin embargo, se recomienda encarecidamente conservar una copia de seguridad de los archivos fuente originales.
Dado que los archivos de audio y video pueden ser bastante voluminosos, existe la opción de crear una referencia externa a los archivos. Esto significa que los documentos multimedia permanecen en su ubicación original y se accede a ellos desde allí. En la medida de lo posible, estos archivos no deben moverse a una ubicación diferente. Si es necesario moverlos, deberá volver a vincularlos al proyecto. ATLAS.ti le alertará si existe algún problema y un archivo ya no puede ser accedido.
Importante para proyectos en equipo
Cuando se trabaja en equipo y se desea trabajar sobre los mismos documentos, es importante que una sola persona configure el proyecto y agregue todos los documentos y códigos que se van a compartir. La razón es que todas las entidades se marcan con un ID único en el momento de su creación. Este ID permite a ATLAS.ti detectar si las entidades son iguales al fusionar proyectos.
Si los mismos documentos (o códigos) se agregan en computadoras diferentes a proyectos distintos, todos tendrán IDs diferentes. En lugar de fusionarse al combinar todos los proyectos, se añadirán. Por lo tanto, el proyecto fusionado contendrá duplicados. Es posible fusionar códigos duplicados, pero no se pueden fusionar documentos duplicados. Si esto ocurre, deberá transferir manualmente toda la codificación realizada desde los documentos duplicados. Consulte Trabajo en equipo para obtener más información.
Cómo agregar documentos
En el menú principal, seleccione Documento > Agregar documentos. Otra opción es abrir el menú desplegable del botón de documento en la barra de herramientas, o simplemente arrastrar archivos desde el Finder a la barra lateral izquierda de ATLAS.ti.
Si desea vincular un archivo de video, seleccione la opción Referenciar documentos multimedia externos. Para más información, consulte Agregar datos multimedia.
Si desea escribir su propio texto, por ejemplo para transcribir datos, seleccione la opción Nuevo documento de texto.
Por supuesto, también puede importar transcripciones o incluso usar la Transcripción automática de ATLAS.ti; consulte Agregar transcripciones.
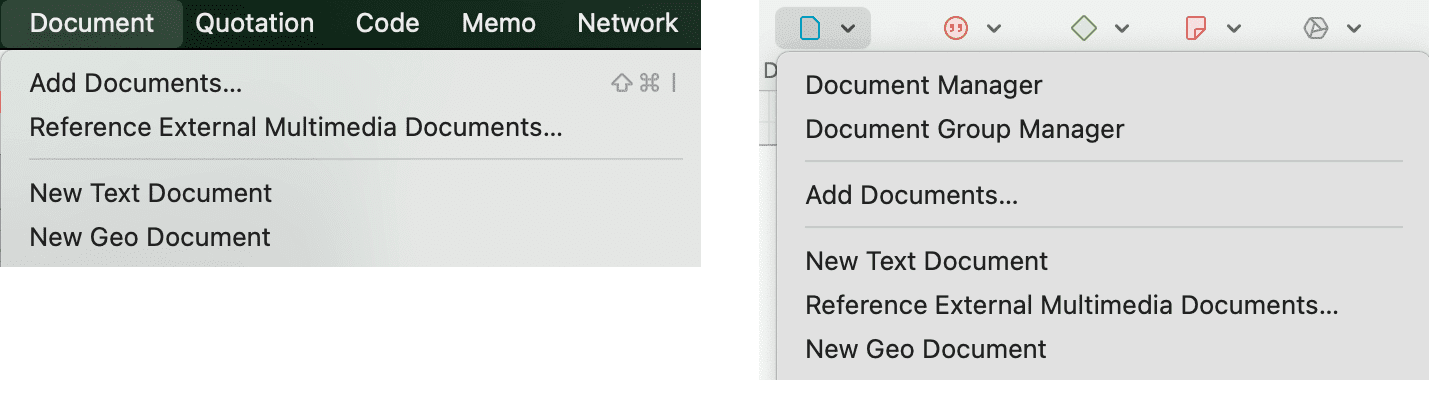
Todos los documentos agregados o vinculados se numeran consecutivamente comenzando por 1, 2, 3, etc.
El orden de clasificación predeterminado es por nombre en orden alfabético. El orden de los documentos no puede modificarse en la versión para Mac.
Restricciones de tamaño
En teoría, las restricciones de tamaño no tienen un papel importante debido a la forma en que ATLAS.ti gestiona los documentos. Sin embargo, debe tenerse en cuenta que la velocidad de procesamiento y la capacidad de almacenamiento del equipo pueden afectar al rendimiento.
Los documentos excesivamente grandes pueden resultar incómodos de trabajar, incluso si se dispone de un equipo con excelentes prestaciones.
En el caso de los documentos de texto, el número y el tamaño de los objetos incrustados puede causar tiempos de carga extraordinariamente largos. Es muy probable que si un documento de texto se carga lentamente en ATLAS.ti, también se cargue lentamente en Word o WordPad.
Para textos muy extensos o archivos multimedia, desplazarse hasta posiciones exactas puede resultar engorroso.
Tenga en cuenta estos aspectos al preparar los archivos.
Una nota sobre los "grandes volúmenes de datos"
Tenga presente que el enfoque de ATLAS.ti es apoyar el análisis de datos cualitativos y, en menor medida, el análisis de datos cuantitativos.
Los grandes volúmenes de datos (big data) son un término de moda hoy en día, y muchos de esos datos suelen presentarse como texto o imágenes, por lo que podrían considerarse cualitativos. Sin embargo, ATLAS.ti no está diseñado para el análisis de verdaderos grandes volúmenes de datos, que no es lo mismo que el análisis cualitativo de datos.
Como referencia, la codificación puede apoyarse mediante la función de autocodificación. No obstante, sigue siendo necesario leer y corregir la codificación, y la mayor parte de la codificación en ATLAS.ti se realiza mientras el investigador lee los datos y crea, selecciona y aplica un código adecuado.
Un proyecto es demasiado grande si se dispone de tantos datos que es necesario depender de una máquina para realizar toda la codificación, sin poder leer personalmente lo que ha sido codificado. Si bien estamos incorporando herramientas de procesamiento del lenguaje natural a ATLAS.ti y mejorando continuamente el rendimiento para proyectos de gran escala, estas herramientas están diseñadas para asistir al investigador, no para sustituir al ser humano. Aunque en ocasiones pueda parecer lo contrario, las computadoras aún no saben pensar.
Transcripción
Además del servicio integrado de transcripción automática rápida y de alta calidad, ATLAS.ti permite importar transcripciones de prácticamente cualquier servicio o aplicación de transcripción. Ya sea que utilice un servicio de transcripción comercial, realice la traducción manual usted mismo o emplee un sistema automatizado de conversión de voz a texto, ATLAS.ti puede importar los datos.
Los formatos admitidos son VTT, SRT, TXT, DOCX y RTF.
ATLAS.ti puede detectar y codificar automáticamente a los participantes en archivos VTT que incluyan información sobre los mismos.
Algunos de los servicios y aplicaciones que pueden exportar formatos compatibles:
- AmberScript
- Descript
- Easytranscript
- ELAN
- eStream
- Express Scribe
- f4 & f5 transcript
- Go Transcribe
- Happy Scribe
- HyperTRANSCRIBE
- Inqscribe
- Microsoft Teams
- oTranscribe
- Otter.ai
- Panopto
- Rev
- Scribie
- Simon Says
- Sonix
- Speechmatics
- Spoken ONLINE
- Temi
- Transana
- Transcribe by Wreally
- TranscribeMe!
- Transcriber Pro
- Transcriva
- Transkripto
- Trint
- Uitgetypt.nl
- Vimeo
- Vocalmatic
- Voicedocs
- WebEx
- YouTube
- Zoom
Marcas de tiempo admitidas para transcripciones TXT, RTF y DOCX
Al escribir sus propias transcripciones, puede optar por utilizar software de transcripción especializado (recomendado), escribir la transcripción dentro de ATLAS.ti o simplemente redactar la transcripción en el editor de texto o procesador de texto de su elección.
Al escribir sus transcripciones manualmente, elija uno de los formatos siguientes para garantizar la máxima compatibilidad con ATLAS.ti.
| Formato | Exportado por |
|---|---|
| #hh:mm:ss-x# | Easytranscript, f4 & f5transcript |
| [hh:mm:ss] | Transcribe |
| [hh:mm:ss.xx] | HyperTRANSCRIBE, Inqscribe, Transcriva |
| [hh:mm:ss.xxx] | HyperTRANSCRIBE, Inqscribe, Transcriva |
| (h:mm:ss.xx) | Transana |
| hh:mm:ss | Transcriber Pro |
Agregar transcripciones
Cada vez que importa un archivo de audio o video individual, ATLAS.ti le preguntará si desea proporcionar un archivo de transcripción, transcribir el archivo automáticamente o importarlo sin transcripción.
También puede importar una transcripción haciendo clic en Documentos en la barra de herramientas y eligiendo Importar transcripción….
Haga clic en el menú desplegable superior para elegir el archivo que contiene el texto transcrito.
Por último, si ya tiene un documento de audio o video en ATLAS.ti y desea agregar una transcripción, abra el documento y, en la barra de herramientas, haga clic en Transcripción y elija Transcripción automática… o Importar transcripción….
Las transcripciones automáticas de ATLAS.ti, así como algunos archivos VTT, contienen información sobre los participantes. Active la casilla correspondiente y ATLAS.ti insertará automáticamente los nombres de los participantes en su archivo de texto y codificará los fragmentos hablados con el nombre del participante correspondiente, si el archivo contenía información sobre participantes.
Consulte Trabajar con transcripciones multimedia para los próximos pasos.
Transcripción automática
Como servicio de pago, ATLAS.ti ofrece transcripción automática de muy alta calidad y gran velocidad. Las marcas de tiempo son precisas a nivel de oración. Una hora de audio en inglés se transcribe normalmente en menos de un minuto.
Al importar un archivo de audio o video individual, ATLAS.ti le pregunta si desea que el archivo se transcriba automáticamente. También puede transcribir automáticamente un documento en un momento posterior. Simplemente ábralo y, en la barra de herramientas, haga clic en Transcripción y elija Transcripción automática….
Diarización y codificación de participantes
ATLAS.ti admite la diarización automática de participantes. Esto permite distinguir a los diferentes hablantes en la misma pista de audio. Dado que ATLAS.ti no conoce los nombres de los participantes, los denominará Participante 1, Participante 2, y así sucesivamente — de ahí que esta función se llame diarización de participantes y no detección de participantes.
Seleccionar "Codificar participantes" creará codificaciones de participantes para cada fragmento hablado. Esto es muy útil cuando desea identificar quién dijo qué mediante consultas, códigos inteligentes, análisis de coocurrencia de códigos, etc.
Antes de importar el siguiente archivo, cambie el nombre de los códigos de participantes creados. ATLAS.ti creará un nuevo código de Participante 1 al transcribir el siguiente audio si no existe ninguno, pero reutilizará el código de Participante 1 si ya está presente. Dado que los participantes se nombran en orden de aparición por archivo, el Participante 1 en un documento puede ser el Participante 2 en otro, incluso si es una entrevista con la misma persona.
Idiomas admitidos
La transcripción automática admite más de 30 idiomas y audio bilingüe en inglés y español en la misma pista.
Aunque ATLAS.ti admite la detección automática de idioma, para obtener mejores resultados recomendamos seleccionar el idioma usted mismo.
- Búlgaro
- Catalán
- Chino
- Chino (simplificado)
- Chino (simplificado, República Popular China)
- Chino (tradicional)
- Chino (tradicional, Taiwán)
- Checo
- Danés
- Neerlandés
- Inglés
- Inglés (Australia)
- Inglés (Nueva Zelanda)
- Inglés (India)
- Inglés (Reino Unido)
- Inglés (Estados Unidos)
- Estonio
- Finlandés
- Flamenco
- Francés
- Francés (Canadá)
- Alemán
- Alemán (Suiza)
- Griego
- Hindi
- Húngaro
- Indonesio
- Italiano
- Japonés
- Coreano
- Letón
- Lituano
- Malayo
- Noruego
- Polaco
- Portugués
- Portugués (Brasil)
- Rumano
- Ruso
- Eslovaco
- Español
- Español (Latinoamérica y el Caribe)
- Sueco
- Tailandés
- Turco
- Ucraniano
- Vietnamita
También puede importar una transcripción haciendo clic en Documentos en la barra de herramientas y eligiendo Importar transcripción….
Haga clic en el menú desplegable superior para elegir el archivo que contiene el texto transcrito.
Por último, si ya tiene un documento de audio o video en ATLAS.ti y desea agregar una transcripción, abra el documento y, en la barra de herramientas, haga clic en Transcripción y elija Transcripción automática… o Importar transcripción….
Las transcripciones automáticas de ATLAS.ti, así como algunos archivos VTT, contienen información sobre los participantes. Active la casilla correspondiente y ATLAS.ti insertará automáticamente los nombres de los participantes en su archivo de texto y codificará los fragmentos hablados con el nombre del participante correspondiente, si el archivo contenía información sobre participantes.
Consulte Trabajar con transcripciones multimedia para los próximos pasos.
Trabajar con transcripciones multimedia
Una transcripción multimedia consta de dos partes: una parte de audio o video y una transcripción asociada. En ATLAS.ti se gestiona de manera muy similar a un documento de texto, con la capacidad adicional de reproducción sincronizada de audio/video.
Desplazamiento sincronizado
El desplazamiento sincronizado está siempre activo en las transcripciones. Esto significa que mientras el archivo multimedia se reproduce, el segmento de texto en la transcripción entre dos marcas de tiempo se resalta — y cuando reposiciona el cursor de texto, el documento multimedia se desplaza al tiempo correspondiente.
Tenga en cuenta que el posicionamiento solo será tan preciso como sus marcas de tiempo. La mayoría de las transcripciones no tendrán marcas de tiempo suficientemente precisas para una sincronización exacta a nivel de palabra. La transcripción automática de ATLAS.ti ofrece precisión a nivel de oración.
Si el documento no contiene marcas de tiempo, ATLAS.ti estima la sincronización en función de la duración del archivo multimedia y la transcripción.
Editar texto
Puede editar el texto como lo haría con un documento de texto ordinario. Para preservar las marcas de tiempo invisibles, evite eliminar secciones grandes del documento de una sola vez y mantenga sus ediciones pequeñas.
Trabajar con datos de gestor de referencias
ATLAS.ti se utiliza con frecuencia para asistir en revisiones de literatura. Consulte, por ejemplo:
- Cómo realizar una revisión de literatura con ATLAS.ti
- Gestión de revisiones de literatura con ATLAS.ti
video tutorial Revisión de literatura con ATLAS.ti 22 Windows y Mac
Es posible que haya recopilado muchos artículos en un gestor de referencias. No todos estos artículos serán relevantes para la revisión de literatura de una investigación o artículo en particular. Por lo tanto, cree una colección de 50 a 200 artículos en su gestor de referencias para codificarlos y analizarlos en ATLAS.ti.
Puede importar archivos XML de EndNote o archivos bibtex. Esto debería permitirle importar datos de casi todos los gestores de referencias.
Importar datos del gestor de referencias
Para iniciar la importación del archivo en ATLAS.ti, seleccione Documento > Importar > Datos del gestor de referencias.
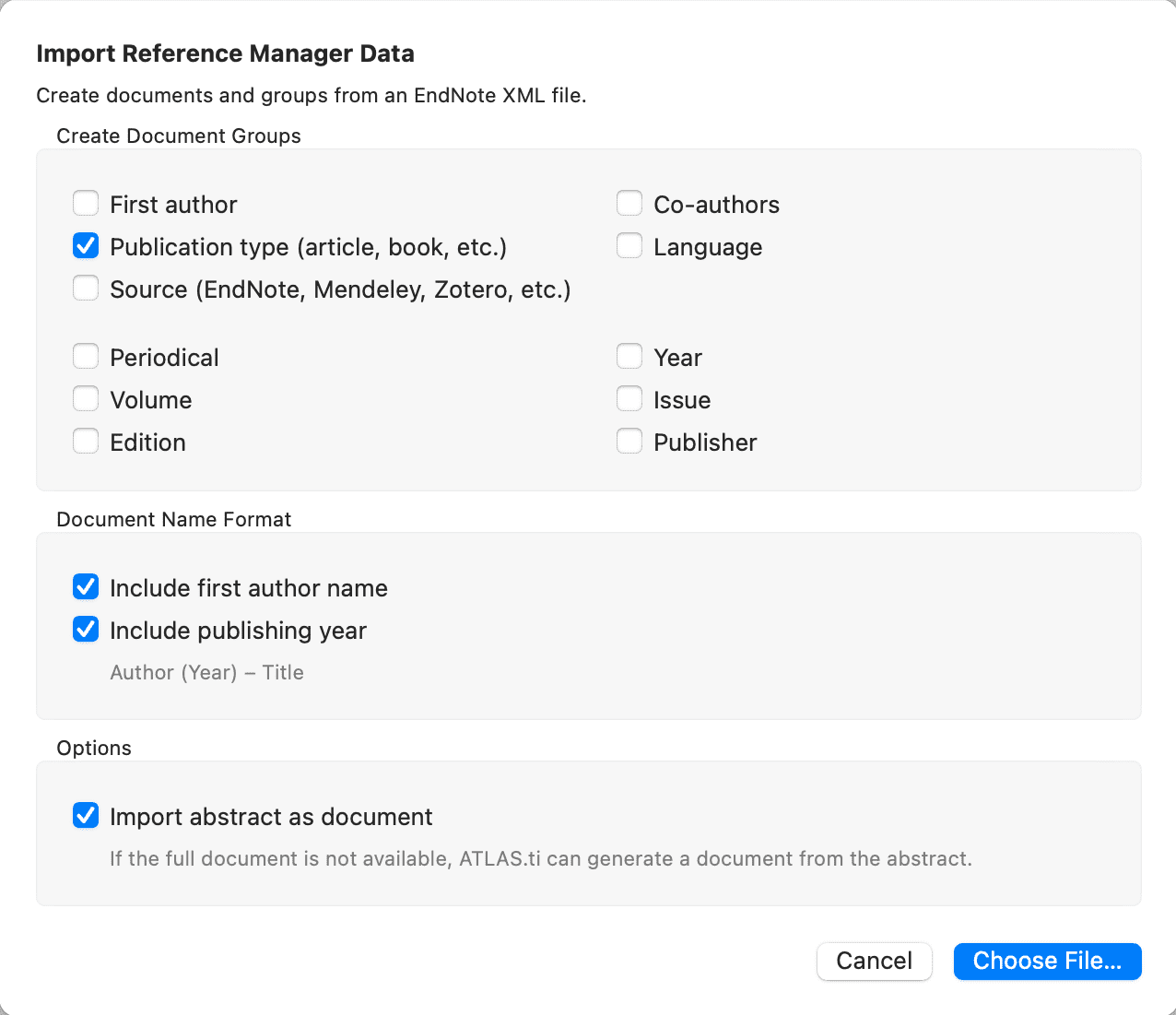
Si su gestor de referencias no exporta los archivos PDF a una carpeta separada, asegúrese de que los archivos PDF estén almacenados en las ubicaciones indicadas en los archivos XML o bibtex. Por lo general, esta será la biblioteca de su gestor de referencias.
ATLAS.ti puede crear grupos de documentos basados en los siguientes metadatos:
- Primer autor
- Coautores
- Tipo de publicación (artículo de revista, libro, capítulo de libro, etc.)
- Idioma
- Fuente: si importa documentos desde más de un gestor de referencias, es útil agrupar los documentos por fuente para saber de dónde provienen.
- Publicación periódica
- Año
- Volumen
- Número
- Edición
- Editorial
Formato del nombre del documento
El nombre predeterminado del documento en ATLAS.ti es el nombre del documento tal como se usa en el gestor de referencias. Para facilitar la ordenación y organización, puede optar por añadir el nombre del primer autor y el año de publicación al nombre del documento (recomendado).
Si el documento completo no está disponible
Si solo está disponible el resumen del documento y no el documento completo, puede optar por importar el resumen como documento.
Si ha escrito una nota sobre el documento en su gestor de referencias, esta nota se importará como comentario del documento.
Realice sus selecciones.
Haga clic en Elegir archivo y seleccione el archivo XML o bibtex que exportó desde su gestor de referencias.
Inspeccionar los documentos importados
Abra el Administrador de documentos.
Los documentos importados están ordenados por autor y año en orden alfabético, si seleccionó esa opción. Además, se crean grupos de documentos a partir de todas las opciones seleccionadas.
El texto introducido como nota en el gestor de referencias se importa como comentario del documento. Si la URL de un documento está disponible, también se añadirá al campo de comentarios.
Importar comentarios de redes sociales
Tutorial en vídeo: Importar comentarios de redes sociales.
Las redes sociales ofrecen un reflejo poderoso de la estructura y dinámica de la sociedad moderna. A menudo no es un solo tuit o publicación lo que resulta interesante, sino las reacciones e interacciones de los usuarios de las redes sociales. Hay muchas aplicaciones para analizar comentarios de usuarios, como: movimientos sociales, comunidades de marca, campañas de marketing, discurso político, discursos sobre temas de actualidad dentro de una comunidad o sociedad determinada, comprensión de la audiencia, o incluso situaciones de crisis comunicativa.
ATLAS.ti importa archivos Excel generados por exportcomments.com. Puede usar el servicio de forma gratuita para exportar hasta 100 comentarios por enlace. Por una pequeña tarifa, puede usar el servicio durante tres días para descargar los datos que necesita. Esto también permite exportar comentarios anidados.
Las redes sociales admitidas son:
- YouTube
- TikTok
- VK
- Twitch
- Discord
Busque una publicación en redes sociales cuyos comentarios desee analizar. Copie la URL.
Vaya a exportcomments.com, introduzca la URL y descargue los comentarios.
Vaya a ATLAS.ti y, en el menú principal, seleccione Documento / Importar / Comentarios de redes sociales.
Seleccione el archivo Excel exportado desde exportcomments.com y haga clic en Abrir.
ATLAS.ti codifica automáticamente a todos los usuarios y crea categorías para cada red social. Todos los códigos generados automáticamente se agrupan en un grupo de códigos (Códigos de importación de comentarios de redes sociales).
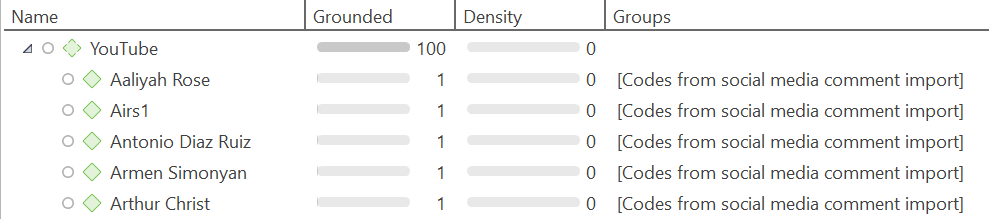
Así podría verse el documento tras la importación. Se han añadido el título y una captura de pantalla del vídeo que se está discutiendo:
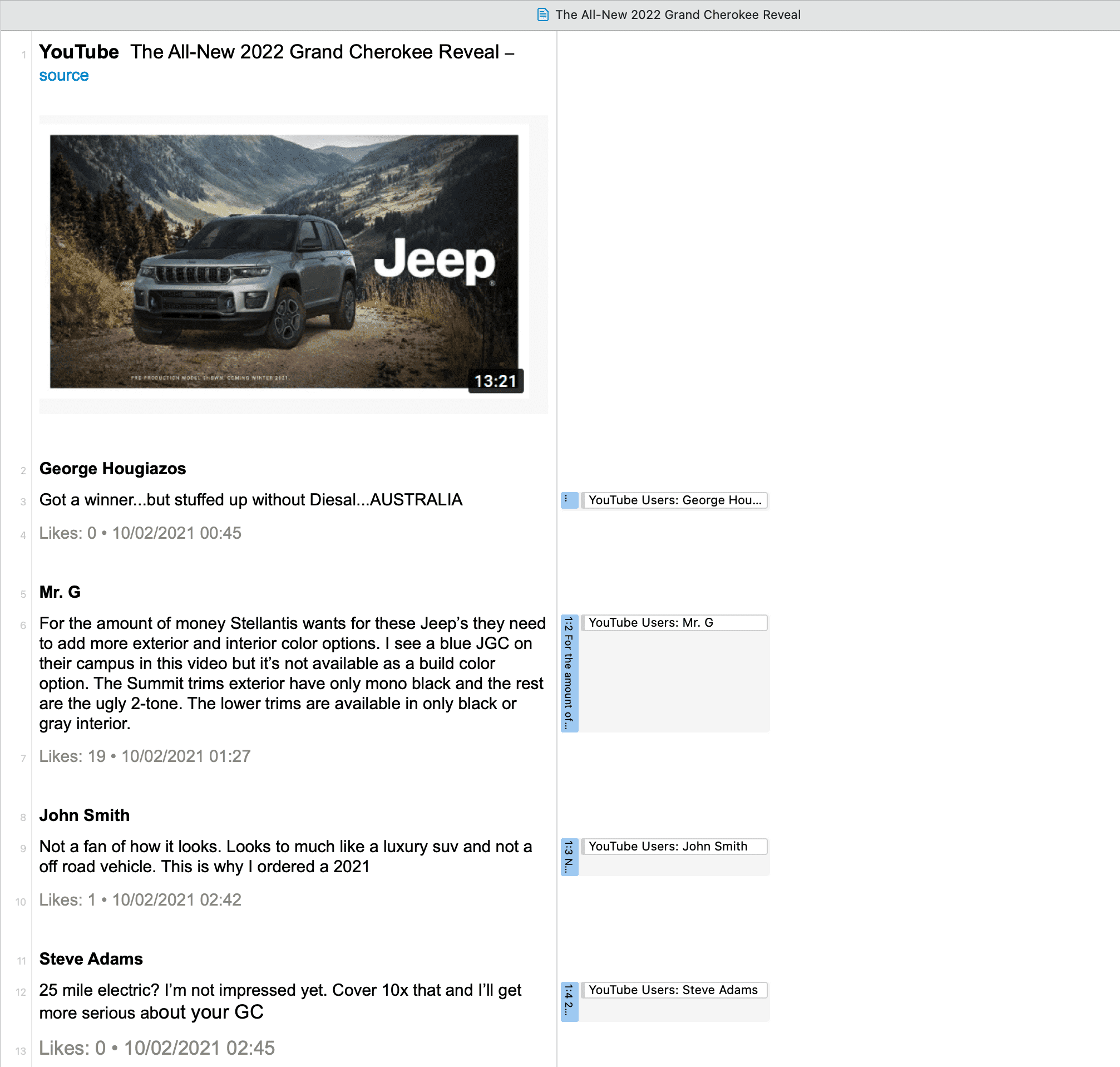
Un posible paso siguiente es ejecutar un análisis de sentimiento:
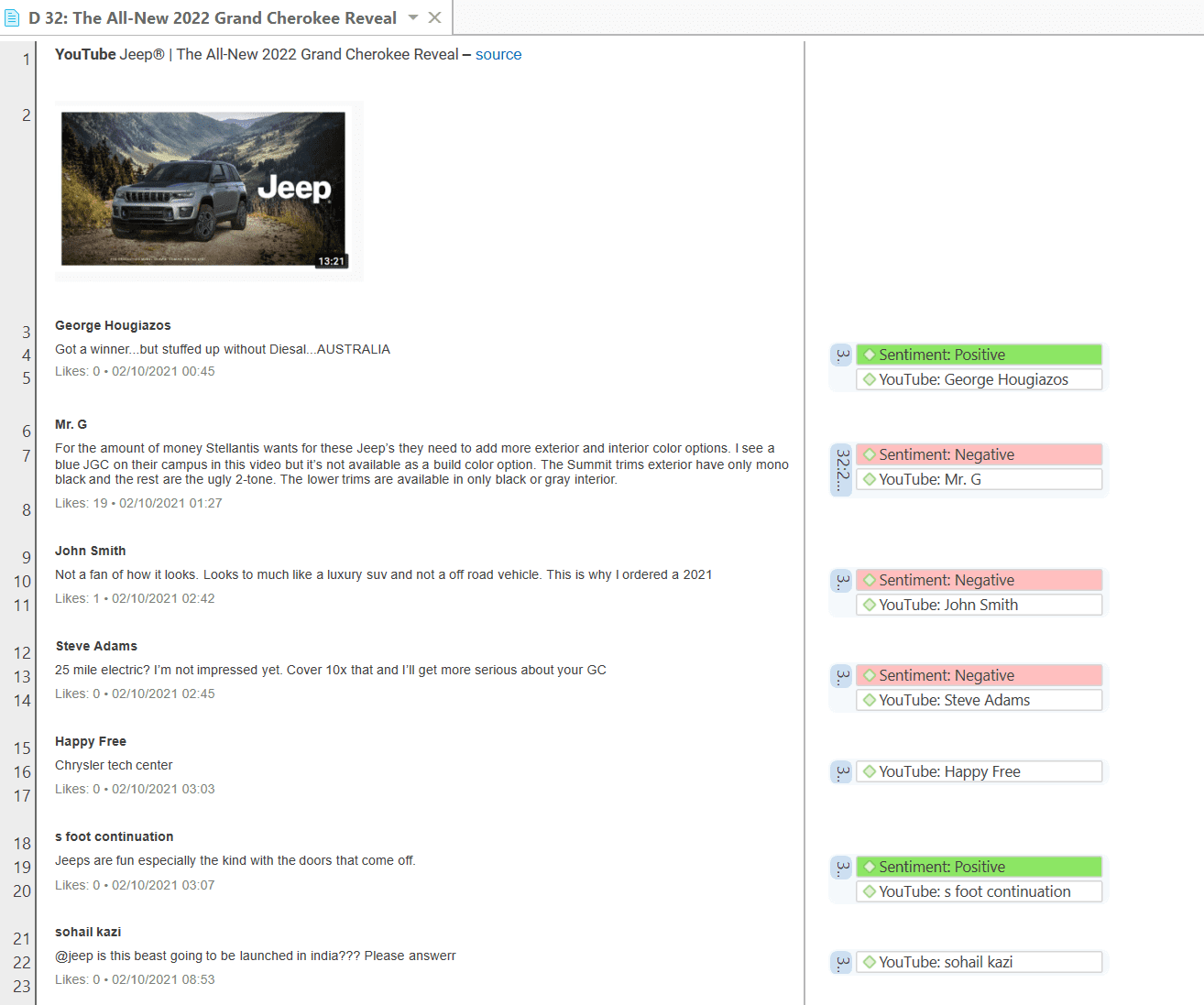
Importar datos desde Evernote
Evernote es un software para tomar notas que le ayuda a crear y organizar notas digitales, manteniéndolas sincronizadas en todos sus dispositivos. Puede usarlo como archivador digital para organizar todas sus notas, ya sean notas de campo en un proyecto de investigación, planes estratégicos de trabajo, notas de reuniones, notas para la planificación de proyectos, documentos PDF encontrados en línea, sitios web, fotos o vídeos tomados con dispositivos móviles, o notas de audio.
Para importar todos los datos que ha recopilado en Evernote, o una selección de ellos:
Seleccione la pestaña Importar y exportar en la cinta principal y, desde allí, Evernote.
Inicie sesión en su cuenta de Evernote y autorice a ATLAS.ti para acceder a su cuenta.
Seleccione lo que desea importar. ATLAS.ti reconoce la estructura de carpetas que ha creado en Evernote y agrupará los documentos en consecuencia, creando grupos de documentos en ATLAS.ti.
Administrador de documentos tras la importación:
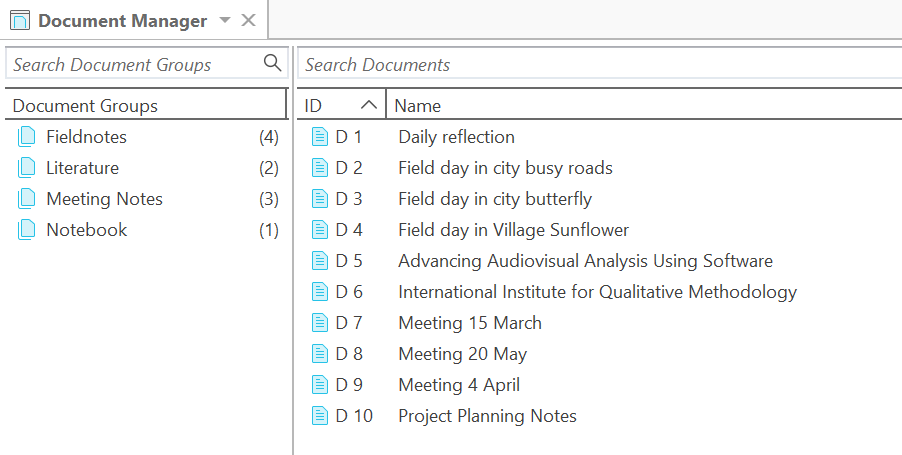
Trabajar con datos de encuestas
Tutorial en vídeo: Importar datos de encuestas.
Hoy en día, la mayoría de las encuestas se realizan en línea. Un efecto positivo de esto es que (a) todos los datos están disponibles de inmediato en formato digital y (b) los encuestados suelen escribir respuestas extensas a las preguntas abiertas. Si trabaja con encuestas del mundo analógico, es probable que en algún momento terminen en una hoja de cálculo Excel™. Independientemente del origen de sus encuestas, ATLAS.ti puede gestionarlas una vez que existan en ese formato.
Las encuestas en línea pueden crearse con diversas herramientas. Lo que la mayoría de estas herramientas tienen en común es que permiten exportar los datos como archivo Excel™. Al importar dicho archivo Excel a través de la opción de importación de encuestas en ATLAS.ti, un asistente le guiará por el proceso de importación, y podrá decidir qué información de la encuesta debe incluirse, qué preguntas deben convertirse en grupos de documentos para el análisis comparativo y qué preguntas constituirán el cuerpo de los datos.
Además de las respuestas a las preguntas abiertas, también pueden importarse datos demográficos como edad, profesión o grupo etario, respuestas a preguntas de opción única (sí/no u ofreciendo más de dos opciones) y respuestas a preguntas de opción múltiple. En el marco de ATLAS.ti, estos se mapean en forma de grupos de documentos, un grupo por valor.
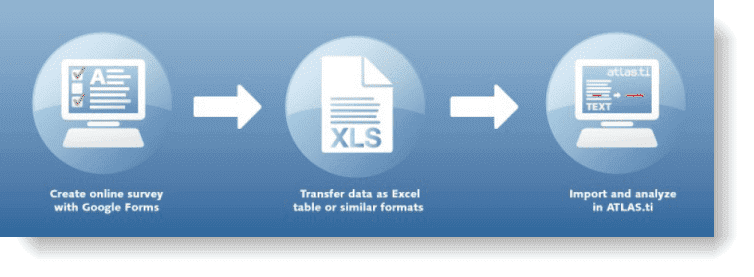
Una encuesta consta, en términos generales, del nombre de la encuesta, las preguntas y las respuestas de cada encuestado. Las preguntas pueden ser de distintos tipos:
- Opción única entre dos (sí/no) o más opciones
- Opción múltiple
- Pregunta abierta
En el marco de ATLAS.ti, estos conceptos se mapean de la siguiente manera:
| Concepto de encuesta | Concepto de ATLAS.ti |
|---|---|
| Pregunta abierta | Código (y comentario de código) |
| Respuesta a una pregunta abierta | Contenido de una cita (datos) |
| Pregunta de opción única | Un grupo de documentos por cada valor |
| Pregunta de opción múltiple | Un grupo de documentos por cada valor |
ATLAS.ti codifica automáticamente cada pregunta abierta con la información proporcionada en el encabezado. Como normalmente esta información es la pregunta en sí, el nombre del código puede resultar muy largo. Por ello, puede dividirlo en etiqueta de código y comentario. Se recomienda usar el número de pregunta como etiqueta del código y el texto completo de la pregunta como comentario. Para ello, agregue dos columnas (::) entre el número de pregunta y la pregunta, como en: 'Pregunta 1::Cuénteme sobre los momentos destacados de sus últimas vacaciones'.
Los datos se importan por caso. Esto significa que cada fila de la tabla Excel™ importada desde la herramienta de encuesta en línea se transforma en un documento.
Haga clic aquí para aprender cómo Importar datos de encuestas.
Importar datos de encuestas
Si importa la misma tabla varias veces, las filas con documentos ya existentes se omiten. De esta manera, no es necesario esperar a que el último encuestado haya completado el cuestionario.
Al importar los mismos datos nuevamente con información actualizada, solo puede importar nuevos casos (es decir, filas en Excel), pero no nuevas preguntas (es decir, columnas en Excel).
En el menú principal, seleccione Documento > Importar > Encuesta.
Seleccione el archivo Excel que desea importar y haga clic en Abrir.
Se abre un asistente que le guiará por los pasos siguientes:
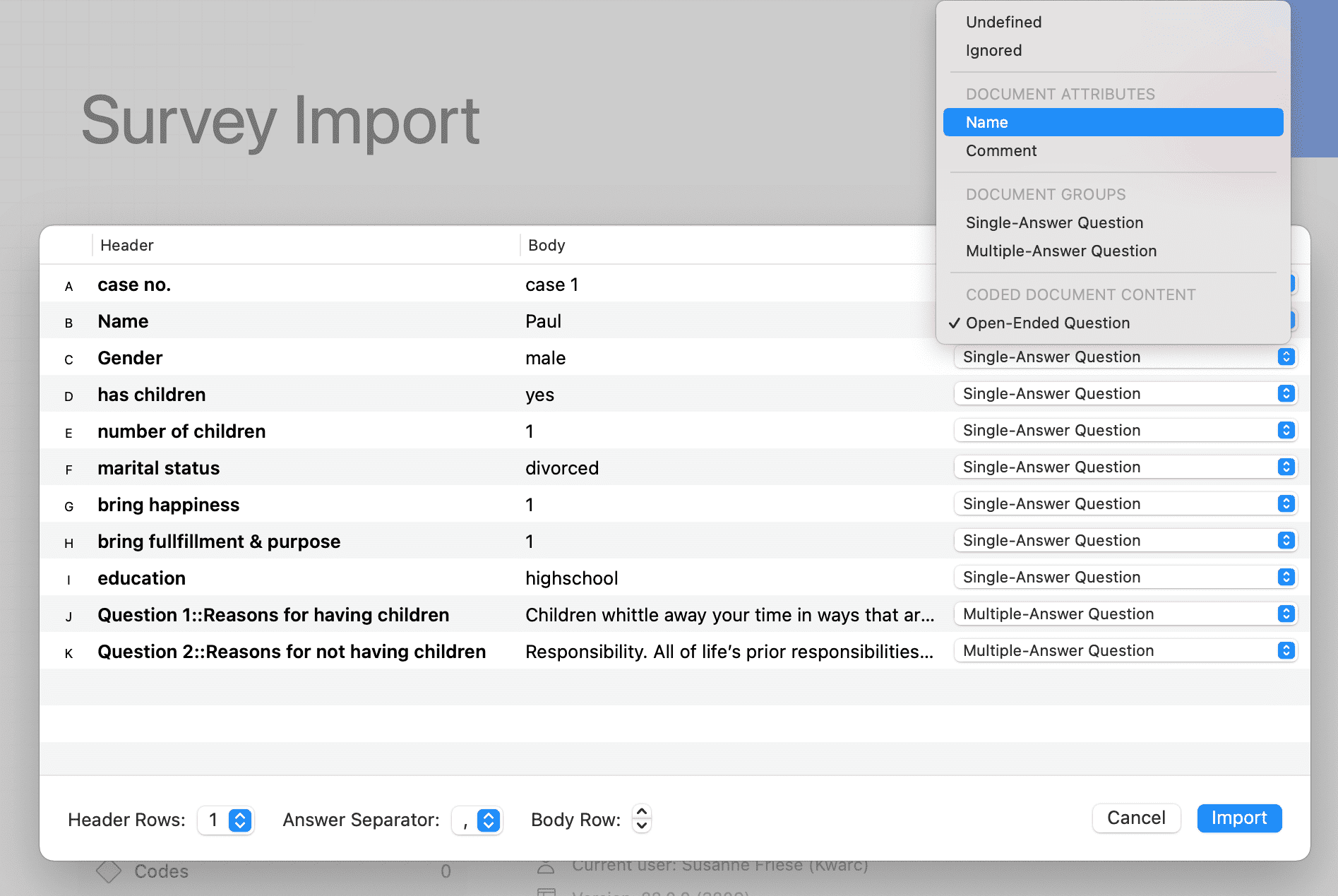
Para cada columna de la tabla puede decidir si debe transferirse como atributo de documento, grupo de documentos o contenido de un documento codificado. También puede excluir columnas.
Sin definir: ATLAS.ti intenta hacer una estimación razonada para cada columna. Si esto no es posible, se introduce "sin definir". En ese caso, debe seleccionar una opción adecuada. Los datos no pueden importarse si algunas columnas tienen el estado "sin definir".
Ignorado: Seleccione esta opción si no desea importar esta columna. Se recomienda limpiar la tabla previamente en Excel y eliminar todo lo que no desee importar a ATLAS.ti. Esto facilitará la importación.
Atributo de documento: nombre: use el contenido de cada celda de esta columna como nombre del documento. También puede seleccionar más de una columna para componer el nombre, como se muestra en el ejemplo. Si tanto "número de caso" como "Nombre" se eligen para formar el nombre del documento, el nombre será "caso 1 Pablo", "caso 2 Ana", "caso 3 Toni", etc. Puede usar la opción Fila de cuerpo en la barra de herramientas en la parte inferior del asistente para desplazarse por el contenido de cada fila.
Atributo de documento: comentario: use la información de esta columna como comentario del documento.
Grupo de documentos: pregunta de respuesta única: si tiene una pregunta en la que pide a los encuestados que indiquen su estado civil y las opciones de respuesta posibles son: soltero, casado, divorciado, ATLAS.ti crea un grupo de documentos para cada uno de estos valores:
- estado civil::soltero
- estado civil::casado
- estado civil::divorciado
Grupo de documentos: pregunta de respuesta múltiple: use esta opción si los encuestados pueden dar múltiples respuestas a una pregunta. Por ejemplo: "¿Cuáles son sus sabores de helado favoritos? Seleccione todos los que le gusten." ATLAS.ti creará un grupo de documentos para cada opción de respuesta. El separador de respuestas predeterminado es la coma (,). Consulte la sección inferior del asistente. Ajuste el separador si se utiliza un punto y coma (;).
Contenido de documento codificado: pregunta abierta: todas las respuestas que deben formar parte del cuerpo del documento.
Barra de herramientas

Filas de encabezado
Algunas aplicaciones de encuestas usan dos filas de encabezado, como Survey Monkey, por ejemplo. Esto significa que el resultado de Excel podría verse así:
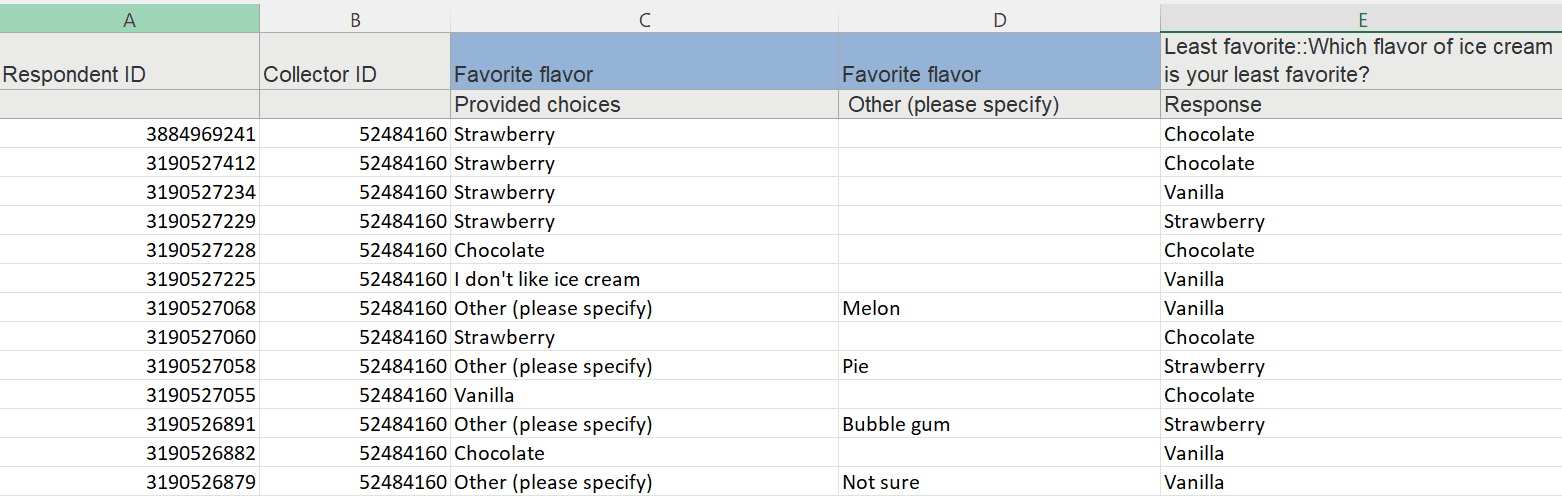
En ese caso, debe cambiar el número de filas de encabezado de 1 a 2. A continuación se muestra un ejemplo:
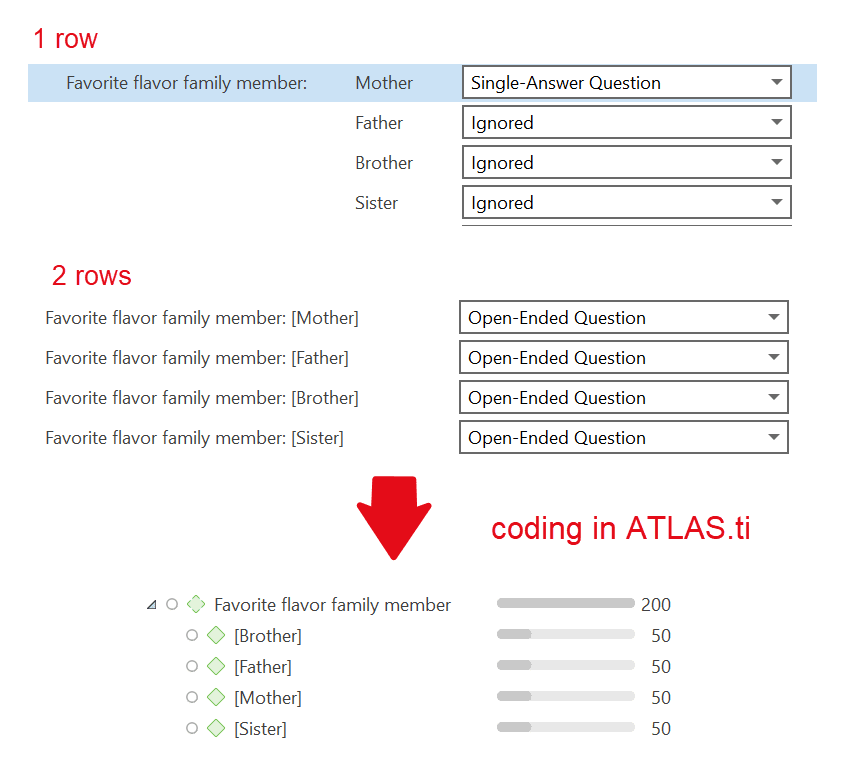
Inspeccionar los datos de encuesta importados
Abra el Administrador de documentos y observe qué se ha añadido al proyecto:
Nombres de documentos: si no especifica un nombre para cada caso, el nombre predeterminado es caso 1, caso 2, caso 3, y así sucesivamente. En el ejemplo mostrado aquí, el número de caso y el nombre se usan como nombre del documento.
Grupos de documentos: basándose en la información proporcionada en la tabla Excel, se crean grupos de documentos. El encuestado resaltado "caso 7 Leo" en el ejemplo tiene un título universitario, es hombre, está casado y tiene 2 hijos. Respondió la pregunta "¿Los hijos dan plenitud y propósito?" con sí.
ATLAS.ti crea automáticamente un grupo que contiene todos los datos de encuesta, en caso de que trabaje con datos de múltiples fuentes.
Datos: el texto del documento para cada caso consiste en las respuestas a las preguntas abiertas. Cada respuesta se codifica automáticamente con la información proporcionada en Excel. El código puede ser simplemente el número de pregunta o una etiqueta más larga.
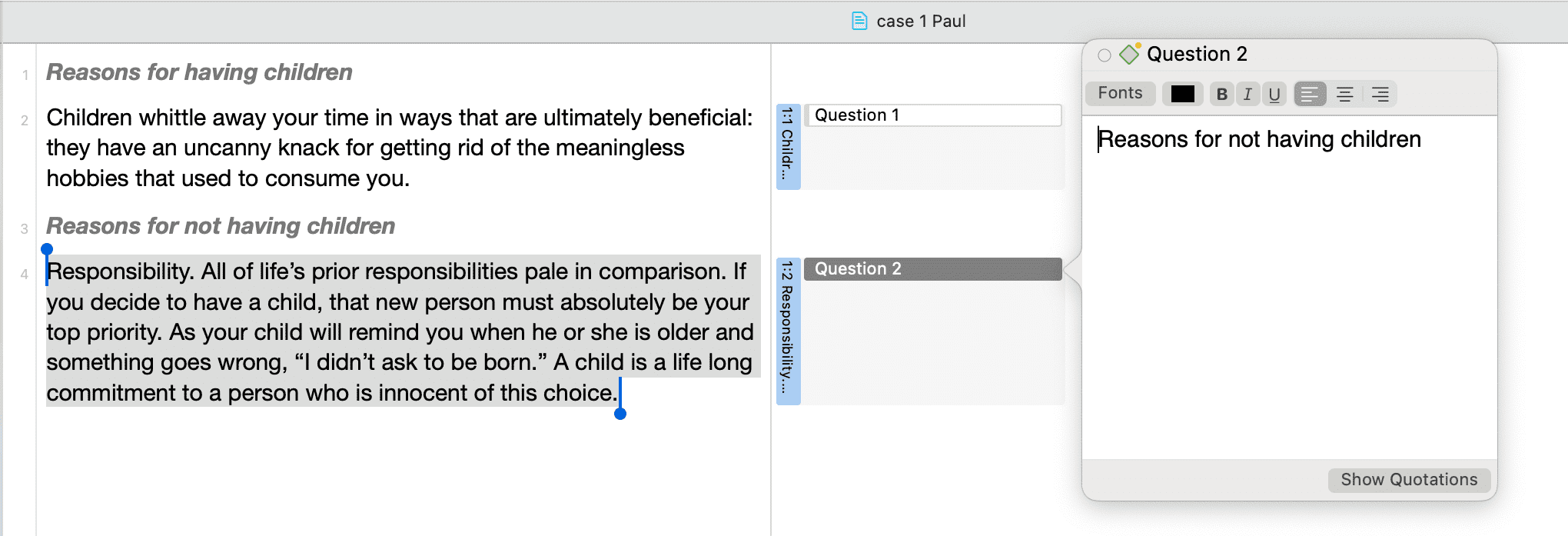
Ahora puede comenzar a agregar una codificación más detallada para cada pregunta. Las herramientas útiles para obtener rápidamente información de sus datos son: Codificación con IA, análisis de sentimiento y dejar que ATLAS.ti busque conceptos.
Para un análisis comparativo basado en los grupos de documentos creados, puede usar la Tabla código-documento:
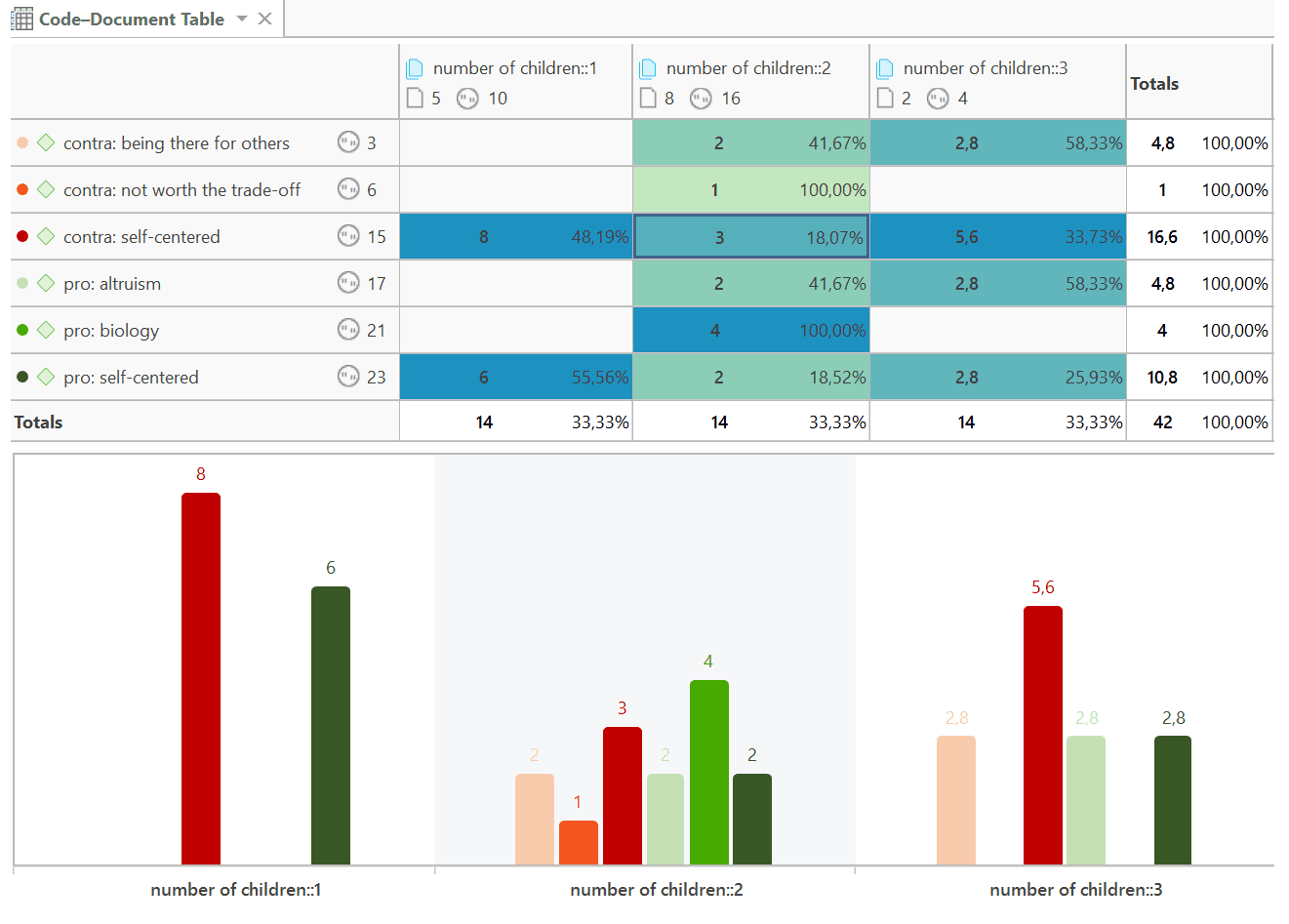
La imagen anterior muestra una comparación de los encuestados con 1, 2 y 3 hijos. Se comparan los tipos de razones que dan a favor y en contra de tener hijos.
Analizar datos de encuestas
-
El análisis de datos de encuestas requiere saber cómo codificar. Consulte Trabajar con códigos.
-
Es posible que desee explorar los datos primero creando nubes de palabras o listas de palabras; consulte Explorar datos, y utilizando la función de autocodificación. Consulte Buscar y codificar.
-
Después de la codificación, otras opciones de análisis que se usan frecuentemente con datos de encuestas son:
- la Tabla código-documento
- la Herramienta de consulta en combinación con la opción de Ámbito
- la Tabla de co-ocurrencia de códigos
Agregar un documento geográfico a un proyecto
ATLAS.ti utiliza Open Street Map como fuente de datos para los documentos geográficos. Puede verlo como mapa, satélite o híbrido. Aunque solo haya una fuente de datos, puede usar más de un documento geográfico en su proyecto, por ejemplo, para crear conjuntos distintos de ubicaciones, simular recorridos o simplemente contar historias diferentes.
Para agregar un documento geográfico al proyecto, vaya al botón Documento en la barra de herramientas y seleccione Nuevo documento geográfico en el menú desplegable.
Se agrega un nuevo documento y, al abrirlo, verá el mapa mundial. El nombre predeterminado es "Documento geográfico". Puede que desee renombrarlo para que describa mejor su intención analítica.
Buscar una ubicación
Lo primero que probablemente querrá hacer es consultar una dirección:
Introduzca una ubicación, dirección o punto de referencia, como la Torre Eiffel, en el campo de búsqueda.
El mapa muestra inmediatamente la ubicación que corresponde al término de búsqueda y añade una marca de lugar.
Cambiar la vista
En la parte inferior izquierda, puede alternar entre la vista de mapa, satélite o híbrida.
Para obtener más información, consulte Trabajar con datos geográficos.
Trabajar con documentos geográficos
Crear citas geográficas
Para obtener información general sobre las citas, consulte Nivel de cita y Trabajar con citas.
Crear una cita geográfica no es muy diferente de crear otros tipos de citas. La única diferencia es que la cita corresponde a una sola ubicación en el mapa —la marca de lugar— y no a una región.
Haga clic derecho en la marca de lugar y seleccione la opción Crear cita.
Para crear más citas:
Introduzca una nueva dirección y busque una ubicación de interés, o haga clic con el botón izquierdo en un punto de interés en el mapa para colocar una marca de lugar.
Haga clic derecho y seleccione Crear cita del menú contextual, o use el atajo cmd+H.
Puede introducir un nombre para la cita geográfica en el inspector del lado derecho.
Visualización de citas geográficas
Las citas geográficas son accesibles desde el área de margen, el Administrador de citas, el Explorador de proyectos y desde las redes. Las citas geográficas se muestran de la siguiente manera:
-
El icono de cita muestra una marca de lugar.
-
En el Explorador de proyectos, el Lector y Administrador de citas, y en todos los informes, las citas geográficas se referencian en grados decimales, por ejemplo, LAT 48.859911° LON 2.377317°.
Además, el Administrador de citas muestra una vista previa de la ubicación geográfica. Puede considerar renombrar las citas geográficas, por ejemplo, añadiendo el nombre de la ubicación. Otra opción es agregar un comentario. Consulte también Trabajar con citas multimedia.
Activar citas geográficas
Seleccione una cita geográfica en cualquiera de los siguientes lugares y haga doble clic:
- área de margen
- Administrador de citas
- Explorador de proyectos
- Red
La cita se mostrará en contexto.
Una marca de lugar activada se colorea en naranja. Las marcas de lugar no activadas se colorean en gris.
Modificar una cita geográfica
Para modificar una cita geográfica, actívela para que quede resaltada en naranja.
Mueva la marca de lugar a una ubicación diferente. La cita se actualiza en consecuencia.
Codificar citas geográficas
Para obtener información general sobre codificación, consulte Codificar datos.
También puede crear una cita y vincularle un código en un solo paso, o codificar una cita existente:
Coloque una marca de lugar o seleccione una cita existente, haga clic derecho y seleccione la opción Aplicar códigos o cmd+J.
También se aplican todas las operaciones de arrastrar y soltar descritas para la codificación.
Crear una captura de pantalla geográfica
Puede crear una captura de pantalla de la región geográfica que se muestra actualmente en su pantalla. Esta captura se añade automáticamente como un nuevo documento de imagen.
La ventaja de la imagen es que puede seleccionar una región como cita y no solo un punto en el mapa. Además, puede explorar la ubicación geográfica en Google Maps (véase más adelante).
Abra un documento geográfico.
En la pestaña Documento, haga clic en el botón Crear captura de pantalla.
Se crea un nuevo documento. El nombre predeterminado es: 'Geo Snapshot @ longitud:latitud' de la última ubicación seleccionada.
Como una captura da como resultado un documento de imagen, también puede tratarlo como un documento de imagen. Consulte, por ejemplo, Crear citas de imagen.
Gestión de documentos
Cada vez que es necesario mostrar, imprimir o buscar el contenido de un documento, ATLAS.ti accede a su fuente de datos y carga el contenido. Esta solicitud suele activarse de forma indirecta, por ejemplo, al mostrar una cita. A continuación se enumeran algunos procedimientos que cargan directa o indirectamente el contenido de un documento:
- Activar un documento en el Explorador de proyectos o en el Administrador de documentos.
- Activar una cita en un navegador, en el Administrador de citas o en el Lector de citas.
- Seleccionar una cita para un código o memo activado.
- Activar un hipervínculo en el área de margen.
Cargar documentos
Seleccione un documento en el Explorador de proyectos y haga doble clic. Se cargará en la siguiente pestaña disponible.
Alternativamente:
Haga doble clic en un documento en el Administrador de documentos. (Para abrir el Administrador de documentos, haga doble clic en la rama principal de documentos en el Explorador de proyectos.)
Editar documentos
Para editar un documento, haga clic en Editar texto en la barra de herramientas. Aparecerá una barra de herramientas de edición en la parte superior del documento con diversas opciones.
Para salir del modo edición, haga clic nuevamente en Editar texto.
Se recomienda no permanecer en modo edición mientras se codifica. Podría modificar texto accidentalmente al resaltar segmentos de texto para codificar.
Cuando se trabaja en equipo, se recomienda encarecidamente no editar el texto. Si los miembros del equipo editan el mismo documento, se perderá una versión al fusionar el proyecto. Si es necesario modificar el texto, solo debe editarse en el Proyecto maestro por parte del administrador del proyecto.
Renombrar documentos
Seleccione un documento en el Explorador de proyectos o en el Administrador de documentos y haga clic con el botón izquierdo. Esto habilita la edición en el lugar.
Renombrar un documento en ATLAS.ti no cambia el nombre del archivo fuente original. Como se describe en Agregar documentos, los documentos se copian en la biblioteca de ATLAS.ti al agregarlos a un proyecto, y ATLAS.ti ya no necesita los archivos fuente originales.
Eliminar documentos
Si ha agregado documentos por error o desea quitarlos del proyecto por otras razones, puede eliminarlos.
Seleccione uno o varios documentos en el Explorador de proyectos o en el Administrador de documentos, haga clic derecho y seleccione Eliminar.
Si elimina un documento por error, siempre puede usar la opción Deshacer en la barra de herramientas de acceso rápido.
Después de eliminar documentos, la numeración consecutiva puede quedar desajustada. Para renumerar los documentos en orden consecutivo, seleccione en el menú principal Documentos > Renumerar documentos y citas.
Duplicar documentos
Si necesita un documento para distintos propósitos —por ejemplo, desea verlo desde diferentes ángulos y codificar distintos aspectos, o asociarlo con diferentes transcripciones—, puede duplicarlo. Todo el trabajo realizado hasta el momento en el documento, como el comentario del documento, todas las citas y sus comentarios, todos los hipervínculos, todos los códigos y memos vinculados, también se duplicará.
Abra el Administrador de documentos y seleccione uno o más documentos que desee duplicar.
Haga clic en la pestaña Herramientas y seleccione Duplicar documento(s).
Los documentos duplicados se añadirán al final de la lista de documentos. Tienen el mismo nombre que el documento original más un número consecutivo entre paréntesis.
En cuanto al tamaño del proyecto, los archivos de la biblioteca no se duplican. El documento duplicado utiliza el mismo archivo fuente que el documento original.
Renumerar todos los documentos
Esta opción es útil después de haber eliminado uno o más documentos de un proyecto, lo cual genera saltos en la secuencia de números de documento. Puede eliminar estos saltos renumerando todos los documentos:
En el menú principal, seleccione Documentos > Renumerar documentos y citas.
Orden de clasificación de documentos definido por el usuario
Actualmente esto solo es posible en la versión para Windows.
Gestión del proyecto
Abrir un proyecto
Para abrir un proyecto, haga clic en un proyecto en la Pantalla de bienvenida, o si ya tiene un proyecto abierto y desea abrir otro, seleccione Proyecto > Abrir.
Guardar un proyecto
Para guardar un proyecto, seleccione Proyecto > Guardar en el menú principal, o use la combinación de teclas command + S.
El proyecto se guarda como archivo interno de ATLAS.ti en la biblioteca de ATLAS.ti. La ubicación predeterminada de la biblioteca es la carpeta de la aplicación en su equipo. Consulte ¿Dónde almacena ATLAS.ti los datos del proyecto?
Es posible cambiar la ubicación predeterminada de la biblioteca de ATLAS.ti o crear nuevas bibliotecas. Consulte Acerca de las bibliotecas de ATLAS.ti.
Si desea guardar una copia externa de su proyecto, debe exportarlo. Consulte Exportar proyecto.
Cambiar el nombre de un proyecto
Seleccione Proyecto > Cambiar nombre en el menú principal.
Eliminar un proyecto
Puede eliminar proyectos desde la pantalla de bienvenida, ya sea al iniciar ATLAS.ti o seleccionando Proyecto > Abrir.
Seleccione un proyecto en la pantalla de bienvenida, haga clic derecho en él y seleccione la opción Eliminar.
Se le pedirá que confirme la eliminación, ya que esta acción es permanente y no puede deshacerse.
Protección con contraseña
Para establecer una contraseña para su proyecto, primero debe cargarlo.
Seleccione Proyecto > Cambiar contraseña.
ATLAS.ti Scientific Software GmbH no guarda sus contraseñas. No podemos acceder, leer ni recuperar su contraseña. Si no recuerda su contraseña, ya no podrá acceder a su proyecto.
Los datos del proyecto de ATLAS.ti se guardan en una biblioteca
Trabajar con la biblioteca de ATLAS.ti
La ubicación predeterminada para los archivos de proyecto de ATLAS.ti es una subcarpeta dentro de la carpeta de soporte de la aplicación en su Mac. Sin embargo, también puede crear una ubicación definida por el usuario donde se almacenan todos sus datos de ATLAS.ti.
Aspectos importantes a tener en cuenta
-
Cada usuario trabaja dentro de su propia biblioteca de ATLAS.ti.
-
Cada usuario puede definir dónde debe ubicarse la biblioteca de ATLAS.ti. Esta ubicación puede estar en su equipo, en un servidor o en una unidad externa.
-
No es posible utilizar un servicio de sincronización en la nube como Dropbox, ya que el modo específico de funcionamiento de estos sistemas puede comprometer la integridad de la biblioteca de ATLAS.ti.
-
Es posible trabajar con múltiples bibliotecas. En teoría, podría crear una nueva biblioteca vacía cada vez que inicie un nuevo proyecto. Sin embargo, esto requiere una gestión cuidadosa de los datos por su parte, ya que deberá llevar un seguimiento de la ubicación de todas estas bibliotecas.
Cambiar la ubicación de la biblioteca
En el menú principal, seleccione ATLAS.ti > Cambiar biblioteca.
Se abrirá un asistente que le guiará a través del proceso. La siguiente elección que deberá hacer es si desea abrir una biblioteca existente, mover la biblioteca a una ubicación diferente o crear una nueva biblioteca vacía.
Mover la biblioteca a una ubicación diferente: Elija esta opción si desea o necesita mover su biblioteca actual a una ubicación diferente, por ejemplo porque ya no desea trabajar en la unidad C. Es posible conservar una copia de la biblioteca en la ubicación anterior.
Crear una nueva biblioteca: Esta opción le permite crear una nueva biblioteca en la ubicación que elija. Si ya tiene proyectos, ninguno de ellos se trasladará a la nueva biblioteca. Para llenar esta biblioteca, puede crear nuevos proyectos desde cero o importar archivos de paquete de proyecto que haya exportado previamente de otras bibliotecas.
Abrir una biblioteca existente: Elija esta opción si trabaja con múltiples bibliotecas y desea acceder a una biblioteca existente en una ubicación diferente.
Después de realizar su elección, haga clic en Continuar.
-
Si seleccionó abrir una biblioteca existente: Seleccione la ubicación de esa biblioteca.
-
Si seleccionó mover la biblioteca: Seleccione la ubicación donde desea que esté esta biblioteca. Puede conservar una copia del estado actual de la biblioteca en la ubicación actual. Tenga en cuenta que esta copia no se actualiza si continúa trabajando con la biblioteca en la nueva ubicación.
-
Si seleccionó crear una nueva biblioteca vacía: Seleccione dónde se creará esta nueva biblioteca. Tras confirmar la nueva ubicación, la pantalla de apertura estará vacía y podrá comenzar a llenarla con nuevos proyectos.
Una nota del servicio de asistencia: Sabemos que los datos de su proyecto son muy valiosos para usted y que no desea perderlos. Por ello, seleccione una ubicación sensata para la biblioteca de ATLAS.ti. Por ejemplo: no la guarde en el escritorio. Probablemente disponga de una carpeta donde almacena todos los datos relacionados con su proyecto. Si no puede o no desea usar la ubicación predeterminada de ATLAS.ti, le recomendamos crear una subcarpeta para su trabajo relacionado con ATLAS.ti dentro de su carpeta de proyecto, y dentro de esa subcarpeta, una carpeta dedicada para su biblioteca. ¡Asegúrese de que su carpeta de proyecto esté incluida en cualquier rutina de copia de seguridad automática de su equipo!
Crear una copia de seguridad del proyecto
Los proyectos de ATLAS.ti no pueden abrirse con versiones anteriores de ATLAS.ti.
Exporte sus proyectos de forma regular y guarde los archivos de paquete en un lugar seguro. Si algo le ocurre a su equipo, seguirá teniendo una copia de su proyecto a la que recurrir.
Para crear una copia de seguridad de su proyecto, debe exportarlo y guardarlo como archivo de paquete de proyecto en su equipo, en una unidad externa, en un servidor o en un servicio en la nube.
La Nube de proyectos de ATLAS.ti también puede servir como copia de seguridad útil. No olvide cargar los cambios realizados en sus proyectos.
Un archivo de paquete de proyecto funciona como copia de seguridad externa de su proyecto, independiente de la instalación de ATLAS.ti en su equipo.
-
El archivo de paquete de proyecto contiene todos los documentos que ha agregado o vinculado a un proyecto, así como el archivo de proyecto que incluye toda la codificación, los códigos, todos los memos, comentarios, redes y vínculos. Los archivos de audio o video de gran tamaño pueden excluirse del paquete.
-
Los archivos de paquete de proyecto también se utilizan para transferir proyectos entre equipos. Pueden ser leídos tanto por ATLAS.ti para Mac como por ATLAS.ti para Windows. Consulte Transferencia de proyectos.
-
Si su proyecto contiene documentos vinculados, estos pueden excluirse al crear un archivo de paquete de proyecto. Consulte "Crear paquetes parciales" a continuación.
Exportar un proyecto
Para exportar su proyecto con el fin de guardarlo como copia de seguridad o para transferirlo a un equipo diferente:
En el menú principal, seleccione Proyecto > Exportar > Proyecto.
Si su proyecto no contiene archivos multimedia, se abre el cuadro de diálogo Guardar archivo. Si contiene archivos multimedia, consulte Exportar archivos de paquete parcial.
Seleccione una ubicación para guardar el archivo de paquete de proyecto.
El nombre predeterminado del paquete será el nombre del proyecto. Puede cambiar el nombre del archivo de paquete de proyecto en este momento, lo que sin embargo no cambia el nombre del proyecto que contiene el paquete.
Seleccione un nombre y una ubicación donde desee guardar el proyecto y haga clic en Guardar.
Piense en el archivo de paquete de proyecto como una bolsa que contiene su proyecto. Poner una etiqueta diferente en el exterior de la bolsa no cambia nada de lo que hay en su interior, que es su proyecto con todos sus segmentos codificados, comentarios, memos, redes, etc. y todos los documentos que se han agregado. Cuando importe el paquete de proyecto, el nombre del proyecto tras la importación seguirá siendo el nombre original. Si desea cambiar el nombre del archivo de proyecto, deberá hacerlo durante el proceso de importación del proyecto o en la pantalla de apertura. Consulte Gestión del proyecto.

Exportar un proyecto en formato XML
Puede exportar un proyecto de ATLAS.ti para Mac en formato XML. Esto abre numerosas posibilidades para su uso externo como formato no propietario, por ejemplo, para archivar datos. El archivo de datos cualitativos de Essex (actualmente UK Data Service) utilizó originalmente el formato XML de ATLAS.ti como base para su estándar. Otro caso de uso es importar datos a otras aplicaciones.
En el menú principal, seleccione Proyecto > Exportar > XML.
Exportar un paquete parcial si el proyecto contiene archivos multimedia
Si su proyecto contiene archivos multimedia de gran tamaño, puede excluirlos. Esto reduce el tamaño del archivo de paquete. Al preparar un paquete de proyecto parcial, asegúrese de hacer también una copia de seguridad de los archivos multimedia que excluyó del paquete. Si importa el proyecto en una etapa posterior, podrá volver a vincular los archivos excluidos al proyecto durante la importación o después de ella.
Si exporta un proyecto que contiene archivos multimedia, se abre la siguiente ventana:
Deseleccione todos los archivos que NO deben incluirse en el paquete y, a continuación, haga clic en Exportar.
Transferencia de proyectos
Puede transferir proyectos de ATLAS.ti a la versión web y viceversa. Esta última es la opción recomendada: comience su trabajo en la versión Web, especialmente si le interesa la codificación sincrónica con un equipo. Si desea utilizar la funcionalidad de la versión de escritorio, exporte su proyecto e impórtelo en la versión de escritorio. Si transfiere un proyecto de escritorio a ATLAS.ti Web, el formato del documento cambia, ya que en línea se trabaja en un navegador. Por lo tanto, no es posible configurar un proyecto de trabajo en equipo mixto donde algunas personas trabajen en la versión de escritorio y otras en la versión web.
Los proyectos de ATLAS.ti no pueden abrirse con versiones anteriores de ATLAS.ti.
Para transferir un proyecto a un equipo diferente, por ejemplo, para compartirlo con miembros del equipo, es necesario crear un archivo de paquete de proyecto.
Un archivo de paquete de proyecto contiene todos los documentos que ha agregado o vinculado a un proyecto. Además, contiene el archivo de proyecto con todas las codificaciones, códigos, memos, comentarios, redes y vínculos.
Para crear un archivo de paquete de proyecto:
En el menú principal, seleccione Proyecto > Exportar > Proyecto.
Si su proyecto no contiene archivos multimedia, se abre el cuadro de diálogo Guardar archivo. Si su proyecto contiene archivos multimedia, consulte Crear archivos de paquete parcial.
El nombre predeterminado del paquete será el nombre del proyecto. Puede cambiar el nombre del archivo de paquete de proyecto en este momento, lo que sin embargo no cambia el nombre del proyecto que contiene el paquete.
Seleccione un nombre y una ubicación para guardar el archivo de paquete de proyecto y haga clic en Guardar.
Piense en el archivo de paquete de proyecto como una bolsa que contiene su proyecto. Poner una etiqueta diferente en el exterior de la bolsa no cambia nada de lo que hay en su interior, que es su proyecto con todos sus segmentos codificados, comentarios, memos, redes, etc. y todos los documentos que se han agregado. Cuando importe el paquete de proyecto, el nombre del proyecto tras la importación seguirá siendo el nombre original. Si desea cambiar el nombre del archivo de proyecto, deberá hacerlo durante el proceso de importación del proyecto o en la pantalla de apertura. Consulte Gestión del proyecto.
Crear una instantánea del proyecto
Un duplicado de proyecto es una copia del archivo de proyecto interno de ATLAS.ti. Los motivos para crear un duplicado son:
- preservar determinadas etapas del proyecto para revisarlas más adelante.
- como versión de reserva antes de una fusión, por si el resultado es diferente de lo esperado y ya se ha guardado el proyecto fusionado. Consulte Fusión de proyectos.
- como copia del proyecto para usar como plantilla para otro proyecto.
- como copia del proyecto para preparar un análisis de acuerdo entre codificadores. Consulte Acuerdo entre codificadores.
Para crear un duplicado de proyecto,
En la Pantalla de bienvenida, seleccione un proyecto, haga clic derecho y seleccione Duplicar.
Si tiene un proyecto abierto, puede volver a la Pantalla de bienvenida seleccionando: Proyecto > Abrir.
Al igual que los archivos de proyecto de ATLAS.ti, los duplicados se guardan internamente en el entorno de ATLAS.ti. Un duplicado tiene el mismo ID que el proyecto a partir del cual se crea.
¿Dónde almacena ATLAS.ti los datos del proyecto?
De forma predeterminada, los proyectos de ATLAS.ti y todos los documentos que se agregan a un proyecto se almacenan en una subcarpeta de la carpeta de soporte de la aplicación:
~/Library/Application Support/ATLAS.ti.
La biblioteca de ATLAS.ti es una carpeta del sistema y no está destinada al acceso directo por parte del usuario. ¡Los archivos en esta carpeta no pueden usarse fuera de ATLAS.ti!
Esta ubicación predeterminada para almacenar los datos de ATLAS.ti puede cambiarse. Consulte Trabajar con la biblioteca de ATLAS.ti.
Trabajar con grupos
Los grupos en ATLAS.ti le ayudan a clasificar, organizar y filtrar las distintas entidades. Los grupos están disponibles para documentos, códigos, memos y redes.
Características comunes a todos los grupos:
- Una entidad puede estar en varios grupos a la vez. Por ejemplo, si asigna un documento al grupo gender::female, también puede asignarlo a otros grupos como location::urban o family status::single.
- Si hace clic en un grupo en un administrador, activa un filtro (véase más adelante). Entonces solo se muestran los elementos que pertenecen a los grupos seleccionados.
- Puede combinar grupos mediante operadores booleanos. Consulte, por ejemplo, Explorar datos codificados.
- Puede guardar una combinación de grupos para reutilizarla en forma de grupo inteligente.
- Puede establecer grupos como filtro global.
No existen grupos para las citas, ya que los códigos ya cumplen esta función. Los códigos agrupan las citas que tienen un significado similar. Por eso, en lugar de grupos, en el panel lateral del Administrador de citas se muestran los códigos.
Aplicación de los grupos de documentos
Tutorial en vídeo: Organización de documentos y grupos de documentos.
Con frecuencia, los datos provienen de distintas fuentes, ubicaciones o participantes con diferentes características sociodemográficas. Para facilitar el manejo de los distintos tipos de datos, estos pueden organizarse en grupos de documentos.
También puede usar grupos de documentos con fines administrativos en proyectos de equipo cuando distintos codificadores deban codificar diferentes documentos. En ese caso, puede crear un grupo con todos los documentos para el codificador 1, otro grupo con los documentos para el codificador 2, y así sucesivamente.
Tutorial en vídeo: Organización de los datos del proyecto - Crear grupos de documentos
Otra aplicación es el uso de grupos de documentos para comparaciones analíticas en la Tabla código-documento.
Los grupos de documentos también pueden añadirse a las Redes y puede mostrar qué códigos se han aplicado a cada grupo.
Aplicación de los grupos de códigos
Los grupos de códigos pueden usarse para clasificar y organizar los códigos en el Administrador de códigos. Los grupos de códigos facilitan la navegación por los códigos en el Administrador de códigos como filtro local. Véase más adelante.
Los grupos de códigos pueden usarse como filtros globales en los análisis.
Los grupos de códigos también pueden usarse en la Tabla código-documento para comparaciones de casos.
Los usuarios con frecuencia confunden los grupos de códigos con un tipo de código de orden superior, lo cual no es correcto. Sin embargo, pueden ser muy útiles para construir un sistema de codificación.
Aplicación de los grupos de memos
Los grupos de memos resultan prácticos cuando se han escrito muchos memos. Por ejemplo, podría agrupar los memos por función: notas metodológicas, memos de equipo, diarios de investigación, análisis.
Si tiene varios memos que contienen respuestas a una pregunta de investigación, puede agrupar todos esos memos.
Si tiene varios memos con contenido para una sección particular del informe de investigación, puede crear un grupo de memos para ellos.
Puede encontrar más información sobre el trabajo con memos aquí: Memos y comentarios.
Los grupos como filtros
Los grupos aparecen en los paneles laterales del administrador de documentos, códigos, memos y redes.
Haga clic en uno o más grupos para filtrar la lista de elementos. Para seleccionar varios grupos, mantenga presionada la tecla Cmd.
Una vez que haya establecido uno o más grupos como filtro, aparece una barra amarilla encima de la lista de entidades que indica a) que se ha establecido un filtro y b) cuál es.
Para restablecer el filtro y ver todas las entidades de nuevo, haga clic en el signo menos (-) en la esquina superior derecha de la barra amarilla.
También es posible ejecutar consultas simples con los operadores AND y OR:
En cuanto seleccione más de un grupo, verá la palabra any (cualquiera) en azul en la barra de filtro. Esto significa que la operación predeterminada es combinar los elementos de los grupos seleccionados con OR.
Si desea filtrar por la intersección de dos o más grupos, haga clic en la palabra "any" y cámbiela a all (todos). Este es el operador booleano AND.
Un ejemplo sería filtrar por todos los participantes femeninos que viven en una región urbana. Para ello es necesario haber agrupado los documentos por estos dos criterios:
-
gender::female
-
region::urban
El filtro mostrará entonces el siguiente texto: Mostrar documentos en todos los grupos: gender::female, region::urban.
Las mismas opciones están disponibles para todos los tipos de entidades.
Crear y renombrar grupos
Puede crear grupos de diversas maneras y en distintos lugares del software.
Crear grupos en un administrador
Abra el Administrador de documentos, p. ej., haciendo doble clic en la rama Documentos en el Explorador de proyecto, o seleccionando Administrador de documentos en el menú desplegable Documentos de la barra de herramientas.
Seleccione varios documentos y arrástrelos y suéltelos en el panel lateral izquierdo. Puede usar la técnica de selección estándar manteniendo presionada la tecla Cmd o Mayús. ATLAS.ti crea automáticamente un grupo y le asigna un nombre. Haga clic izquierdo en el nombre para modificarlo.
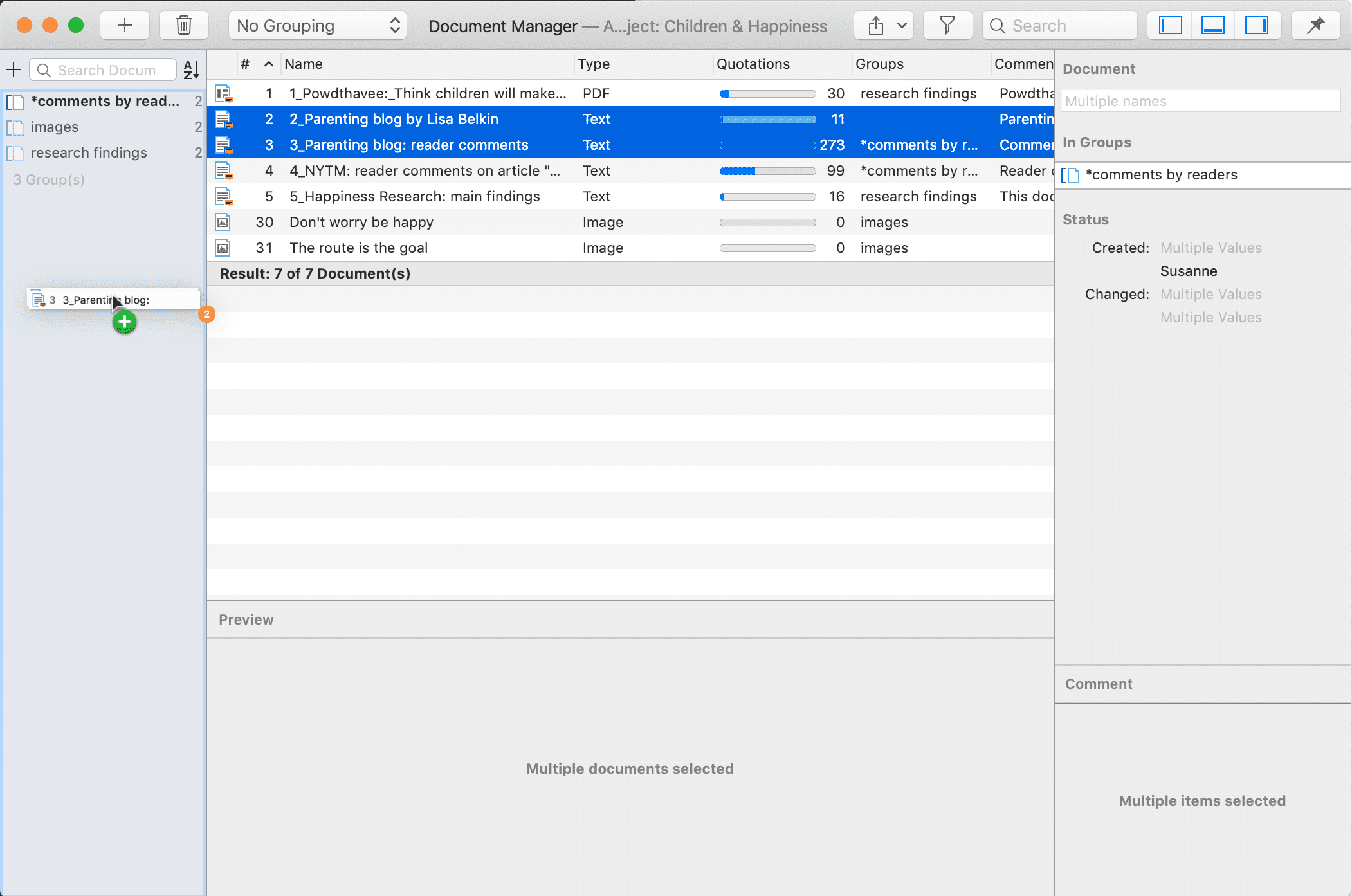
Otra forma de crear grupos en un administrador es:
Seleccione varios elementos en un administrador, haga clic derecho y seleccione la opción Agrupar documentos / Códigos / Memos / Redes en el menú contextual. ATLAS.ti crea un grupo, le asigna un nombre y abre el Administrador de grupos correspondiente. Cambie el nombre predeterminado para adaptarlo a sus necesidades.
Crear grupos en el Explorador de proyecto
Seleccione varios elementos en una rama del Explorador de proyecto, haga clic derecho y seleccione la opción Crear grupo en el menú contextual. Introduzca un nombre y haga clic en Crear.
Crear grupos en el Administrador de grupos
Abra el Administrador de grupos seleccionándolo en el menú desplegable de la entidad correspondiente en la barra de herramientas. Alternativamente, encontrará una opción Mostrar Administrador de grupos en el menú principal Documento / Código / Memo y Red.
Para crear un nuevo grupo, haga clic en el botón + e introduzca un nombre.
A continuación, seleccione uno o más elementos en el panel: "No está en el grupo" y muévalos al panel izquierdo "En el grupo" haciendo clic en el botón con la flecha izquierda (<). También puede hacer doble clic en cada elemento que desee mover.
Crear grupos de documentos en el Lector de citas
En ocasiones, es necesario codificar primero los datos para encontrar información relevante, como años de experiencia laboral, habilidades especiales, actitudes sobre algo, relaciones con otras personas, etc. Para ello se necesita una opción que permita crear grupos de documentos basados en los resultados de consultas.
Puede crear grupos de documentos basados en cualquier dato que recupere. Puede ser una consulta simple como hacer doble clic en un código, una consulta en el Administrador de citas o en la Herramienta de consulta, o los resultados de la Tabla código-documento o la Tabla de co-ocurrencia de códigos.
Haga clic en el botón Opciones en el Lector de citas y seleccione Crear grupo de documentos en el menú desplegable.
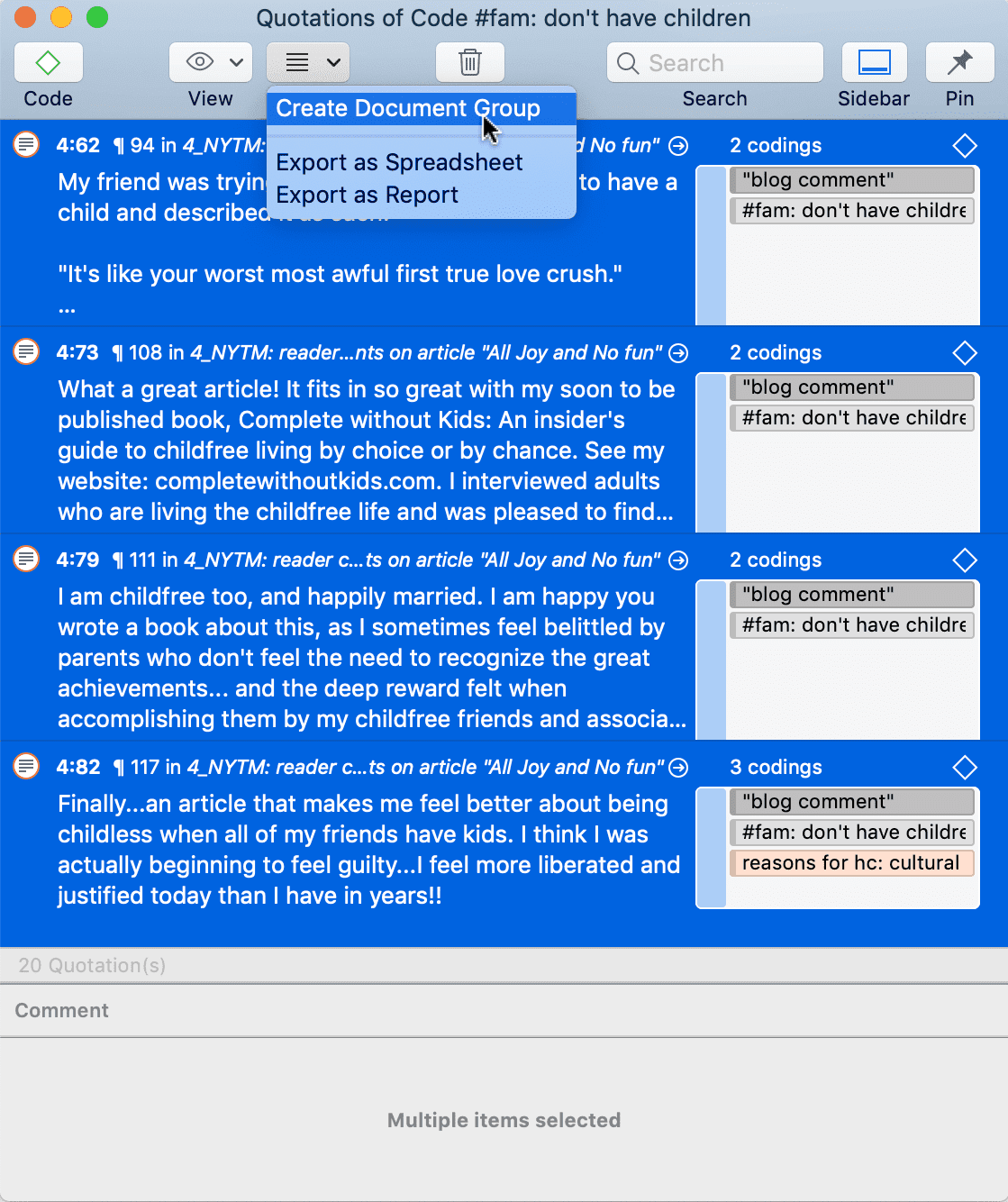
Renombrar un grupo
Seleccione un grupo en un administrador o en el Administrador de grupos, haga clic izquierdo y renómbrelo; o renómbrelo en el inspector del panel derecho.
Eliminar grupos
Quitar miembros de un grupo
Puede quitar miembros de un grupo en cuatro ubicaciones diferentes:
Explorador de proyecto
Abra la rama de un grupo, seleccione uno o más elementos que no desea tener en el grupo, haga clic derecho y seleccione Quitar del grupo en el menú contextual.
En los administradores
Abra un administrador y seleccione un grupo.
Seleccione uno o más elementos de la lista que ya no desea tener en el grupo, haga clic derecho en cualquiera de los elementos seleccionados y seleccione Quitar del grupo en el menú contextual.
Área de filtro en los administradores
Abra un administrador y seleccione un grupo.
Seleccione uno o más elementos de la lista que ya no desea tener en el grupo, haga clic derecho en el grupo en el área de filtro y seleccione Quitar del grupo en el menú contextual.
Quitar miembros de un grupo en el Administrador de grupos
Abra el Administrador de grupos haciendo doble clic en un grupo en el Explorador de proyecto.
Alternativamente:
Busque la opción Mostrar Administrador de grupos en el menú principal Documento / Código / Memo y Red.
A continuación, seleccione uno o más elementos en el panel: "En el grupo" y muévalos al panel derecho "No está en el grupo".
Eliminar grupos
Seleccione uno o más grupos en el Explorador de proyecto o en el área de filtro de un administrador.
Haga clic derecho y seleccione Eliminar en el menú contextual.
También es posible eliminar uno o varios grupos en el Administrador de grupos.
Importar y exportar grupos de documentos
Puede exportar e importar la lista de documentos y sus grupos hacia y desde Excel.
La exportación de los datos ofrece una visión general de todos los grupos de documentos y sus miembros. También puede utilizarse como punto de partida para preparar un archivo Excel para la importación.
Es posible que desee importar una tabla de grupos de documentos si ya dispone de un archivo Excel con información sobre cada documento, como género, niveles educativos, ubicación, etc.
El contenido de la Tabla de grupos de documentos es el siguiente:
- Primera columna: nombre del documento.
- Segunda columna y siguientes: grupos de documentos o atributos de documentos.
Dado que los grupos de documentos en ATLAS.ti son dicotómicos, los grupos de documentos aparecen en las columnas, y las celdas contienen un 0 si el documento no pertenece al grupo, y un 1 si pertenece al grupo.
Si no sigue las convenciones de nomenclatura de ATLAS.ti (véase más adelante), la tabla tendrá el siguiente aspecto:

Si utiliza la convención de nomenclatura de ATLAS.ti para grupos de documentos: nombre del atributo::etiqueta o valor del atributo, entonces ATLAS.ti usa el nombre del atributo como encabezado de columna y la etiqueta o el valor del atributo para cada celda. Por ejemplo, si tiene los siguientes grupos:
- education::high school
- education::some college
- education::University degree
- gender::male
- gender::female
- has children::yes
- has children::no
- marital status: single
- marital status: married
- marital status: divorced
- number of children:1
- number of children:2
....la tabla de Excel tendrá el siguiente aspecto:
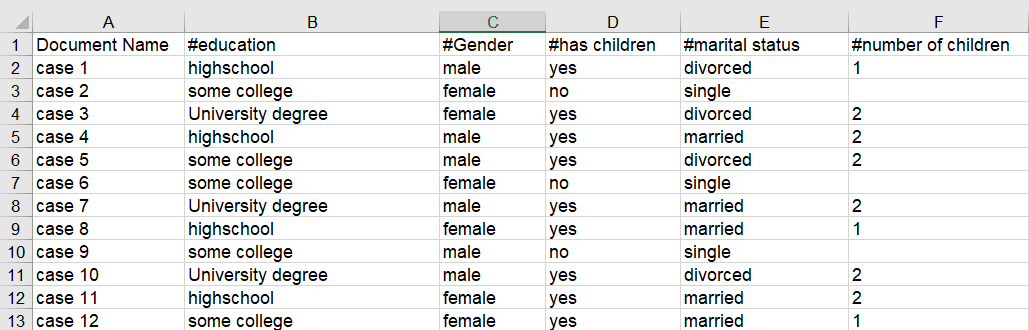
Exportar grupos de documentos a Excel
Seleccione Documento > Exportar > Grupos de documentos. Seleccione una ubicación para guardar el archivo Excel. Acepte el nombre predeterminado o cámbielo. Haga clic en Guardar.
Si utiliza la convención de nomenclatura para grupos de documentos descrita anteriormente, la tabla mostrará el formato más convencional con atributos/variables como encabezados de columna y los distintos valores para cada variable en las celdas de la tabla.
Importar grupos de documentos desde Excel
Si desea preparar una tabla para importar, la forma más sencilla es exportar primero una tabla. De este modo, generará una tabla que ya contiene todos los nombres de documentos en el orden en que aparecen en ATLAS.ti.
Exporte una tabla de grupos de documentos (véase más arriba).
Agregue los atributos del documento como encabezados de columna.
-
Si hay múltiples valores para un atributo, agregue el prefijo ´#´.
-
Si no agrega un prefijo, el documento se asigna al grupo si el valor de la celda es 1.
Introduzca los valores para cada documento en las celdas de la tabla.
-
Si no hay ninguna entrada en una celda, el documento no se asigna a ningún grupo.
-
Si dos o más valores del mismo atributo se aplican al documento, introduzca los valores separados por una coma.
A continuación se muestran dos ejemplos:
| Nombre del documento | #género | #grupo de edad | le gusta el chocolate | #bebida favorita |
|---|---|---|---|---|
| doc 1 | male | 1 | 1 | cola |
| doc 2 | female | 2 | milk,beer | |
| doc 3 | female | 2 | 1 | juice |
| doc 4 | male | 1 | tea, coffee, cola | |
| doc 5 | male | 3 | 1 | coffee |
Guarde la tabla en Excel.
Ejemplo de tabla Excel lista para importar a ATLAS.ti:

Importar la tabla
Cierre la tabla en Excel antes de importarla.
Seleccione Documento > Importar > Grupos de documentos. Seleccione el archivo Excel y haga clic en Abrir.
Si desea agregar nuevos grupos aunque ya existan algunos, puede proceder como se describe. Simplemente deje los grupos existentes en la tabla. ATLAS.ti los reconocerá y no los creará de nuevo.
El nivel de citas de ATLAS.ti
Tutorial en video: Trabajar con citas
Christina Silver, experta en software de análisis cualitativo de datos asistido por computadora, explica el nivel de citas de ATLAS.ti de la siguiente manera:
"Cuando se crea una cita, se está marcando un segmento de datos que puede recuperarse y revisarse posteriormente. Es posible que en ese momento ya se sepa cómo y por qué es interesante o significativo; en ese caso, se puede capturar de inmediato, ya sea cambiándole el nombre, comentándolo, codificándolo, vinculándolo a otra cita o a un memo, por ejemplo. Si aún no se sabe, simplemente se puede crear la cita y volver a ella más tarde, quizás cuando se tenga una mejor visión general del conjunto de datos en su totalidad y se esté listo para conceptualizar el significado en relación con los objetivos de investigación."
"Una de mis cosas favoritas de ATLAS.ti es que las citas se pueden visualizar y trabajar en una ventana gráfica, es decir, las redes de ATLAS.ti. El contenido de las citas puede verse dentro de la red, y las citas pueden vincularse, comentarse y codificarse en ese espacio visual. Esto es muy útil si se prefiere trabajar visualmente o se está acostumbrado a analizar datos cualitativos manualmente con marcadores de colores, pizarras, notas adhesivas, etc. Las redes también pueden utilizarse como espacios de interrogación visual; por ejemplo, para revisar citas que tienen más de un código aplicado, lo cual es muy poderoso. Todo lo que se hace en la red está conectado en todo el proyecto de ATLAS.ti."
El nivel de citas de ATLAS.ti ofrece una capa adicional de análisis. En ATLAS.ti no es necesario codificar los datos de inmediato, como ocurre en la mayoría de los demás software CAQDAS. Primero se puede revisar los datos y establecer citas, resumir las citas en el nombre de la cita y escribir una interpretación en el campo de comentario. Véase Trabajar con citas. Esto es útil para muchos enfoques de análisis interpretativo en el proceso de desarrollo de conceptos. Una vez que se tienen ideas para los conceptos, se puede empezar a codificarlos.
Esto evita caer en la trampa de la codificación, es decir, generar demasiados códigos. Los códigos que solo pueden aplicarse a uno o dos segmentos de los datos no son muy útiles. Los nombres de los códigos deben ser suficientemente abstractos para poder aplicarse a más que unas pocas citas.
También se verá más adelante en el proceso de análisis que ninguna de las herramientas de análisis adicionales, como la Tabla de documentos por código o la Tabla de co-ocurrencia de códigos, parece ser muy útil.
Si se generan 1000 o más códigos, conviene considerar qué se puede hacer con las citas en su lugar. A partir de ello, se deben desarrollar códigos en un nivel más abstracto que permitan construir un sistema de códigos bien estructurado.
Crear citas en documentos de texto
Al codificar datos, las citas se crean automáticamente. Véase Codificar datos. Sin embargo, también se pueden crear citas sin codificar. Para hacerlo:
Resalte una sección en el texto, haga clic derecho y seleccione la opción Crear cita. Como alternativa, también puede usar el atajo cmd+H.

Una vez creada la cita, aparece una barra azul en el área de margen y una entrada en el Administrador de citas y en el árbol de documentos del Explorador de proyectos.
Crear citas en documentos PDF
Un archivo PDF de texto también puede contener imágenes, como fotografías, gráficos o tablas. En ATLAS.ti se pueden crear citas para texto e imágenes en documentos PDF.
Selección de texto: Seleccione el texto igual que en un archivo Word. Asegúrese de colocar el cursor justo junto a una letra.
Selección de un elemento gráfico: Al igual que al seleccionar un área en un archivo gráfico, dibuje un área rectangular con el mouse. Véase también Crear citas gráficas.
Seleccione un segmento en el documento PDF, haga clic derecho y seleccione la opción Crear cita. Como alternativa, también puede usar el atajo cmd+H.

Los archivos PDF pueden ser de texto o de imagen. A veces los usuarios agregan accidentalmente un PDF de imagen y no entienden por qué solo pueden crear citas gráficas y no pueden seleccionar texto. Si esto ocurre, es necesario recrear el archivo PDF, por ejemplo, ejecutando un escáner OCR sobre el archivo PDF de imagen. En muchos creadores de PDF actuales esto es una opción del software, sin necesidad de realizar un escaneo físico adicional.
Modificar los límites de una cita
Modificar la longitud de una cita es sencillo.
Si se selecciona una cita, por ejemplo haciendo clic en la barra del área de margen, aparece una línea azul con un punto al inicio y al final de la cita. Mueva la posición de inicio o de fin a una ubicación diferente según desee acortar o alargar la cita. Esto se aplica a todos los tipos de medios.

ID y referencia de cita
Cada cita tiene un ID compuesto por dos números:

El ID 2:15, por ejemplo, significa que la cita proviene del documento 2 y es la decimoquinta cita creada en ese documento. Se encuentra en el párrafo 10. La cita 6:1 proviene del documento 6; es la primera cita creada en el documento 6 y se puede encontrar en los párrafos 67 a 71.
Las citas se numeran en orden cronológico y no secuencial. Si se desea cambiar este orden, véase Trabajar con citas.
Agregar nombres de citas y escribir comentarios
Poder nombrar cada cita tiene varias aplicaciones útiles.
- Permite revisar rápidamente las citas en la vista de lista.
- Se puede usar el campo de nombre para parafrasear una cita, como requieren algunos enfoques de análisis de contenido, o para escribir un breve resumen.
- Se puede usar el campo de nombre para codificación detallada (codificación línea a línea en la Teoría Fundamentada; codificación inicial en la Teoría Fundamentada Constructivista, o según otros enfoques interpretativos) en lugar de aplicar códigos. Si ya se aplican códigos durante esta fase, se terminarán generando demasiados códigos inútiles para el análisis posterior. Véase Construir un sistema de códigos.
- Agregar títulos a citas multimedia. Véase Trabajar con datos multimedia.

Para agregar un nombre a una cita, selecciónela y haga clic con el botón izquierdo en el campo de nombre, o agregue un texto en el campo de nombre en el inspector de la parte derecha. Puede escribir información adicional sobre la cita, como un resumen o interpretación, en el campo de comentario que también se encuentra en el inspector.
Si se selecciona una cita en el Administrador de citas, aparece una previsualización de la cita en el panel inferior a la lista de citas. Esto se aplica a todos los formatos de archivo de datos.
Para saber cómo crear citas en documentos de audio y video, véase Crear citas multimedia.
Para saber cómo crear citas en documentos de imagen, véase Crear citas de imagen.
Crear citas en documentos de imagen
Si se trabaja con imágenes, videos o instantáneas geográficas, o documentos PDF de imagen:
Mueva el puntero del mouse hasta la esquina superior izquierda de la sección rectangular que va a crear, mantenga presionado el botón izquierdo del mouse y arrástrelo hasta la esquina inferior derecha del rectángulo. Suelte el botón del mouse. Ahora se ha creado una selección y el rectángulo quedará resaltado.
Haga clic derecho y seleccione la opción Crear cita. Como alternativa, también puede usar el atajo Cmd+H.
Para modificar una cita de imagen, simplemente cambie el tamaño del rectángulo.
Se recomienda agregar un nombre a cada cita de imagen como título o descripción. Esto facilita el análisis posterior.
Las citas gráficas se pueden previsualizar en el Administrador de citas; pueden insertarse en redes y se incluyen como fragmentos gráficos en los informes.
Crear citas en documentos PDF
Un archivo PDF de texto también puede contener imágenes, como fotografías, gráficos o tablas. En ATLAS.ti se pueden crear citas para texto e imágenes en documentos PDF.
Selección de texto: Seleccione el texto igual que en un archivo Word. Asegúrese de colocar el cursor justo junto a una letra.
Selección de un elemento gráfico: Al igual que al seleccionar un área en un archivo gráfico, dibuje un área rectangular con el mouse. Véase también Crear citas gráficas.
Seleccione un segmento en el documento PDF, haga clic derecho y seleccione la opción Crear cita. Como alternativa, también puede usar el atajo Cmd+H.
Los archivos PDF pueden ser de texto o de imagen. A veces los usuarios agregan accidentalmente un PDF de imagen y no entienden por qué solo pueden crear citas gráficas y no pueden seleccionar texto. Si esto ocurre, es necesario recrear el archivo PDF, por ejemplo, ejecutando un escáner OCR sobre el archivo PDF de imagen. En muchos creadores de PDF actuales esto es una opción del software, sin necesidad de realizar un escaneo físico adicional.
Trabajar con datos multimedia
En esta sección se describen las siguientes opciones:
- Crear citas multimedia
- Crear citas multimedia mientras se escucha el archivo de audio o se visualiza el archivo de video
- Visualización de citas multimedia
- Codificar citas multimedia
- Activar y reproducir citas multimedia
- Ajustar el tamaño de las citas multimedia
- Renombrar una cita multimedia
- Capturar instantáneas de fotogramas de video como documentos de imagen para análisis adicional
Crear citas multimedia
También puede codificar archivos multimedia de forma inmediata. Sin embargo, dado que los archivos de video especialmente contienen mucha más información en comparación con el texto, a menudo resulta más sencillo recorrer y segmentar primero el archivo de audio o video, es decir, crear citas antes de codificar.
Para crear una cita de audio o video, mueva el puntero del ratón sobre la forma de onda de audio y marque una sección haciendo clic con el botón izquierdo del ratón donde desee que comience. Luego arrastre el cursor hasta la posición final. Se muestran los tiempos de las posiciones de inicio y fin, así como la duración total del segmento.
En cuanto suelte el ratón, se crea una cita y verá el límite azul de la cita en el área del margen.
Crear citas multimedia mientras escucha/visualiza
También puede crear una cita de audio o video mientras escucha o visualiza un documento. Para ello, puede utilizar los botones Marcar inicio de cita y Crear cita de la barra de herramientas sobre la línea de tiempo, o las teclas de acceso directo (véase más abajo).
Continúe escuchando o visualizando, y estableciendo citas.
Usar teclas de acceso directo
Para marcar la posición de inicio: use (<) o (,)
Para crear una cita: use (>) o (.)
La tecla de acceso directo que debe usar depende de su teclado. Use aquellas teclas para las que no tenga que usar Mayús.
Reproduzca el video. Si encuentra algo interesante que desee marcar como cita, haga clic en la tecla (,) o (<). Esto establece la posición de inicio.
Para establecer la posición final y crear una cita, haga clic en la tecla (.) o (>).
-
Una nueva cita aparecerá en el Administrador de citas, el Explorador de proyectos o el Navegador de citas. El ID de la cita consiste en el número del documento más un contador consecutivo en orden cronológico según el momento en que se creó la cita en el documento. El ID de cita 15:5, por ejemplo, significa que es una cita en el documento 15 y fue la quinta cita creada en dicho documento.
-
Después del ID se muestra la referencia de la cita, que es la posición de inicio de la cita de audio o video. El campo de nombre está vacío. Puede, por ejemplo, agregar un título breve para cada cita multimedia; véase más abajo.
-
Dependiendo del tipo de medio, el icono de la cita cambia.
Las citas de audio y video se reconocen fácilmente por su icono especial.
Codificar citas multimedia
Codificar citas multimedia no es diferente a codificar documentos de texto o imagen:
Haga clic derecho en la cita y seleccione Aplicar códigos. Para obtener más información, consulte: Codificar datos.
Activar y reproducir citas multimedia
En el área del margen
Para reproducir la cita, haga doble clic en la barra de cita, o pase el ratón sobre la forma de onda de audio y haga clic en el icono de reproducción.
Puede mover el cabezal de reproducción a cualquier posición dentro de un archivo de audio o video desplazándose.
Desde otros lugares
-
Al hacer doble clic en una cita multimedia en el Explorador de proyectos, el Navegador de citas o el Administrador de citas, el documento multimedia se abre en la posición donde comienza la cita. Haga clic en la barra espaciadora para reproducirla.
-
Puede obtener una vista previa de una cita multimedia en el área de vista previa del Administrador de citas o del Lector de citas.
-
Puede obtener una vista previa de una cita multimedia en una red.
-
Puede obtener una vista previa de una cita multimedia si forma parte de un hipervínculo. Consulte Trabajar con hipervínculos.
Ajustar el tamaño de las citas multimedia
Para ajustar o cambiar la duración de la cita, arrastre la posición de inicio o fin hasta la posición deseada.
Renombrar una cita multimedia
Si agrega nombres a las citas multimedia, estos pueden servir como títulos. En el comentario de la cita pueden añadirse resúmenes breves. Esto permite crear un resultado de texto significativo para los segmentos de audio y video.
Seleccione una cita multimedia y añada un nombre en el inspector.
Utilice el área de comentario para añadir más información, por ejemplo, describir el segmento y ofrecer una primera interpretación.
Consulte también Aprovechamiento del nombre y comentario de la cita con fines analíticos.
Capturar instantáneas de fotogramas de video como documentos de imagen
Si desea analizar fotogramas concretos de su video con más detalle, puede capturar una instantánea.
Mueva el cabezal de reproducción a la posición deseada en el video.
Haga clic en el icono de cámara en la barra de herramientas.
La instantánea se agrega automáticamente como nuevo documento de imagen a su proyecto. Consulte Crear citas en imágenes para obtener más información sobre cómo trabajar con archivos de imagen.
Trabajar con citas
Tutorial en video: Trabajar con citas.
Aprovechar los nombres y comentarios de citas con fines analíticos
Se puede usar el campo de nombre de cita para parafrasear o resumir el contenido de citas textuales, como título para citas de video e imagen, o para ingresar la ubicación de citas geográficas.
El nombre de la cita también puede usarse, por ejemplo, para la fase de codificación línea a línea en la Teoría Fundamentada, para la codificación inicial en la Teoría Fundamentada Constructivista, o para otros enfoques inductivos. En lugar de generar demasiados códigos en un nivel descriptivo, el nombre de la cita puede usarse para este tipo de codificación.
Para aprovechar esta funcionalidad, abra el inspector en la barra lateral.
Después de crear una cita, ingrese un texto en el campo de nombre en el inspector. Si creó una cita y la codificó al mismo tiempo, seleccione la barra de cita en el margen para que la cita aparezca en el inspector.
Las interpretaciones adicionales pueden escribirse en el campo de comentario de la cita. También se pueden agregar y modificar nombres de citas y agregar comentarios en el Administrador de citas.
Revisar citas codificadas y modificar la codificación
Tutorial en video: Recuperar datos codificados
Existen varias formas de revisar las citas codificadas:
-
Haga doble clic en un código en cualquier lugar. Esto abre el Lector de citas o da la opción de abrirlo.
-
Abra el Administrador de citas y seleccione un código en el panel lateral.
-
Cree una consulta en la herramienta de consulta, una Tabla de documentos por código, o una Tabla de co-ocurrencia de códigos y revise las citas en las listas de resultados.
Mostrar citas en contexto
Mostrar citas en contexto significa que se puede ver una cita listada en un navegador o en una lista dentro del contexto de los datos originales.
-
Haga doble clic en una entrada del Administrador de citas.
-
Haga clic en la barra de cita en el área de margen.
-
Haga doble clic en la cita en la subrama de documentos del Explorador de proyectos.
-
Una vez codificados los datos, las citas también pueden recuperarse a través de sus códigos. Véase Lector de citas.
-
Las citas pueden activarse en redes. Véase Trabajar con redes.
-
Las citas pueden activarse desde una lista de resultados de una búsqueda de proyecto (véase Búsqueda de proyecto).
Eliminar citas
Para eliminar una sola cita, haga clic derecho en una cita y seleccione la opción Eliminar en el menú contextual.
Esta opción está disponible en todos los navegadores, ventanas y listas donde se ven citas, es decir, el Explorador de proyectos, el Lector de citas, el Administrador de citas, en una red o en el área de margen.
Eliminar una cita no elimina los datos en sí. Piense en las citas como una capa sobre los datos. Eliminar esta capa no elimina los datos subyacentes. Sin embargo, todos los demás vínculos existentes, como vínculos a códigos, memos o hipervínculos, se eliminarán al borrar una cita.
Referenciar citas
Puede ser útil referenciar citas en los memos o comentarios, o en documentos escritos en otras aplicaciones.
Todo esto se puede hacer simplemente copiando una cita desde cualquier lugar y pegándola en el texto. También funciona arrastrar y soltar. Y en un memo o documento, también se puede situar el cursor sobre los números de párrafo y hacer clic en el botón que aparece para seleccionar citas e insertarlas.
Cuando esté dentro de un documento de texto, asegúrese de copiar la cita y no solo el texto haciendo clic derecho en la cita en el margen.
Las citas insertadas de esta manera incluyen el texto completo, la referencia y un vínculo en el que se puede hacer clic para abrir la cita en su documento y verla en contexto. ¡Esto funciona incluso desde fuera de ATLAS.ti!
Al colaborar en equipo, también puede enviar a sus colegas un vínculo a una cita pegándolo en su aplicación de mensajería preferida, siempre que tengan una copia del mismo proyecto en su computadora que contenga esa cita.
Cambiar el orden cronológico de las citas
El ID de cita numera las citas en el orden cronológico en que fueron creadas. Por diversas razones, a veces los usuarios desean que las citas estén numeradas en el orden secuencial en que aparecen en el documento.
Al eliminar citas, la numeración no se ajusta automáticamente. En cambio, quedan vacíos. Renumerar las citas también cierra esos vacíos.
Para renumerar citas:
En el menú principal, seleccione Documentos > Renumerar documentos y citas.
Codificación de datos - Conceptos básicos
"Codificar significa que adjuntamos etiquetas a 'segmentos de datos' que describen de qué trata cada segmento. A través de la codificación, planteamos preguntas analíticas sobre nuestros datos [...]. La codificación destila los datos, los ordena y nos proporciona un punto de apoyo analítico para hacer comparaciones con otros segmentos de datos" (Charmaz, 2014:4).
"La codificación es la estrategia que transforma los datos de un texto difuso y desordenado en ideas organizadas sobre lo que está ocurriendo" (Richards y Morse, 2013:167).
"La codificación es una función central en ATLAS.ti que le permite 'indicar' al software dónde están las cosas interesantes en sus datos. ... el objetivo principal de categorizar los datos es etiquetar las cosas para definirlas u organizarlas. En el proceso de categorización, comparamos segmentos de datos y buscamos similitudes. Todos los elementos similares pueden agruparse bajo el mismo nombre. Al nombrar algo, lo conceptualizamos y lo enmarcamos al mismo tiempo" (Friese, 2019).
Código independiente / Código de categoría / Subcódigo
Con ATLAS.ti 22, se introdujeron nuevas formas de organizar los códigos en el sistema de códigos. Si no es necesario organizar los códigos en una jerarquía de códigos de orden superior e inferior, se puede trabajar con códigos independientes. Si se desea crear una jerarquía de códigos, se pueden usar códigos de categoría y subcódigos. Si algunos códigos no encajan en ninguna categoría, pueden permanecer como códigos independientes.
Otra forma de organizar los códigos son las carpetas. Puede añadir códigos independientes y categorías con sus subcódigos a carpetas. Las carpetas también pueden contener otras carpetas.
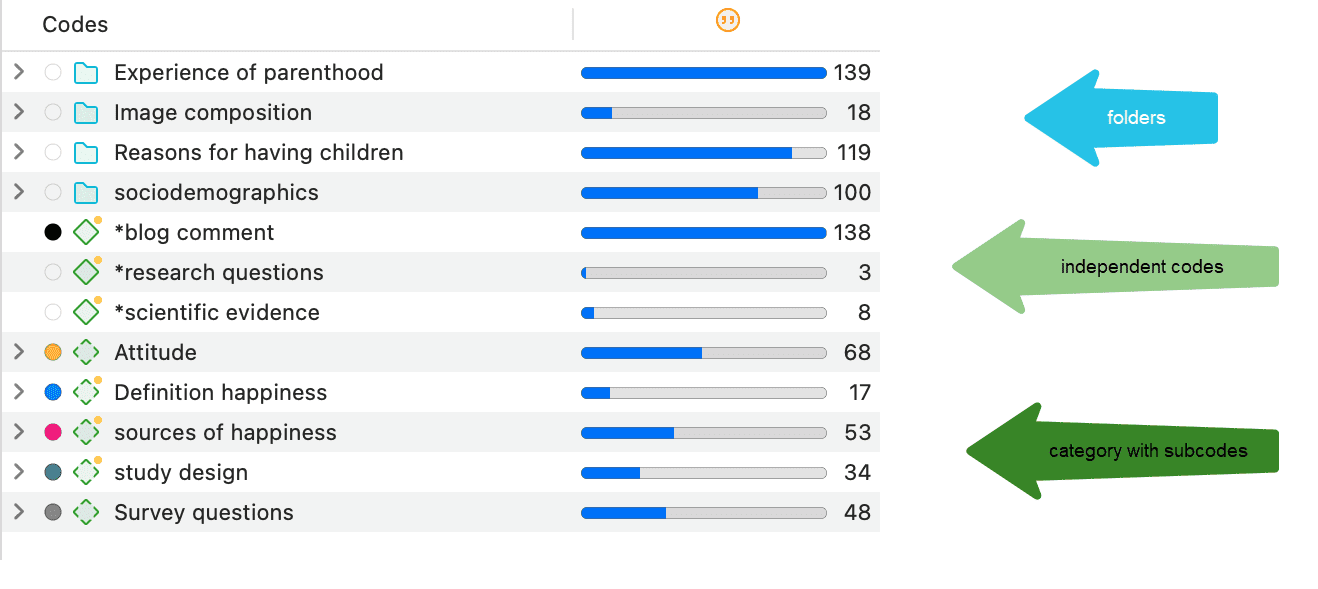
A continuación se explica cada uno de estos tipos con más detalle:
Código independiente: Al comenzar a codificar los datos y crear nuevos códigos, estos serán códigos independientes de primer nivel. Permanecen como códigos independientes hasta que se añaden a una categoría como subcódigo. El enraizamiento de un código independiente es el número de citas que ha codificado.
Código libre: Un código libre es también un código independiente, pero que no ha sido usado (todavía) para la codificación. Su enraizamiento es cero y no tiene subcódigos.
Código de categoría: Un código se convierte en categoría cuando se arrastran y sueltan otros códigos debajo de él. Estos pueden ser códigos independientes o subcódigos que se mueven desde una categoría diferente. La propia categoría no codifica citas. Por ello, solo se pueden insertar otros códigos como subcódigos si el código no está vinculado a citas.
La razón de esto es que a través del código de categoría se pueden recuperar todas las citas de todos los subcódigos. Por lo tanto, si se desea una vista agregada de los datos, basta con seleccionar la categoría. Si se pudieran aplicar el código de categoría y sus subcódigos a las mismas citas, se obtendrían citas duplicadas. Esto se evita al no permitir que el código de categoría se use para la codificación.
El enraizamiento de un código de categoría es el número de citas codificadas por todos sus subcódigos. Dado que se pueden aplicar varios códigos a la misma cita, el total de una categoría puede diferir de la simple suma de citas de todos los subcódigos. Ambas sumas son iguales solo si se usan los subcódigos de manera mutuamente exclusiva, como se requiere por ejemplo para el análisis de acuerdo entre codificadores
Para todos los usuarios anteriores de ATLAS.ti: dado que el código de categoría puede recuperar todas las citas de sus subcódigos, los operadores semánticos SUB, UP y SIBLING ya no son necesarios y se han eliminado de la herramienta de consulta.
Subcódigo: Un subcódigo es un código que está ordenado bajo un código de categoría. No se pueden crear más subcódigos bajo los subcódigos. La razón de esto es metodológica y no técnica. Cada código debe aparecer solo una vez en un sistema de códigos. Véase: Cómo construir un sistema de códigos. Si se usa una jerarquía más profunda, es probable que los códigos comiencen a duplicarse e incluso multiplicarse en los niveles inferiores. Esto no solo hace que el sistema de códigos sea largo y difícil de mantener, sino que también impide realizar un análisis comparativo efectivo.
Carpeta: Las carpetas ayudan a organizar los códigos. Puede mover códigos independientes y categorías con sus subcódigos a carpetas. Una carpeta también puede contener otras carpetas, tantas como se desee. Las carpetas no pueden usarse para codificar datos.
El número que aparece detrás de una carpeta es el número de citas codificadas por los códigos independientes o subcódigos contenidos en ella. Como se pueden aplicar múltiples códigos a la misma cita (es decir, codificación multivalor), el total puede diferir de la suma de todos los números de todos los códigos independientes y subcódigos.
Cómo se cuenta el enraizamiento
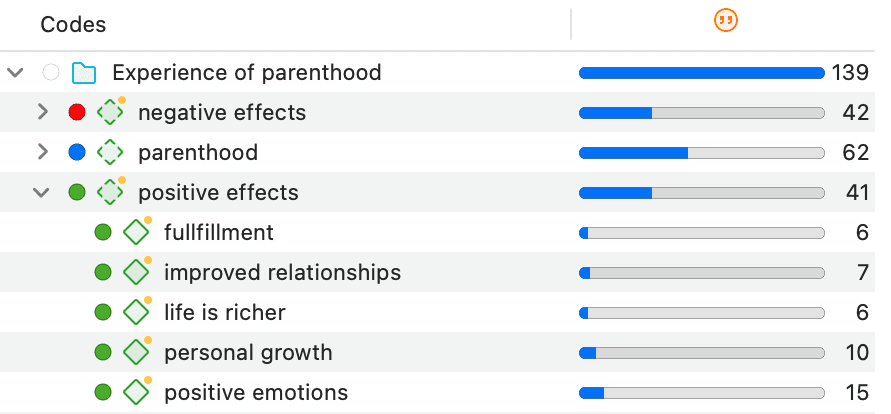
Código independiente: El enraizamiento de un código independiente es el número de citas que ha codificado.
Código de categoría: El enraizamiento de un código de categoría es el número de citas codificadas por todos sus subcódigos. Dado que se pueden aplicar varios códigos a la misma cita, el total de una categoría puede diferir de la simple suma de citas de todos los subcódigos. Ambas sumas son iguales solo si se usan los subcódigos de manera mutuamente exclusiva, como se requiere por ejemplo para el análisis de acuerdo entre codificadores
La imagen anterior muestra la categoría efectos positivos. Al sumar las citas codificadas por todos los subcódigos, la suma es 44. Sin embargo, el enraizamiento de la categoría es 41. Esto significa que hay 3 citas que están codificadas con más de uno de los subcódigos. Esto se ilustra en la imagen a continuación:

Subcódigo: El enraizamiento de un subcódigo es el número de citas que ha codificado. Por ejemplo, el subcódigo la vida es más rica está codificando 6 citas.
Carpeta: El enraizamiento de una carpeta es el número de citas codificadas por los códigos independientes o subcódigos contenidos en ella. Como se pueden aplicar múltiples códigos a la misma cita (es decir, codificación multivalor), el total puede diferir de la suma de todos los números de todos los códigos independientes, subcódigos o categorías. En el ejemplo anterior, la carpeta Experiencia de la paternidad tiene un enraizamiento de 139 citas. Esto es menor que la suma de las tres categorías contenidas en la carpeta (42 + 62 + 41 = 145). De nuevo, esto significa que algunas citas están codificadas con más de uno de los códigos de la carpeta. Solo se cuentan las citas únicas y no el número de codificaciones.
Cómo se cuenta la densidad
La densidad del código no está relacionada con la jerarquía del código ni con el número de codificaciones. La densidad se define como el número de vínculos entre dos códigos. Se pueden vincular dos códigos entre sí mediante arrastrar y soltar, o como se recomienda, en una red. Consulte el capítulo sobre redes para más información.
Crear y aplicar códigos
Tutorial en video: Cómo codificar datos.
Crear nuevos códigos sin codificar
Puede crear códigos que no hayan sido usados (todavía) para la codificación. Estos códigos se denominan códigos "libres". Consulte Codificación de datos - Conceptos básicos. Esto puede ser útil, por ejemplo, cuando se ocurren ideas para códigos durante el trabajo de codificación habitual que no se pueden aplicar al segmento actual pero serán útiles más adelante. Si ya dispone de una lista de códigos, posiblemente con descripciones y agrupaciones, puede usar la opción: Importar una lista de códigos.
En el menú principal, seleccione Código / Nuevo código. El atajo de teclado es Cmd+K.
También puede crear nuevos códigos en el Administrador de códigos haciendo clic en el botón +.
Codificar con un nuevo código
Abra un documento y resalte un segmento de datos, es decir, un fragmento de texto, datos de audio o vídeo, un área en un documento gráfico o una ubicación en un documento geográfico.
Haga clic derecho y seleccione Aplicar códigos, o use el atajo Cmd+J, o haga clic en el botón 'Aplicar códigos' en la barra de herramientas.

Introduzca un nombre y haga clic en el botón de más o presione Enter. Una vez creado el código, puede introducir una definición en el campo de comentario.
Puede continuar añadiendo más códigos, o simplemente continuar seleccionando otro segmento de datos. El diálogo se cierra automáticamente.
Para obtener más información sobre cómo trabajar con datos distintos a texto, consulte Trabajo con datos multimedia y Trabajo con documentos geográficos.
Codificación in vivo
Use la codificación in vivo cuando el propio texto contenga un nombre útil y significativo para un código.
La codificación in vivo solo puede aplicarse a documentos primarios de texto.
La codificación in vivo crea una cita a partir del texto seleccionado Y usa ese texto como nombre del código. Si los límites del texto seleccionado no son exactamente los deseados para la cita, el siguiente paso suele ser modificar la "extensión" de la cita tras crear el código in vivo. Consulte Trabajo con códigos > Modificar la longitud de un segmento codificado.
Seleccione un segmento en un documento de texto, haga clic derecho y seleccione Codificación in vivo, o el botón correspondiente en la cinta de opciones (Windows) / barra de herramientas (Mac).
"La excesiva dependencia de los códigos in vivo... 'puede limitar su capacidad para trascender hacia niveles más conceptuales y teóricos de análisis e interpretación' (Saldana, 2009:77). Cuando son descriptivos y únicos para una persona, el codificador necesita superarlos con bastante rapidez para generar un código más analítico." (Bazeley, 2013:166).
Visualización de segmentos de datos codificados en el área de margen
El segmento codificado se muestra en el área de margen. Una barra azul marca el tamaño del segmento codificado (= cita) y el nombre del código aparece junto a ella. Al codificar datos de esta manera, se crea automáticamente una nueva cita y el código queda vinculado a dicha cita.

Aplicar códigos existentes
Los códigos existentes se pueden aplicar usando el Diálogo de codificación o mediante Arrastrar y soltar.
Usar el diálogo de codificación
Resalte un segmento de datos, haga clic derecho y seleccione Aplicar códigos, o simplemente haga doble clic en la cita.
Es fácil saltar rápidamente al código que se busca introduciendo las primeras letras del código en el campo de búsqueda.
Seleccione uno de los códigos existentes, haga clic en el botón de más o presione Enter.
Codificación por arrastrar y soltar
La codificación por arrastrar y soltar es posible desde las siguientes ubicaciones:
- la rama Códigos del Explorador de proyecto
- el Navegador de códigos en el panel de navegación.
- el Administrador de códigos
Al final de este capítulo encontrará otras opciones de arrastrar y soltar disponibles para su conveniencia.
Codificación por arrastrar y soltar desde el Navegador de códigos
Para abrir el Navegador de códigos, haga clic en el icono Códigos. El campo de búsqueda en el Navegador de códigos facilita el manejo de una lista larga de códigos. En lugar de desplazarse por la lista, introduzca las primeras letras de un código.

Resalte un segmento de datos, seleccione uno o más códigos de la lista de códigos y arrastre el código sobre el segmento de datos resaltado.
Por cierto, en caso de que se lo pregunte, la densidad del código no es un valor que calcule el software. Aumenta cuando el investigador empieza a vincular códigos entre sí. Consulte Trabajo con redes.
Codificación por arrastrar y soltar desde el Administrador de códigos
Al usar el Administrador de códigos para la codificación por arrastrar y soltar, se recomienda colocarlo junto a los datos que se están codificando. Si hace clic en el pin en la parte superior derecha de la ventana, el Administrador de códigos permanece al frente.
Puede acceder rápidamente a los códigos usando grupos de códigos para filtrar la lista.
Resalte un segmento de datos, seleccione uno o más códigos de la lista de códigos y arrastre el código sobre el segmento de datos resaltado.
Codificación rápida
La codificación rápida asigna el último código usado al segmento de datos actual. Es un método eficiente para la codificación consecutiva de segmentos usando el código utilizado más recientemente.
Resalte un segmento de datos o haga clic en una cita existente.
Haga clic derecho y seleccione Codificación rápida en el menú contextual, o use el atajo cmd+L. Otra opción es seleccionar la lista desplegable junto a Aplicar códigos en la barra de herramientas.
Atajos de teclado para la codificación
| Codificación | Atajo de teclado |
|---|---|
| Crear código libre | Cmd+K |
| Aplicar códigos | Cmd+J |
| Aplicar últimos códigos usados | Cmd+L |
| Codificación in vivo | Shift+Cmd+V |
Más opciones de arrastrar y soltar
-
Puede arrastrar y soltar citas en el Administrador de citas hacia un código en el panel lateral del Administrador de citas.
-
Puede arrastrar y soltar citas desde el Administrador de citas hacia un código en el Administrador de códigos.
-
Puede arrastrar y soltar uno o más códigos hacia una cita en el Administrador de citas.
-
Puede arrastrar y soltar uno o más códigos hacia una cita en el Navegador de citas del panel de navegación.
-
Puede arrastrar y soltar citas desde el Navegador de citas hacia un código en el Administrador de códigos.
-
Puede arrastrar y soltar citas desde el Navegador de citas del panel de navegación hacia un código en el panel lateral del Administrador de citas.
Escribir comentarios de código
Los comentarios de código se pueden usar para diversos propósitos. El uso más habitual es para una definición del código. Si trabaja en equipo, puede añadir también una regla de codificación o una cita de ejemplo. Si trabaja inductivamente, puede usar los comentarios de código para anotar las primeras ideas sobre cómo aplicar ese código. También puede usarlos para redactar resúmenes de todos los segmentos codificados con ese código y su interpretación. Hay varias formas de escribir un comentario de código.
-
Si selecciona un código en cualquier lugar, puede escribir un comentario de código en el inspector.
-
Agregar un comentario de código al crear un nuevo código en el diálogo de codificación:
Introduzca un nuevo nombre de código y haga clic en el + para crear el código. Ahora puede introducir una descripción o definición de código en el campo de comentario.
- En el área de margen, puede hacer doble clic en un código para abrir el editor de comentarios.

Otra opción es hacer clic derecho en un código en cualquier lugar y seleccionar la opción Editar comentario en el menú contextual.
Todos los códigos que tienen un comentario muestran un pequeño punto amarillo en la parte superior derecha del icono del código.
Trabajo con códigos
Modificación de la longitud de un segmento codificado
Seleccione la cita haciendo clic en la barra de cita o en el código del área de margen. Luego mueva el controlador con forma de línea y punto azul hacia la derecha, la izquierda, arriba o abajo, según si desea acortar o alargar la cita.

Eliminar una codificación
Esta opción es la función inversa de la codificación. Elimina los vínculos entre códigos y citas. A diferencia de la función de eliminar, no se suprime ni el código ni la cita; solo se elimina la asociación entre el código y la cita.
En el área de margen
Haga clic derecho en el código del área de margen y seleccione la opción Desvincular en el menú contextual.
En el diálogo de codificación
Haga doble clic en la cita del área de margen. Se abre el diálogo de codificación. Haga clic en Códigos aplicados para ver rápidamente qué códigos se han aplicado a la cita. Haga clic en el botón con el signo menos (-) para eliminar un código.
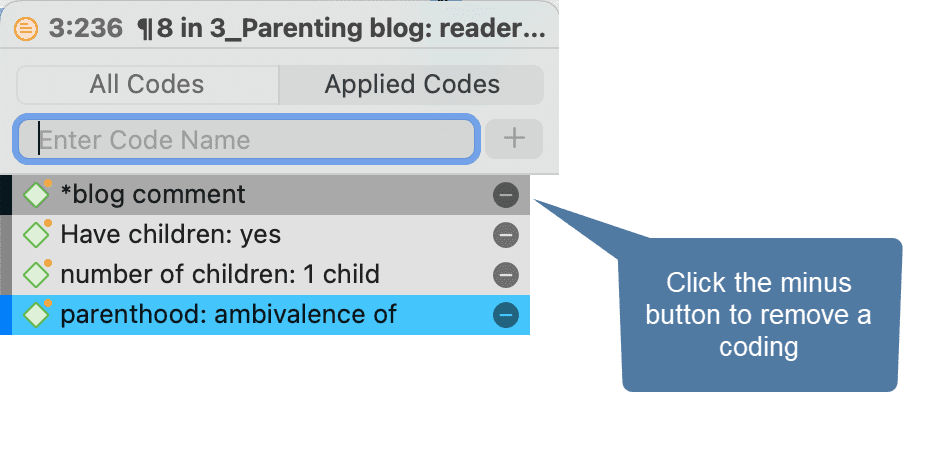
Reemplazar un código mediante arrastrar y soltar
Si desea reemplazar un código vinculado a un segmento de datos:
Puede arrastrar y soltar otro código desde el Explorador de proyecto, el Navegador de códigos o el Administrador de códigos sobre el código existente.

Agregar, cambiar y eliminar el color de un código
Seleccione uno o varios códigos en el Administrador de códigos, el Explorador de proyecto o el Navegador de códigos, haga clic derecho y seleccione Cambiar color en el menú contextual. Seleccione uno de los colores ofrecidos.
También puede hacer clic en el círculo de color en el inspector. Esto también abre la lista de colores de códigos.
La paleta de colores predeterminada es adecuada también para personas con daltonismo. Se pueden añadir colores adicionales si se importa una lista de códigos desde Excel. Consulte Importar listas de códigos.
Renombrar un código
Puede hacer clic con el botón izquierdo en un código en cualquier lugar para renombrarlo en el modo de edición en línea. Otra opción es renombrar el código en el inspector.
Para renombrar un código en el área de margen, seleccione un código y renómbrelo en el inspector del lado derecho.
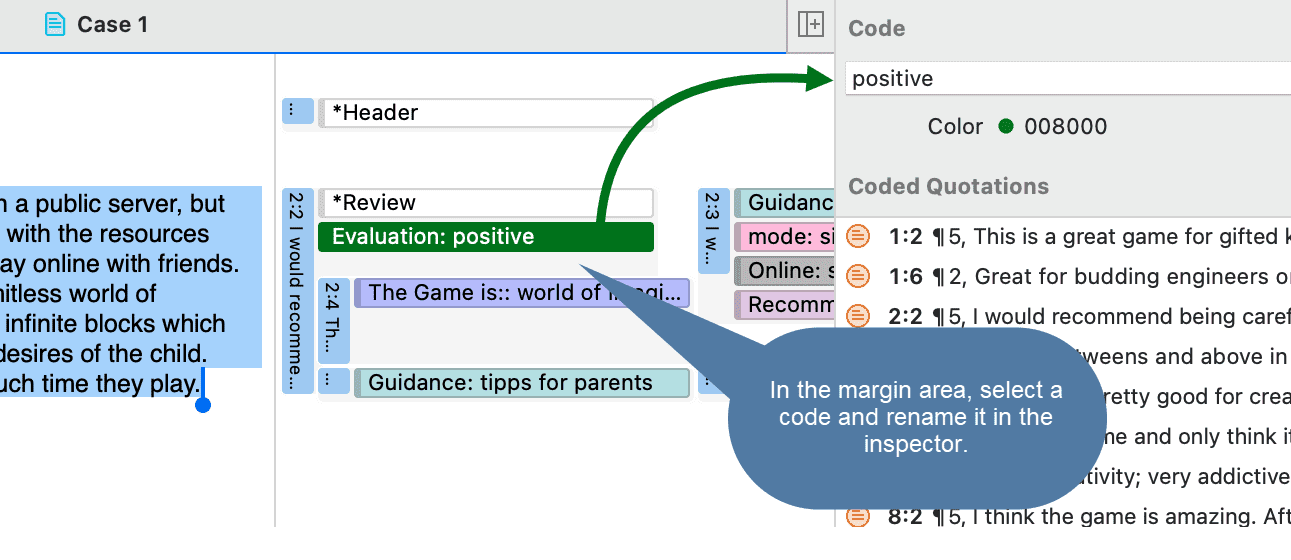
Eliminar uno o varios código(s)
En el Explorador de proyecto, el Navegador de códigos o el Administrador de códigos, haga clic derecho en un código y seleccione Eliminar. Para seleccionar varios códigos, mantenga presionada la tecla Comando.
Acerca de renombrar, eliminar y desvincular códigos
Renombrar y eliminar códigos son procedimientos que parecen triviales, pero comprender el alcance de estas operaciones puede ser un problema para los usuarios nuevos. En ambas operaciones debe entenderse que solo existe UN código, por ejemplo 'fuente de felicidad: hijos', en un proyecto determinado, aunque haya aplicado ese código muchas veces.
En el área de margen, es posible que el código aparezca muchas veces al desplazarse por el documento. En realidad, se están viendo las codificaciones de ese código. Técnicamente, son vínculos entre una cita representada por una barra azul y el código, representado por su nombre e icono.
Eliminar una codificación en el área de margen (es decir, desvincular el código) es como borrar una palabra en el margen de un documento en papel con una goma de borrar. Solo afecta a una codificación, es decir, a una ocurrencia específica del código. Todas las demás ocurrencias del mismo código no se ven afectadas. El efecto de la operación es local.
Al renombrar o eliminar un código de un proyecto, se afecta cada ocurrencia del código en todo el proyecto. El efecto es global. Renombrar el código cambiará instantáneamente todos los vínculos de código en el margen para reflejar el nuevo nombre. Eliminarlo suprimirá todas las ocurrencias en el margen (y de todos los demás contextos en los que estaba involucrado, como redes, grupos, etc.).
Duplicar un código
También es posible duplicar códigos con todos sus vínculos. El código duplicado es un clon exacto del código original, incluyendo el color, el comentario, los vínculos código-cita, los vínculos código-memo y los vínculos código-código. Duplicar un código puede ser una opción útil para limpiar o modificar un sistema de códigos.
Para duplicar un código, haga clic derecho en un código en el Explorador de proyecto, el Navegador de códigos o el Administrador de códigos y seleccione Duplicar.
Escribir comentarios de código
Los comentarios de código se pueden usar para diversos propósitos. El uso más habitual es para una definición del código. Si trabaja en equipo, puede añadir también una regla de codificación o una cita de ejemplo. Si trabaja inductivamente, puede usar los comentarios de código para anotar las primeras ideas sobre cómo aplicar ese código. También puede usarlos para redactar resúmenes de todos los segmentos codificados con ese código y su interpretación. Hay varias formas de escribir un comentario de código.
-
Si selecciona un código en cualquier lugar, puede escribir un comentario de código en el inspector.
-
Agregar un comentario de código al crear un nuevo código en el diálogo de codificación:
Introduzca un nuevo nombre de código y haga clic en el + para crear el código. Ahora puede introducir una descripción o definición de código en el campo de comentario.
- En el área de margen, puede hacer doble clic en un código para abrir el editor de comentarios.
Otra opción es hacer clic derecho en un código en cualquier lugar y seleccionar la opción Editar comentario en el menú contextual.
Todos los códigos que tienen un comentario muestran un pequeño punto amarillo en la parte superior derecha del icono del código.
Recuperación de datos codificados
Tutorial en vídeo: Recuperación de datos codificados.
Desde el Explorador de proyectos, el Administrador de códigos o el Explorador de códigos
Haga doble clic sobre un código. Esto abre el Lector de citas y permite revisar todas las codificaciones.
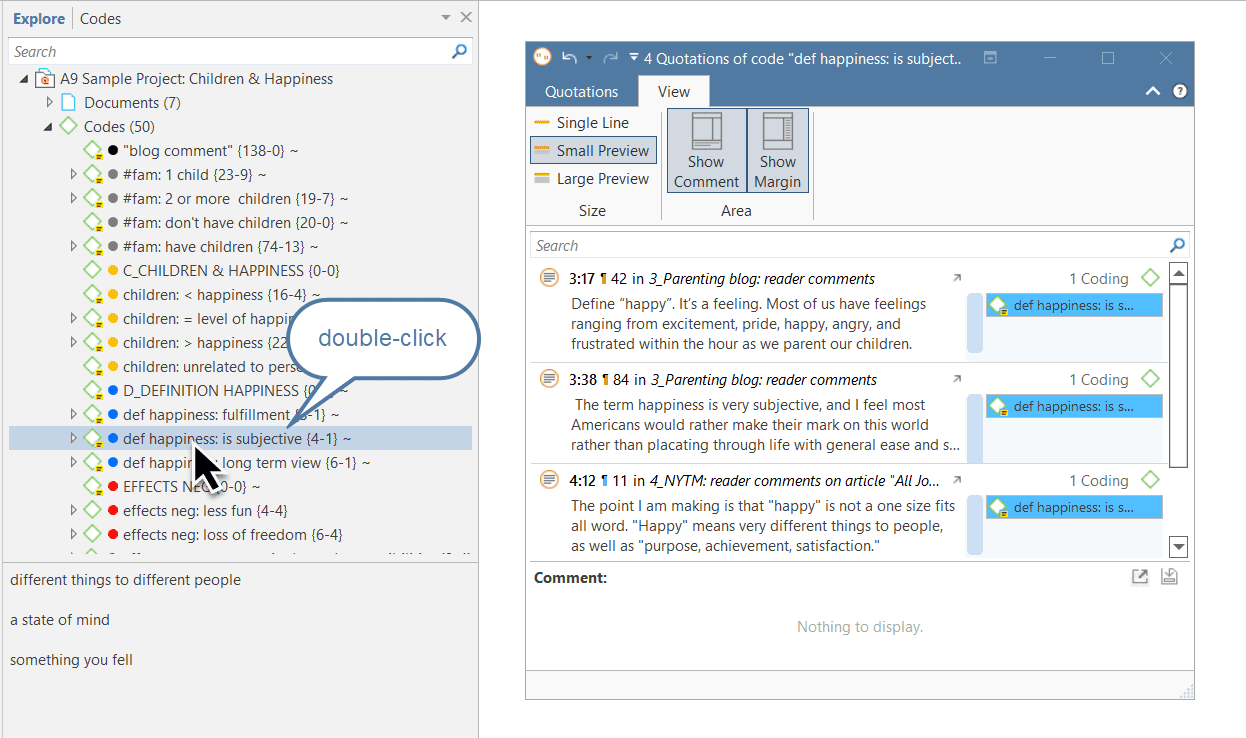
Si prefiere leer los datos en contexto, puede acoplar el Lector de citas al lado derecho o izquierdo de la pantalla en formato de línea única. Para ello:
Seleccione la opción Acoplar al área de navegación en la cinta:
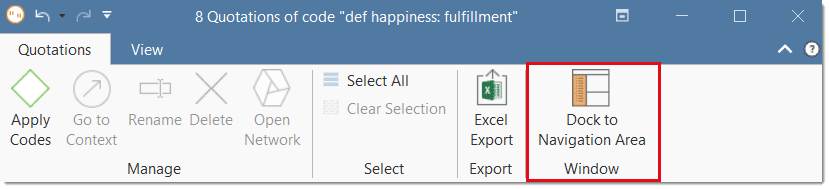

Recuperación simple en el área de margen
Si hace doble clic sobre un código en el área de margen, se abre el campo de comentario. Desde allí puede acceder a las citas codificadas con el código.
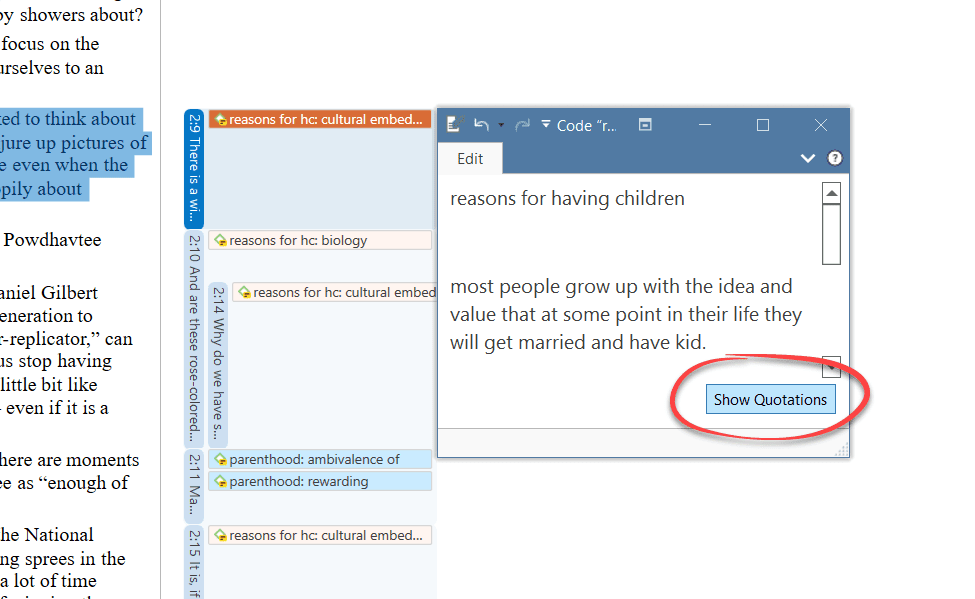
Consultas booleanas simples en el Administrador de citas
Abra el Administrador de citas.
Seleccione un código en el área de filtro. Si tiene una lista larga de códigos, puede introducir algunas letras en el campo Buscar código para reducir la lista a solo los códigos que busca:
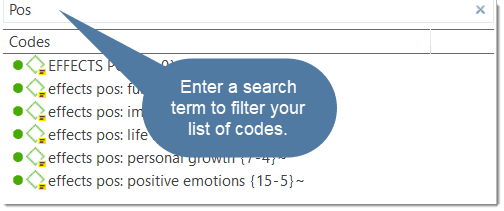
La lista de citas muestra únicamente las citas del código seleccionado. Si hace clic en una cita, se mostrará en el área de vista previa. Si hace doble clic, la cita se mostrará en el contexto del documento.
La barra amarilla en la parte superior muestra el o los códigos que se están utilizando como filtro.
Al seleccionar dos o más códigos en el panel lateral, el filtro se amplía a una consulta OR: Mostrar citas codificadas con ALGUNO de los códigos.....
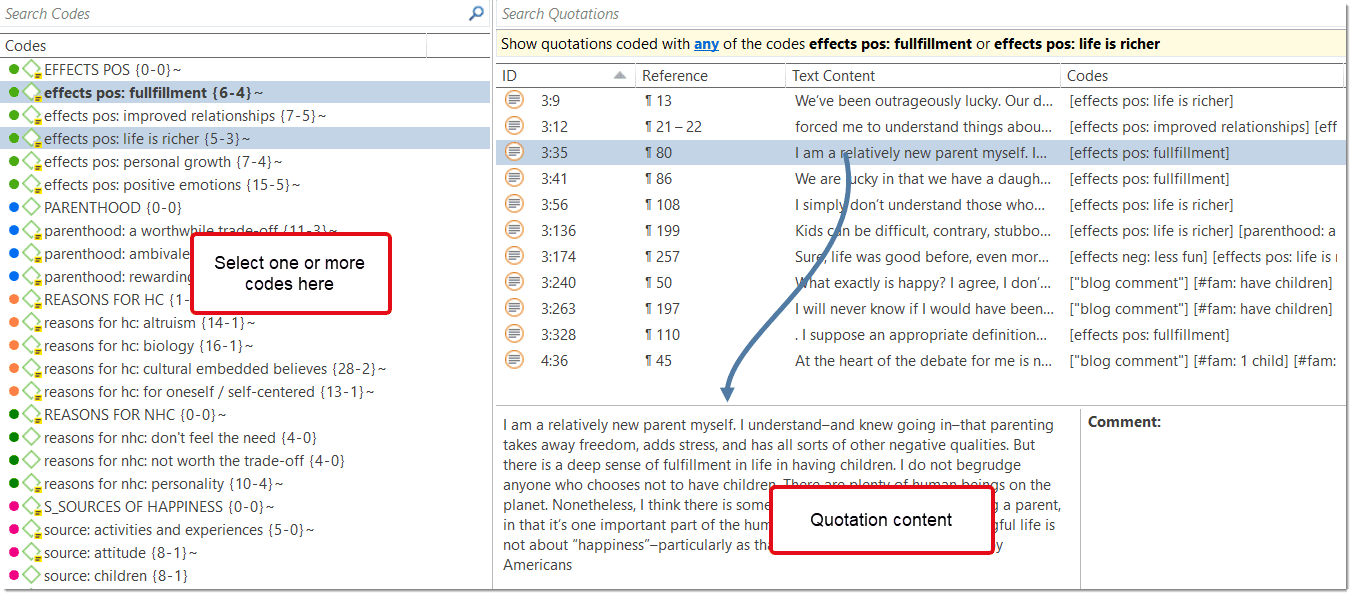
Haga clic en el operador cualquiera subrayado en azul. Se abrirá un menú desplegable y podrá cambiar entre CUALQUIERA y TODOS.

-
CUALQUIERA: Mostrar todas las citas vinculadas a cualquiera de los códigos seleccionados.
-
TODOS: Mostrar las citas donde se aplican todos los códigos seleccionados. Esto significa que dos o más códigos han sido aplicados exactamente a la misma cita.
Tutorial en vídeo: Recuperación de datos - Lector de citas
En el Administrador de códigos
Abra el Administrador de códigos y haga doble clic sobre un código. Esto abre el Lector de citas. En el Lector de citas puede revisar, editar y también eliminar codificaciones.
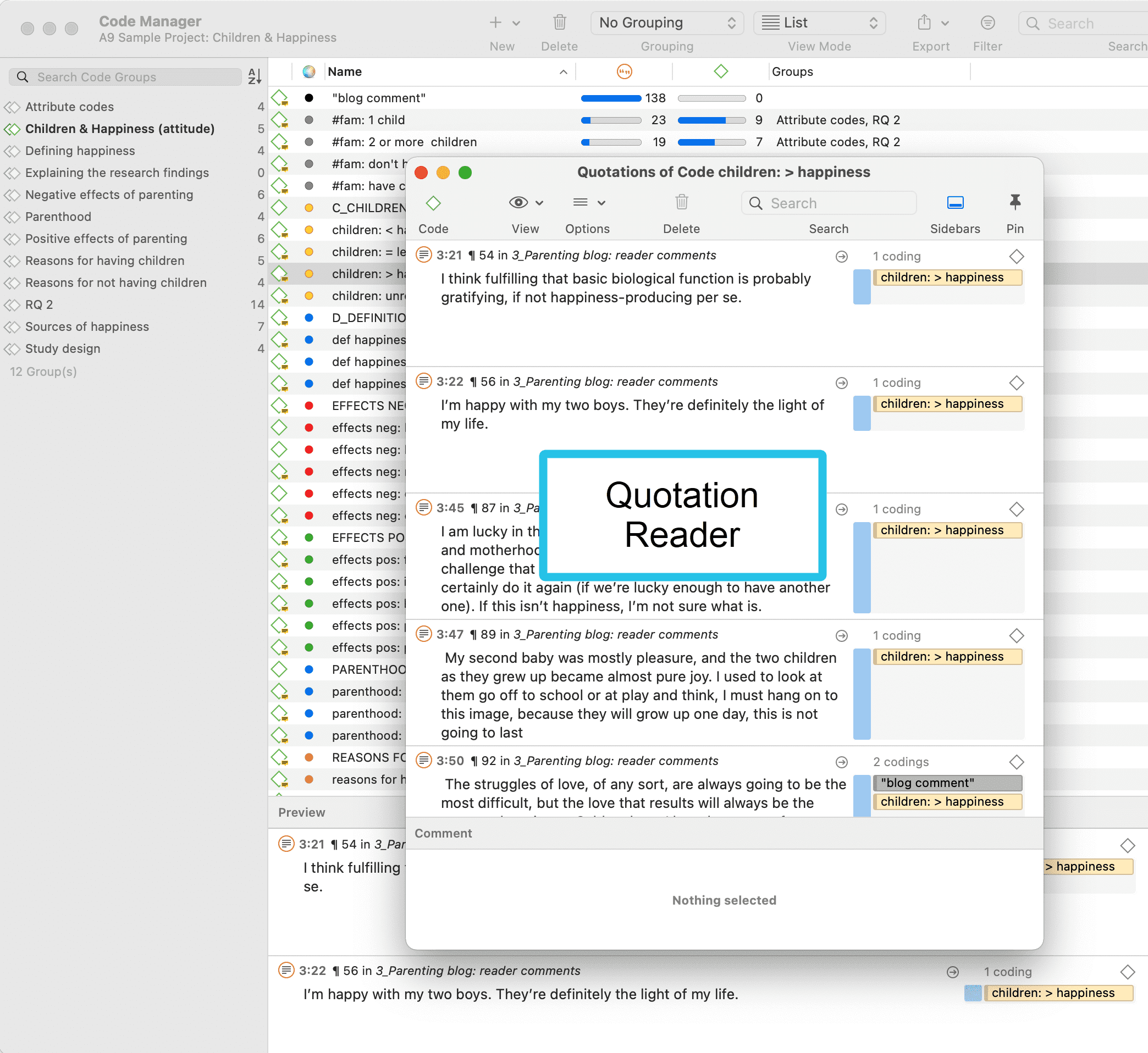
Recuperación simple en el área de margen
Si hace doble clic sobre un código en el área de margen, se abre el campo de comentario. Desde allí puede acceder a las citas codificadas con el código.
Consultas booleanas simples en el Administrador de citas
Abra el Administrador de citas.
Seleccione un código en el área de filtro. La lista de citas muestra únicamente las citas del código seleccionado. Si hace clic en una cita, se mostrará en el área de vista previa. Si hace doble clic, la cita se mostrará en el contexto del documento.
La barra amarilla en la parte superior muestra el o los códigos que se están utilizando como filtro.
Al seleccionar dos o más códigos en el panel lateral, el filtro se amplía a una consulta OR: Filtrar citas que estén codificadas con cualquiera de los códigos.....
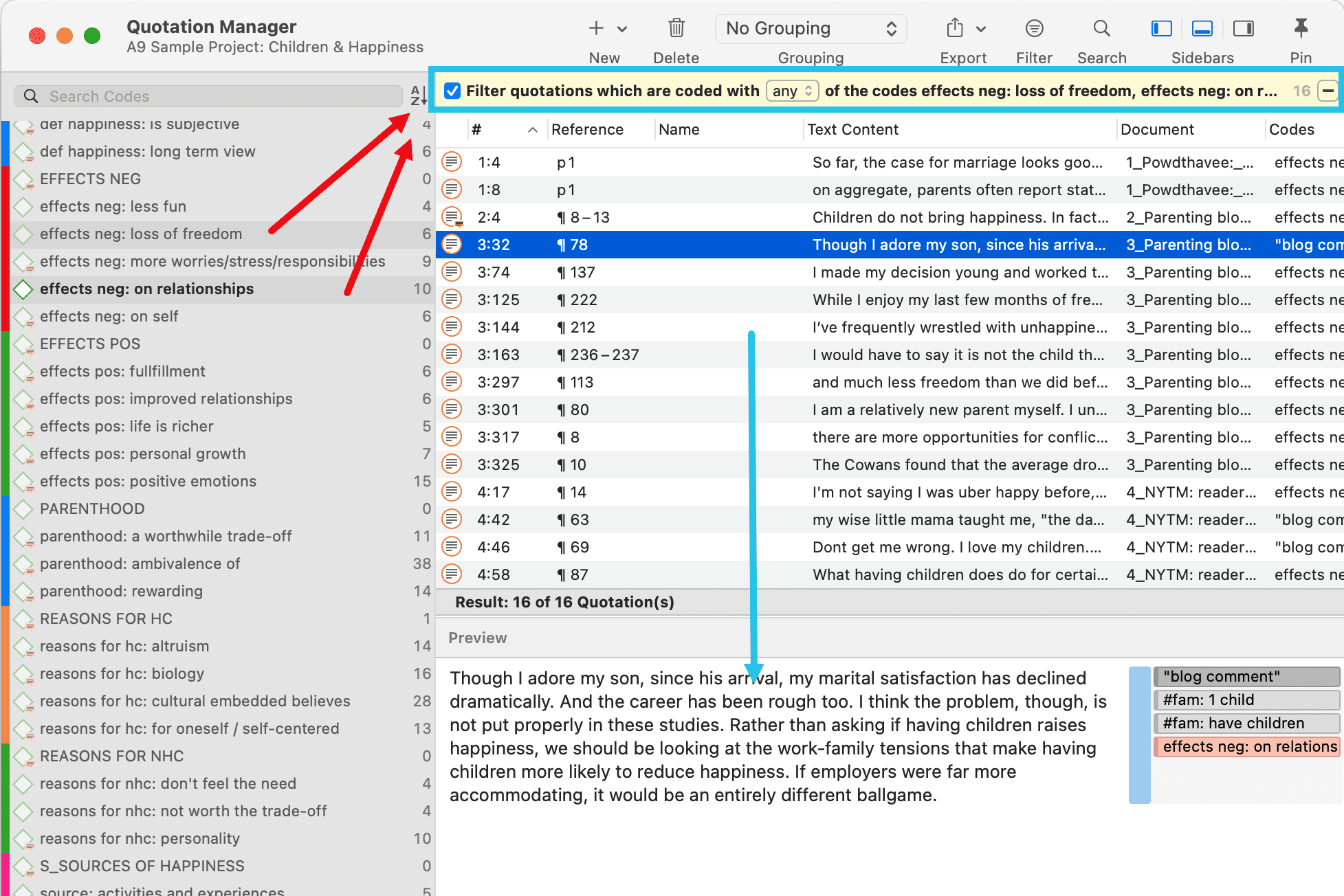
Haga clic en el cuadro con el operador cualquiera. Se abrirá un menú desplegable y podrá cambiar entre CUALQUIERA y TODOS.
-
CUALQUIERA: Mostrar todas las citas vinculadas a cualquiera de los códigos seleccionados.
-
TODOS: Mostrar las citas donde se aplican todos los códigos seleccionados. Esto significa que dos o más códigos han sido aplicados exactamente a la misma cita.
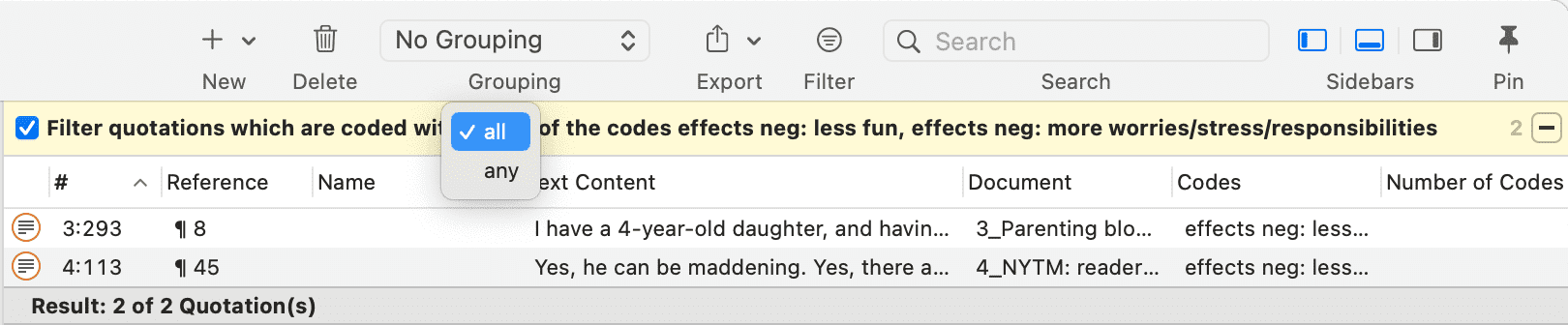
Exportar resultados
Si desea exportar los resultados, haga clic en el botón Exportar y seleccione una opción del menú desplegable. Para más información sobre los informes disponibles y las opciones de informe, consulte Crear informes.
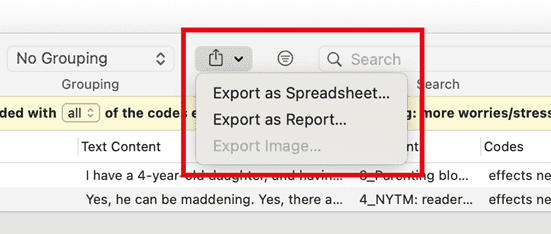
Creación de categorías y subcódigos
Tutorial en video: Construcción de una jerarquía de códigos.
Si desea organizar sus códigos en códigos de orden superior e inferior, puede utilizar categorías y subcódigos. Otra forma de organizar los códigos son las carpetas. Las carpetas pueden contener otras carpetas, lo que ofrece múltiples niveles de organización. Solo los códigos independientes y los subcódigos pueden contener datos codificados. La razón de esto es metodológica y no técnica. Si se usa una jerarquía más profunda, es probable que los códigos comiencen a duplicarse e incluso a multiplicarse en los niveles inferiores. Esto no solo hace que el sistema de códigos sea largo y difícil de mantener, sino que también impide realizar un análisis comparativo efectivo. A continuación se cita a uno de los muchos autores que ofrecen este consejo:
"Si tiene un proyecto típico de complejidad moderada, no debería necesitar más de 10 categorías [principales] para cubrir el tema [...]. Además, la mayoría de los sistemas de códigos no tienen más de dos o tres niveles de profundidad. Si los tienen, es probable que las categorías utilizadas ya no sean verdaderas subcategorías de las categorías de orden superior a las que pertenecen; y, en la práctica, resulta inconveniente para el codificador recordarlas, localizarlas y usarlas eficazmente" (Bazeley, 2013. p. 183).
Véase también: Cómo construir un sistema de códigos.
Otra forma de organizar los códigos son las carpetas. Puede agregar códigos independientes y categorías con sus subcódigos a carpetas. Las carpetas también pueden contener otras carpetas. Esto permite agrupar códigos bajo temas o tópicos que son demasiado abstractos para usarse en la codificación.
A continuación se muestra un ejemplo de jerarquía de 3 niveles, ilustrada con la función de redes de ATLAS.ti:
Creación de categorías con subcódigos
Hay dos formas de crear una categoría: moviendo códigos mediante arrastrar y soltar hacia un código libre, o dividiendo un código que ya tiene codificaciones.
Mover códigos hacia un código libre
Cree un nuevo código.
Seleccione uno o más códigos en la lista de códigos usando las técnicas de selección múltiple habituales.
Arrastre los códigos hacia el código recién creado. Se abre un menú contextual. Seleccione la primera opción: Agregar 'x número de códigos' en...:
Una vez que haya añadido subcódigos a un código independiente, este se convierte en una categoría. El icono del código cambia. Vea la imagen a continuación.
Creación de una categoría mediante división
Seleccione un código que desee dividir en subcódigos.
Haga clic derecho y seleccione la opción Dividir en subcódigos. Se abre la herramienta Dividir código.
Haga clic en Agregar códigos para introducir las etiquetas de los subcódigos. Después de introducir el primer código, presione la flecha hacia la derecha (->|) para pasar al siguiente campo de entrada y escribir la segunda etiqueta, y así sucesivamente. Una vez terminado, haga clic en Agregar.
De forma predeterminada, se añade un subcódigo con el nombre Indeciso a la primera columna de la tabla. Todas las citas se añaden a este subcódigo. El siguiente paso es asignar las citas a los nuevos subcódigos que ha creado. Si una cita no encaja en ninguno de los subcódigos, puede dejarla en el subcódigo 'Indeciso'.
Así es como se asignan las citas a uno o más subcódigos:
Seleccione una cita. Su contenido se muestra en la parte inferior de la pantalla. Asigne la cita haciendo clic en la casilla de verificación de los subcódigos que correspondan.
Para acelerar el proceso, puede presionar las teclas numéricas (1, 2, 3, etc.) para asignar la cita seleccionada al subcódigo 1, 2, 3, etc.

Mutuamente exclusivo: Si no desea permitir que una cita sea codificada con dos de los subcódigos, active la opción Mutuamente exclusivo. Esto es un requisito para algunos enfoques de análisis de contenido y para el cálculo del acuerdo entre codificadores. Consulte Requisitos para la codificación.
Una vez que todas las citas hayan sido asignadas a uno o más subcódigos, haga clic en Dividir código. El código que dividió se convertirá en una categoría, lo cual se indica mediante el cambio en el icono del código. Si hace clic en la flecha desplegable frente al código, puede expandir la categoría para ver los subcódigos.
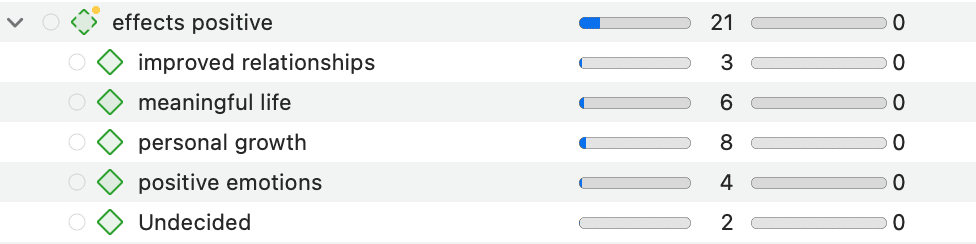
El enraizamiento de un código de categoría es el número de citas codificadas por todos sus subcódigos. Dado que se pueden aplicar varios códigos a la misma cita, el total de una categoría puede diferir de la simple suma de citas de todos los subcódigos. Ambas sumas son iguales solo si se usan los subcódigos de manera mutuamente exclusiva.
Creación de categoría y subcódigos en el diálogo de codificación
Al hacer doble clic en una cita en el margen, o al resaltar un segmento de datos y seleccionar la opción Aplicar códigos en el menú contextual, se abre el diálogo de codificación. Puede crear aquí directamente una nueva categoría con un subcódigo, o agregar un nuevo subcódigo a una categoría existente.
Agregar una categoría con subcódigo
Para crear un código de categoría con un subcódigo, simplemente introduzca como etiqueta: nombre de categoría: nombre de subcódigo:

Agregar un nuevo subcódigo a una categoría ya existente
Comience a escribir el nombre del código de categoría. Esto filtra la lista de códigos.
Seleccione uno de los subcódigos existentes, resalte el nombre del subcódigo y escríba el nuevo nombre encima, o elimine primero esa parte del nombre y luego añada el nuevo nombre de subcódigo.
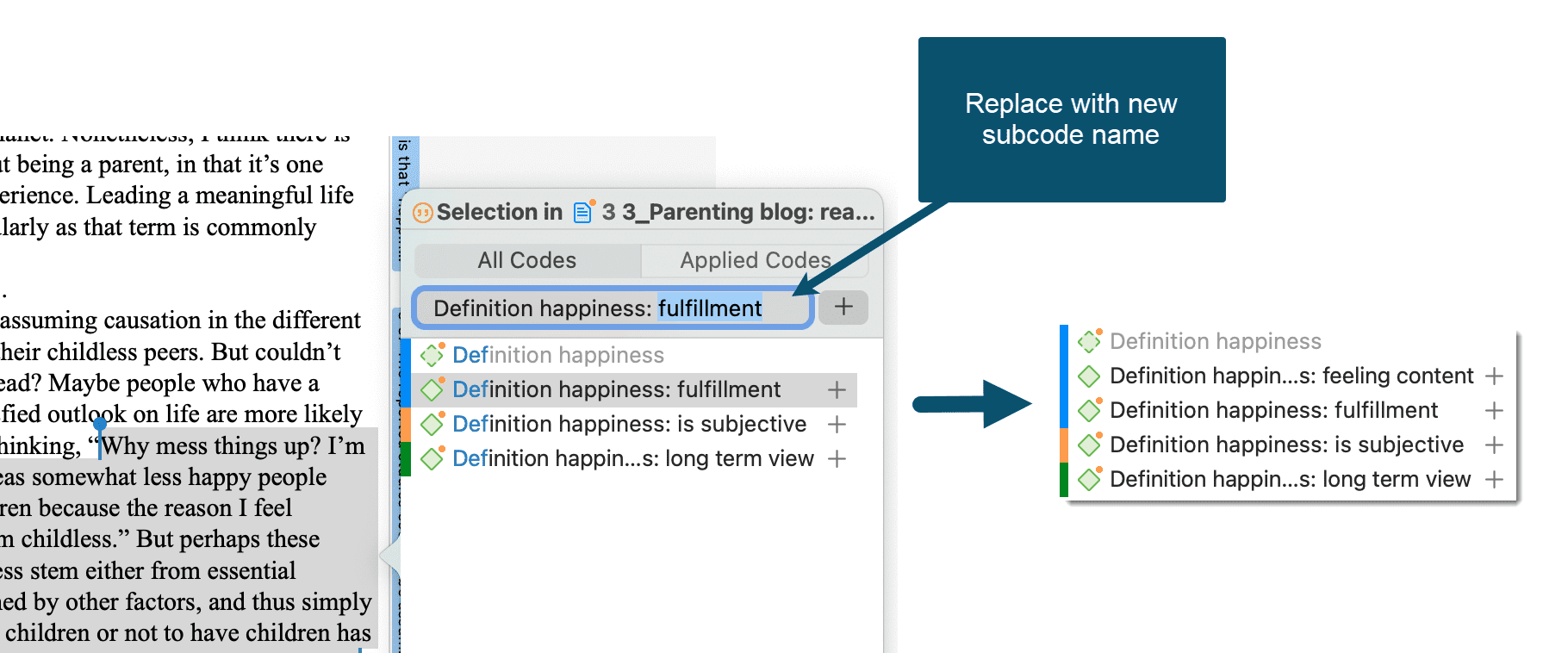
Codificación fácil con subcódigos de una categoría
Existe una forma muy sencilla de aplicar subcódigos a los datos mediante la codificación por arrastrar y soltar.
Resalte una sección de sus datos y arrastre y suelte un código de categoría desde el explorador de proyecto, el navegador de códigos o el administrador de códigos sobre el texto.
Aparece una ventana con la lista de subcódigos. Seleccione uno de los subcódigos para codificar.
Si selecciona una cita existente y ya se han aplicado uno o más subcódigos de la categoría seleccionada, esto se indica con una marca de verificación.
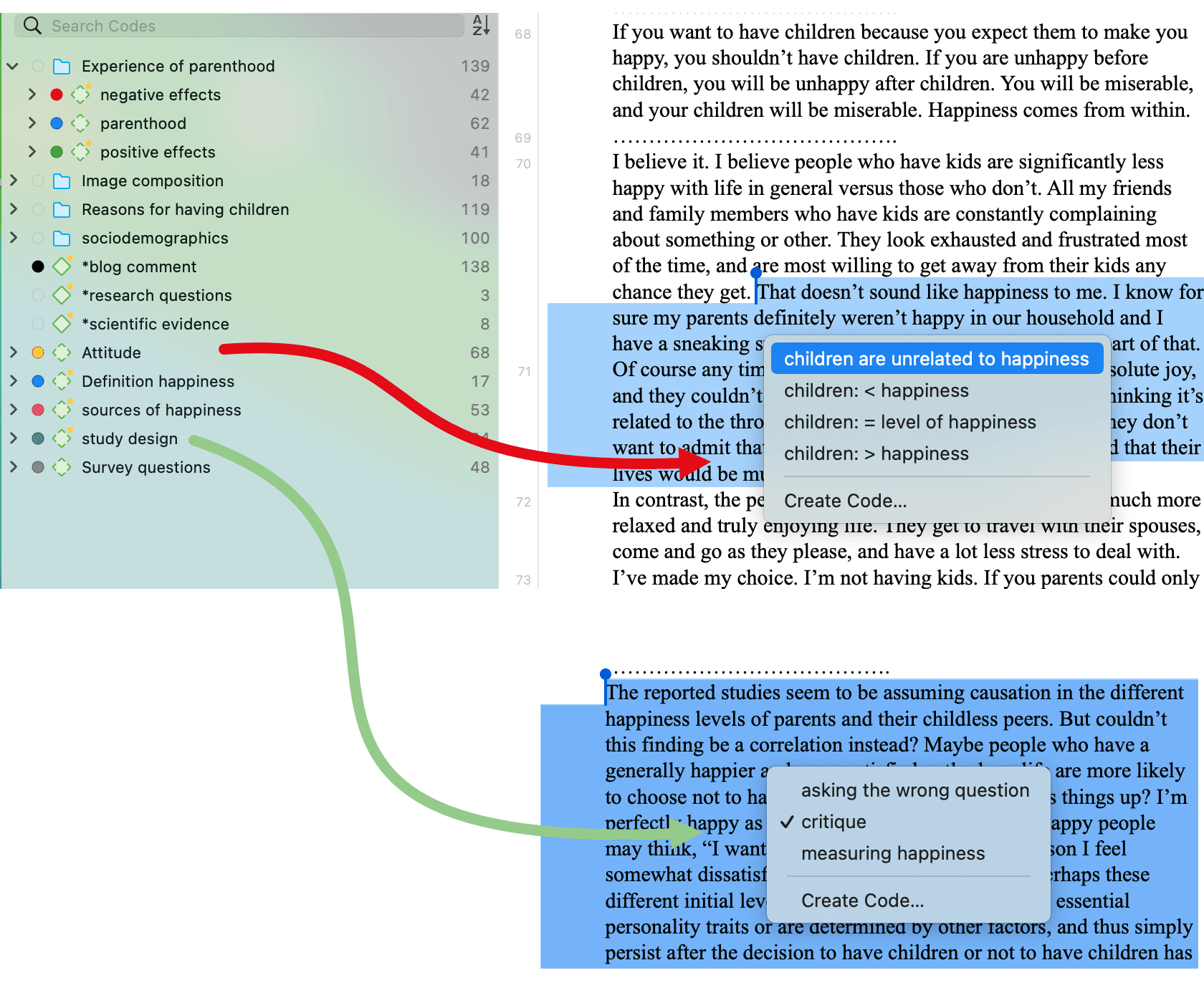
Cómo mover subcódigos fuera de una categoría
Tiene dos opciones: puede mover subcódigos de una categoría a otra mediante arrastrar y soltar.
Si desea mover subcódigos fuera de una categoría al primer nivel, estos se vuelven códigos independientes de nuevo. Si mueve todos los subcódigos, el código de categoría también vuelve a ser un código independiente.
Resalte los subcódigos que desea mover y arrástrelos hacia la izquierda hasta que vea una línea vertical azul, luego suelte:
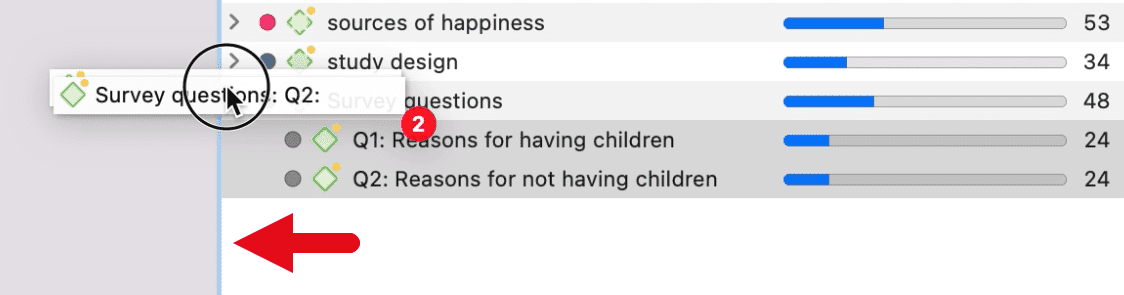
Los subcódigos se ordenarán en la lista de códigos en orden alfabético. El enraizamiento de la categoría se ajustará. En el ejemplo ilustrado a continuación, todos los subcódigos se movieron fuera de la categoría; la categoría se ha convertido en un código independiente con enraizamiento 0:
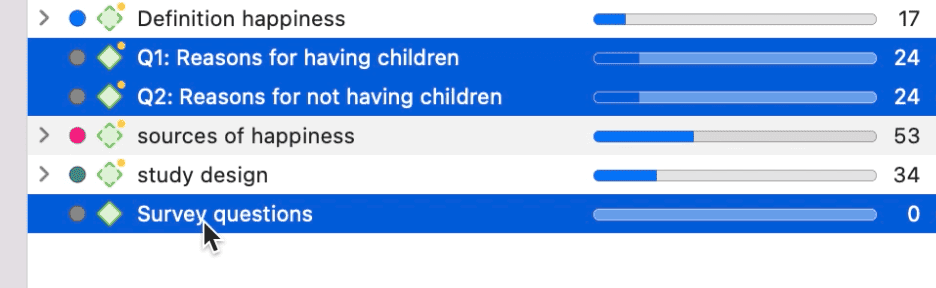
Organización de códigos en carpetas
Los códigos independientes o las categorías con sus subcódigos se pueden organizar en carpetas. A diferencia de los grupos de códigos, un código o una categoría no puede estar en más de una carpeta. La estructura de carpetas es jerárquica, mientras que los grupos de códigos no lo son.
Las carpetas pueden estar contenidas en otras carpetas. Puede haber proyectos que requieran un cuarto nivel de organización. A continuación se muestra un ejemplo con tres niveles. Consulte también las recomendaciones del capítulo Cómo construir un sistema de códigos eficaz.
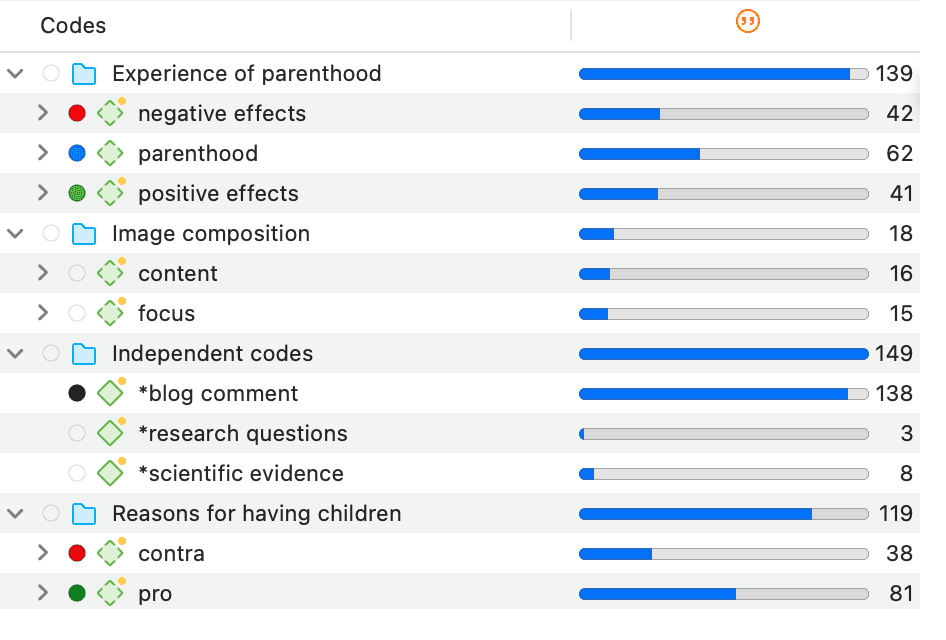
Cómo crear carpetas
En el Administrador de códigos, haga clic en la lista desplegable junto al signo más y seleccione Agregar carpeta de códigos.
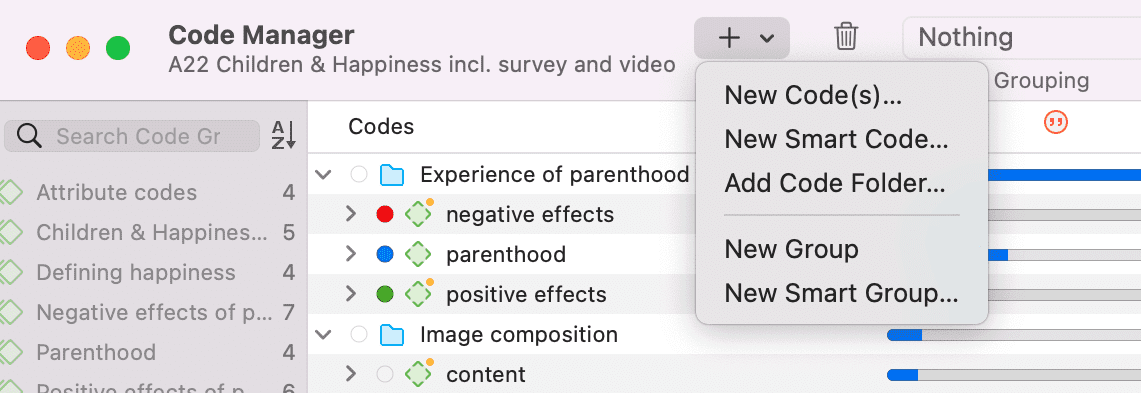
O bien:
Seleccione uno o más códigos o categorías, haga clic derecho y seleccione la opción Nueva carpeta con selección en el menú contextual.
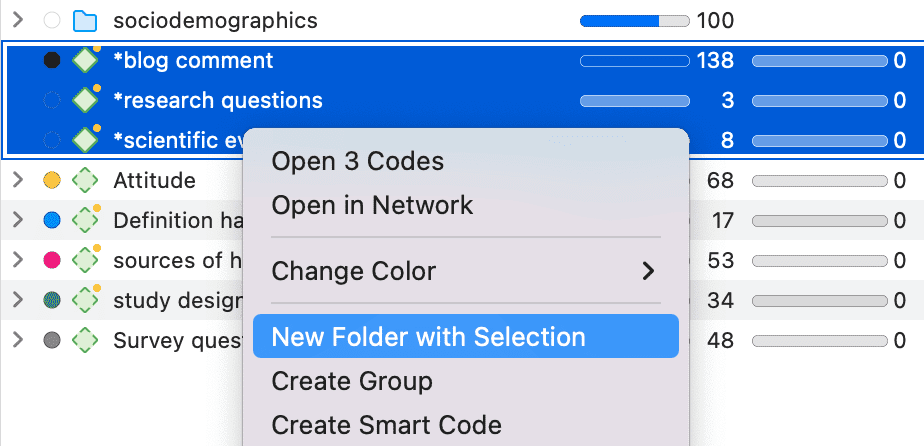
Si elimina una carpeta, también se eliminará todo su contenido.
Cómo mover elementos entre carpetas o fuera de una carpeta
Tiene dos opciones: puede mover códigos independientes, categorías o subcódigos de una carpeta a otra mediante arrastrar y soltar. La segunda opción es resaltar todos los elementos que desea mover y arrastrarlos hacia la izquierda hasta que vea una línea vertical azul; luego suelte.
Exploración de datos codificados
Para explorar las palabras utilizadas en las citas vinculadas a uno o más códigos, puede crear una lista de palabras o una nube de palabras. Las listas de palabras y las nubes de palabras se describen en detalle en la sección Exploración de datos.
Para crear una Nube de palabras o una Lista de palabras, haga clic derecho en un código o grupo de códigos en cualquier parte del proyecto y seleccione la opción de nube de palabras o lista de palabras en el menú contextual.
Puede alternar entre la visualización de Lista de palabras o Nube de palabras:
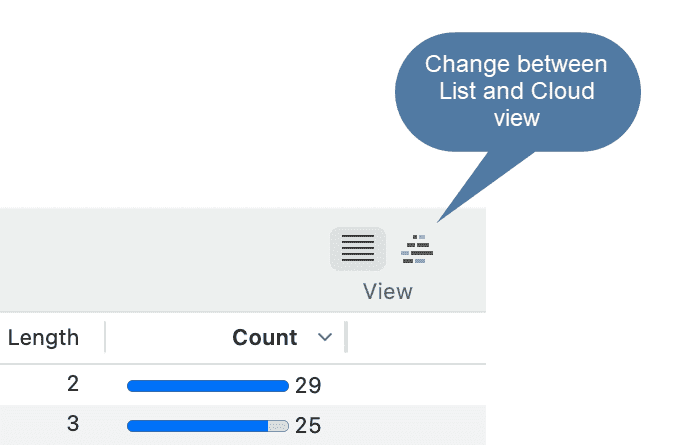
Puede agregar las palabras activando las dos opciones 'Ignorar mayúsculas y minúsculas' e 'Inferir formas base'. Esta última resume, por ejemplo, 'niño' y 'niños', o 'traer', 'trae' y 'trajo'. Si usa esta opción, puede colocar el cursor sobre una palabra y se mostrará qué palabras se han combinado bajo ese término.
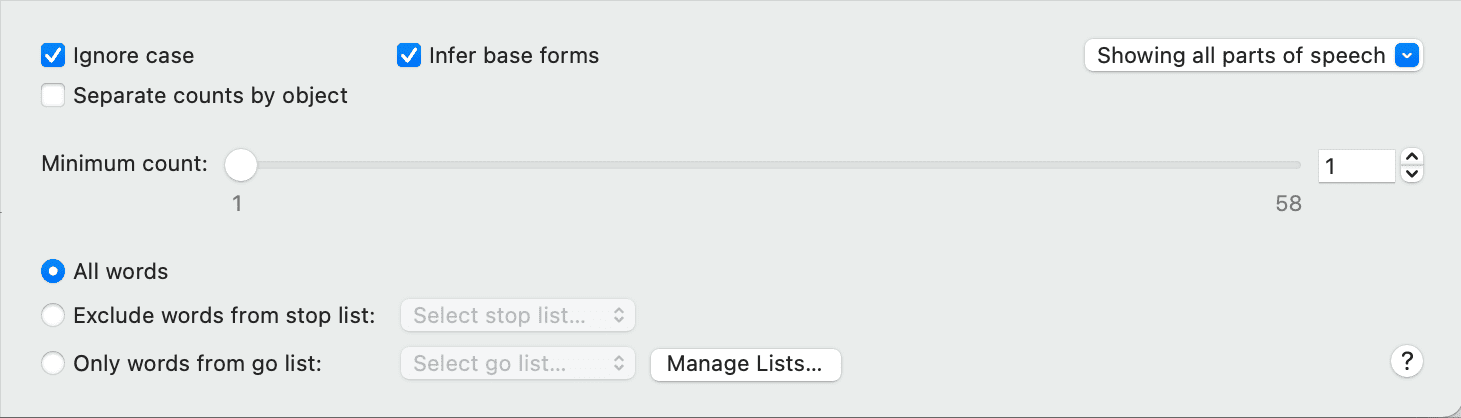

Partes de la oración
También puede seleccionar mostrar solo las palabras que pertenecen a una determinada categoría de palabras, las denominadas 'partes de la oración'.
Una parte de la oración es un término usado en la gramática tradicional para una de las categorías principales en las que se clasifican las palabras según sus funciones en las oraciones, como los sustantivos o los verbos. También conocidas como clases de palabras, son los bloques de construcción de la gramática.
Las partes de la oración del español comúnmente enumeradas son: sustantivo, verbo, adjetivo, adverbio, pronombre, preposición, conjunción, interjección, numeral, artículo o determinante.
Sustantivo
Los sustantivos son una persona, lugar, cosa o idea. Pueden desempeñar una multitud de funciones en una oración, desde el sujeto hasta el objeto de una acción. Se escriben con mayúscula cuando son el nombre oficial de algo o alguien, denominados en esos casos sustantivos propios. Ejemplos: pirata, Caribe, barco, libertad, Capitán Jack Sparrow.
Pronombre
Los pronombres sustituyen a los sustantivos en una oración. Son versiones más genéricas de los sustantivos que solo se refieren a personas. Ejemplos: yo, tú, él, ella, ello, nuestros, ellos, quién, cuál, cualquiera, nosotros mismos.
Verbo
Los verbos son palabras de acción que indican lo que sucede en una oración. También pueden mostrar el estado de ser del sujeto de una oración (es, era). Los verbos cambian de forma según el tiempo (presente, pasado) y la distinción de número (singular o plural). Ejemplos: cantar, bailar, cree, parecía, terminar, comer, beber, ser, se convirtió.
Adjetivo
Los adjetivos describen sustantivos y pronombres. Especifican cuál, cuánto, de qué tipo y más. Los adjetivos permiten a los lectores y oyentes usar sus sentidos para imaginar algo con más claridad. Ejemplos: caliente, perezoso, divertido, único, brillante, hermoso, pobre, suave.
Adverbio
Los adverbios describen verbos, adjetivos e incluso otros adverbios. Especifican cuándo, dónde, cómo y por qué ocurrió algo y en qué medida o con qué frecuencia. Ejemplos: suavemente, perezosamente, a menudo, solo, con suerte, a veces.
Preposición
Las preposiciones muestran las relaciones espaciales, temporales y de función entre un sustantivo o pronombre y las demás palabras en una oración. Aparecen al inicio de una frase preposicional, que contiene una preposición y su objeto. Ejemplos: sobre, encima de, contra, por, para, en, cerca de, fuera de, aparte de.
Conjunción
Las conjunciones unen palabras, frases y cláusulas en una oración. Hay conjunciones coordinantes, subordinantes y correlativas. Ejemplos: y, pero, o, así que, sin embargo, con.
Artículos y determinantes
Los artículos y determinantes funcionan como adjetivos al modificar los sustantivos, pero son diferentes de los adjetivos en que son necesarios para que una oración tenga la sintaxis adecuada. Los artículos y determinantes especifican e identifican los sustantivos, y existen artículos indefinidos y definidos. Ejemplos: artículos: un, una, el, la; determinantes: estos, ese, aquellos, suficiente, mucho, pocos, cuál, qué.
Algunas gramáticas tradicionales han tratado los artículos como una parte de la oración distinta. Las gramáticas modernas, sin embargo, más a menudo incluyen los artículos en la categoría de determinantes, que identifican o cuantifican un sustantivo. Aunque modifican los sustantivos como los adjetivos, los artículos son diferentes en que son esenciales para la sintaxis correcta de una oración, al igual que los determinantes son necesarios para transmitir el significado de una oración, mientras que los adjetivos son opcionales.
Interjección
Las interjecciones son expresiones que pueden usarse solas o dentro de oraciones. Estas palabras y frases a menudo transmiten emociones fuertes y expresan reacciones. Ejemplos: ¡ah!, ¡ups!, ¡ay!, ¡yabba dabba doo!
Clases de palabras abiertas y cerradas
Las partes de la oración se dividen comúnmente en clases abiertas (sustantivos, verbos, adjetivos y adverbios) y clases cerradas (pronombres, preposiciones, conjunciones, artículos/determinantes e interjecciones). La idea es que las clases abiertas pueden modificarse y ampliarse a medida que evoluciona el idioma, mientras que las clases cerradas están más o menos establecidas. Por ejemplo, se crean nuevos sustantivos cada día, pero las conjunciones nunca cambian.
En la lingüística contemporánea, la etiqueta de parte de la oración ha sido descartada en general en favor del término clase de palabra o categoría sintáctica. Estos términos facilitan la calificación objetiva de las palabras según su construcción en lugar de su contexto. Dentro de las clases de palabras, existe la clase léxica o abierta y la clase funcional o cerrada.
Fuente: The 9 Parts of Speech: Definitions and Examples
En ATLAS.ti, puede seleccionar una o más de las siguientes partes de la oración:
Todas las demás opciones se explican en el capítulo Exploración de datos de texto
Fusionar códigos
Tutorial en video:
Es posible que al comenzar la codificación muy cerca de los datos se genere una gran cantidad de códigos. Para no verse desbordado por una lista extensa, es necesario agregar esos códigos de vez en cuando, lo que implica fusionarlos y renombrarlos para reflejar un nivel de abstracción mayor. Otra razón para fusionarlos es que se detecte que dos códigos tienen el mismo significado pero se han usado con etiquetas diferentes.
Mover todos los códigos de baja frecuencia bajo un código de categoría para "limpiar" no es una buena solución. Puede comenzar usando etiquetas descriptivas para los códigos independientes, pero en algún momento será necesario agregarlos, generalmente después de haber repasado las primeras fuentes. Si hay demasiados códigos de baja frecuencia, se creará un sistema de codificación que se prolifera y se vuelve inmanejable (Bazeley, 2013). Además, tampoco será muy útil para el análisis.
Siempre hay excepciones. Los códigos de baja frecuencia que capturan un pensamiento especialmente perspicaz, por ejemplo, no deben fusionarse. Debería haber solo unos pocos de estos, no decenas o cientos.
Así es como se hace:
Seleccione dos o más códigos en el Administrador de códigos y arrástrelos hacia el código en el que desea fusionarlos. Se abre un menú. Seleccione la segunda opción Fusionar código ... en ...
Se inserta automáticamente un comentario en el código de destino que proporciona un registro de auditoría de los códigos fusionados. Si los códigos fusionados tenían un comentario, estos comentarios también se añaden al código de destino.
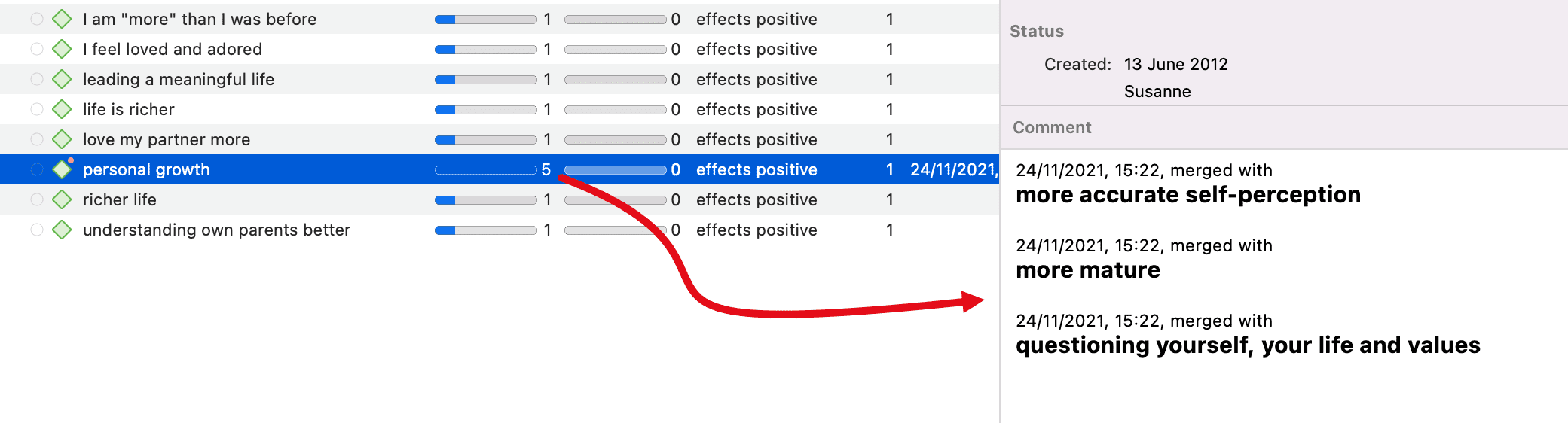
Dividir un código
"Inevitablemente, no todos los códigos que se producen seguirán siendo útiles. Algunos serán demasiado generales, otros demasiado específicos para uno o dos segmentos de datos (véase Fusionar códigos). Con excepción de los códigos contextuales, una categoría tan amplia o tan vagamente definida que codifica un número muy grande de pasajes o pasajes muy extensos tiene menos probabilidades de ser útil en el análisis" (Bazeley, 2013:185).
Dividir un código es necesario cuando se han agrupado muchas citas bajo un tema amplio. Este es un enfoque adecuado para una primera lectura de los datos con el fin de obtener una visión general. En algún momento, esos códigos deben dividirse en códigos con un número menor de codificaciones o en subcódigos de una categoría para ser significativos en el análisis.
Esto se puede hacer de dos maneras:
- División en códigos independientes
- División en subcódigos (creación de una categoría)
División de un código en códigos independientes
Haga clic derecho en un código que desee dividir en el Administrador de códigos o en el Explorador de proyecto y seleccione Dividir código en el menú contextual.
En la herramienta Dividir código se muestra la lista de citas codificadas con el código.
Haga clic en Agregar códigos para introducir las etiquetas de los subcódigos. Después de introducir el primer código, presione la flecha hacia la derecha (->|) para pasar al siguiente campo de entrada y escribir la segunda etiqueta, y así sucesivamente. Una vez terminado, haga clic en Agregar.
De forma predeterminada, el nombre del código original se añade a la primera columna de la tabla. Todas las citas siguen vinculadas a él. El siguiente paso es asignar las citas a los nuevos códigos que ha creado. Si una cita no encaja en ninguno de los nuevos códigos, puede dejarla vinculada al código original.
Así es como se asignan las citas a uno o más subcódigos:
Seleccione una cita. Su contenido se muestra en la parte inferior de la pantalla. Asigne la cita haciendo clic en la casilla de verificación de los códigos que correspondan. La cita se desvincula automáticamente del código que está dividiendo.
Para acelerar el proceso, puede presionar las teclas numéricas (1, 2, 3, etc.) para asignar la cita seleccionada al subcódigo 1, 2, 3, etc.
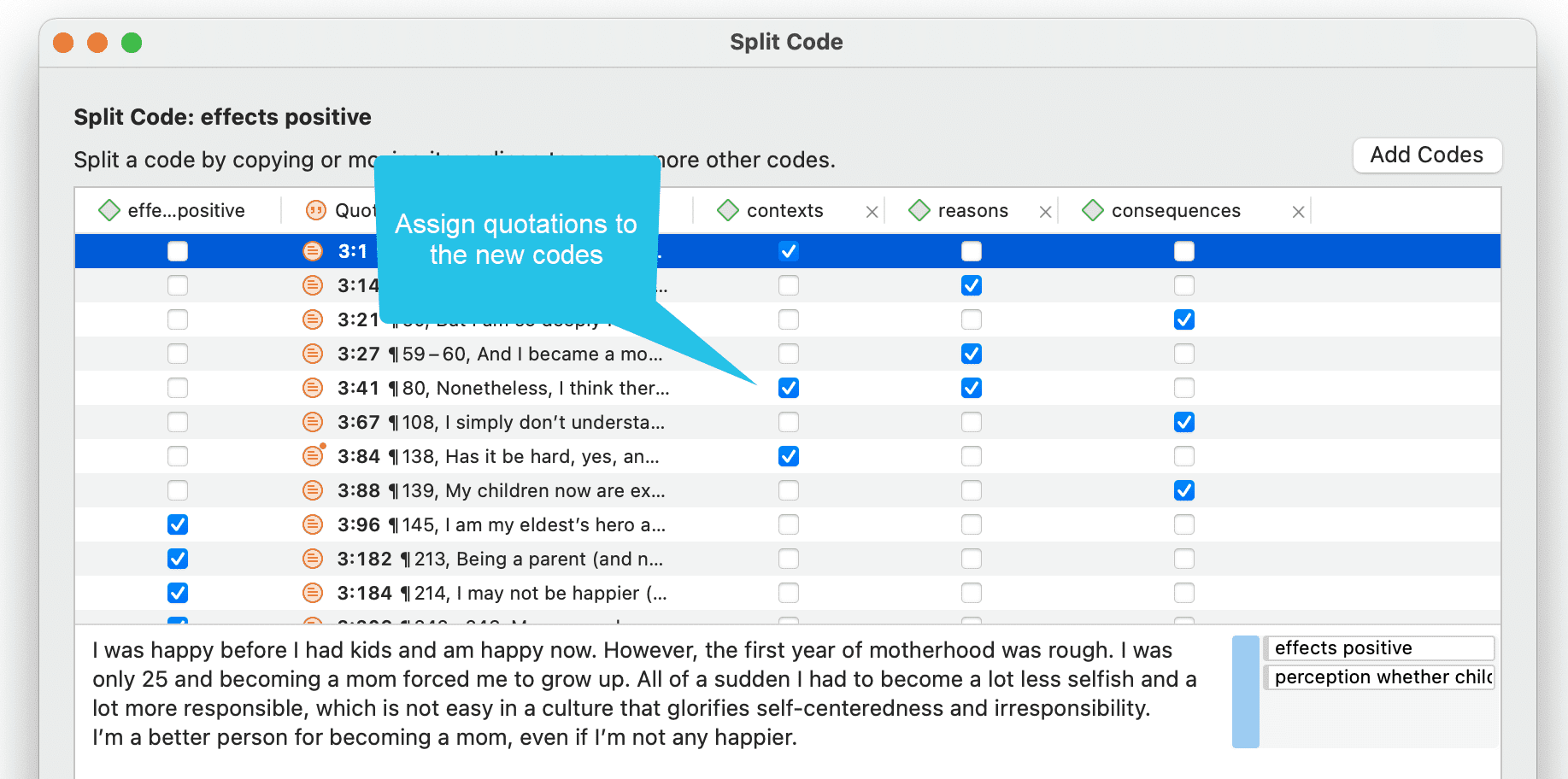
Después de haber distribuido algunas o todas las citas en los subcódigos, haga clic en Dividir código. Los nuevos códigos se crearán y las citas se asignarán en consecuencia.
No es necesario asignar todas las citas a los nuevos códigos. Las citas pueden permanecer vinculadas al código original, o también al código original y a cualquiera de los nuevos códigos creados.
Opciones
-
Copiar comentarios: Seleccione esta opción si desea que todos los subcódigos tengan el mismo comentario que el código que dividió.
-
Copiar vínculos: Seleccione esta opción si desea que todos los subcódigos hereden los vínculos existentes con otros códigos o memos.
-
Mutuamente exclusivo: Si se activa, solo se puede asignar una cita a un subcódigo. Esto es un requisito para algunos enfoques de análisis de contenido y para el cálculo del acuerdo entre codificadores.
Codificación mutuamente exclusiva
Si no desea permitir que una cita sea codificada con dos de los códigos, active la opción Mutuamente exclusivo. Esto es un requisito para algunos enfoques de análisis de contenido y para el cálculo del acuerdo entre codificadores. Consulte Requisitos para la codificación.
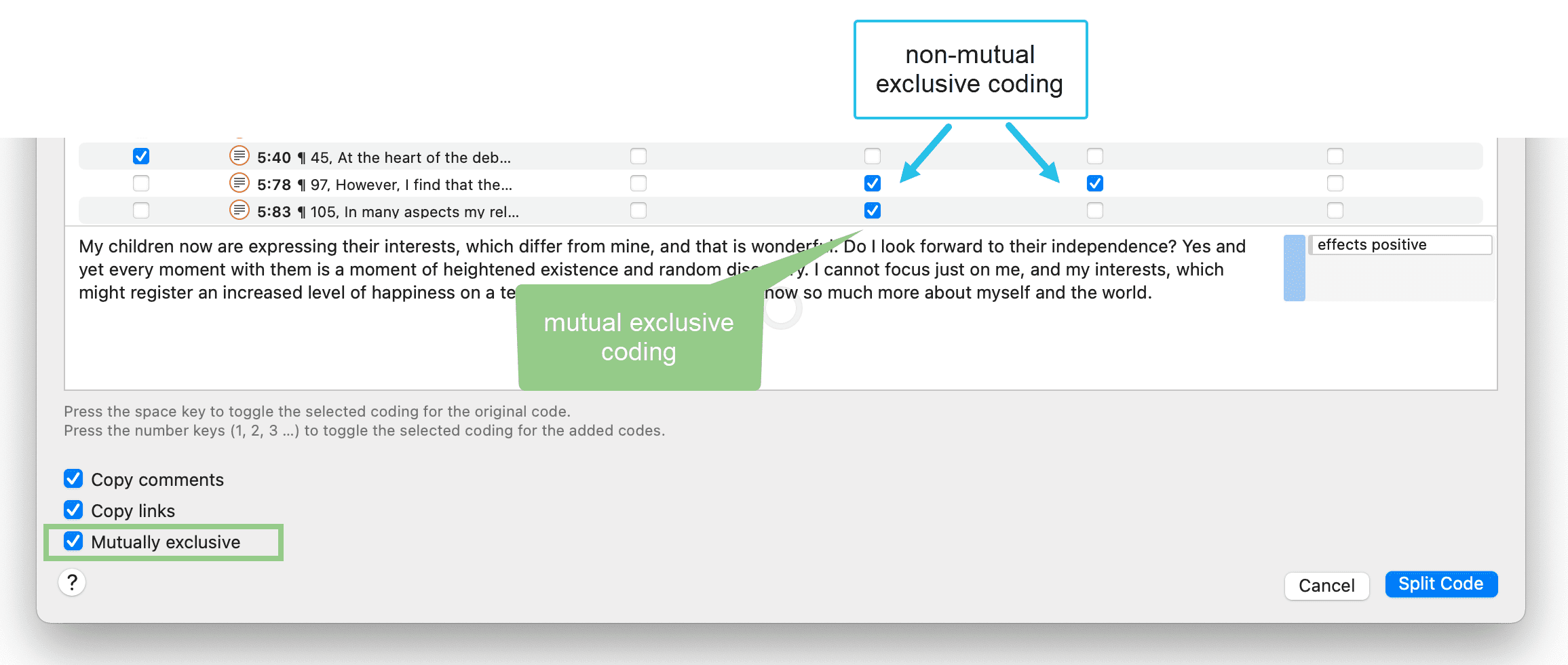
División de un código en una categoría y subcódigos
Seleccione un código que desee dividir en subcódigos.
Haga clic derecho y seleccione la opción Dividir en subcódigos. Se abre la herramienta Dividir código.
Haga clic en Agregar códigos para introducir las etiquetas de los subcódigos. Después de introducir el primer código, presione la flecha hacia la derecha (->|) para pasar al siguiente campo de entrada y escribir la segunda etiqueta, y así sucesivamente. Una vez terminado, haga clic en Agregar.
De forma predeterminada, se añade un subcódigo con el nombre Indeciso a la primera columna de la tabla. Todas las citas se añaden a este subcódigo. El siguiente paso es asignar las citas a los nuevos subcódigos que ha creado. Si una cita no encaja en ninguno de los subcódigos, puede dejarla en el subcódigo 'Indeciso'.
Así es como se asignan las citas a uno o más subcódigos:
Seleccione una cita. Su contenido se muestra en la parte inferior de la pantalla. Asigne la cita haciendo clic en la casilla de verificación de los subcódigos que correspondan. La cita se desvincula automáticamente del subcódigo 'Indeciso'.
Para acelerar el proceso, puede presionar las teclas numéricas (1, 2, 3, etc.) para asignar la cita seleccionada al subcódigo 1, 2, 3, etc.
Mutuamente exclusivo: Si no desea permitir que una cita sea codificada con dos de los subcódigos, active la opción Mutuamente exclusivo. Esto es un requisito para algunos enfoques de análisis de contenido y para el cálculo del acuerdo entre codificadores. Consulte Requisitos para la codificación.
Una vez que todas las citas hayan sido asignadas a uno o más subcódigos, haga clic en Dividir código. El código que dividió se convertirá en una categoría, lo cual se indica mediante el cambio en el icono del código. Si hace clic en la flecha desplegable frente al código, puede expandir la categoría para ver los subcódigos.
El enraizamiento de un código de categoría es el número de citas codificadas por todos sus subcódigos. Dado que se pueden aplicar varios códigos a la misma cita, el total de una categoría puede diferir de la simple suma de citas de todos los subcódigos. Ambas sumas son iguales solo si se usan los subcódigos de manera mutuamente exclusiva.
Visualización de códigos en el Explorador de proyecto y el Navegador de códigos
En el Explorador de proyecto, bajo la rama principal de Códigos, se listan todos los códigos. Si solo desea ver la lista de códigos, haga clic en el icono de código en la barra de herramientas.
El número que aparece detrás de la rama principal de códigos, p. ej., (11), es el número total de entradas de primer nivel. Estas pueden ser carpetas, categorías y códigos independientes.
El número que aparece detrás de una carpeta es el número de citas codificadas por los códigos independientes o subcódigos contenidos en ella. Como se pueden aplicar múltiples códigos a la misma cita (es decir, codificación multivalor), el total puede diferir de la suma de todos los números de todos los códigos independientes y subcódigos.
El número que aparece detrás de un código de categoría es el número de citas codificadas por todos sus subcódigos. Como se pueden aplicar múltiples códigos a la misma cita, el total de una categoría puede diferir de la suma de los números de cada subcódigo. Solo es igual si se aplican subcódigos de manera mutuamente exclusiva, como se requiere por ejemplo para el análisis de acuerdo entre codificadores
Opciones de vista en el Administrador de códigos
Hay tres Modos de vista: Se pueden ver los códigos en vista de lista (predeterminado), como nube o en forma de gráfico de barras:
Lista de códigos como gráfico de barras
Seleccione el Gráfico de barras para visualizar la lista de códigos en forma de gráfico de barras.
Los códigos en la vista de gráfico de barras también tienen un menú contextual. Por lo tanto, desde aquí también se pueden iniciar las mismas acciones que en la vista estándar.
Nube de códigos
Seleccione la opción Nube para visualizar la lista de códigos en forma de nube de palabras:

Si hace clic derecho en un código, se abre el mismo menú contextual que en la vista 'Lista'. Por lo tanto, en la vista de nube se pueden iniciar las mismas acciones que en la vista habitual. Por ejemplo, se pueden renombrar códigos, establecer un color, dividirlos o abrir una red sobre uno o varios códigos.
El gráfico "Distribución de códigos por documento" que aparece debajo de la lista de códigos se explica en el capítulo Análisis de distribuciones de códigos.
Visualizar la lista de códigos como nube de códigos o gráfico de barras
Una forma alternativa de ver la lista de códigos es en forma de nube de códigos o gráfico de barras.
Nube de códigos
En el Administrador de códigos, seleccione el Modo de vista y seleccione la opción Nube de códigos.

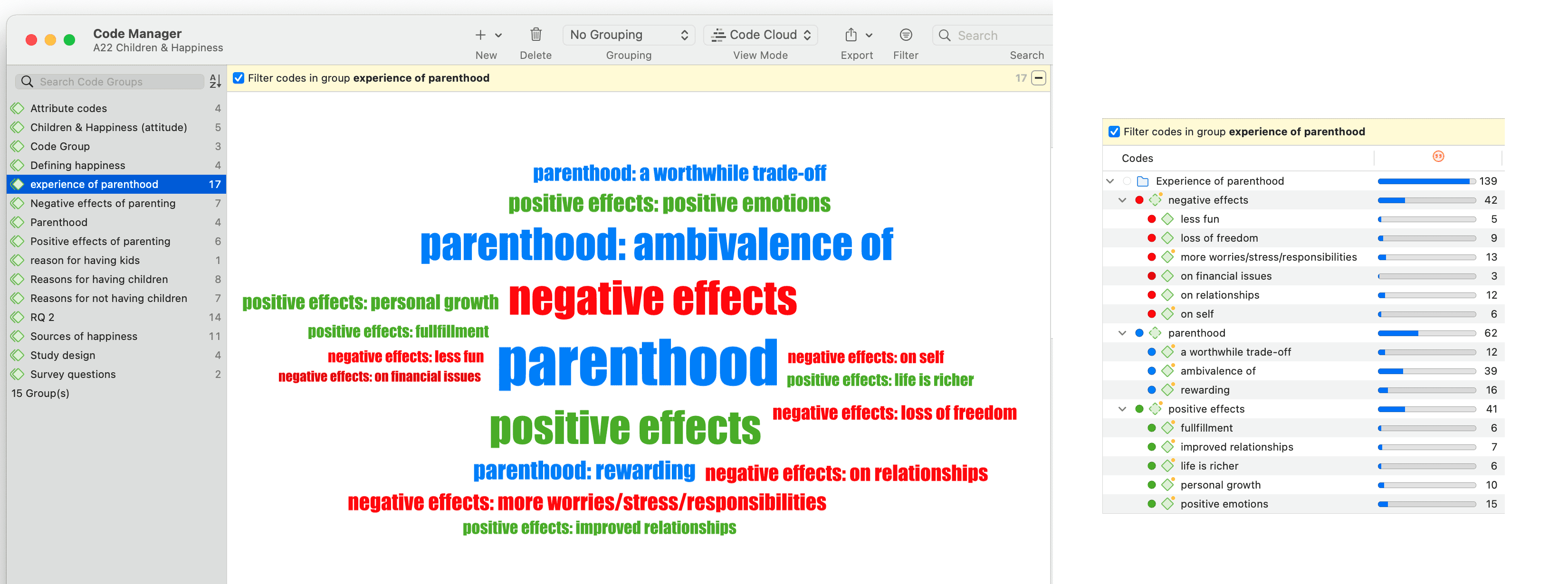
La imagen anterior muestra una lista de códigos filtrada por un grupo de códigos que contiene tres categorías y sus subcódigos. Los subcódigos se muestran con sus nombres completos en la nube de códigos (categoría: subcódigo).
Lista de códigos como gráfico de barras
Seleccione la opción Gráfico de barras para visualizar la lista de códigos en forma de gráfico de barras.
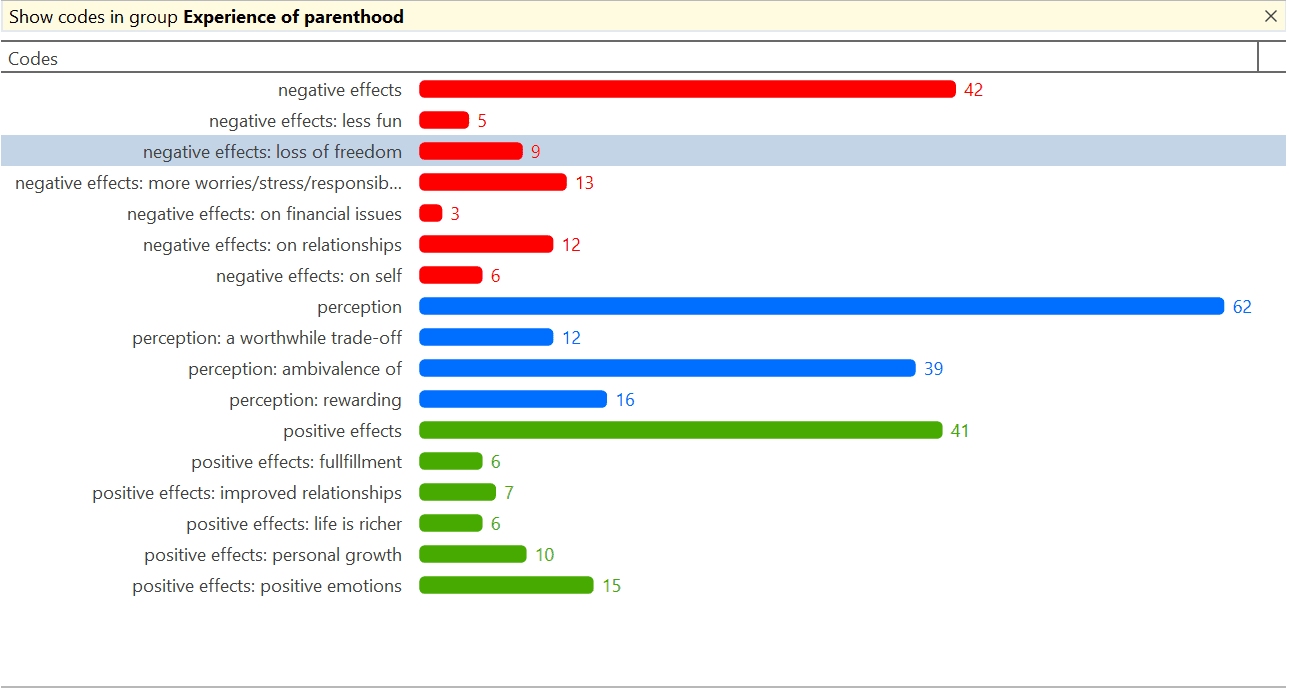
Si hace clic derecho en un código, se abre el mismo menú contextual que en la vista 'Lista'. Por lo tanto, en la vista de nube se pueden iniciar las mismas acciones que en la vista habitual. Por ejemplo, se pueden renombrar códigos, dividirlos o fusionarlos, o abrir una red sobre uno o varios códigos.
Imprimir la vista de nube de códigos o el gráfico de barras
Puede imprimir tanto la vista 'Nube' como el 'Gráfico de barras'. Para hacerlo:
Seleccione el botón Exportar en la barra de herramientas y desde allí Exportar imagen. La imagen se guarda como archivo .png.
Trabajo con grupos de códigos
Los grupos de códigos ayudan a organizar los códigos, facilitan el acceso a códigos específicos en una lista larga y permiten crear cualquier tipo de filtro necesario para consultar los datos.
Los grupos de códigos se pueden crear de dos maneras: en el Administrador de grupos de códigos o en el panel lateral del Administrador de códigos.
Para abrir el Administrador de códigos, haga doble clic en la rama principal de códigos en el Explorador de proyecto, o haga clic en el botón de códigos de la barra de herramientas y seleccione Administrador de códigos en el menú desplegable.
Seleccione algunos códigos y arrástrelos hacia el área de filtros en el lado izquierdo. Tras soltar los códigos, el grupo de códigos se crea automáticamente. Si desea cambiar el nombre predeterminado, haga clic con el botón izquierdo sobre el grupo de códigos.
Al hacer clic en el grupo de códigos recién creado, solo aparecerán en la lista de la derecha los códigos de ese grupo. Esto permite acceder rápidamente a los códigos sin necesidad de desplazarse por la lista continuamente.
Para mostrar todos los códigos de nuevo, haga clic en el signo menos (-) del panel amarillo que aparece en la parte superior de la lista de códigos al seleccionar un grupo.
Para obtener más información sobre cómo trabajar con grupos, consulte Trabajo con grupos.
Si le interesa conocer las diferencias entre códigos, grupos de códigos y códigos inteligentes, vea este video.
Importar y exportar una lista de códigos
Exportar la lista de códigos
Use esta opción si desea exportar una lista de códigos para reutilizarla en otro proyecto de ATLAS.ti o en otro software. Para esto último, es necesario usar la opción de exportación QDPX. Para más información, consulte el capítulo sobre Intercambio universal de datos
Para exportar todos los códigos con comentarios y grupos para su uso en otro proyecto de ATLAS.ti, seleccione Códigos > Exportar > Libro de códigos (XLSX).
Seleccione una ubicación donde guardar el archivo y haga clic en Guardar.
Importar la lista de códigos
Importar un libro de códigos ya existente puede ser útil por varias razones:
- Para preparar un conjunto de códigos predefinidos en el marco de una teoría determinada. Esto es especialmente útil en el contexto de un proyecto en equipo al crear un proyecto maestro.
- Para codificar de manera "deductiva" (o de arriba hacia abajo), con todos los conceptos necesarios ya disponibles. Esto complementa la etapa de codificación inductiva (o de abajo hacia arriba), en la que los conceptos emergen de los datos.
Puede preparar un libro de códigos con descripciones, grupos y colores de códigos en Excel e importar el archivo Excel. A continuación se indica cómo debe preparar el archivo Excel:
Puede introducir encabezados como Código, Definición de código, Grupo de código 1, Grupo de código 2, pero no es obligatorio. Los encabezados pueden estar en cualquier idioma. Las columnas se interpretan en el siguiente orden, independientemente de si se agregan encabezados o no:
- columna 1: nombre del código
- columna 2: descripción del código (comentario)
- columna 3: grupo de código 1
- columna 4: grupo de código 2
- todas las columnas siguientes: grupos de códigos adicionales

- Todos los códigos individuales se importan como códigos independientes.
- Todos los códigos que tengan el mismo prefijo se importarán como subcódigos. A partir del prefijo, ATLAS.ti determina los códigos de categoría. Como en el ejemplo mostrado aquí: 'benefit' se convertirá en un código de categoría; todos los códigos como 'benefit: creative' o 'benefit: collaboration' se convertirán en subcódigos de benefit.
- Si asigna color a los nombres de los códigos, ese color se usará en ATLAS.ti como color del código.
Las carpetas no se pueden importar mediante el archivo Excel. Deben añadirse posteriormente.
Para importar el archivo Excel, seleccione Códigos > Importar > Libro de códigos (XLSX).
Seleccione un archivo. Dependiendo de si ha insertado encabezados en el archivo Excel, active o desactive la opción "Ignorar encabezados (primera fila) durante la importación". Esta opción se encuentra en la parte inferior izquierda del selector de archivos.
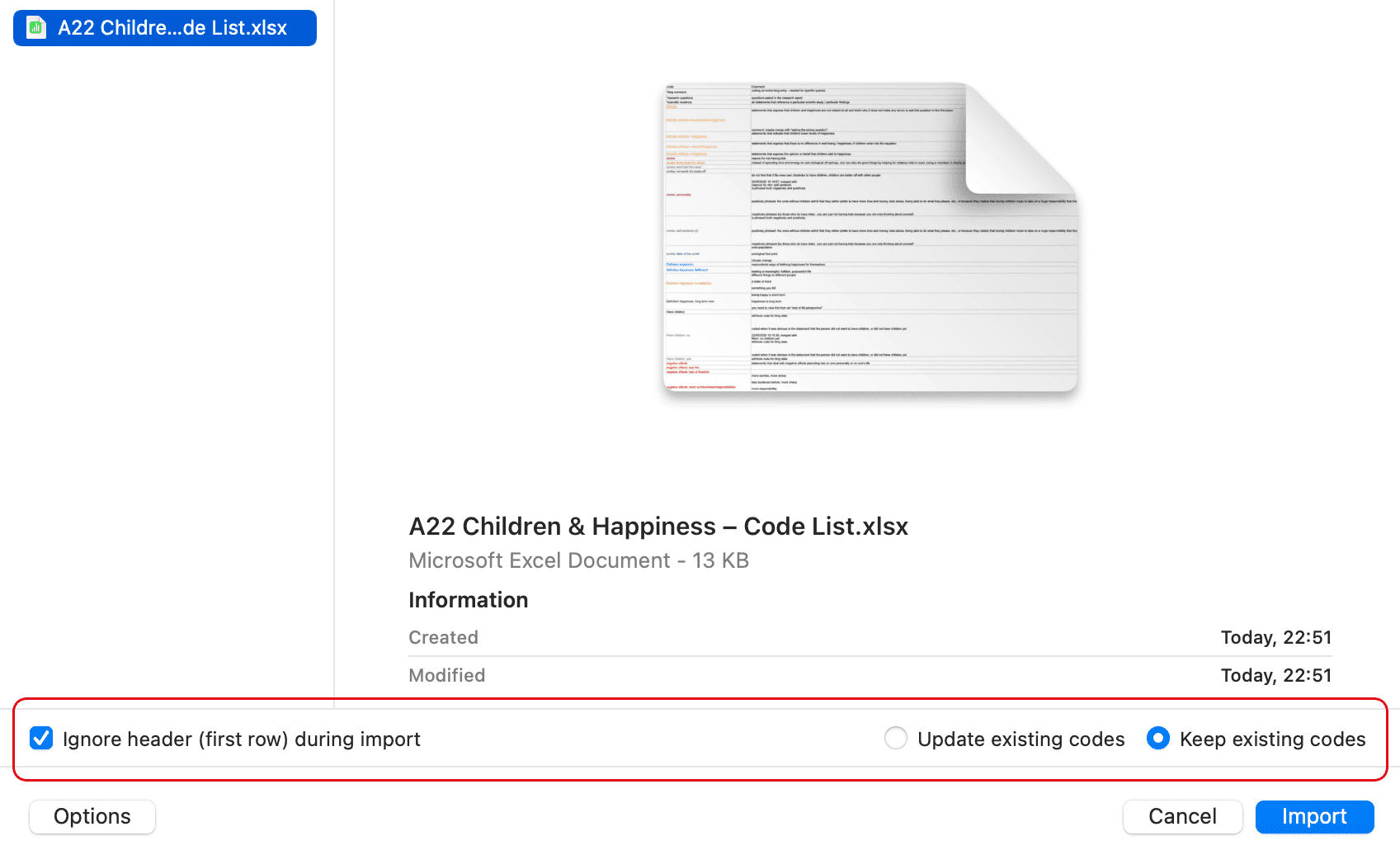
Si su proyecto ya tiene códigos, deberá decidir qué debe hacer ATLAS.ti si la lista de códigos de la tabla Excel contiene códigos que ya existen en su proyecto. Puede actualizar los atributos de los códigos existentes, es decir, el color y el comentario del código, para que coincidan con la información del archivo Excel. En ese caso, seleccione Actualizar códigos existentes. Si no desea modificar los códigos existentes, seleccione Conservar códigos existentes.
Realice sus elecciones y haga clic en Importar.
Construcción de un sistema de códigos
Una lista de códigos bien estructurada es importante para el análisis posterior, en el que se buscan relaciones y patrones en los datos con el objetivo de integrar todos los resultados para contar una historia coherente. Si, como en una encuesta, solo se tienen preguntas con categorías de respuesta "sí" y "no" en el cuestionario, los datos solo constarán de variables nominales. Esto significa que el análisis es limitado y no va más allá del nivel descriptivo. Esto es comparable a un libro de códigos que consiste en un conjunto de códigos cuyo nivel de análisis permanece indefinido. El objetivo de construir un sistema de códigos es poder acceder a los datos a través de los códigos y aprovechar al máximo las herramientas de análisis.
Al final del capítulo encontrará una lista de artículos y libros en los que se basan las siguientes recomendaciones.
Cómo empezar a construir un sistema de códigos
A menos que se trabaje con códigos a priori derivados teóricamente, al principio se crearán códigos para capturar ideas a medida que surjan. La lista de códigos crece y resulta cada vez más difícil mantener una visión de conjunto. Es hora de empezar a gestionar la lista de códigos. Esto puede ocurrir después de codificar un documento, una entrevista o algunos documentos. Gestionar los códigos implica comenzar a ordenarlos en carpetas, categorías y subcódigos. Los grupos de códigos también pueden ayudar en este proceso. A través de los grupos de códigos se pueden recopilar códigos relacionados. Luego, se establece el grupo de códigos como filtro para concentrarse en ese subconjunto más reducido de códigos. ¿Qué códigos podrían formar una categoría?, ¿cuáles deben fusionarse o dividirse?
Aplicar un catálogo organizado jerárquicamente al sistema de códigos tiene varias ventajas. Véase también Bazely (2013:179-183).
-
Crea orden: se sabe dónde buscar para colocar o encontrar un código determinado.
-
Aporta claridad conceptual para uno mismo y para los demás.
-
Proporciona un recordatorio para codificar aspectos adicionales a medida que se continúa la codificación. Por ejemplo, se recuerda codificar las 'razones para tener hijos', las 'fuentes de felicidad', la 'definición de felicidad', etc., porque existe una categoría para este tipo de cosas. También sensibiliza para detectar otros subcódigos que aparecen en los datos.
-
Ayudará a identificar patrones de relaciones en los datos. No solo se podrán hacer preguntas sobre una categoría en particular, sino que también permitirá explorar relaciones entre categorías, por ejemplo, entre emociones y eventos. Se puede explorar, por ejemplo, si determinados eventos dan lugar regularmente a determinadas emociones. Esto se logra mejor si los tipos de cosas cuyas asociaciones se desean explorar están codificados en diferentes categorías; en este caso, una categoría 'Emoción' con los distintos tipos de emociones como subcódigos, y una categoría 'Evento' con los distintos eventos como subcódigos. Por lo tanto, solo se necesita una jerarquía de 2 niveles compuesta por categorías y subcódigos.
Varios autores ofrecen sugerencias sobre cómo pueden agruparse los códigos en un sistema de códigos. Lofland (1971), por ejemplo, propuso actos, actividades, significados, participación, relaciones y escenarios. Bogdan y Biklen (1992) propusieron escenario/contexto, definición de la situación, perspectivas, comprensiones de personas y objetos, proceso, actividades, eventos, estrategias, relaciones y estructura social. Bazeley (2013) añadió personas/actores/participantes, cuestiones, es decir, asuntos planteados sobre los que puede haber debate, actitudes, creencias, posiciones ideológicas, marcos, contexto cultural, respuestas o estados emocionales, características personales, impacto/resultados (facilitadores o barreras).
Puede descubrirse que algunas de estas ideas se traducen fácilmente en una categoría con subcódigos; otras pueden ser demasiado abstractas para codificar con ellas. En cambio, pueden usarse a nivel de carpeta. Dentro de la carpeta se pueden desarrollar categorías con subcódigos que puedan aplicarse para codificar los datos.
A continuación se muestra un ejemplo. En la primera captura de pantalla, solo se ve el nivel de carpeta y categoría. Se han creado grupos de códigos como medio para filtrar en el nivel de carpeta y categoría con diferentes propósitos. Consulte Análisis de datos adicional
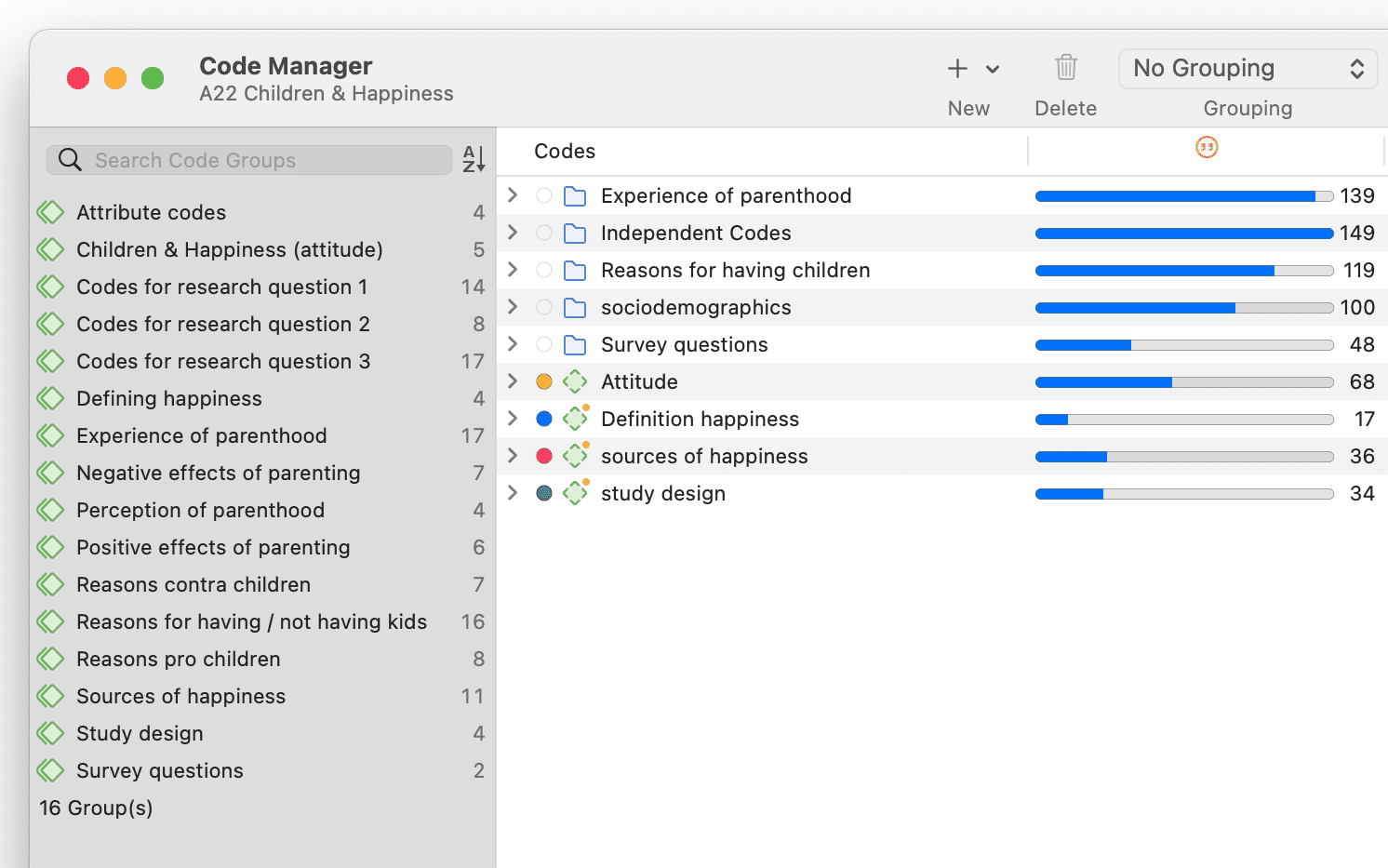
En la segunda captura de pantalla, las carpetas se han expandido y se puede ver el tipo de categorías que se ordenaron en las distintas carpetas.
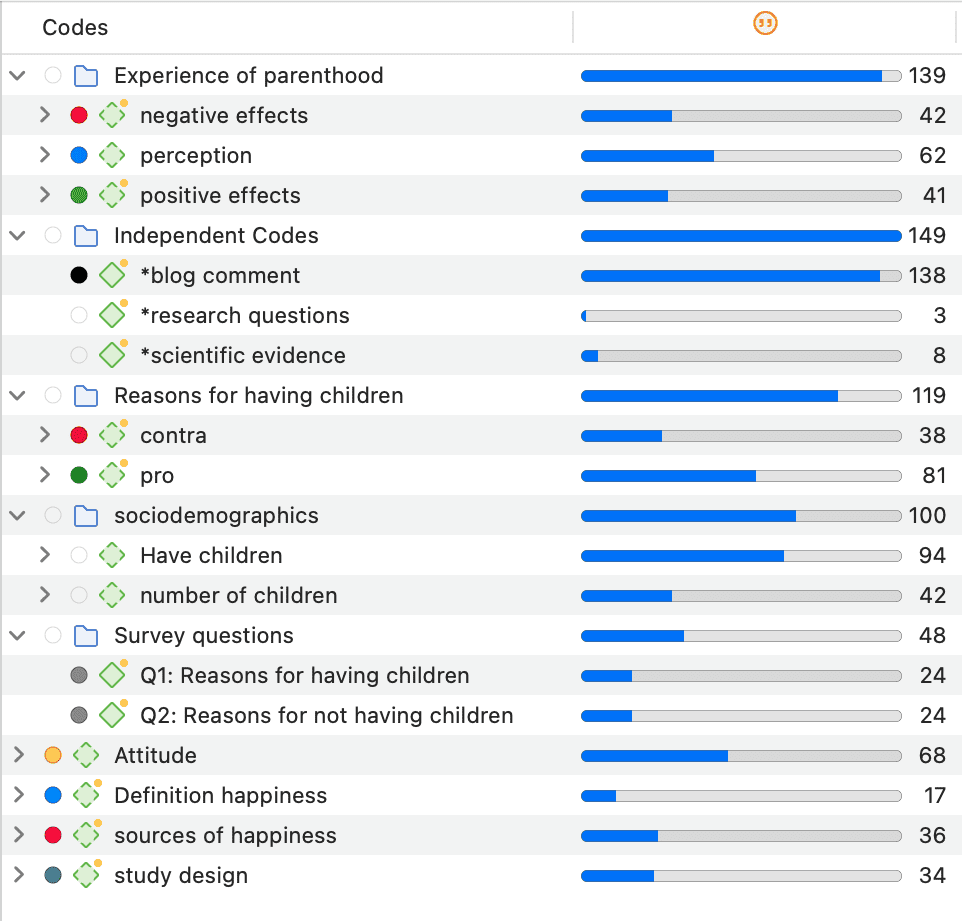
Si tiene transcripciones de entrevistas y desea "codificar" atributos de los encuestados como género, edad, estado civil y similares, debe usar grupos de documentos. Solo se codifican las características sociodemográficas si hay varios encuestados en un mismo documento, como es el caso de los datos de grupos focales.
En la tercera captura de pantalla, algunas categorías se han expandido y se pueden ver los subcódigos. En versiones anteriores de ATLAS.ti era útil usar el mismo color para todos los códigos de una categoría. Dadas las nuevas herramientas de visualización, por ejemplo en el Administrador de documentos y de códigos, puede ser útil asignar un color diferente a cada subcódigo, como se muestra para la categoría 'fuentes de felicidad'.
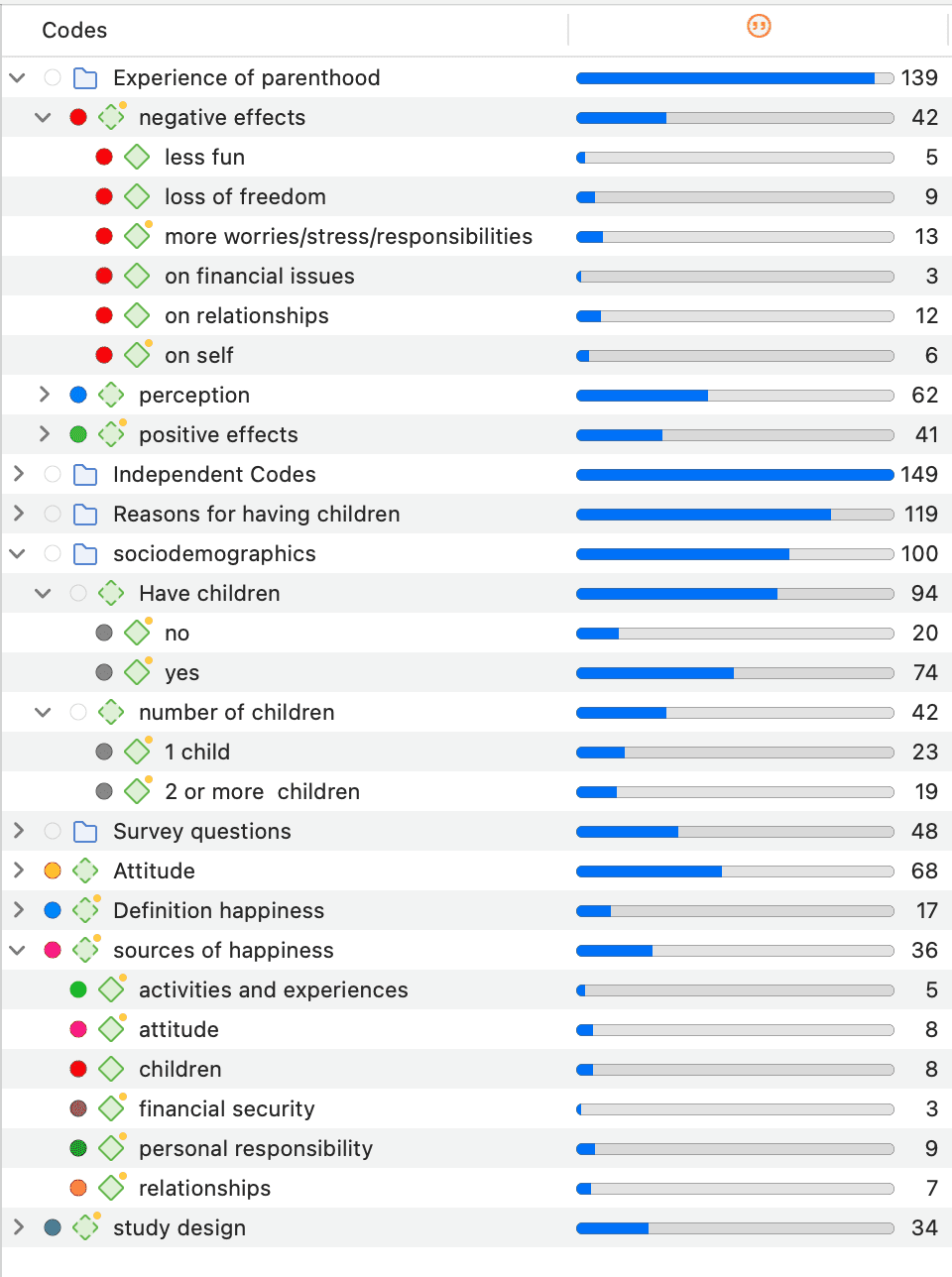
Características de una lista de códigos bien estructurada
- Cada código es distinto; su significado es diferente al de cualquier otro código.
- El significado de cada código está descrito en el comentario del código.
- Cada categoría puede distinguirse claramente de las otras categorías.
- Todos los subcódigos pertenecientes a una categoría son similares, ya que representan el mismo tipo de cosa. No obstante, cada subcódigo dentro de una categoría es distinto.
- Cada código aparece solo una vez en el sistema de códigos.
- El sistema de códigos es ateórico. Esto significa que el sistema de códigos en sí mismo no representa un modelo ni una teoría. Los códigos simplemente describen los datos para que se pueda acceder a ellos fácilmente a través de ellos.
- El sistema de códigos debe ser lógico, de modo que se pueda encontrar lo que se busca.
- El sistema de códigos contiene entre 10 y 25 categorías de primer nivel.
- El sistema de códigos tiene no más de dos o tres niveles de profundidad. Por lo tanto, consta de carpetas, categorías y sus subcódigos. Si hay capas de significado en una sección de los datos, es mejor crear códigos separados y codificar los datos con varios códigos. De esta forma se pueden asociar posteriormente esas capas de significado, por ejemplo, usando la tabla de co-ocurrencias de códigos.
Consejos de buenas prácticas
Organice la estructura de códigos según similitudes conceptuales, no según asociaciones observadas o teóricas, ni según cómo se piense escribir los capítulos de resultados.
Use un código separado para cada elemento del contenido del texto, es decir, cada código debe abarcar un solo concepto. Si hay múltiples aspectos, el pasaje puede codificarse con múltiples códigos.
No se preocupe si no todos los códigos pueden ordenarse en una categoría. Algunos códigos permanecerán como códigos individuales. Para no "perderlos", recójalos en una carpeta, de modo que aparezcan en su propia sección en el sistema de códigos.
El papel de los grupos de códigos en la construcción de un sistema de códigos
Si tiene muchos códigos de baja frecuencia que desea o necesita fusionar, los grupos de códigos son una buena manera de recopilarlos. Después de haber añadido todos los códigos de bajo nivel que pertenecen al mismo tema / tópico / idea, puede establecer ese grupo de códigos como filtro. Esto facilita la fusión de los códigos. El siguiente paso más probable es crear una categoría y añadir los códigos fusionados como subcódigos. Puede que desee conservar el grupo de códigos porque resultará útil más adelante en el análisis como filtro.
Avanzar
Una vez codificados los datos, se tiene una buena visión general del material y se puede describir. A continuación, se puede profundizar el análisis consultando los datos. Las herramientas disponibles incluyen la tabla de co-ocurrencias de códigos, la tabla de código-documento, la herramienta de consulta y las redes.
El objetivo es profundizar en los datos y encontrar relaciones y patrones. Escribir memos es muy importante en esta etapa, ya que gran parte del análisis no ocurre simplemente por aplicar una herramienta. Las ideas surgen al leer los datos resultantes de una consulta y al redactar resúmenes e interpretaciones.
Literatura
Las recomendaciones de esta sección se basan en los siguientes autores:
Bazeley, Pat (2013). Qualitative Data Analysis: Practical Strategies. London: Sage.
Bernard, Russel H. and Ryan, Gery W. (2010). Analysing Qualitative Data: Systematic Approaches. London: SAGE Publications.
Bodgan, R., and Biklen, S.K. (1992). Qualitative Research for education: An introduction to theory and methods (2nd ed.). Boston: Allyn & Bacon.
Charmaz, Kathy (2006/2014). Constructing Grounded Theory: A Practical Guide Through Qualitative Analysis. London: SAGE Publications.
Corbin, Juliet and Strauss, Anselm (2008/2015, 3rd and 4th ed.). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory. Thousand Oaks, CA: SAGE Publications.
Freeman, Melissa (2017). Modes of Thinking for Qualitative Data Analysis. NY: Routledge.
Friese, Susanne (2019). Qualitative Data Analysis with ATLAS.ti. London: Sage.
Gibbs, G. (2008). Analysing Qualitative Data. London: SAGE.
Guest, G., MacQueen, K.M., and Namey, E.E. (2012). Applied Thematic Analysis. Los Angeles: SAGE Publications.
Guest, G., Kathleen M. MacQueen, and Emily E. Namey (2012). Applied Thematic Analysis. Los Angeles: Sage.
Hammersley M., and Atkinson P. (2007) Ethnography: Principles in Practice. Third edition. London: Routledge.
Johnston, L. (2006). Software and method: Reflections on teaching and using QSR NVivo in doctoral research. International Journal of Social Research Methodology, 9(5), 379–391.
Lofland, J. (1971). Analyzing social settings: A guide to qualitative observation and analysis. CA: Wadsworth.
Miles, Matthew B., Huberman, M., and Saldaña, J. (2014, 3rd ed.). Qualitative Data Analysis. Thousand Oaks, CA: SAGE Publications.
Richards, L., and Morse, J.M. (2013, 3rd ed). Readme first: for a user's guide to Qualitative Methods. Los Angeles: Sage
Richards, L. (2021, 4ed). Handling qualitative data: A practical guide. London: SAGE Publications.
Saldaña, J. (2021). The Coding Manual for Qualitative Researchers. London: SAGE Publications.
Spradley, James P. (2016). The Ethnographic Interview. Waveland Press.
Strauss, A. (1987). Qualitative analysis for social scientists. Cambridge, UK: Cambridge University Press.
Weston, C., Gandell, T., Beauchamp, J., Beauchamp, C., McApline, L., and Wiseman, C. (2001). Analyzing Interview Data: The Development and Evolution of a Coding System, Qualitative Sociology, 24(3): 381-400.
Creación de un libro de códigos
Si desea crear un libro de códigos para el apéndice de un informe, no use la opción Exportar libro de códigos que se encuentra en el menú principal de Código. El propósito de esta opción es transferir libros de códigos entre proyectos o equipos.
La opción recomendada para crear un libro de códigos es utilizar la opción de exportación a Excel del Administrador de códigos:
Abra el Administrador de códigos. Haga clic en el botón Exportar y seleccione Exportar como hoja de cálculo.
ATLAS.ti exporta todas las columnas visibles en el Administrador de códigos. Si hace clic en el encabezado de una columna en el Administrador de códigos, puede deseleccionar las columnas que no desea exportar.
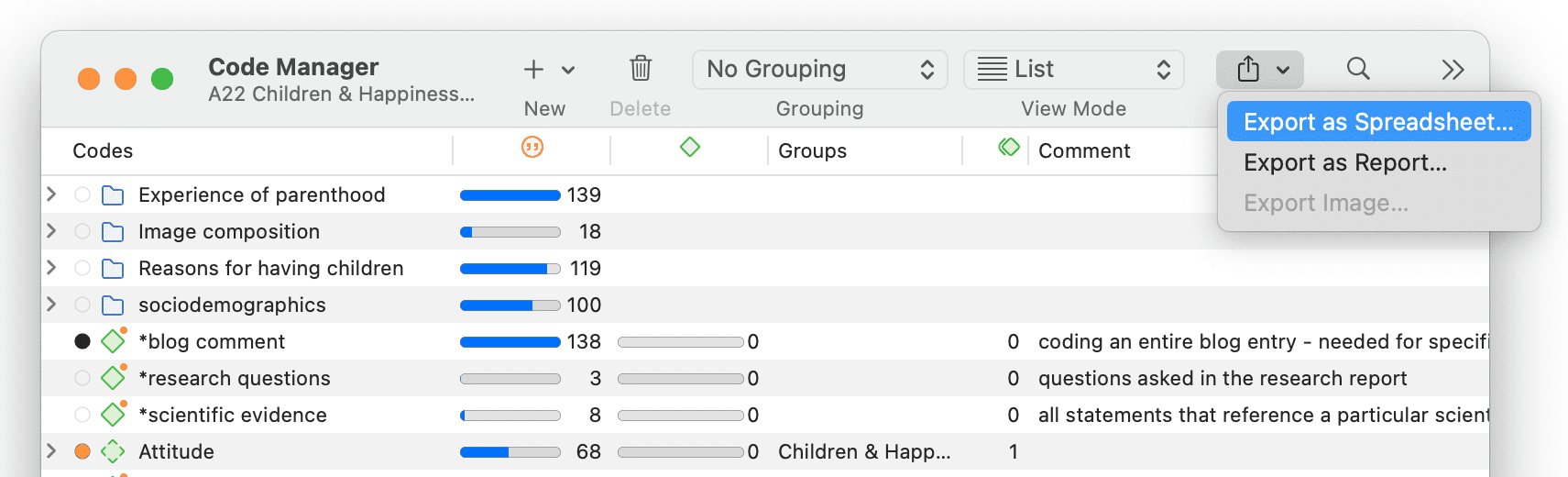
Resultado de ejemplo:
Las carpetas y los códigos independientes se listan en la primera columna, las categorías en la segunda columna y los subcódigos en la tercera columna.

Lector de citas
Tutorial en video: El Lector de citas
El Lector de citas permite leer cómodamente las citas codificadas con un código seleccionado o como resultado de una consulta. Es posible modificar los códigos existentes, es decir, agregar o eliminar códigos. En otros contextos, esto se conoce como codificación continua.
En el Lector de citas, se puede:
- cambiar entre vista de línea única, previsualización pequeña y grande
- agregar o modificar el nombre de la cita
- escribir un comentario para una cita
- aplicar códigos nuevos o existentes
- eliminar códigos aplicados
- ver una cita en el contexto del documento original
- eliminar una cita
Barra de herramientas

Código
Para cambiar la codificación de una cita, haga clic en el botón Código en la barra de herramientas, o haga clic derecho y seleccione Aplicar códigos, o use el atajo: cmd+J. Esto abre el diálogo de codificación, donde se pueden usar todas las opciones que se explican en la sección Codificar datos.
También se puede codificar con el último código utilizado. Haga clic derecho en una cita y seleccione Agregar últimos códigos usados. O bien: seleccione varias citas, haga clic derecho y luego seleccione la opción Últimos códigos usados.
También se pueden seleccionar varias citas o todas las citas y codificarlas con un código nuevo o existente. También se puede codificar con el último código usado: haga clic derecho en una cita y seleccione Agregar últimos códigos usados. O bien: seleccione varias citas, haga clic derecho y luego seleccione la opción Últimos códigos usados.
También se pueden seleccionar varias citas o todas las citas y codificarlas con un código nuevo o existente.
Vista
Según la longitud de las citas, se puede ajustar la vista a línea única, previsualización pequeña o grande. Si las citas son muy cortas, la vista de línea única puede ser suficiente. También es útil cuando se ha creado un nombre propio para las citas, por ejemplo, para parafrasear datos textuales o escribir títulos para citas multimedia.
Ver en contexto

Si se desea ver una cita en el contexto del documento original, haga clic en la flecha hacia la derecha o haga doble clic.
Opciones
Crear grupo de documentos: Se puede crear un nuevo grupo de documentos que contenga todos los documentos de los que forman parte las citas en el Lector de citas. Supongamos que se codificaron los años de experiencia profesional. Esto surgió en la entrevista y no se sabía de antemano. Si se desea comparar las declaraciones de personas con diferentes duraciones de experiencia laboral, esta es una forma conveniente de convertir un código en un grupo de documentos y, en este caso, en una variable de comparación. Véase Trabajar con grupos.
Exportar como hoja de cálculo: Se pueden exportar todas las citas a una hoja de cálculo de Excel.
Exportar como informe: Se puede crear un informe de texto que contenga todas las citas y demás información de interés. Encontrará más información sobre cómo crear informes de texto aquí.
Opciones del menú contextual
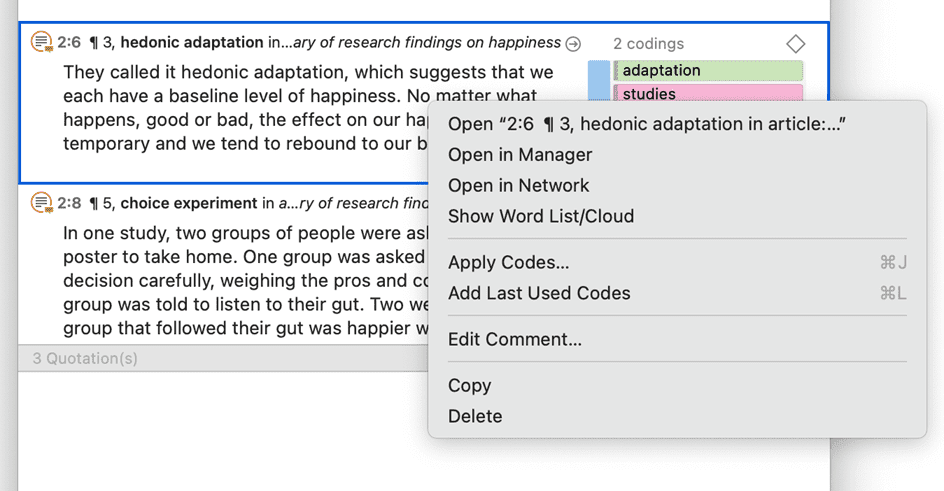
Abrir red: Si se desea ver todos los vínculos de una cita, seleccione una o varias citas, haga clic derecho y seleccione Abrir en red. Véase Trabajar con redes.
Mostrar lista/nube de palabras: Otra opción del menú contextual es mostrar una lista de palabras o una nube de palabras para los elementos seleccionados. Véase Trabajar con listas y nubes de palabras.
Escribir un comentario: Si se desea escribir un comentario para una cita, selecciónela, haga clic derecho y seleccione Editar comentario en el menú contextual. O bien, selecciónela y escriba un comentario en el campo de comentario que se encuentra en la parte inferior del Lector de citas.
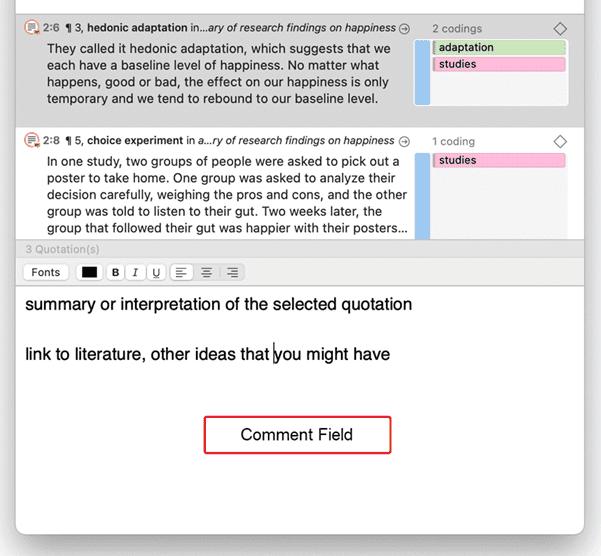
Exploración de datos de texto
Una forma rápida de hacerse una idea del contenido de los documentos de texto es creando una nube de palabras o una lista de palabras.
Las listas de palabras ofrecen capacidades de «procesamiento» de palabras para un análisis de contenido cuantitativo sencillo. Esta función crea una lista con el recuento de frecuencias de palabras y algunas métricas adicionales, como la longitud de las palabras y el porcentaje de aparición dentro de todas las entidades seleccionadas o entre ellas. Las listas de palabras se pueden exportar a Excel.
Las nubes de palabras son un método para presentar visualmente datos de texto. Son populares para el análisis de texto porque facilitan la identificación de las frecuencias de palabras. Cuanto más frecuente es una palabra, mayor y más negrita aparece. Las nubes de palabras se pueden exportar como imagen.
Las nubes de palabras y las listas de palabras se pueden crear para:
- documentos y grupos de documentos
- citas
- contenido de citas por código y grupo de códigos
Se puede utilizar una lista de exclusión/inclusión, incluyendo una lista de caracteres «ignorables», para controlar el análisis. Las palabras también se pueden eliminar temporalmente de una lista o nube sin necesidad de añadirlas a una lista de exclusión.
Para obtener más información, consulte Creación de listas y nubes de palabras.
Creación de nubes de palabras
Para crear una nube de palabras, navegue al Explorador de proyectos o al administrador de entidades correspondiente y seleccione una o más entidades (documentos, códigos o citas).
En el Explorador de proyectos, haga clic derecho y seleccione la opción Análisis > Frecuencias de palabras. En un administrador, también puede seleccionar la opción Analizar > Frecuencias de palabras en la cinta del administrador. Haga clic en el icono Nube para mostrar la nube de palabras.
Siempre es posible agregar o quitar más elementos del mismo tipo de entidad a la nube o lista una vez que se ha creado la nube de palabras.
Otras opciones para acceder a una nube de palabras incluyen:
- Cargar un documento y seleccionar la opción Analizar > Frecuencias de palabras en la cinta del editor, seguida de hacer clic en el icono Nube.
- Abrir la pestaña Buscar y codificar, luego seleccionar la opción Frecuencias de palabras en la cinta y hacer clic en el icono Nube.
Cuando selecciona crear una nube de palabras a partir de uno o varios códigos, la nube de palabras muestra las palabras de las citas codificadas con el/los código(s) seleccionado(s). Si desea que su lista de códigos se muestre en forma de nube, debe seleccionar la pestaña Vista en el Administrador de códigos y, desde allí, la opción «Nube». El tamaño de los códigos en la Nube de códigos está relacionado con su frecuencia. Consulte Trabajar con códigos.
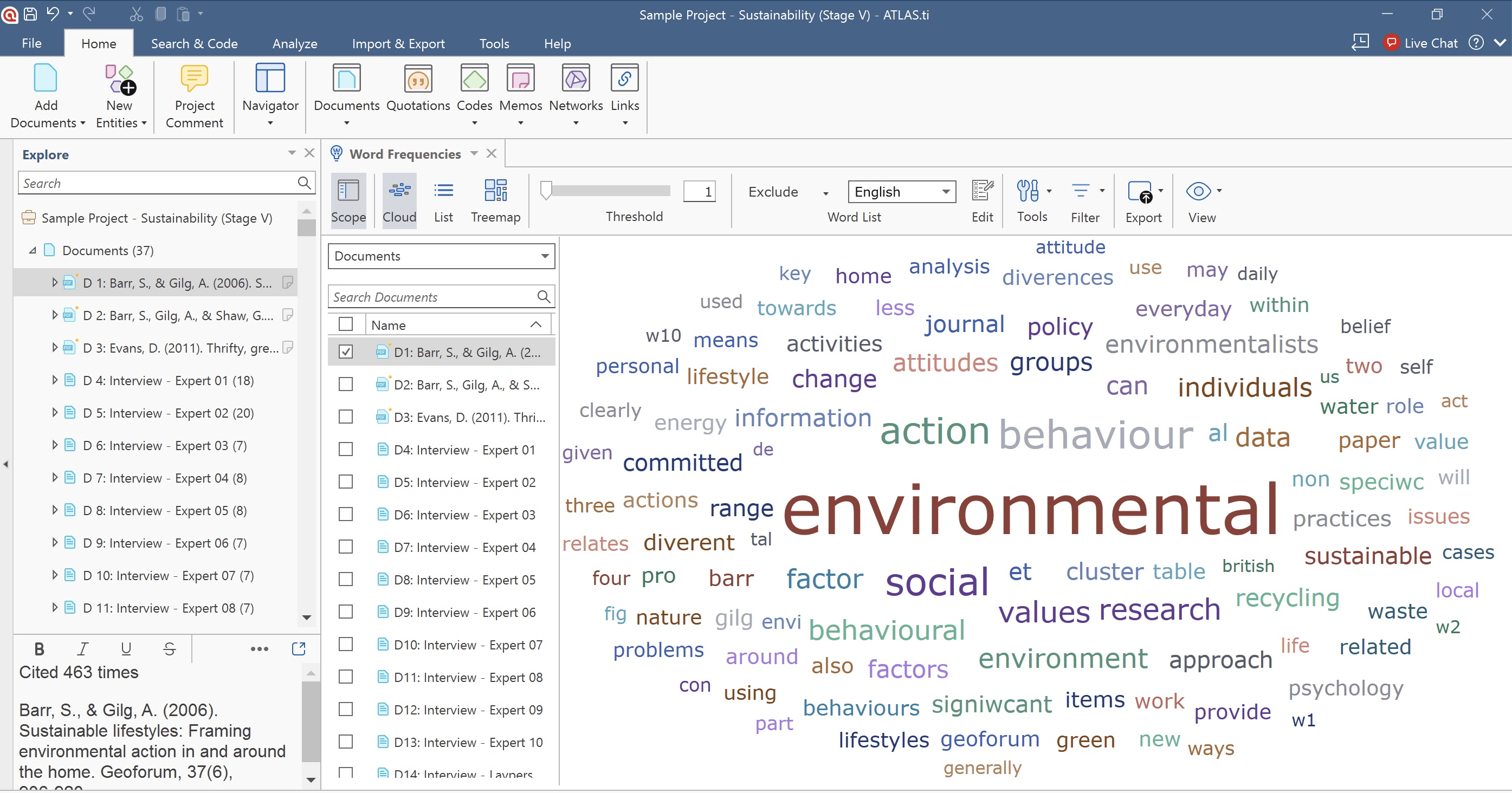
Al pasar el cursor sobre una palabra, se muestra su frecuencia (= token / número de ocurrencias de una palabra única).
Configuración del alcance
Una vez creada una nube de palabras, aparece un panel lateral a la izquierda. Las casillas de verificación de las entidades activas actualmente están marcadas. Puede marcar más entidades o desmarcar las que ya están activadas.
También puede cambiar el tipo de entidad. Las opciones son:
- documentos
- grupos de documentos
- códigos
- grupos de códigos
- citas
Otra opción de alcance es ingresar un término de búsqueda en el campo de búsqueda para buscar un documento, código o citas específicos que solo contengan determinadas palabras.
Cinta de frecuencias de palabras
La cinta de Frecuencias de palabras ofrece varias opciones:
Mostrar alcance: Permite activar o desactivar el panel lateral que permite seleccionar el alcance.
Nube/Lista/Mapa de árbol: La herramienta analizará los datos seleccionados y devolverá los resultados en forma de nube de palabras, lista de palabras o mapa de árbol.
Umbral: Al mover el deslizador de izquierda a derecha, puede determinar que solo se muestren las palabras con una determinada frecuencia. El número del lado izquierdo muestra la frecuencia de aparición más baja, el número del lado derecho muestra la más alta.
Excluir: Las palabras en las listas de exclusión son palabras que se filtran al procesar el texto. Las palabras vacías son palabras funcionales cortas que aparecen con mucha frecuencia y que no transmiten ningún significado particular. Ejemplos son «el», «la», «tú», «es», «en» y «que». ATLAS.ti ofrece listas de exclusión predefinidas en 35 idiomas. Estas listas de exclusión se basan en la información proporcionada por Ranks NL.
Herramientas: Están disponibles las siguientes opciones:
-
Ignorar mayúsculas/minúsculas: Seleccione esta opción si no desea contar las palabras por separado según si contienen letras mayúsculas o minúsculas.
-
Inferir formas base: Las formas plurales de los sustantivos, las formas de pasado, participio pasado y participio presente de los verbos, y las formas comparativas y superlativas de adjetivos y adverbios se conocen como formas flexionadas. Si activa esta opción, la nube de palabras muestra solo la forma básica de la palabra, p. ej., edificio pero no edificios.
-
Partes del discurso: Esta opción permite filtrar los datos por elementos gramaticales específicos (partes del discurso) como adjetivos, sustantivos, numerales, pronombres, etc. A continuación se muestra un ejemplo que solo muestra adjetivos:
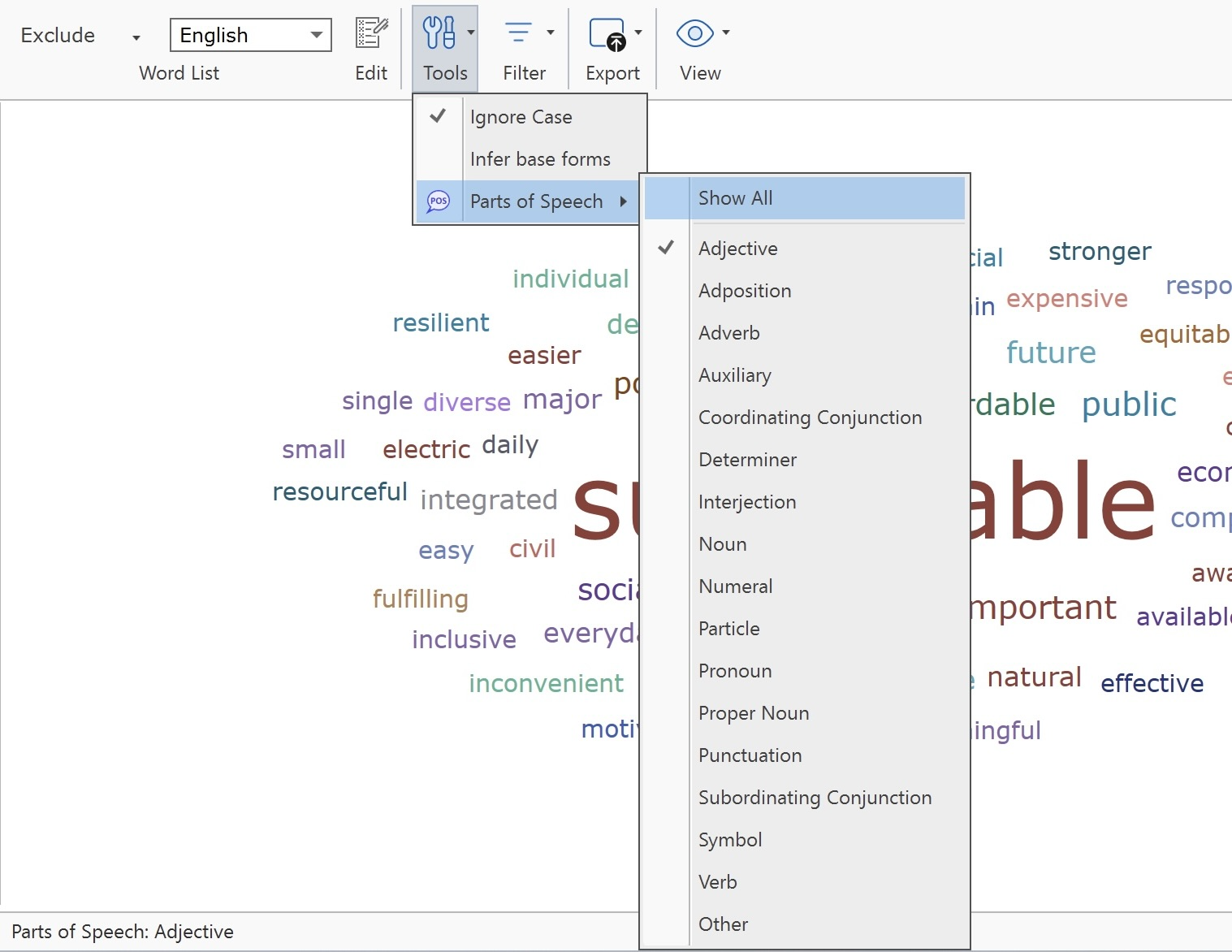
Filtro: En esta sección puede ingresar caracteres especiales que no desea que se cuenten ni se muestren en la nube de palabras.
Por defecto, se excluyen los siguientes caracteres:
|"(){}[]<>/\#+-_%$&""´`@^'„
Puede seleccionar si estos caracteres deben eliminarse en general o solo al final de las palabras. Si agrega o elimina caracteres, o desactiva la restricción a los finales de palabras, puede hacer clic en el botón Recargar. Esto actualiza la nube de palabras.
Exportar: Están disponibles las siguientes opciones:
-
Excel: Puede exportar los resultados de la lista de palabras como tabla Excel. Existen límites en cuanto a la cantidad de datos que se pueden procesar o gestionar de manera significativa y mostrar en Excel. Suponiendo que hay 2000 palabras únicas en un documento y se procesan 100 documentos, el resultado es una tabla Excel compuesta por 200.000 celdas.
-
Imagen: Puede guardar una nube de palabras como archivo gráfico (.png).
Vista: Están disponibles las siguientes opciones:
-
Mostrar detalles: Muestra el recuento de palabras de cada documento si ha seleccionado varios documentos.
-
Mostrar porcentaje: Muestra la frecuencia relativa de cada palabra (recuento de palabras en relación con el número total de palabras del documento / todos los documentos seleccionados).
-
Excluir: Puede excluir palabras de un solo carácter, números, guiones y guiones bajos.
Opciones del menú contextual
Al hacer clic derecho sobre una palabra, dispone de las siguientes opciones:
- Ocultar de la nube de palabras
- Agregar a la lista de exclusión
- Copiar al portapapeles
- Buscar en contexto
La opción Ocultar de la nube de palabras elimina temporalmente la palabra de la nube.
Si ha seleccionado una lista de exclusión (ver más abajo), puede agregar más palabras a ella. La opción aparecerá atenuada como se muestra en la imagen anterior si aún no se ha seleccionado ninguna lista de exclusión.
La opción Copiar al portapapeles es útil si desea ejecutar la herramienta de autocodificación basándose en algunas palabras de la nube de palabras. Consulte Búsqueda de texto.
La opción Buscar en contexto abre la Búsqueda de proyecto y muestra la palabra seleccionada en su contexto.
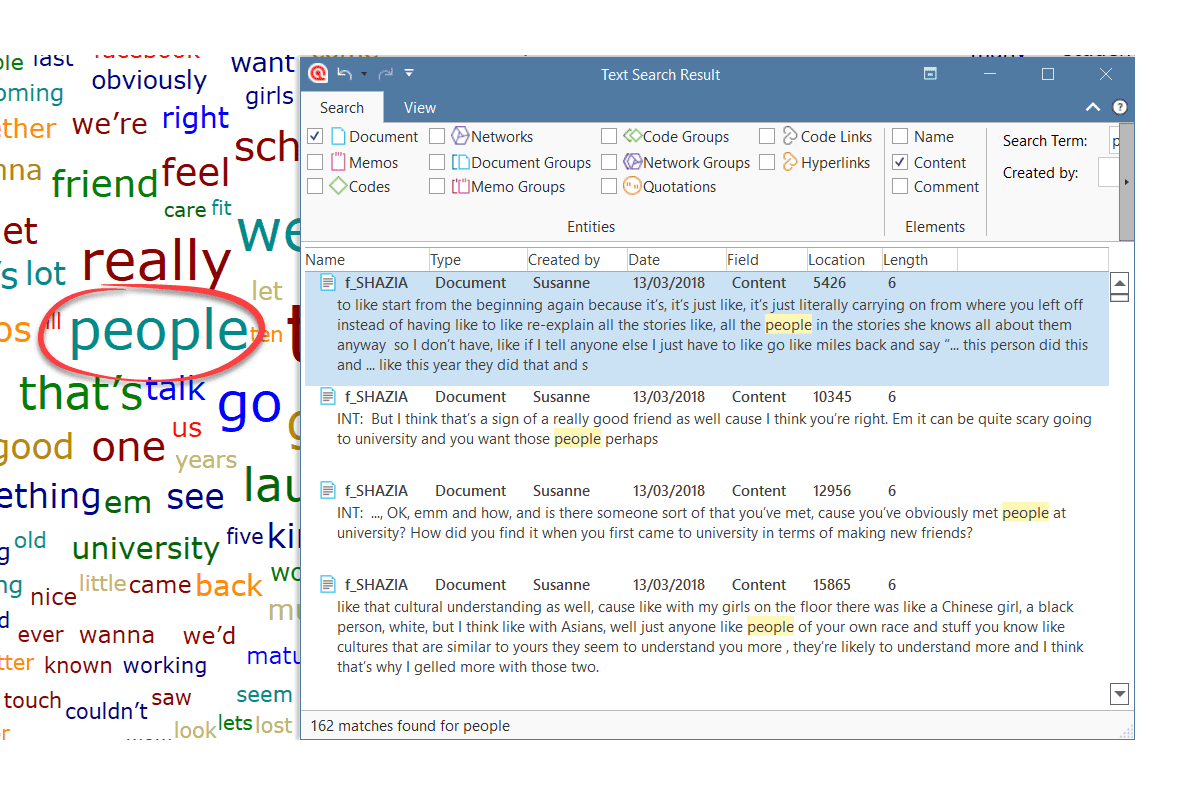
Creación de listas de palabras
Para crear una nube de palabras, navegue al Explorador de proyectos o al administrador de entidades correspondiente y seleccione una o más entidades (documentos, códigos o citas).
En el Explorador de proyectos, haga clic derecho y seleccione la opción Análisis > Frecuencias de palabras. En los administradores, también puede seleccionar la opción Analizar > Frecuencias de palabras en la cinta del administrador. Haga clic en el icono Lista para mostrar la lista de palabras.
Siempre es posible agregar o quitar más elementos del mismo tipo de entidad de la lista una vez creada (consulte Configuración del alcance más adelante).
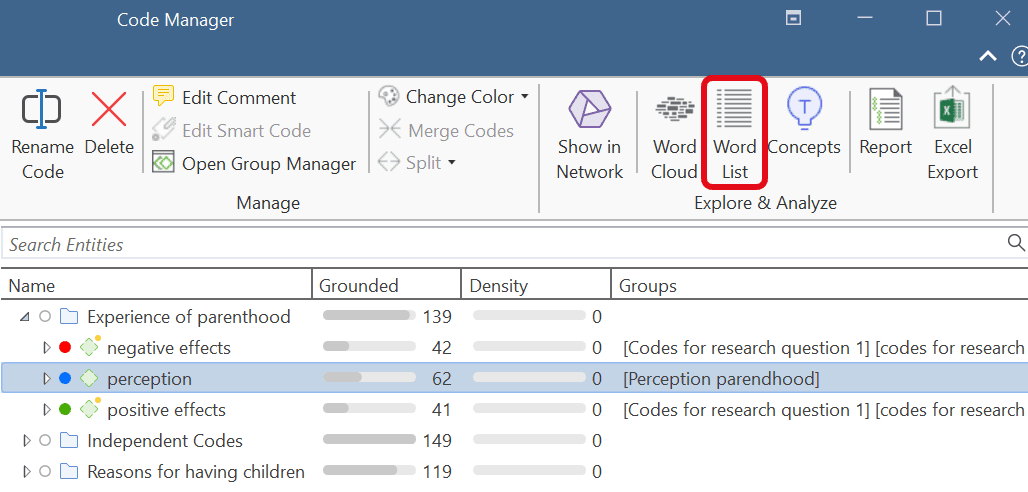
Otras opciones para acceder a una lista de palabras incluyen:
- Cargar un documento y seleccionar la opción Analizar > Frecuencias de palabras en la cinta del editor, seguida de hacer clic en el icono de Lista.
- Abrir la pestaña Buscar y codificar, luego seleccionar la opción Frecuencias de palabras en la cinta y hacer clic en el icono Lista.
Cuando selecciona crear una lista de palabras a partir de códigos, la lista de palabras muestra las palabras de las citas codificadas con el/los código(s) seleccionado(s).
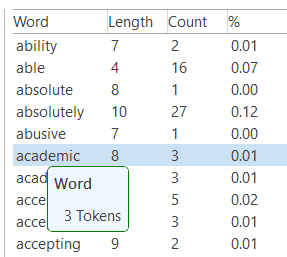
Al pasar el cursor sobre una palabra, se muestra su frecuencia (= token / número de ocurrencias de una palabra única).
Ordenar listas de palabras
Por defecto, las listas de palabras se ordenan alfabéticamente por la primera columna «Palabra». También puede ordenar por cualquiera de las otras columnas haciendo clic en el encabezado de la columna.
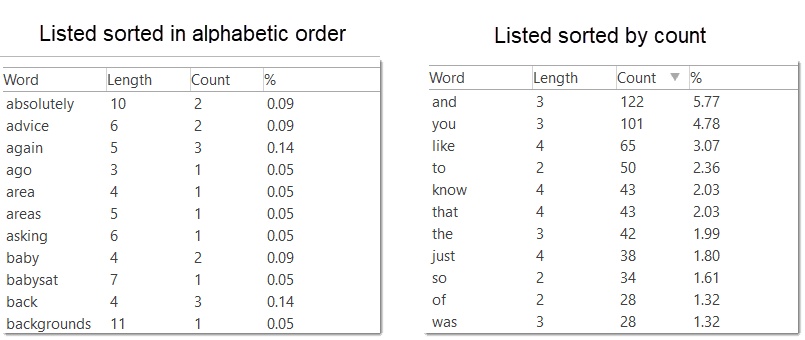
Configuración del alcance
Una vez creada una lista de palabras, aparece un panel lateral a la izquierda. Las casillas de verificación de las entidades activas actualmente están marcadas. Puede marcar más entidades o desmarcar las que ya están activadas.
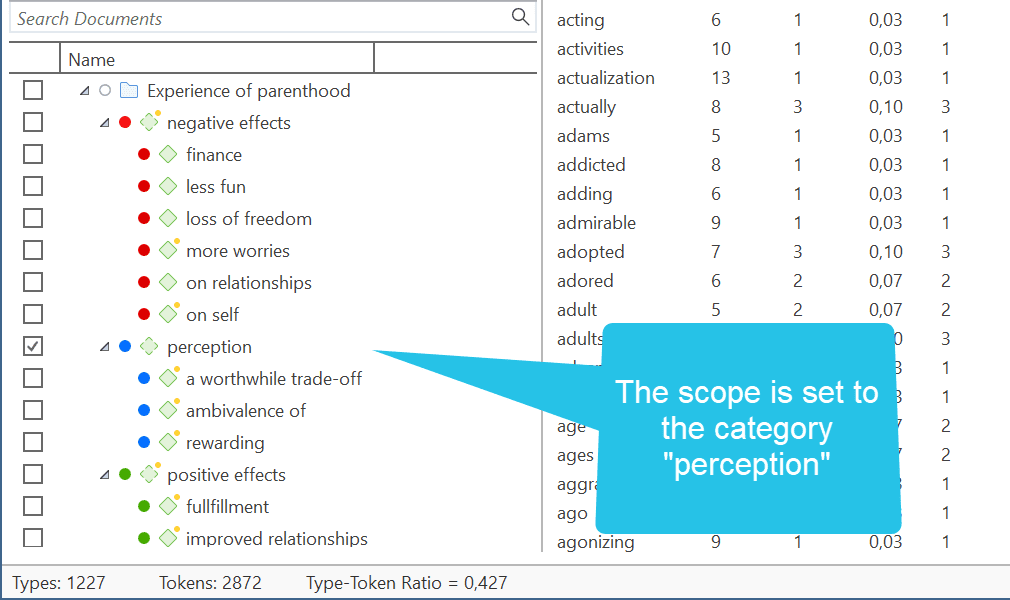
También puede cambiar el tipo de entidad. Las opciones son:
- documentos
- grupos de documentos
- códigos
- grupos de códigos
- citas
Otra opción es ingresar un término de búsqueda en el campo de búsqueda para buscar un documento, código o citas específicos que solo contengan determinadas palabras.
Cinta de frecuencias de palabras
La cinta de Frecuencias de palabras ofrece varias opciones:
Alcance: Permite activar o desactivar el panel lateral que permite seleccionar el alcance.
Nube/Lista/Mapa de árbol: La herramienta analizará los datos seleccionados y devolverá los resultados en forma de nube de palabras, lista de palabras o mapa de árbol.
Umbral: Al mover el deslizador de izquierda a derecha, puede determinar que solo se muestren las palabras con una determinada frecuencia. El número del lado izquierdo muestra la frecuencia de aparición más baja, el número del lado derecho muestra la más alta.
Excluir: Las palabras en las listas de exclusión son palabras que se filtran al procesar el texto. Las palabras vacías son palabras funcionales cortas que aparecen con mucha frecuencia y que no transmiten ningún significado particular. Ejemplos son «el», «la», «tú», «es», «en» y «que». ATLAS.ti ofrece listas de exclusión predefinidas en 35 idiomas. Estas listas de exclusión se basan en la información proporcionada por (Ranks NL).
Herramientas:
-
Ignorar mayúsculas/minúsculas: Seleccione esta opción si no desea contar las palabras por separado según si contienen letras mayúsculas o minúsculas.
-
Inferir formas base: Las formas plurales de los sustantivos, las formas de pasado, participio pasado y participio presente de los verbos, y las formas comparativas y superlativas de adjetivos y adverbios se conocen como formas flexionadas. Si activa esta opción, la nube de palabras muestra solo la forma básica de la palabra, p. ej., edificio pero no edificios.
-
Partes del discurso: Esta opción permite filtrar los datos por elementos gramaticales específicos (partes del discurso) como adjetivos, sustantivos, numerales, pronombres, etc. A continuación se muestra un ejemplo que solo muestra sustantivos:
Filtro:

Filtro de caracteres: En esta sección puede ingresar caracteres especiales que no desea que se cuenten ni se muestren en la nube de palabras. Por defecto, se excluyen los siguientes caracteres:
|"(){}[]<>/\#+-_%$&""´`@^'„
Puede seleccionar si estos caracteres deben eliminarse en general o solo al final de las palabras.
Si agrega o elimina caracteres, o desactiva la restricción a los finales de palabras, puede hacer clic en el botón Recargar. Esto actualiza la nube de palabras.
Opciones del menú contextual
Al hacer clic derecho sobre una palabra, dispone de las siguientes opciones:
- Ocultar de la lista
- Agregar a la lista de exclusión
- Agregar a la lista de inclusión
- Copiar al portapapeles
- Buscar en contexto
La opción Ocultar de la lista elimina temporalmente la palabra de la lista.
Si ha seleccionado una lista de exclusión, puede agregar más palabras a ella.
La opción Copiar al portapapeles es útil si desea ejecutar la herramienta de autocodificación basándose en algunas palabras de la lista de palabras. Consulte Búsqueda de texto.
La opción Buscar en contexto abre la Búsqueda de proyecto y muestra la palabra seleccionada en su contexto.
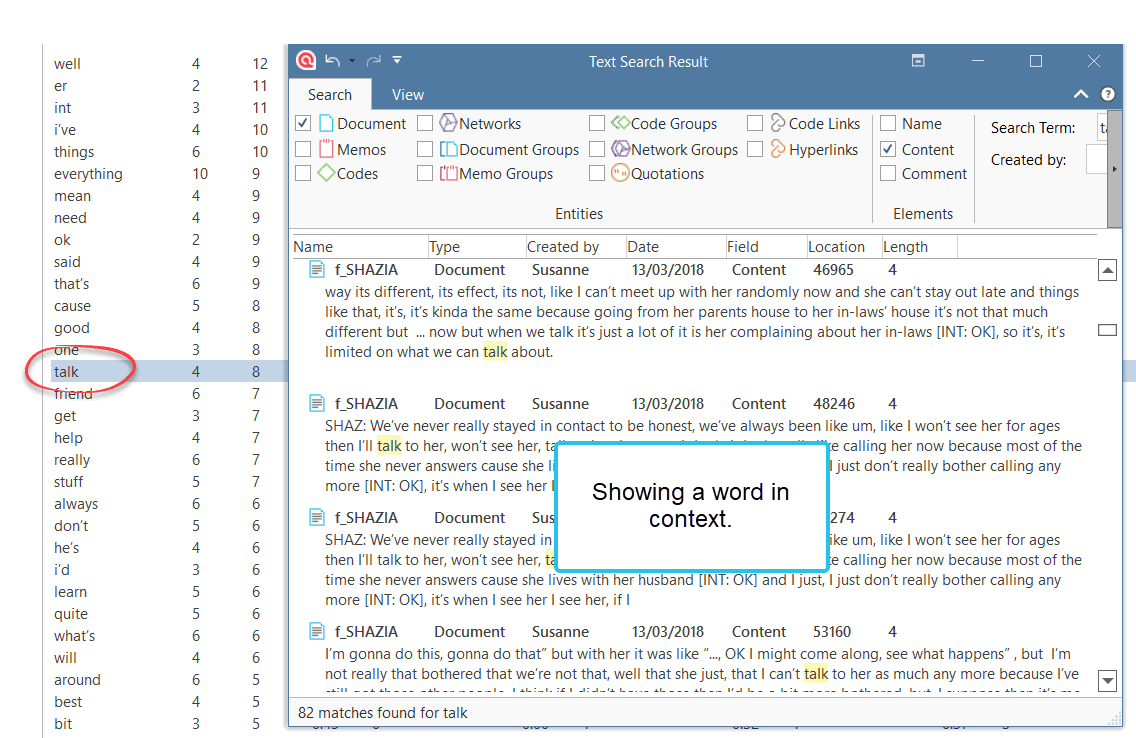
Listas de exclusión e inclusión
El trabajo con listas de exclusión e inclusión se explica en detalle aquí.
Listas de exclusión e inclusión
Las palabras en las listas de exclusión son palabras que se filtran al procesar el texto. Las palabras vacías son palabras funcionales cortas que aparecen con mucha frecuencia y que no transmiten ningún significado particular. Ejemplos son «el», «la», «tú», «es», «en» y «que». ATLAS.ti ofrece listas de exclusión predefinidas en 35 idiomas. Estas listas de exclusión se basan en la información proporcionada por Ranks NL.
Por el contrario, si establece una lista de palabras como Lista de inclusión, solo se contarán las palabras que estén en la lista.
Agregar palabras a una lista de exclusión
El primer paso es seleccionar una lista de exclusión: seleccione la opción Excluir palabras de la lista de exclusión y elija una lista en el menú desplegable. Si necesita una lista de exclusión en un idioma distinto al inglés, francés, alemán o español, haga clic en Gestionar listas y cree una nueva lista de exclusión (consulte más adelante para obtener más información).
Haga clic derecho sobre una palabra en la lista de palabras o nube de palabras y seleccione Agregar a la lista de exclusión.
Eliminar palabras de una lista de inclusión
Seleccione una Lista de inclusión. Si aún no tiene ninguna Lista de inclusión, deberá crear una primero (consulte más adelante para obtener más información).
Haga clic derecho sobre una palabra en una lista de palabras o nube de palabras y seleccione Eliminar de la lista de inclusión.
Crear una nueva lista de exclusión o inclusión
Haga clic en Gestionar listas.
En la siguiente ventana, seleccione Agregar lista.
Ingrese un nombre para la lista y seleccione el tipo de lista: Lista de exclusión o Lista de inclusión. Ingrese un comentario opcional para describir el propósito de la lista.
Para agregar palabras a la lista recién creada, haga clic en Agregar palabras varias veces. Cada vez que hace clic, se agrega un nuevo campo donde puede ingresar una palabra.
RegEx: Puede ingresar expresiones regulares si desea agregar términos específicos a la lista. En ese caso, debe marcar la casilla Regex. Opcionalmente, puede escribir un comentario que explique la expresión regular.
Opciones en el Administrador de listas de exclusión e inclusión
Importar una lista: Use esta opción si anteriormente exportó una lista de otro proyecto, o recibió una lista de otro usuario. Consulte más adelante para obtener más información sobre cómo preparar su propia lista en Excel.
Eliminar una lista: Si ya no necesita una lista, puede eliminarla del proyecto.
Duplicar una lista: Poder duplicar una lista puede ser útil si desea crear diferentes versiones para distintos propósitos.
Exportar una lista: Exportar una lista de exclusión o inclusión permite compartirla con otros usuarios o usarla en otro proyecto.
Crear una lista de exclusión o inclusión definida por el usuario en Excel
Importar una lista definida por el usuario funciona de la siguiente manera:
Exporte una lista existente y ábrala en Excel. Sirve como plantilla.
En Excel, cambie el nombre de la lista, pero deje intacta toda la información del encabezado.
Ahora elimine todas las palabras y reemplácelas con palabras nuevas, una palabra por fila.
Guarde la lista con un nombre nuevo e impórtela.
Puede convertir una lista de exclusión en una lista de inclusión (o viceversa) cambiando el Tipo de lista.
Tasa de tipos/tokens
La tasa de tipos/tokens (TTR) es la relación entre el número de palabras únicas que aparecen en un texto y sus frecuencias. El número de palabras únicas en un texto se denomina frecuentemente número de tokens. Varios de estos tokens se repiten.
- La tasa de tipos/tokens puede variar entre 0 y 1.
- Cuantos más tipos existen en comparación con el número de tokens (cuanto mayor es el valor), más variado es el vocabulario. Esto significa que hay una mayor variedad léxica en el texto.
La tasa de tipos/tokens se calcula de la siguiente manera:
Tasa de tipos/tokens = (número de tipos / número de tokens) * 100
En las listas de palabras y las nubes de palabras, la tasa de tipos/tokens se muestra en la barra de estado situada en la parte inferior.
La tasa de tipos/tokens (TTR) varía considerablemente en función de la longitud del texto — o corpus de textos — que se está estudiando. Un artículo de 1.000 palabras podría tener una TTR del 40%; uno más corto podría alcanzar el 70%; 4 millones de palabras probablemente darán una tasa de tipos/tokens de aproximadamente el 2%.
Creación de listas y nubes de palabras
Para crear una lista o nube de palabras, seleccione Análisis > Frecuencias de palabras en el menú principal.
Seleccione el tipo de entidad: Documentos, Citas, Códigos, Grupos de documentos o Grupos de códigos, y en la lista las entidades para las que desea crear una lista o nube de palabras. También puede ingresar un término de búsqueda en el campo de búsqueda para buscar un documento, código o citas específicos que solo contengan determinadas palabras.
En la parte superior derecha de la barra de herramientas encontrará los botones para alternar entre la vista de lista y de nube.
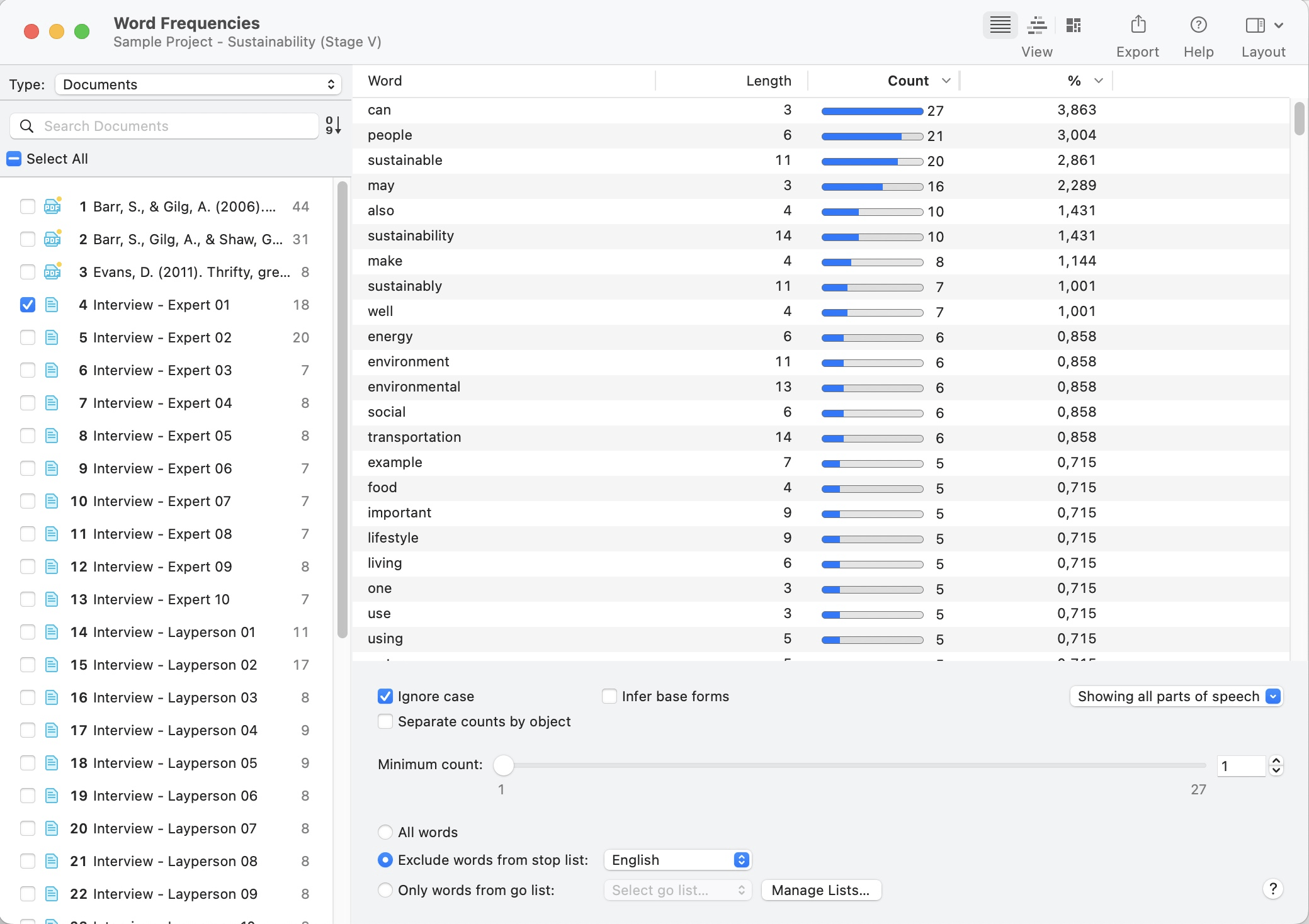
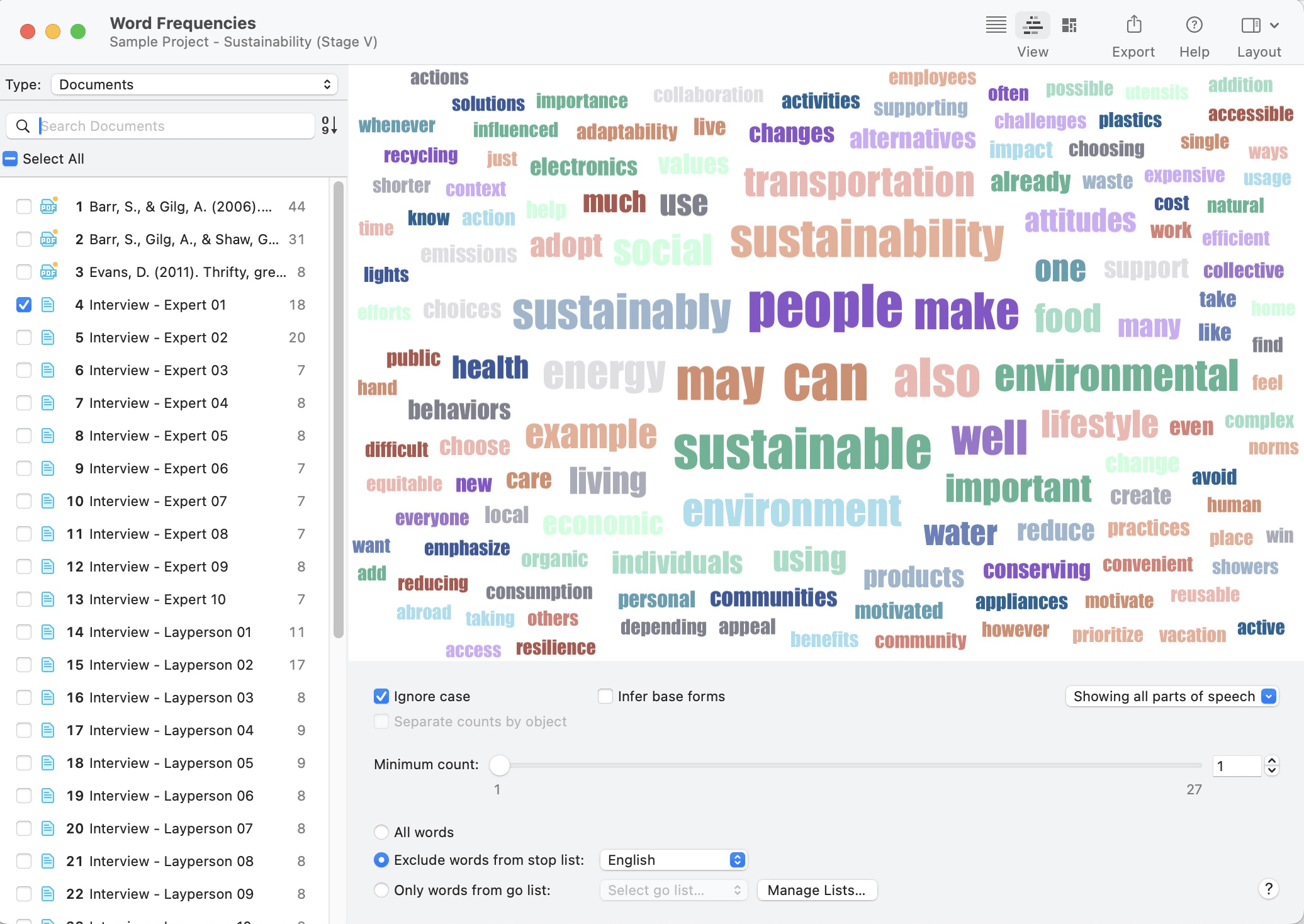
Si desea que su lista de códigos se muestre en forma de nube, debe cambiar de la Vista de lista a la vista Nube de códigos en el Administrador de códigos. Consulte Codificación de datos.
Configuración del alcance
Una vez creada una lista de palabras, aparece un panel lateral a la izquierda. Las casillas de verificación de las entidades activas actualmente están marcadas. Puede marcar más entidades o desmarcar las que ya están activadas.
También puede cambiar el tipo de entidad. Las opciones son:
- Documentos
- Citas
- Códigos
- Grupos de documentos
- Grupos de códigos
Otra opción de alcance es ingresar un término de búsqueda en el campo de búsqueda para buscar un documento, código o citas específicos que solo contengan determinadas palabras.
Opciones
Ignorar mayúsculas/minúsculas: Seleccione esta opción si no desea contar las palabras por separado según si contienen letras mayúsculas o minúsculas.
Inferir formas base: Las formas plurales de los sustantivos, las formas de pasado, participio pasado y participio presente de los verbos, y las formas comparativas y superlativas de adjetivos y adverbios se conocen como formas flexionadas. Si activa esta opción, la nube de palabras muestra solo la forma básica de la palabra, p. ej., edificio pero no edificios.
Separar recuentos por objeto: La lista de palabras proporciona el recuento total y el porcentaje de todos los objetos seleccionados. Seleccione esta opción si también desea un recuento para cada objeto seleccionado.
Partes del discurso: Esta opción permite filtrar los datos por elementos gramaticales específicos (partes del discurso) como adjetivos, sustantivos, numerales, pronombres, etc. A continuación se muestra un ejemplo que solo muestra adjetivos:
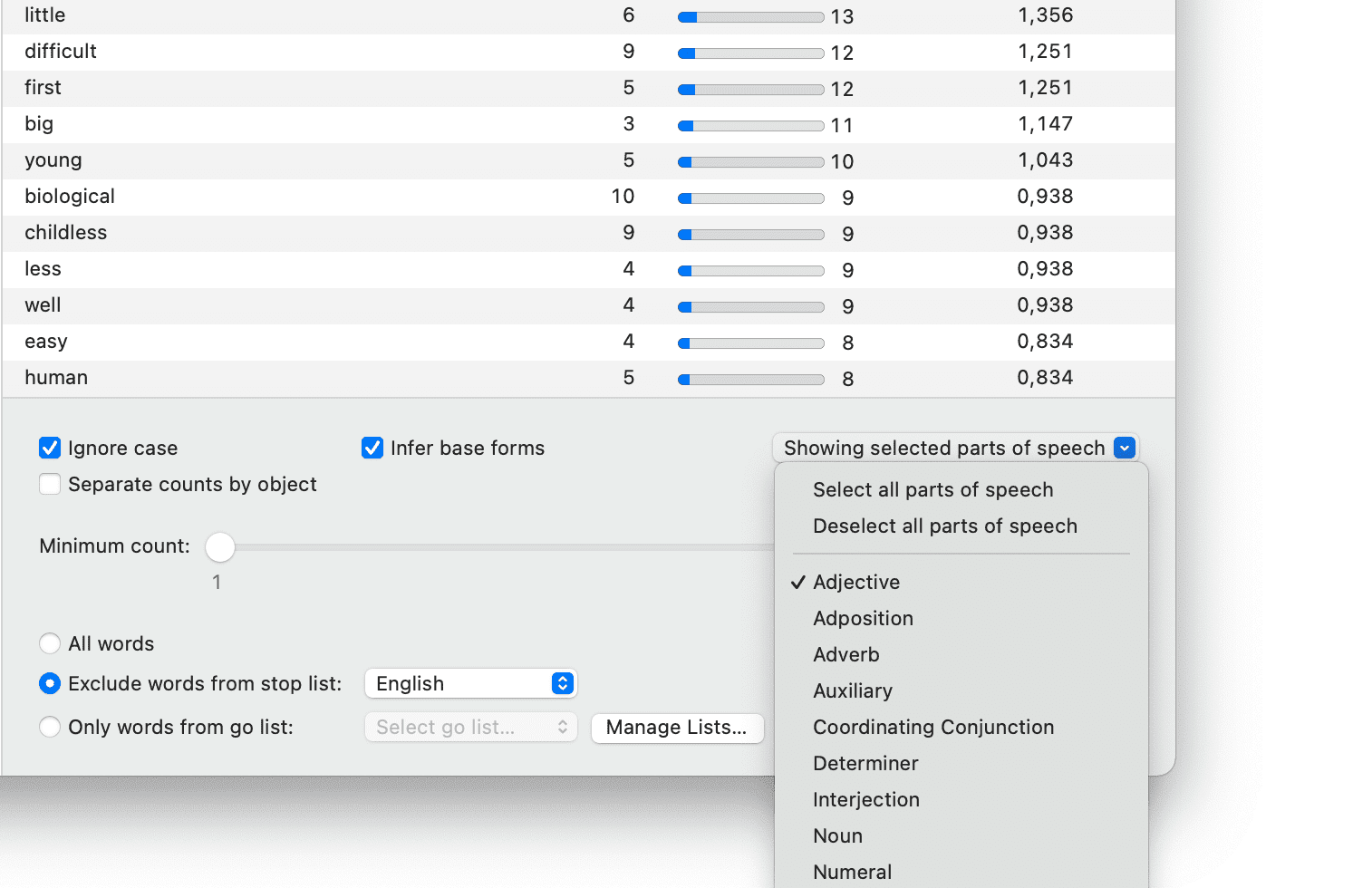
Buscar una palabra en contexto
Haga doble clic en una palabra de la nube de palabras o la lista de palabras para encontrar todas las secciones donde aparece la palabra en el contexto de los datos. Los resultados se mostrarán en la sección de Búsqueda del Navegador de proyectos.
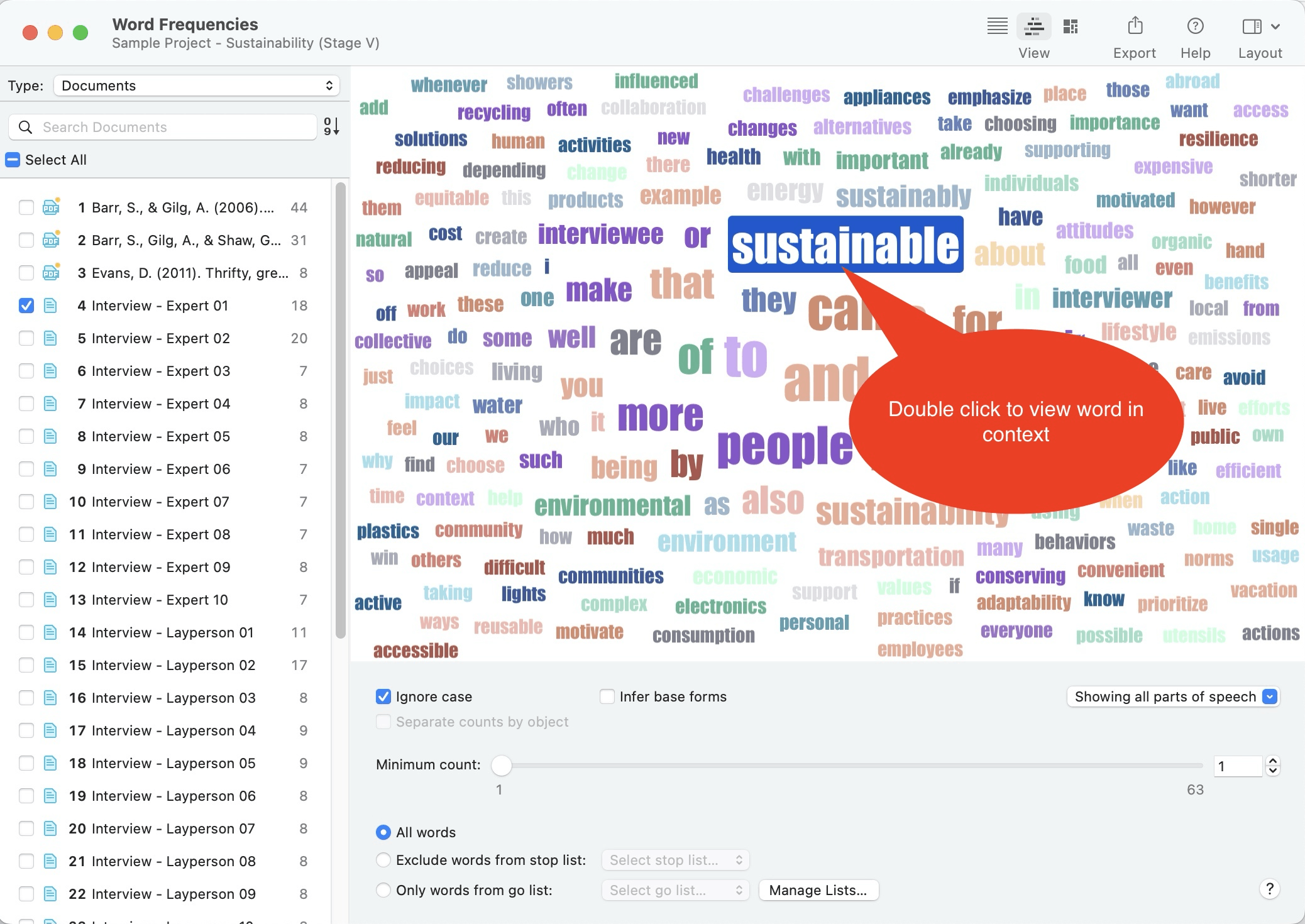
Opciones del menú contextual
Al hacer clic derecho sobre una palabra, dispone de las siguientes opciones:
- Copiar
- Agregar a la lista de exclusión
- Eliminar de la lista de inclusión
- Buscar (en contexto)
La opción Copiar es útil si desea ejecutar la herramienta de autocodificación basándose en algunas palabras de la nube de palabras. Consulte Búsqueda de texto.
La opción Buscar abre la Búsqueda de proyecto y muestra la palabra seleccionada en su contexto.
Exportar la lista de palabras a Excel
Haga clic en el icono de exportación en la barra de herramientas. Ingrese un nombre de archivo y seleccione una ubicación donde desea guardar el archivo. También puede elegir abrir el archivo inmediatamente en Excel. Haga clic en Guardar.
Guardar la nube de palabras como imagen
Las nubes de palabras se pueden guardar como archivo de imagen en formato png. Ingrese un nombre de archivo y seleccione una ubicación donde desea guardarlo. Haga clic en Guardar.
IA conversacional
La IA conversacional le permite mantener conversaciones en lenguaje natural sobre sus documentos. Aunque tiene una interfaz de usuario engañosamente sencilla, es una herramienta muy potente que puede ayudarle a responder preguntas y obtener perspectivas sobre uno o varios documentos a la vez.
A diferencia de los chatbots de IA de uso general, la IA conversacional de ATLAS.ti devuelve las citas en las que se basan sus respuestas, con acceso sencillo para leerlas y codificarlas para su recuperación posterior o análisis adicional. No hay límite funcional para la longitud de los documentos.
Tenga en cuenta que la IA conversacional de ATLAS.ti es una función en versión beta. Puede utilizarla libremente y agradecemos sus comentarios sobre todos sus aspectos.
Puede acceder a la IA conversacional a través del menú Análisis, el botón Documentos en la barra de herramientas principal, o en la sección Análisis de los menús contextuales del documento o del grupo de documentos.
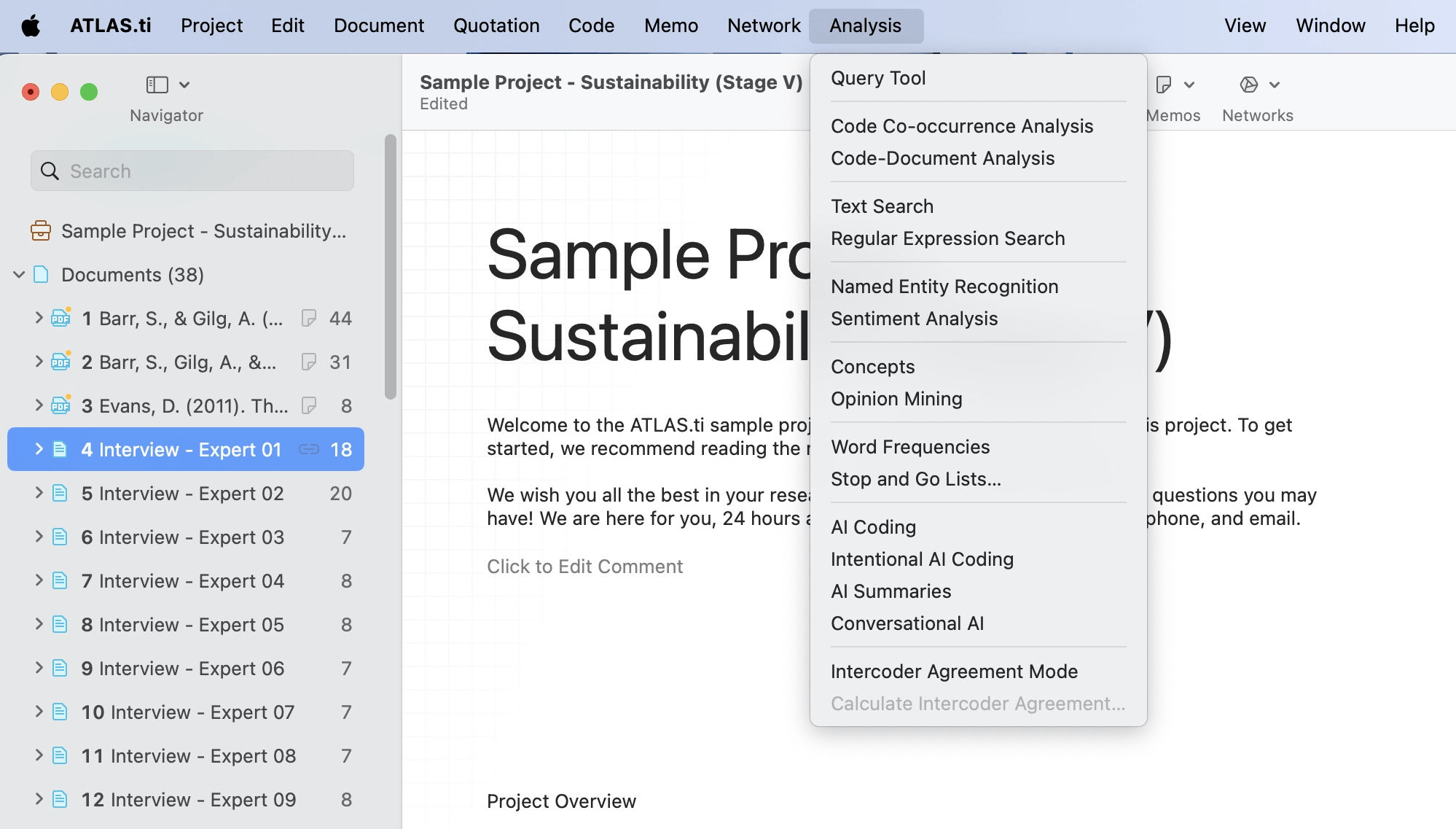

Después de seleccionar el documento o los documentos que necesita analizar, la IA conversacional muestra una ventana donde podrá "chatear" con sus documentos.
Al hacer clic en los vínculos de referencia se abrirá el segmento en cuestión para que pueda leerlo fácilmente en contexto y codificarlo. También puede codificar múltiples referencias a la vez haciendo clic en "Codificar todas las referencias". Esto añadirá su codificación a todas las referencias inmediatamente anteriores al vínculo, lo que le permitirá codificar rápidamente cada tema identificado.
Debajo de cada respuesta encontrará botones para crear un memo con el par pregunta/respuesta o copiarlo para usarlo en otro lugar. También puede hacer lo mismo con toda la conversación usando los botones en la esquina superior derecha de la ventana de conversación.
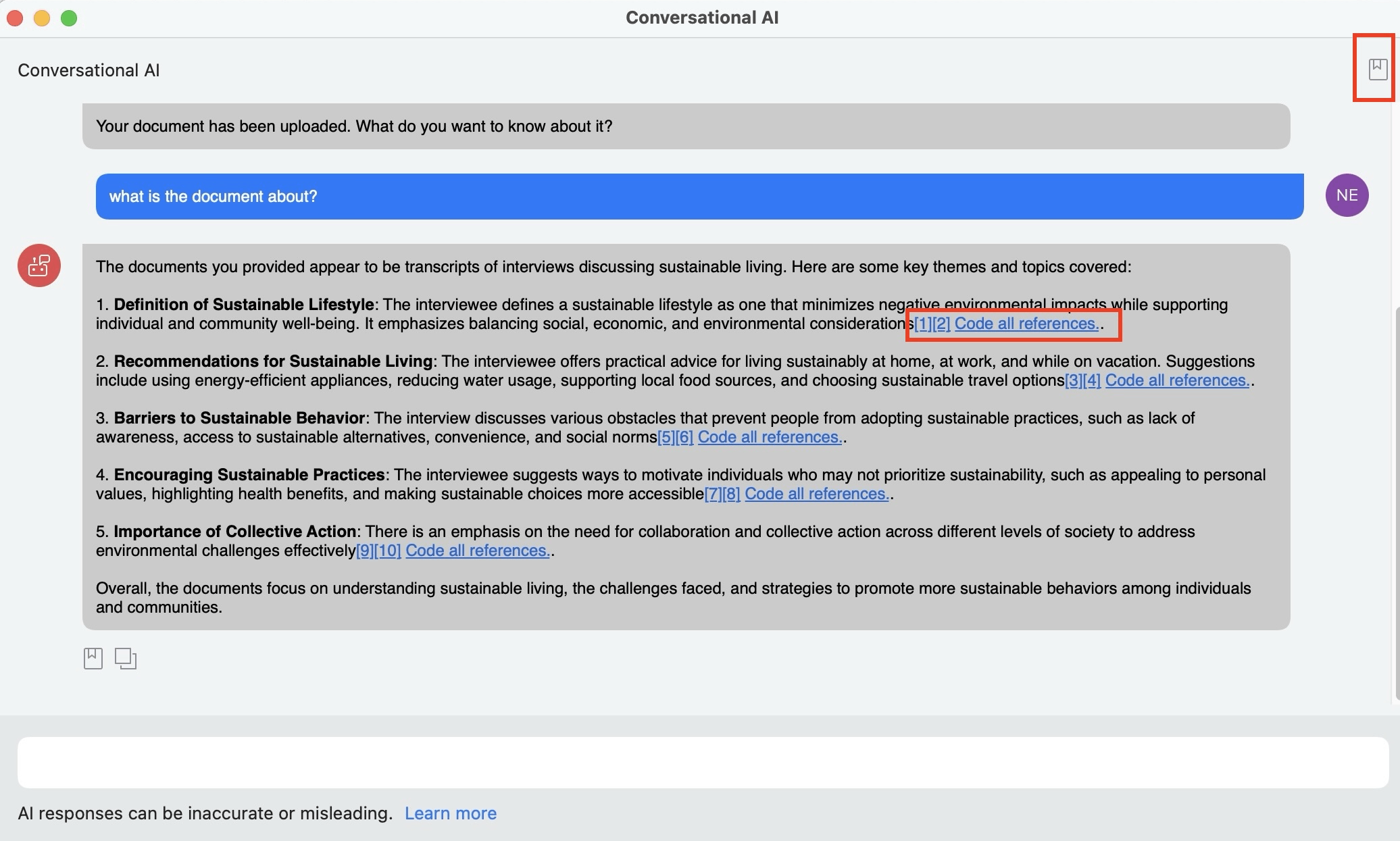
La IA conversacional recuerda su conversación actual y conoce el contenido de los documentos que agrega, pero no tiene contexto sobre estos documentos, como el número de documento, el nombre, la pertenencia a grupos o la codificación existente. Para aprovechar al máximo la IA conversacional, inicie el chat con documentos que pertenezcan al mismo conjunto. Si desea que metadatos como la edad del entrevistado estén disponibles para la IA, agréguelos a los documentos antes de iniciar la conversación.
No dude en pedir aclaraciones, reformular sus preguntas o clarificar sus instrucciones a la IA. Al igual que los humanos, las IA se vuelven "perezosas" al leer grandes cantidades de texto, por lo que puede pedirle que se concentre en aspectos específicos o incluso reprenderla un poco. Tenga cuidado de no poner palabras en boca de la IA y revise las referencias que le proporcione. Lo más importante de todo: ¡diviértase y experimente!
La IA conversacional cargará sus preguntas y el contenido seleccionado de los documentos en los servidores de ATLAS.ti y OpenAI. Nunca cargaremos sus datos sin su consentimiento explícito. Si desea continuar, active la casilla de verificación donde reconoce que acepta nuestro EULA y nuestra Política de privacidad. OpenAI no utilizará los datos de los usuarios de ATLAS.ti para entrenar los modelos de OpenAI.
La IA conversacional actualmente solo está disponible en servidores de EE. UU. Está disponible para nuestros usuarios de todo el mundo, pero siempre utilizará servidores de EE. UU., independientemente de su configuración de región de IA.
Codificar datos automáticamente
Con los recientes avances en el aprendizaje profundo, la capacidad de los algoritmos para analizar texto ha mejorado considerablemente. El uso creativo de técnicas avanzadas de inteligencia artificial puede ser una herramienta eficaz para realizar investigaciones en profundidad.
En el menú Análisis, ATLAS.ti ofrece varias formas de buscar información relevante en sus datos que luego pueden codificarse automáticamente.
- Búsqueda de texto
- Búsqueda por expresiones regulares
- Reconocimiento de entidades nombradas
- Análisis de sentimientos
- Conceptos
- Minería de opiniones
- Codificación de IA
- Codificación de IA intencional
Si introduce un término para una búsqueda de texto, puede seleccionar palabras similares de una lista de sinónimos. Los sinónimos están disponibles en inglés, alemán, español, portugués, francés, neerlandés, ruso y chino simplificado.
Los modelos de lenguaje para los idiomas mencionados también están disponibles para el reconocimiento de entidades nombradas, el análisis de sentimientos y la búsqueda de conceptos.
Como ATLAS.ti es una herramienta para el análisis de datos cualitativos, el proceso no está completamente automatizado. Antes de codificar los datos, puede revisar todos los resultados, realizar modificaciones o decidir no codificar determinados hallazgos.
Las técnicas de inteligencia artificial se han desarrollado para el análisis de grandes volúmenes de datos. Los corpus de datos que habitualmente maneja ATLAS.ti son considerablemente más pequeños. Por lo tanto, no puede esperarse que todos los resultados sean perfectos. Revisar los resultados será un componente necesario del proceso de análisis al utilizar estas herramientas. Al trabajar con las herramientas, comprobará que añaden un nivel adicional a su análisis. Encontrará cosas que simplemente no vería al codificar los datos manualmente, o que no habría considerado codificar. En ATLAS.ti consideramos que la codificación manual y la automática son complementarias; cada una potencia su análisis de una manera única.
Codificación de IA
ATLAS.ti se enorgullece de ofrecer la primera de muchas funciones verdaderamente automatizadas, impulsadas por los modelos GPT de OpenAI, líderes a nivel mundial.
La codificación de IA le ayuda a usted, el investigador, "leyendo" sus documentos y realizando una codificación inductiva completamente automatizada. Por supuesto, puede revisar y perfeccionar los códigos generados para adaptarlos a su investigación, pero puede ahorrarle un tiempo valioso al procesar sus datos y realizar la tarea mecánica de la codificación inicial. El tiempo ahorrado puede utilizarse para refinar y fusionar códigos, realizar análisis y producir visualizaciones al presentar su investigación.
Tenga en cuenta que la codificación de IA es una función en versión beta. Puede utilizarla libremente y agradecemos sus comentarios sobre todos sus aspectos.
Puede acceder a la codificación de IA a través del menú Análisis, el botón Documentos en la barra de herramientas principal, o en la sección Análisis de los menús contextuales del documento o del grupo de documentos.
Descripción general rápida
Comience seleccionando los documentos o grupos de documentos que desea que ATLAS.ti codifique. Después de hacer clic en "Iniciar codificación", ATLAS.ti le preguntará si desea continuar y le mostrará una estimación aproximada del tiempo que tardará en procesar sus datos.
La codificación de IA cargará el contenido de su documento en los servidores de ATLAS.ti y OpenAI. Nunca cargaremos sus datos sin su consentimiento explícito. Si desea continuar, active la casilla de verificación donde reconoce que acepta nuestro EULA y nuestra Política de privacidad. OpenAI NO utilizará los datos de los usuarios de ATLAS.ti para entrenar los modelos de OpenAI.
Puede continuar trabajando mientras se ejecuta la codificación de IA.
Una vez finalizada la codificación de IA, ATLAS.ti le presentará un resumen de los resultados. Aquí puede cambiar el número de categorías que desea arrastrando el control deslizante o ingresando un número en la parte inferior izquierda. Esto no cambiará los códigos que obtenga de la codificación de IA, sino que los agrupará de manera diferente. Esto puede ser útil si la agrupación predeterminada es demasiado amplia o demasiado detallada para usted.
Es posible que el algoritmo de agrupación no siempre devuelva el número exacto de clústeres solicitado.
Puede alternar entre una lista y una visualización de gráfico de fuerza dirigida de los clústeres de códigos. Haga clic en un código o categoría para ver las citas que codificarán.
Cuando esté satisfecho, haga clic en "Aplicar" y ATLAS.ti aplicará la codificación y le mostrará un resumen.
Puede cerrar esta ventana ahora; la codificación está lista.
Todos los códigos generados por la codificación de IA formarán parte del grupo de códigos "Códigos de IA".
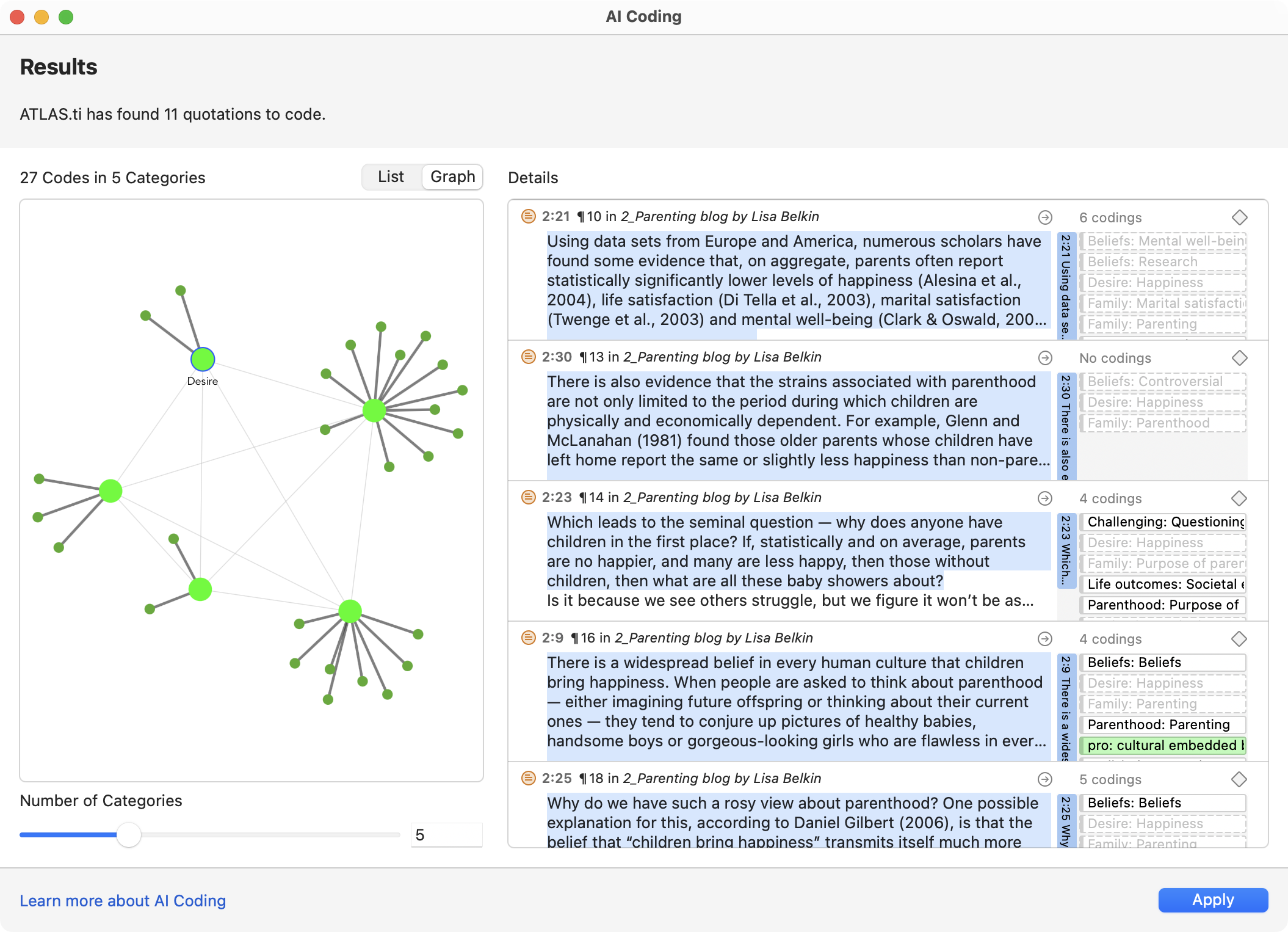
Cómo aprovechar al máximo la codificación de IA
Es mejor enviar documentos que pertenezcan temáticamente al mismo grupo en la misma ronda de codificación de IA. Esto mejorará la calidad de la codificación y permitirá que ATLAS.ti ignore los patrones repetitivos entre documentos, como las preguntas de entrevistas.
La codificación de IA funciona por párrafos. Para obtener los mejores resultados, las preguntas de entrevistas o los nombres de los participantes en las transcripciones deben estar en su propio párrafo, y la estructura de párrafos de un documento debe estar bien definida. Al editar su documento, utilice los números del margen izquierdo para determinar la separación entre párrafos.
Los documentos PDF no contienen párrafos, aunque lo parezca, por lo que los resultados de los documentos PDF probablemente serán deficientes.
La codificación de IA omite los párrafos muy cortos.
La codificación de IA solo analiza el texto sin formato de sus documentos. Los códigos, citas y formatos existentes no tienen ningún efecto en sus resultados.
Codificación de IA en profundidad
La codificación de IA funciona con la familia de modelos de lenguaje de gran escala GPT. Estos modelos se basan en grandes cantidades de textos diversos y en entrenamiento adicional por parte de investigadores humanos, lo que les permite utilizarse de manera general.
En ATLAS.ti ofrecemos acceso sencillo a estos potentes modelos con nuestra función de codificación de IA, sin necesidad de comprender y gestionar los detalles técnicos y las limitaciones. ATLAS.ti divide automáticamente su texto en fragmentos que son procesados por la IA y los pasa a los modelos GPT para un análisis repetido. Los resultados del análisis se combinan algorítmicamente para ofrecer la mejor combinación de códigos que cubran diferentes temas sin producir una cantidad abrumadora de códigos.
A continuación se presenta una visión detallada de estos pasos:
Los modelos de lenguaje de gran escala son sensibles al texto circundante, ya que tienen una ventana de atención, también llamada contexto. Elegir el contexto adecuado es clave al trabajar con un modelo de lenguaje de gran escala. Un contexto corto puede significar que no se procesa mucha información, porque algunas palabras o incluso oraciones solo tienen sentido en un contexto más amplio. Elegir un contexto demasiado grande satura el modelo con información y dificulta que los algoritmos de extracción de códigos encuentren códigos significativos. ATLAS.ti elige contextos de no menos de 100 caracteres de longitud, pero realiza cortes en los límites naturales de los párrafos. Hemos comprobado que estas restricciones tienen un impacto positivo en la calidad de la codificación, al mismo tiempo que excluyen la mayoría de los encabezados y títulos que son de menor importancia para los investigadores cualitativos. Como paso adicional para reducir el ruido en los datos analizados, ATLAS.ti elimina del análisis los párrafos que aparecen más de una vez, ya que es probable que sean frases recurrentes de entrevistas o nombres de hablantes.
En el primer paso del análisis, se encomienda a los modelos de IA que encuentren codificaciones significativas para cada segmento de datos, actuando como si el modelo fuera un asistente de investigación cualitativa. Como los modelos de la familia GPT son bastante creativos, la codificación de IA puede producir codificaciones similares, mientras que otras abordan el mismo tema pero se expresan de maneras diferentes. Este procedimiento puede producir cientos de códigos distintos que no son manejables de manera eficiente.
Para abordar esto, utilizamos una característica de los modelos de lenguaje llamada embeddings (representaciones vectoriales), donde cada palabra o frase puede asociarse con un punto en un espacio multidimensional. Una de las propiedades útiles de esta característica es que las palabras y frases más similares entre sí se ubican más cerca unas de otras que las palabras o frases menos similares. Aprovechando esta propiedad, ATLAS.ti agrupa los códigos combinando los más cercanos entre sí en una colección. Esta agrupación se repite hasta alcanzar un número satisfactorio de colecciones.
Los códigos combinados se asocian con los segmentos generados y se proponen en la interfaz de ATLAS.ti para la visualización de citas.
Tenga en cuenta que, aunque en general es beneficioso que los modelos GPT hayan sido entrenados con grandes cantidades de texto, en algunas situaciones esto puede dar lugar a resultados incorrectos que no reflejan con precisión a personas, lugares o hechos reales. En algunos casos, los modelos GPT pueden incorporar sesgos sociales como estereotipos o sentimientos negativos hacia ciertos grupos. Debe evaluar la precisión de cualquier resultado según corresponda a su caso de uso.
Codificación de IA intencional
Con esta nueva herramienta de codificación basada en IA, le ofrecemos más control, más transparencia y mejores resultados. Simplemente introduzca sus objetivos de investigación y deje que ATLAS.ti codifique sus documentos con las respuestas que necesita.
La codificación de IA intencional es una versión mejorada de nuestra innovadora herramienta de codificación de IA, que ofrece mejores resultados adaptados a sus preguntas de investigación, mayor transparencia e incluso puede ayudarle a encontrar preguntas pertinentes. Al igual que con la codificación de IA, puede revisar y perfeccionar los códigos generados para adaptarlos a su investigación, dejándole a usted, el investigador, en control.
Tenga en cuenta que la codificación de IA intencional es una función en versión beta. Puede utilizarla libremente y agradecemos sus comentarios sobre todos sus aspectos.
Puede acceder a la codificación de IA intencional a través del menú Análisis, el botón Documentos en la barra de herramientas principal, o en la sección Análisis de los menús contextuales del documento o del grupo de documentos.
Descripción general rápida
- El primer paso es seleccionar los documentos o grupos de documentos que desea que ATLAS.ti codifique. Si invocó la codificación de IA intencional sobre un documento o un conjunto de documentos, este paso se omite.
- A continuación, ATLAS.ti le solicita su intención. Escriba aquí su(s) pregunta(s) de investigación o hipótesis. No dude en agregar algo de contexto, ya que esto ayudará a la IA a comprender los datos.
- En el siguiente paso, ATLAS.ti generará preguntas concretas a partir de su intención, junto con nombres de categorías de códigos pertinentes. Aquí puede revisar y editar las preguntas y los nombres de las categorías de códigos, deshabilitar las preguntas que no le interesen e incluso añadir las suyas propias.
- Después de hacer clic en "Iniciar codificación", ATLAS.ti revisará sus documentos y recopilará sugerencias de codificación. Esto puede tardar algunos minutos. Puede continuar trabajando en ATLAS.ti mientras se ejecuta este proceso, pero tenga cuidado de no editar los documentos que estén bajo análisis de IA, ya que eso haría que los resultados no fueran aplicables.
- Cuando esté satisfecho, haga clic en "Aplicar" y ATLAS.ti aplicará la codificación y le mostrará un resumen. Puede cerrar esta ventana ahora; la codificación está lista.
La codificación de IA intencional cargará su intención, sus preguntas, los nombres de categorías de códigos elegidos y el contenido de sus documentos en los servidores de ATLAS.ti y OpenAI. Nunca cargaremos sus datos sin su consentimiento explícito. Si desea continuar, active la casilla de verificación donde reconoce que acepta nuestro EULA y nuestra Política de privacidad. OpenAI NO utilizará los datos de los usuarios de ATLAS.ti para entrenar los modelos de OpenAI.
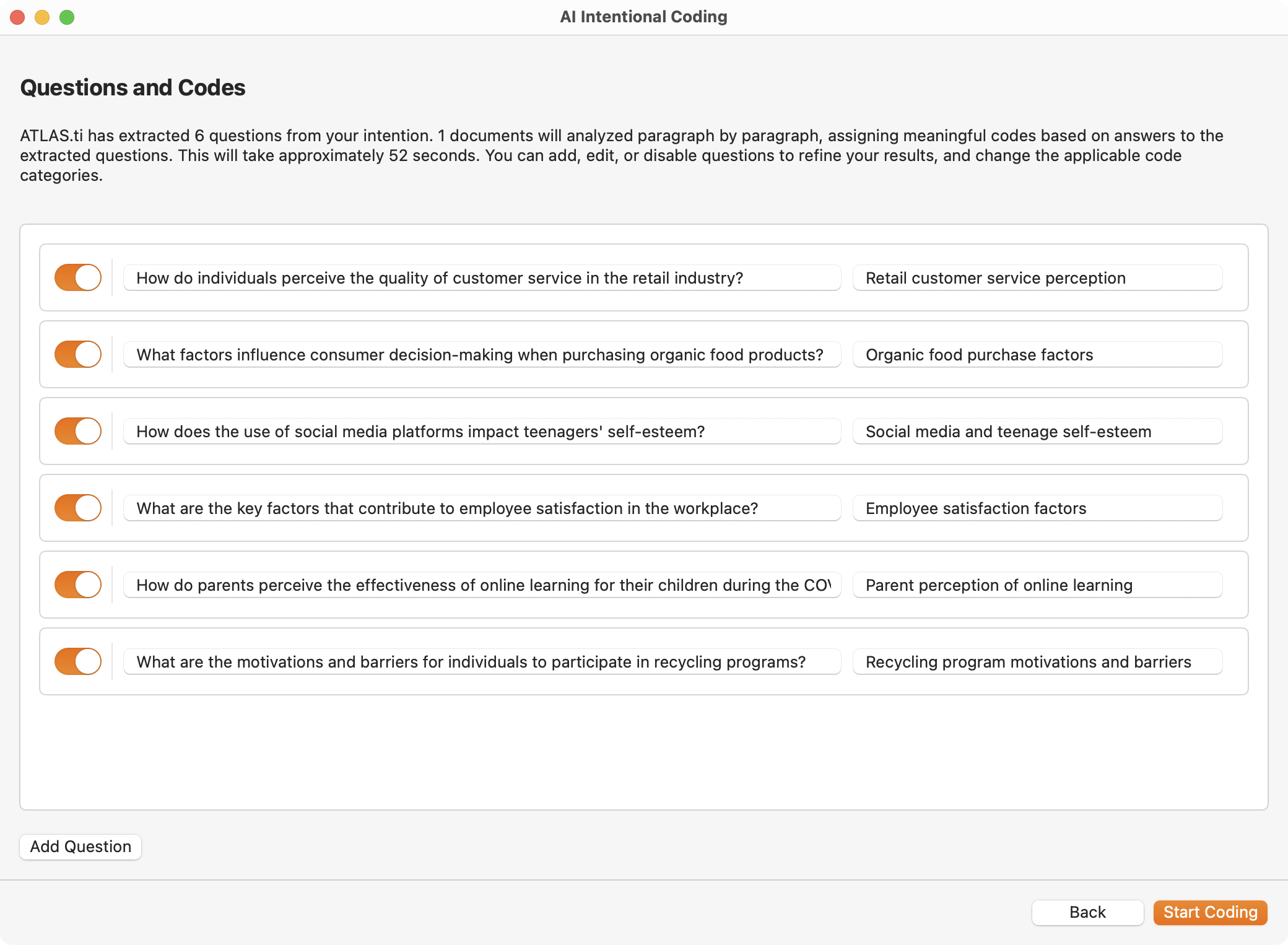
Cómo aprovechar al máximo la codificación de IA intencional
Es mejor enviar documentos que pertenezcan temáticamente al mismo grupo en la misma ronda de codificación de IA intencional. Esto mejorará la calidad de la codificación y permitirá que ATLAS.ti ignore los patrones repetitivos entre documentos, como las preguntas de entrevistas.
La codificación de IA intencional funciona por párrafos. Para obtener los mejores resultados, las preguntas de entrevistas o los nombres de los participantes en las transcripciones deben estar en su propio párrafo, y la estructura de párrafos de un documento debe estar bien definida. Al editar su documento, utilice los números del margen izquierdo para determinar la separación entre párrafos.
Los documentos PDF no contienen párrafos, aunque lo parezca, por lo que los resultados de los documentos PDF probablemente serán deficientes.
La codificación de IA intencional omite los párrafos muy cortos.
La codificación de IA intencional solo analiza el texto sin formato de sus documentos. Los códigos, citas, imágenes y formatos existentes no tienen ningún efecto en sus resultados.
Codificación de IA en profundidad
La codificación de IA intencional funciona con la familia de modelos de lenguaje de gran escala GPT. Estos modelos se basan en grandes cantidades de textos diversos y en entrenamiento adicional por parte de investigadores humanos, lo que les permite utilizarse de manera general.
En ATLAS.ti ofrecemos acceso sencillo a estos potentes modelos con nuestra función de codificación de IA, sin necesidad de comprender y gestionar los detalles técnicos y las limitaciones. ATLAS.ti divide automáticamente su texto en fragmentos que son procesados por la IA y los pasa a los modelos GPT para un análisis repetido. Los resultados del análisis se combinan algorítmicamente para ofrecer la mejor combinación de códigos que cubran diferentes temas sin producir una cantidad abrumadora de códigos.
A continuación se presenta una visión detallada de estos pasos:
En el primer paso, la IA analiza la intención proporcionada, identifica preguntas y determina un nombre de categoría de código basado en cada pregunta. El usuario puede revisar y editar tanto las preguntas como las categorías de códigos.
A continuación, se segmentan los documentos. Los modelos de lenguaje de gran escala son sensibles al texto circundante, ya que tienen una ventana de atención, también llamada contexto. Elegir el contexto adecuado es clave al trabajar con un modelo de lenguaje de gran escala. Un contexto corto puede significar que no se procesa mucha información, porque algunas palabras o incluso oraciones solo tienen sentido en un contexto más amplio. Elegir un contexto demasiado grande satura el modelo con información y dificulta que los algoritmos de extracción de códigos encuentren códigos significativos. ATLAS.ti elige contextos de no menos de 100 caracteres de longitud, pero realiza cortes en los límites naturales de los párrafos. Hemos comprobado que estas restricciones tienen un impacto positivo en la calidad de la codificación, al mismo tiempo que excluyen la mayoría de los encabezados y títulos que son de menor importancia para los investigadores cualitativos. Como paso adicional para reducir el ruido en los datos analizados, ATLAS.ti elimina del análisis los párrafos que aparecen más de una vez, ya que es probable que sean frases recurrentes de entrevistas o nombres de hablantes.
Los documentos se analizan entonces segmento por segmento. En la práctica, esto significa con mayor frecuencia párrafo por párrafo. Cada pregunta se aplica a cada segmento. Si se aplica y genera una respuesta coherente, esa respuesta se condensa en un código, y el código se aplica como codificación propuesta al segmento. El código se agrupa bajo la categoría de código de la pregunta.
ATLAS.ti presenta todas las codificaciones propuestas al usuario antes de aplicarlas.
Tenga en cuenta que, aunque en general es beneficioso que los modelos GPT hayan sido entrenados con grandes cantidades de texto, en algunas situaciones esto puede dar lugar a resultados incorrectos que no reflejan con precisión a personas, lugares o hechos reales. En algunos casos, los modelos GPT pueden incorporar sesgos sociales como estereotipos o sentimientos negativos hacia ciertos grupos. Debe evaluar la precisión de cualquier resultado según corresponda a su caso de uso.
Resúmenes de IA
Como su nombre indica, los resúmenes de IA aprovechan el poder de la inteligencia artificial para crear resúmenes de forma automática. Puede resumir documentos, citas codificadas, grupos de documentos o citas codificadas con códigos de un grupo. Los resultados se almacenan en memos vinculados a sus respectivas entidades resumidas.
Puede acceder a la codificación de IA a través del menú Análisis, el botón Documentos o Códigos en la barra de herramientas principal, o en la sección Análisis de los menús contextuales del documento o del grupo de documentos.
Descripción general rápida
Comience seleccionando los documentos, códigos o grupos que desea que ATLAS.ti resuma. Después de hacer clic en "Resumir", ATLAS.ti le preguntará si desea continuar y le mostrará una estimación aproximada del tiempo que tardará en procesar sus datos.
Los resúmenes de IA cargarán el contenido de su documento en los servidores de ATLAS.ti y OpenAI. Nunca cargaremos sus datos sin su consentimiento explícito. Si desea continuar, active la casilla de verificación donde reconoce que acepta nuestro EULA y nuestra Política de privacidad. OpenAI NO utilizará los datos de los usuarios de ATLAS.ti para entrenar los modelos de OpenAI.
Puede continuar trabajando mientras se generan los resúmenes de IA.
Los resúmenes de IA solo funcionan con contenido de texto. Su funcionamiento con documentos es bastante intuitivo, pero un resumen de un código puede requerir alguna explicación. Al resumir un código, ATLAS.ti obtiene todas las citas textuales codificadas con ese código, las ordena por orden de aparición, crea un gran texto virtual a partir de todas ellas y luego genera un resumen de ese texto.
Al resumir documentos o códigos, obtendrá un resumen por documento o código. Al resumir grupos, obtendrá un resumen por grupo. Funciona de manera muy similar a cuando se recopilan citas de texto para el resumen de un código: primero, ATLAS.ti reúne todos los documentos (o códigos), luego los coloca uno tras otro en un gran texto virtual y, finalmente, obtiene un resumen de todos ellos.
Los documentos PDF suelen ser fácilmente legibles para las personas, pero no tanto para el ordenador: dado que el PDF se desarrolló originalmente como formato de impresión, tiene una gran fidelidad visual, pero el orden del texto puede ser técnicamente muy diferente de cómo lo percibimos los humanos. Por ello, los documentos PDF pueden producir resultados deficientes en ocasiones.
Tenga en cuenta que, aunque en general es beneficioso que los modelos GPT hayan sido entrenados con grandes cantidades de texto, en algunas situaciones esto puede dar lugar a resultados incorrectos que no reflejan con precisión a personas, lugares o hechos reales. En algunos casos, los modelos GPT pueden incorporar sesgos sociales como estereotipos o sentimientos negativos hacia ciertos grupos. Debe evaluar la precisión de cualquier resultado según corresponda a su caso de uso.
Búsqueda de texto y autocodificación
Tutorial en video: Búsqueda de texto y autocodificación.
Al utilizar esta herramienta, introduce su propio término de búsqueda y puede permitir que ATLAS.ti codifique sus datos automáticamente. La herramienta ofrece varias funciones adicionales que la convierten en algo más que una simple herramienta de autocodificación:
- Puede seleccionar sinónimos. Los sinónimos están disponibles en inglés, alemán, español, portugués, francés, neerlandés, ruso y chino simplificado.
- Puede combinar varios términos de búsqueda utilizando operadores booleanos (AND; OR) para buscar ocurrencias dentro de una oración o párrafo, o múltiples sílabas en una palabra.
- Puede buscar formas flexionadas, es decir, buscar "run" (correr) también buscará running, runs, ran.
- Puede usar comodines (*)
- Puede buscar frases exactas introduciendo comillas, como en: „limited liability corporations".
Cómo realizar una búsqueda de texto
Para abrir la herramienta, seleccione Código > Buscar y codificar > Búsqueda de texto en el menú principal.
Seleccione los documentos o grupos de documentos que desea buscar y haga clic en Continuar.
Seleccione la unidad base para la búsqueda y la codificación:
- Párrafos
- Oraciones
- Palabras
- Coincidencias exactas (se pueden usar comodines)
Introduzca un término de búsqueda. Si hay sinónimos disponibles, puede seleccionarlos en la lista desplegable a la derecha del campo de entrada de búsqueda.
Puede agregar más términos de búsqueda vinculándolos con operadores booleanos:
-
AND: Todos los términos de búsqueda introducidos deben aparecer en el contexto seleccionado (párrafo, oración, palabra).
-
OR: Se devuelven resultados si cualquiera de los términos de búsqueda aparece en el contexto seleccionado (párrafo, oración, palabra).
Active la opción formas flexionadas si lo desea. Esta opción está actualmente disponible para todos los idiomas de la interfaz.
Formas flexionadas: Las formas plurales de los sustantivos, las formas de pasado, participio pasado y participio presente de los verbos, y las formas comparativas y superlativas de adjetivos y adverbios se conocen como formas flexionadas. Para mejorar los resultados, puede descargar e instalar un modelo más completo. Para ello, haga clic en Administrar modelos.
Para ejecutar la búsqueda, haga clic en Continuar.
La página de resultados le muestra un Lector de citas que indica dónde se encuentran las citas al (auto)codificar los datos. Si ya existen codificaciones en la cita, también se mostrarán.
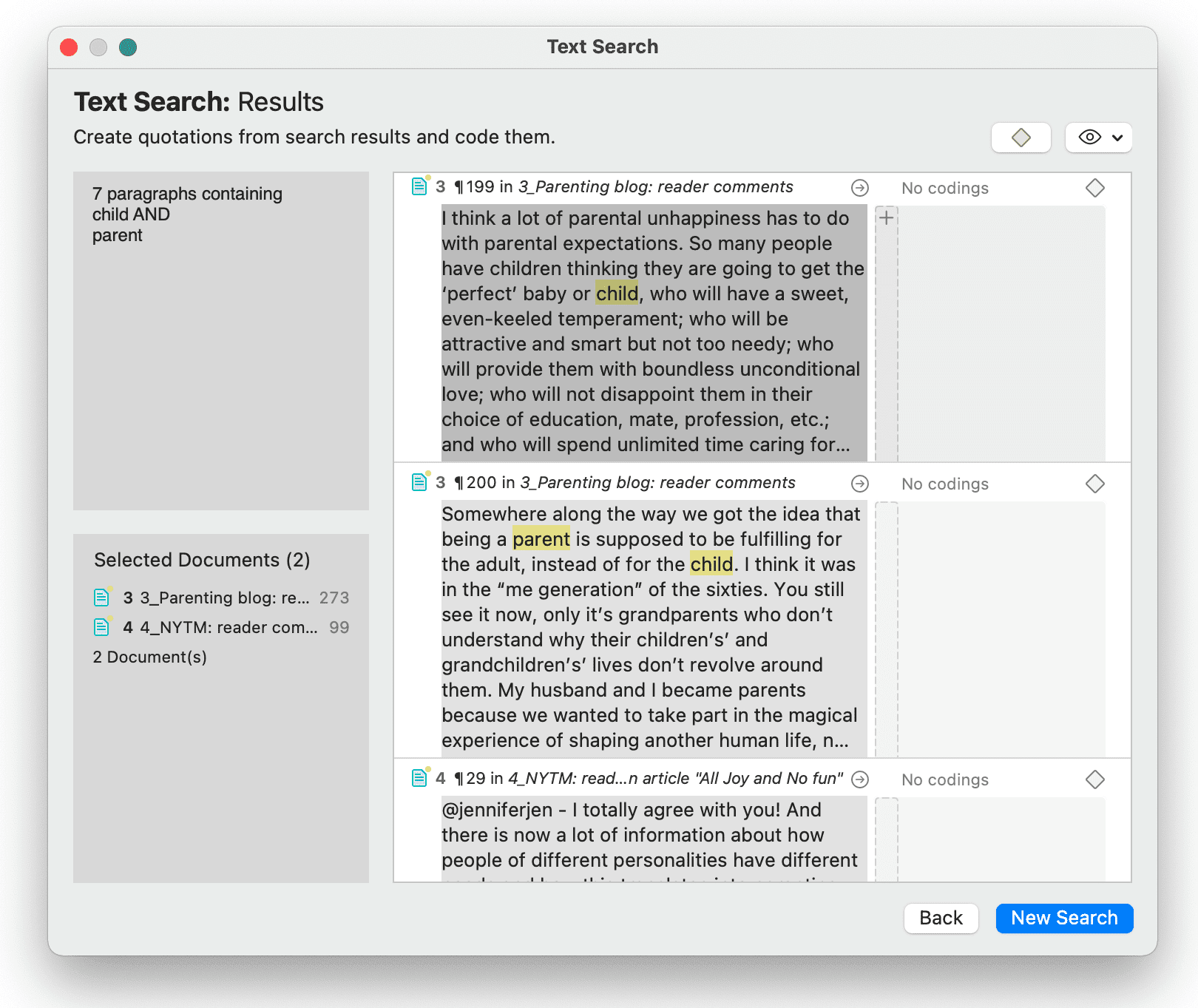
Haciendo clic en el ojo, puede alternar entre vistas previas pequeñas y grandes.
Puede autocodificar todos los resultados con un código resaltando todos los segmentos de datos, por ejemplo, mediante Ctrl+A. Luego seleccione Aplicar códigos, introduzca un nombre de código y haga clic en el icono más.
Según el área que haya seleccionado, se codificará la coincidencia exacta, la palabra, la oración o el párrafo.
Otra opción es revisar cada hallazgo y codificarlo haciendo clic en el icono de codificación. Esto abre el Diálogo de codificación habitual.
Búsqueda de coincidencia exacta
Una búsqueda de coincidencia exacta encuentra los caracteres tal como se introducen en el campo de búsqueda. Los resultados de la búsqueda de 'emotion' (emoción) podrían ser los siguientes:
- emotions
- emotionless
- demotion
- demotional
Si solo desea encontrar "emotion", debe agregar comillas alrededor del término de búsqueda. Consulte: Búsqueda de frase exacta.
Búsqueda de frase exacta
Cuando desea buscar una frase exacta, simplemente rodee su expresión de búsqueda con comillas. Por ejemplo, si desea buscar "limited liability corporations" (sociedades de responsabilidad limitada) pero solo quiere recuperar resultados en los que los términos aparezcan como una frase exacta, escriba "limited liability corporations" (incluyendo las comillas) en el campo de búsqueda.
Sus resultados de búsqueda solo incluirán segmentos de datos que contengan la frase exacta — limited liability corporations — tal como se escribió entre comillas, pero no incluirán resultados en los que los términos estén separados por otras palabras, como en: corporations with limited liability.
Para obtener los mejores resultados, no incluya caracteres comodín en una búsqueda de frase exacta a menos que el carácter comodín * forme parte de la frase que está buscando.
Búsqueda experta con expresiones regulares (regex)
GREP es una conocida herramienta de búsqueda en el mundo UNIX. La herramienta GREP original imprimía cada línea que contenía el patrón de búsqueda, de ahí el acrónimo GREP (Globally search for a Regular Expression and Print matching lines / Buscar globalmente una expresión regular e imprimir las líneas coincidentes).
En ATLAS.ti, los resultados de una búsqueda GREP no se imprimen línea por línea; en cambio, el texto que coincide con el patrón de búsqueda se resalta en la pantalla, o puede codificar automáticamente los resultados incluyendo algo de contexto circundante.
El núcleo de una búsqueda GREP es la inclusión de caracteres especiales en la cadena de búsqueda que controlan el proceso de coincidencia. GREP encuentra instancias en sus datos que coinciden con ciertos patrones.
Puede probar y depurar cualquier expresión regular que formule en este sitio web: https://regex101.com/
Realizar una búsqueda de texto con expresiones regulares
Para abrir la herramienta, seleccione Código > Buscar y codificar > Búsqueda por expresión regular en el menú principal.
Seleccione los documentos o grupos de documentos que desea buscar y haga clic en Continuar.
Seleccione la unidad base para la búsqueda y la codificación:
- Párrafos
- Oraciones
- Palabras
- Coincidencias exactas
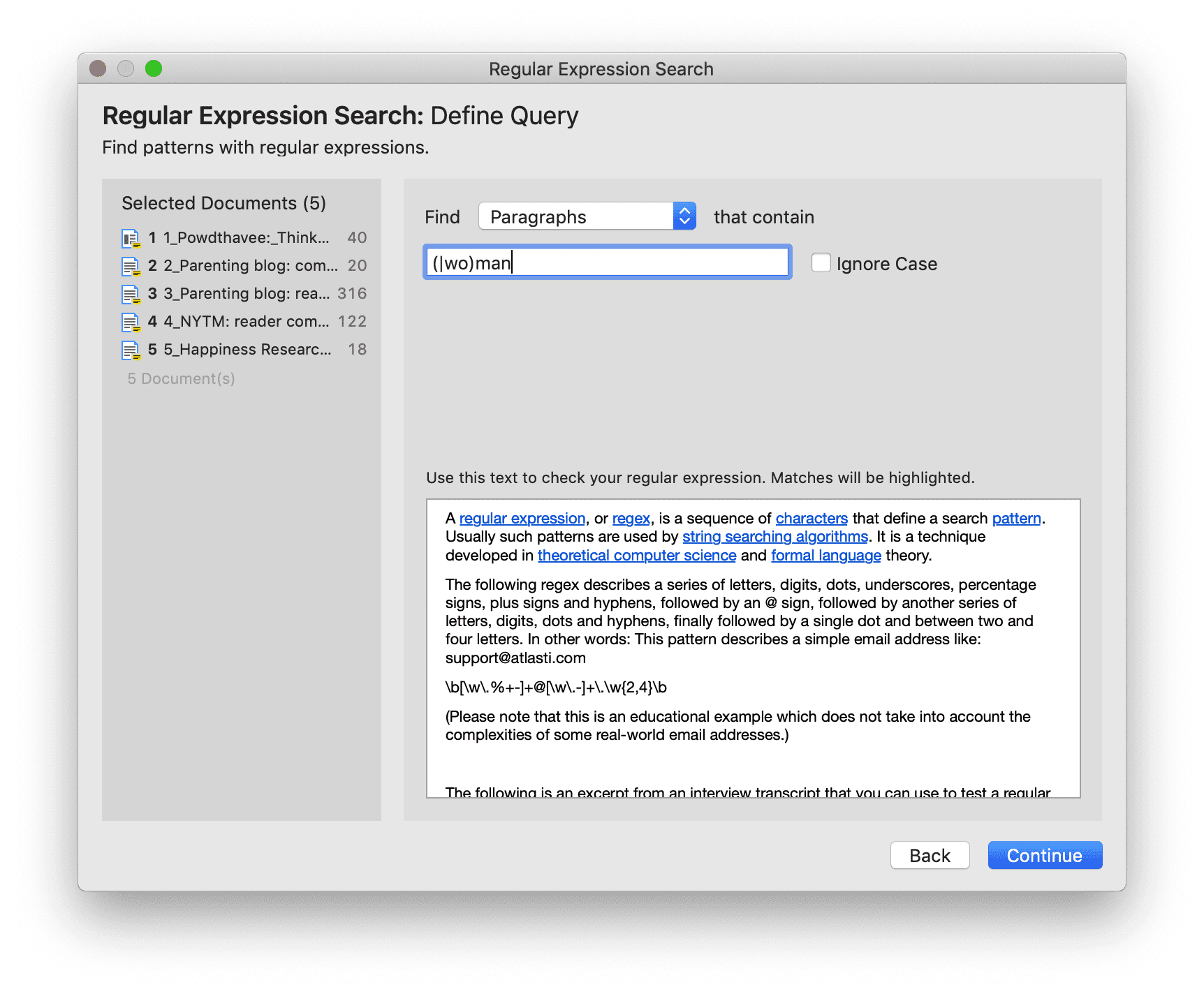
Introduzca un término de búsqueda. Puede probar su expresión de búsqueda en el texto que aparece en la mitad inferior de la pantalla.
Para ejecutar la búsqueda, haga clic en Continuar.
La página de resultados le muestra un Lector de citas que indica dónde se encuentran las citas al (auto)codificar los datos. Si ya existen codificaciones en la cita, también se mostrarán.
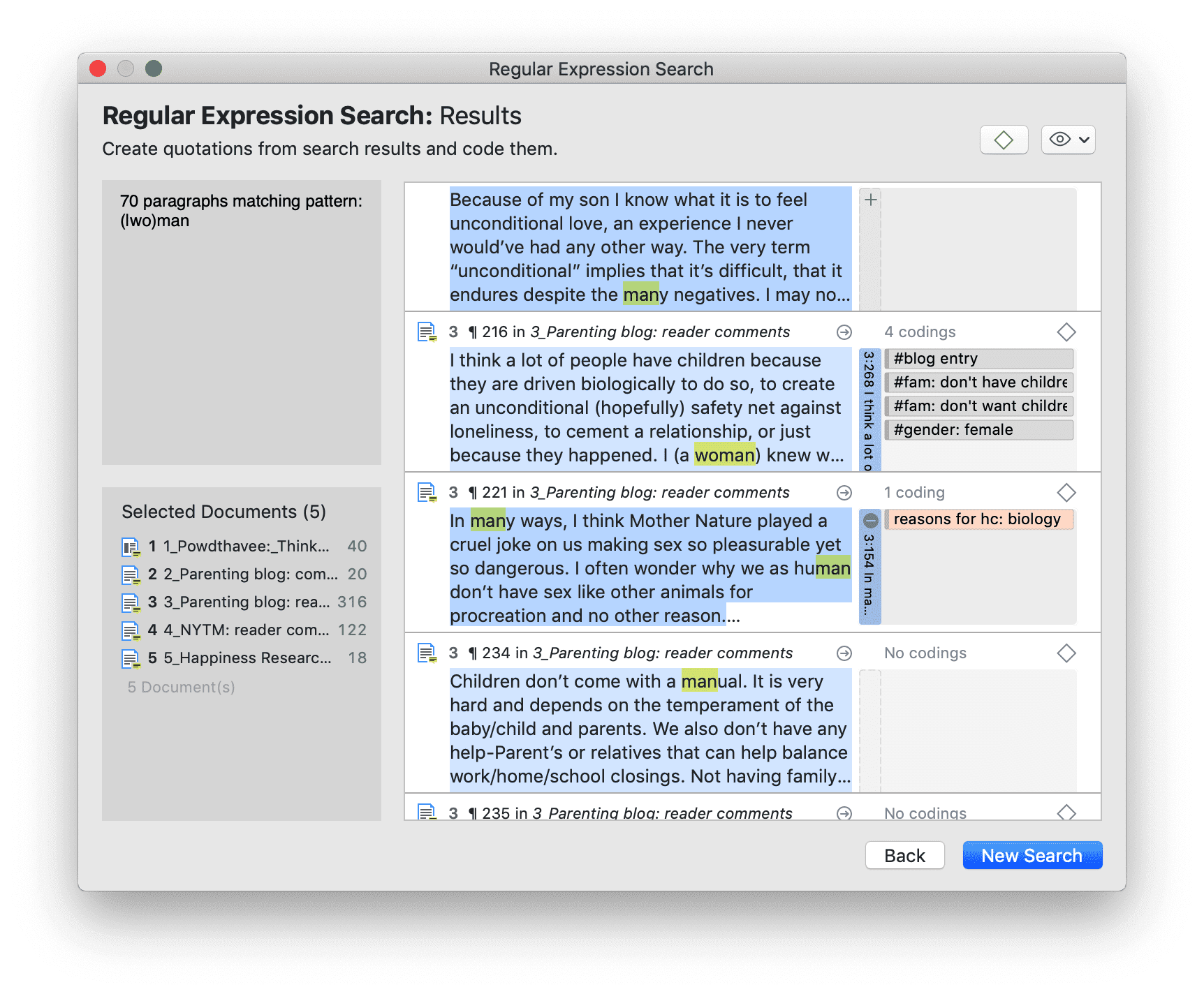
Haciendo clic en el icono del ojo, puede alternar entre vistas previas pequeñas, medianas y grandes.
Puede autocodificar todos los resultados con un código resaltando todos los segmentos de datos, por ejemplo, mediante Ctrl+A. Luego seleccione Aplicar códigos, introduzca un nombre de código y haga clic en el icono más. Según el área que haya seleccionado, se codificará la coincidencia exacta, la palabra, la oración o el párrafo.
Otra opción es revisar cada hallazgo y codificarlo haciendo clic en el icono de codificación. Esto abre el Diálogo de codificación habitual.
Ejemplos de GREP
| Expresión GREP | Descripción |
|---|---|
^ | Coincide con una cadena vacía al comienzo de una línea. |
$ | Coincide con una cadena vacía al final de una línea. |
. | Coincide con cualquier carácter excepto una nueva línea. |
+ | Coincide con al menos una ocurrencia de la expresión o carácter precedente. |
* | Coincide con el elemento precedente cero o más veces. Por ejemplo, ab*c coincide con "ac", "abc", "abbbc", etc. |
? | Coincide con el elemento precedente cero o una vez. Por ejemplo, ba? coincide con "b" o "ba". |
[] | Coincide con un rango o conjunto de caracteres: [a-z] o [0-9] o [aeiou]. Por ejemplo: [0-9] encuentra todos los caracteres numéricos, mientras que [^0-9] encuentra todos los no numéricos. |
\b | Coincide con una cadena vacía en un límite de palabra. |
\B | Coincide con una cadena vacía que no está en un límite de palabra. |
< | Coincide con una cadena vacía al comienzo de una palabra. |
> | Coincide con una cadena vacía al final de una palabra. |
Encierre entre paréntesis las expresiones unidas con OR si el OR debe restringirse a ciertas secuencias de caracteres o expresiones. Vea el ejemplo a continuación.
El carácter de barra invertida deshabilita la funcionalidad GREP especial del carácter siguiente:
| Expresión GREP | Descripción |
|---|---|
\d | Coincide con cualquier dígito (equivalente a [0-9]) |
\D | Coincide con cualquier cosa que no sea un dígito |
\s | Coincide con un carácter de espacio en blanco |
\S | Coincide con cualquier cosa que no sea espacio en blanco |
\w | Coincide con cualquier carácter constituyente de palabra |
\W | Cualquier carácter que no sea constituyente de palabra |
Clases de caracteres
| Clase de caracteres | Descripción |
|---|---|
[:alnum:] | Cualquier carácter alfanumérico, es decir, constituyente de palabra |
[:alpha:] | Cualquier carácter alfabético |
[:cntrl:] | Cualquier carácter de control. En esta versión, significa cualquier carácter cuyo código ASCII sea < 32. |
[:digit:] | Cualquier dígito decimal |
[:graph:] | Cualquier carácter gráfico. En esta versión, significa cualquier carácter con código >= 32. |
[:lower:] | Cualquier carácter en minúscula |
[:punct:] | Cualquier carácter de puntuación |
[:space:] | Cualquier carácter de espacio en blanco |
[:upper:] | Cualquier carácter en mayúscula |
[:xdigit:] | Cualquier carácter hexadecimal |
Tenga en cuenta que estos elementos son componentes de las clases de caracteres, es decir, deben estar encerrados en un conjunto adicional de corchetes para formar una expresión regular válida. Una cadena no vacía de dígitos de longitud arbitraria se representaría como [[:digit:]]+
Ejemplos de búsquedas GREP
A continuación se presentan algunos ejemplos de búsqueda que muestran la expresión GREP correspondiente en la columna derecha.
-
La expresión
man|womancoincide con "man" y "woman". También puede usar(|wo)mancon el mismo efecto. -
H(a|e)llocoincide con "Hello" y "Hallo". -
H(a|e)+llocoincide con "Haaaaaallo" así como con "Heeeeeaaaaeaeaeaeaello". -
¿Y qué hay de
the (angry|lazy|stupid) (man|woman) (walk|run|play|fight)ing with the gr(a|e)y dog? ¿Se entiende la idea?
Reconocimiento de entidades nombradas (NER)
En el procesamiento del lenguaje natural, el reconocimiento de entidades nombradas (NER) es un proceso mediante el cual se analiza una oración o un fragmento de texto para encontrar entidades que pueden clasificarse en categorías como persona, organización, lugar u otras como obras de arte, idiomas, partidos políticos, eventos, títulos de libros, etc.
Esta función está disponible para los siguientes idiomas:
- Inglés
- Alemán
- Español
- Portugués
- Francés
- Neerlandés
- Ruso
- Chino simplificado
Puede considerarse como un procedimiento especial de autocodificación en el que usted, como usuario, no introduce un término de búsqueda. En su lugar, ATLAS.ti recorre sus datos y encuentra entidades por usted.
Puede seleccionar qué tipos de entidades desea buscar:
- persona
- organización
- lugar
- miscelánea (obras de arte, idiomas, partidos políticos, eventos, títulos de libros, etc.)
Una vez completada la búsqueda, ATLAS.ti le muestra lo que encontró y puede realizar correcciones. En el siguiente paso puede revisar los resultados en contexto y codificar todos los resultados con los códigos sugeridos, o decidir por cada hallazgo si desea codificarlo o no.
Para abrir la herramienta:
En el menú principal, seleccione Código > Buscar y codificar > Reconocimiento de entidades nombradas.
Seleccione los documentos o grupos de documentos que desea buscar y haga clic en Continuar.
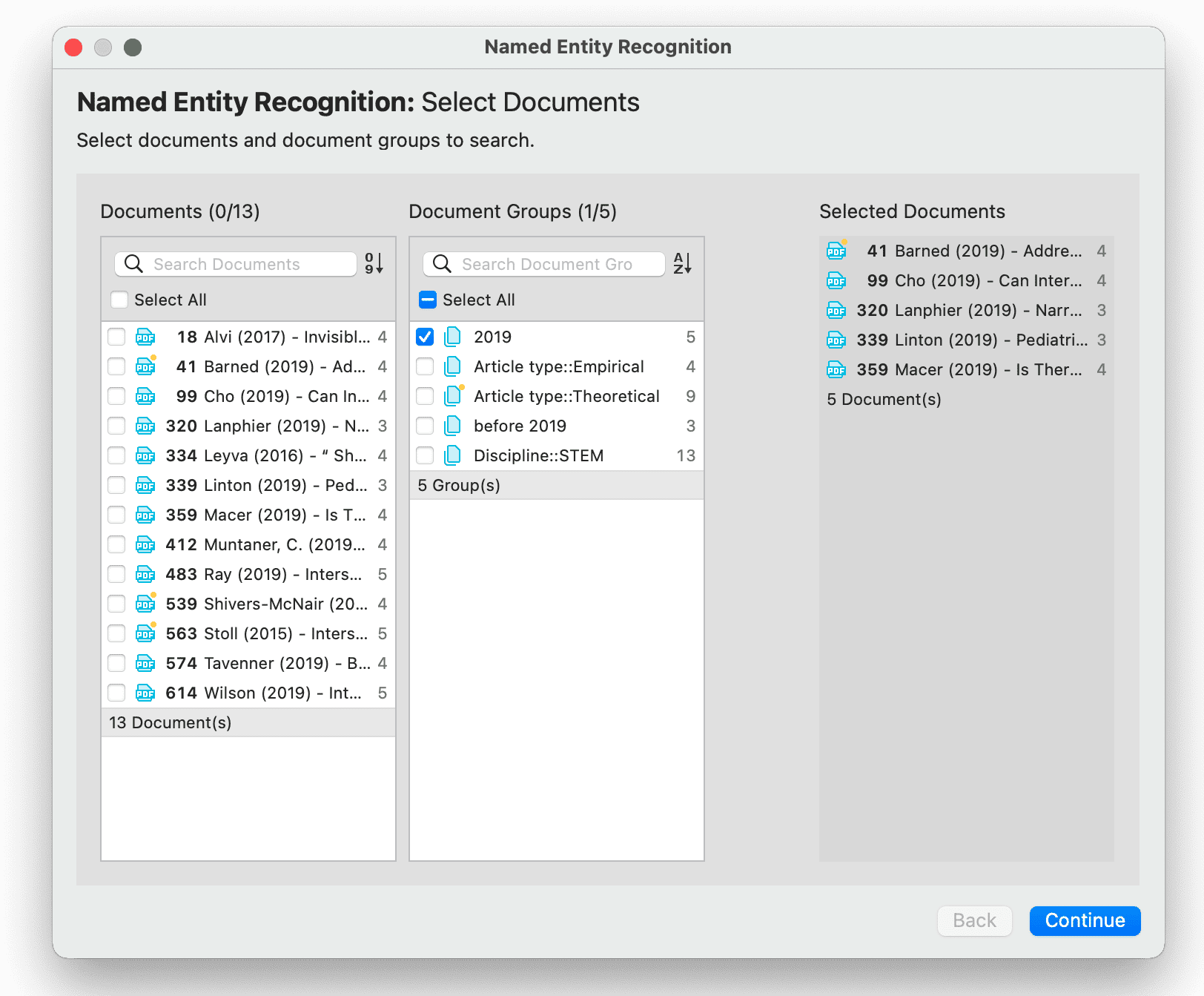
Seleccione si la unidad base para la búsqueda y la codificación debe ser párrafos, oraciones o palabras, y qué categoría de entidad desea buscar.
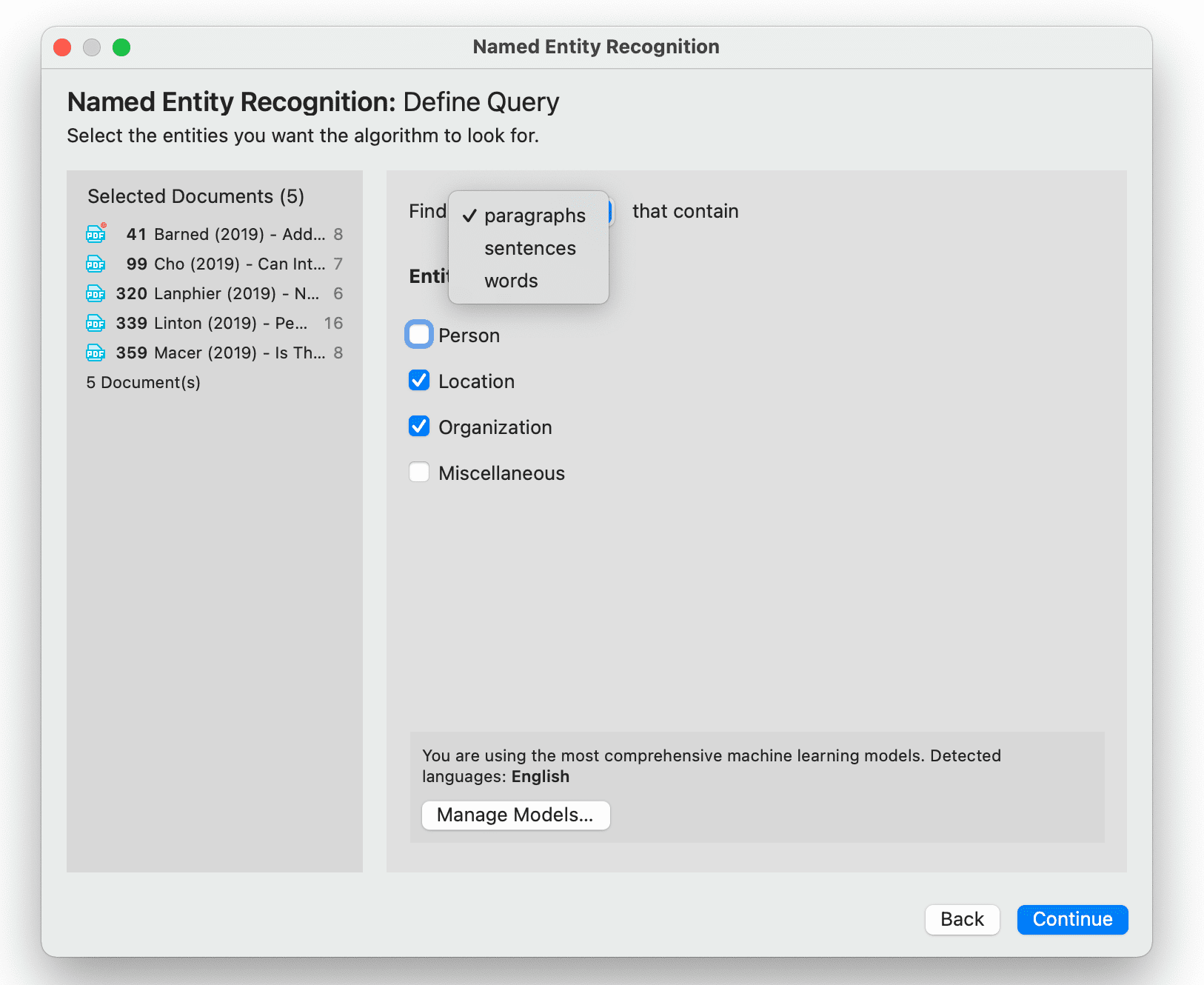
Administrar modelos: Si desea mejorar sus resultados, puede descargar e instalar un modelo más completo.
Haga clic en Administrar modelos si desea instalar o desinstalar un modelo extendido.
Haga clic en Continuar para comenzar a buscar en los documentos seleccionados. En la siguiente pantalla se presentan los resultados de la búsqueda y puede revisarlos.
Revisión de los resultados de la búsqueda
Si seleccionó buscar todos los tipos de entidades (personas, lugares, organizaciones y miscelánea), puede revisarlos todos juntos o centrarse en un tipo de entidad a la vez. Para ello, desactive todos los demás tipos de entidades.
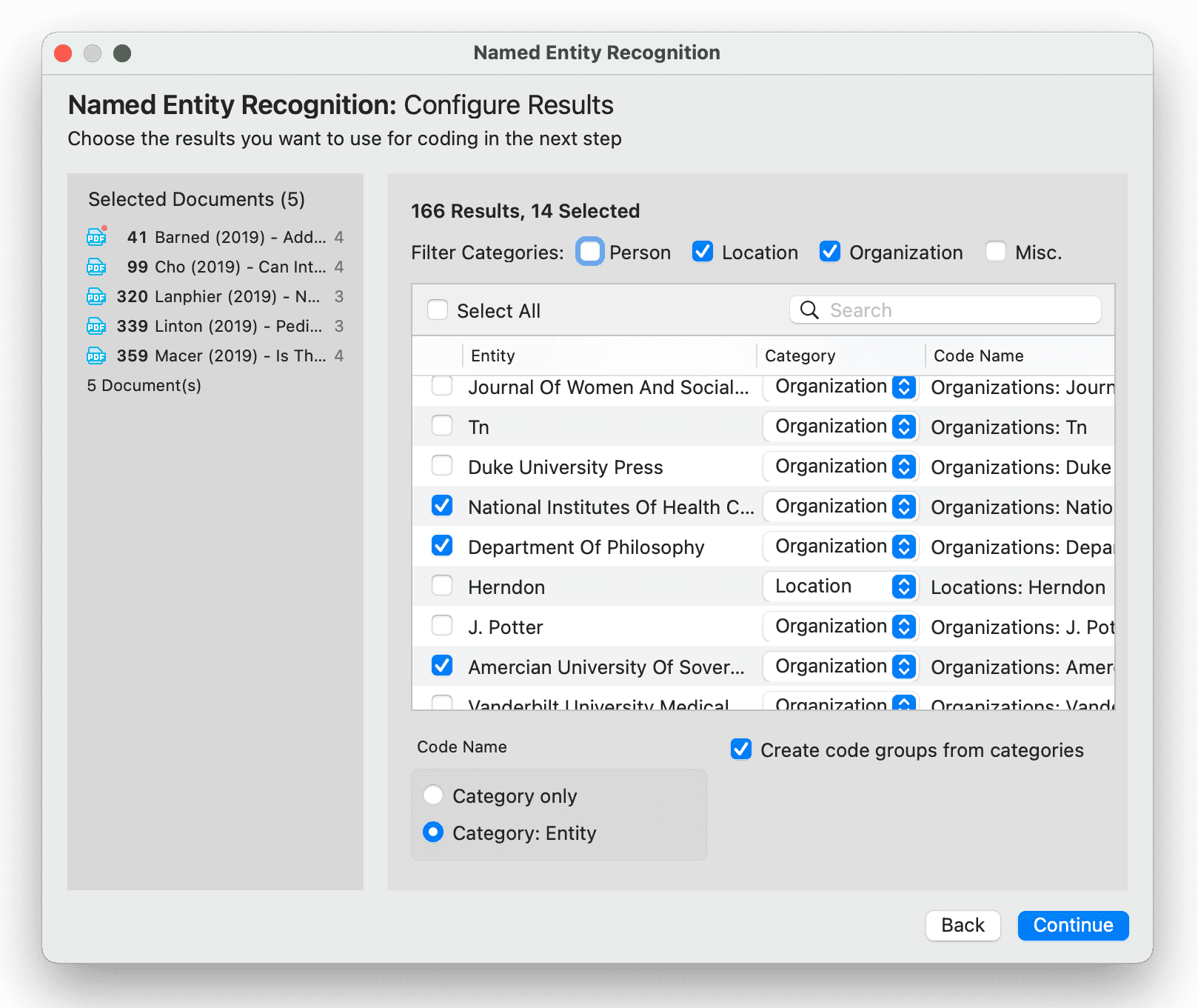
Seleccione todos los resultados que desea codificar. Si un resultado es interesante pero aparece en la categoría incorrecta, puede cambiar la categoría en la segunda columna de la lista de resultados. En la tercera columna se muestra el nombre de código sugerido.
Autocodificar resultados
Tiene tres opciones para el nombre del código:
-
Solo categoría: Si selecciona esta opción, todos los hallazgos de la búsqueda se codificarán bajo la categoría NER: Persona, Lugar, Organización, Miscelánea.
-
Categoría: Entidad: Si selecciona esta opción, se crearán categorías con subcódigos para las NUEVAS categorías: Persona, Lugar, Organización, Miscelánea. Las entidades se convertirán en los subcódigos.
También tiene la opción de agrupar todos los códigos de una categoría NER en un grupo de códigos. Esta opción es útil si seleccionó la segunda opción con subcódigos.
Haga clic en Continuar para inspeccionar los resultados en contexto.
La página de resultados le muestra un Lector de citas que indica dónde se encuentran las citas al codificar los datos con el código propuesto. Si ya existe una codificación en la cita, también se mostrará.
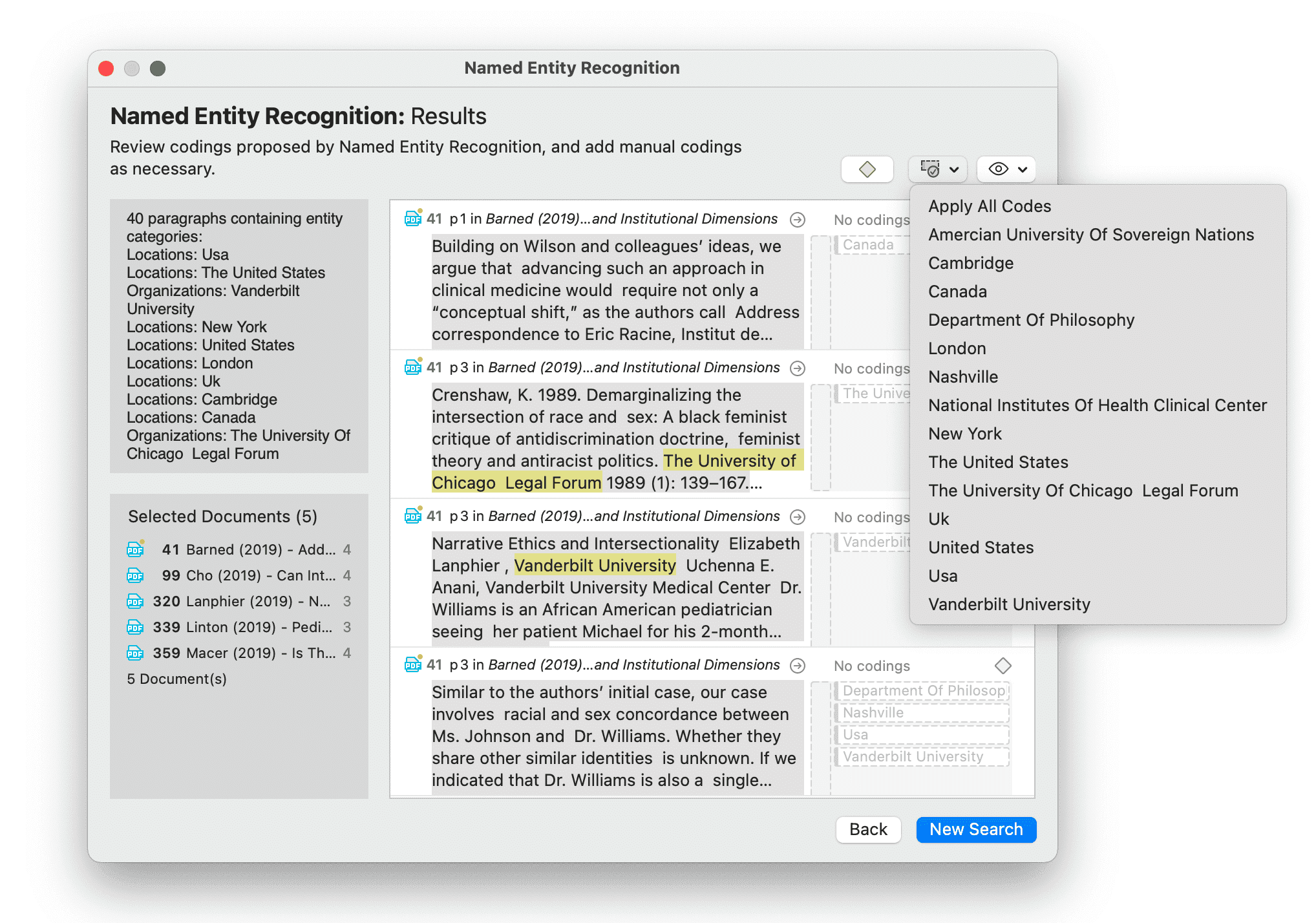
Haciendo clic en el ojo, puede alternar entre vistas previas pequeñas y grandes.
Puede recorrer y revisar cada segmento de datos y luego codificarlo haciendo clic en el más junto al nombre del código. O bien, puede codificar todos los resultados seleccionando el botón Aplicar códigos. Puede seleccionar la primera opción Aplicar todos los códigos, o seleccionar solo un código de la lista.
Si ha seleccionado la opción de categoría: subcódigo para la codificación, los resultados de la codificación podrían verse de la siguiente manera:
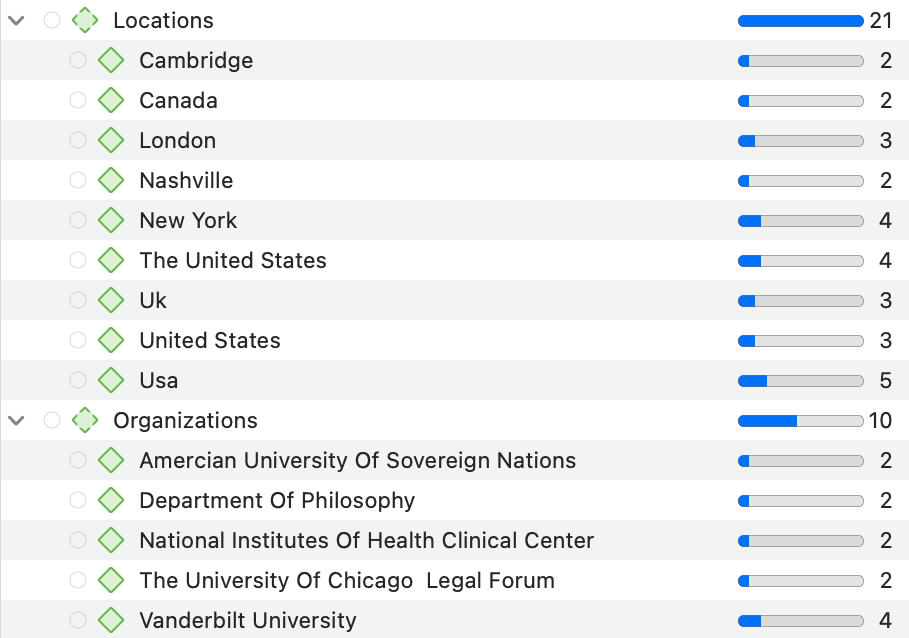
Según el área que haya seleccionado al principio, se codificará la palabra, la oración o el párrafo.
El Diálogo de codificación habitual también está disponible para agregar o eliminar códigos.
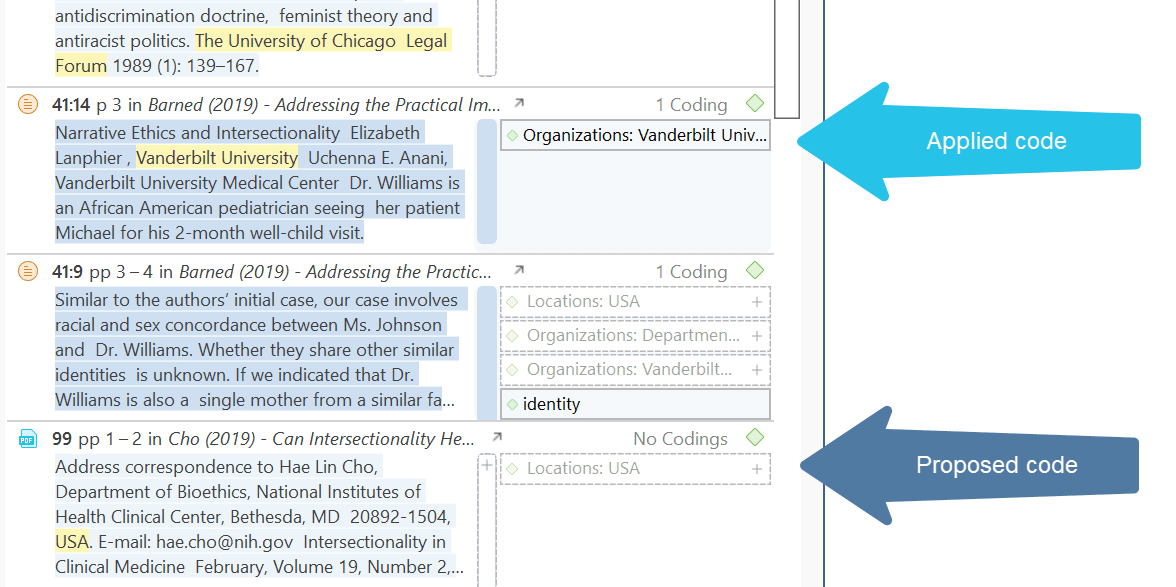
El motor de búsqueda detrás de NER
ATLAS.ti utiliza spaCy como su motor de procesamiento del lenguaje natural. Puede encontrar información más detallada aquí.
Los datos de entrada se procesan en una cadena de procesamiento: paso a paso para mejorar el conocimiento derivado del paso anterior. Haga clic aquí para obtener más detalles.
El primer paso es un tokenizador para dividir un texto dado en partes significativas y reemplazar elipsis, etc. Por ejemplo, la oración:
"I should've known (didn't back then)." se tokenizará como: "I should have known ( did not back then )."
El tokenizador utiliza un vocabulario para cada idioma y asigna un vector a cada palabra. Este vector fue aprendido previamente mediante el uso de un corpus y representa un tipo de similitud de uso en el corpus utilizado. Haga clic aquí para obtener más información.
El siguiente componente es un etiquetador que asigna etiquetas de categoría gramatical a cada token y lexema si el token es una palabra. La secuencia de caracteres "mine" (en inglés), por ejemplo, tiene significados bastante diferentes dependiendo de si es un sustantivo o un pronombre.
Por lo tanto, no se usa simplemente una lista de palabras como referencia. En consecuencia, tampoco existe la opción de agregar sus propias palabras a una lista ni de ver la lista de palabras que se utiliza.
El reconocedor de entidades está entrenado con texto similar al de Wikipedia y funciona mejor con texto gramaticalmente correcto, similar al de una enciclopedia. Utilizamos modelos preentrenados modificados o construidos desde cero, según el idioma.
Análisis de sentimientos
Tutorial en video: Análisis de sentimientos.
El análisis de sentimientos es la interpretación y clasificación de emociones (positivas, negativas y neutras) dentro de datos de texto mediante técnicas de análisis de texto.
Esta función está disponible para los siguientes idiomas:
- Inglés
- Alemán
- Español
- Portugués
- Francés
- Neerlandés
- Ruso
- Chino simplificado
Ejemplos de aplicación
- Identificar y catalogar un fragmento de texto según el tono que transmite.
- Comprender el sentimiento social hacia una marca, producto o servicio.
- Identificar el sentimiento de los encuestados hacia el tema que se debate en conversaciones y comentarios en línea.
- Analizar las evaluaciones de los estudiantes sobre clases, seminarios o programas de estudio.
El análisis de sentimientos funciona mejor con datos estructurados, como preguntas abiertas en una encuesta, evaluaciones, conversaciones en línea, etc.
Cómo realizar un análisis de sentimientos
Para abrir la herramienta, seleccione Código > Buscar y codificar > Análisis de sentimientos en el menú principal.
Seleccione los documentos o grupos de documentos que desea buscar y haga clic en Continuar.
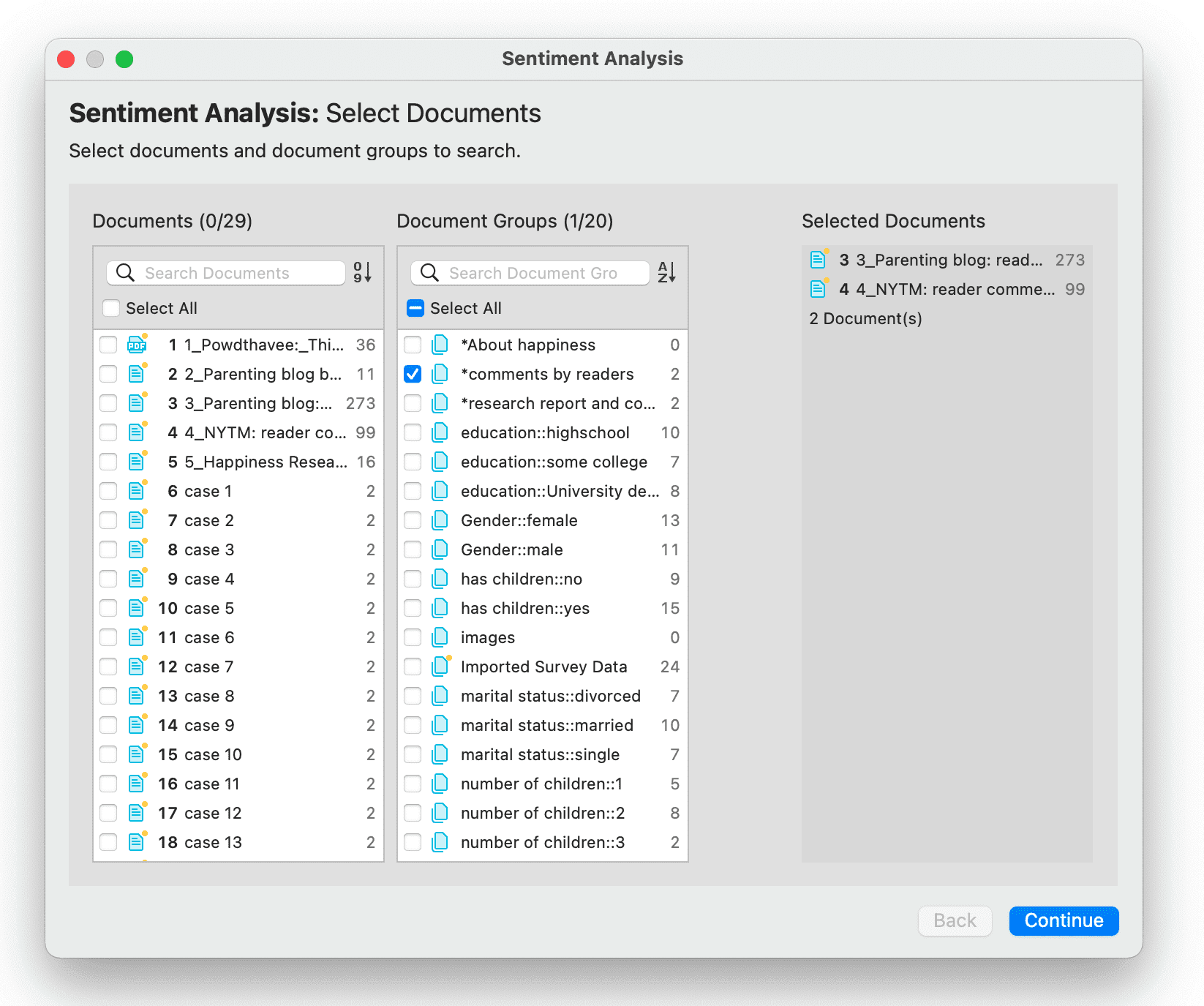
Seleccione la unidad base para la búsqueda y la codificación:
- párrafos
- oraciones
Seleccione el tipo de sentimiento que desea codificar:
- positivo
- neutro
- negativo
ATLAS.ti propone etiquetas de subcódigo para cada sentimiento: Positivo / Neutro / Negativo. Si desea utilizar nombres diferentes, puede cambiarlos aquí.
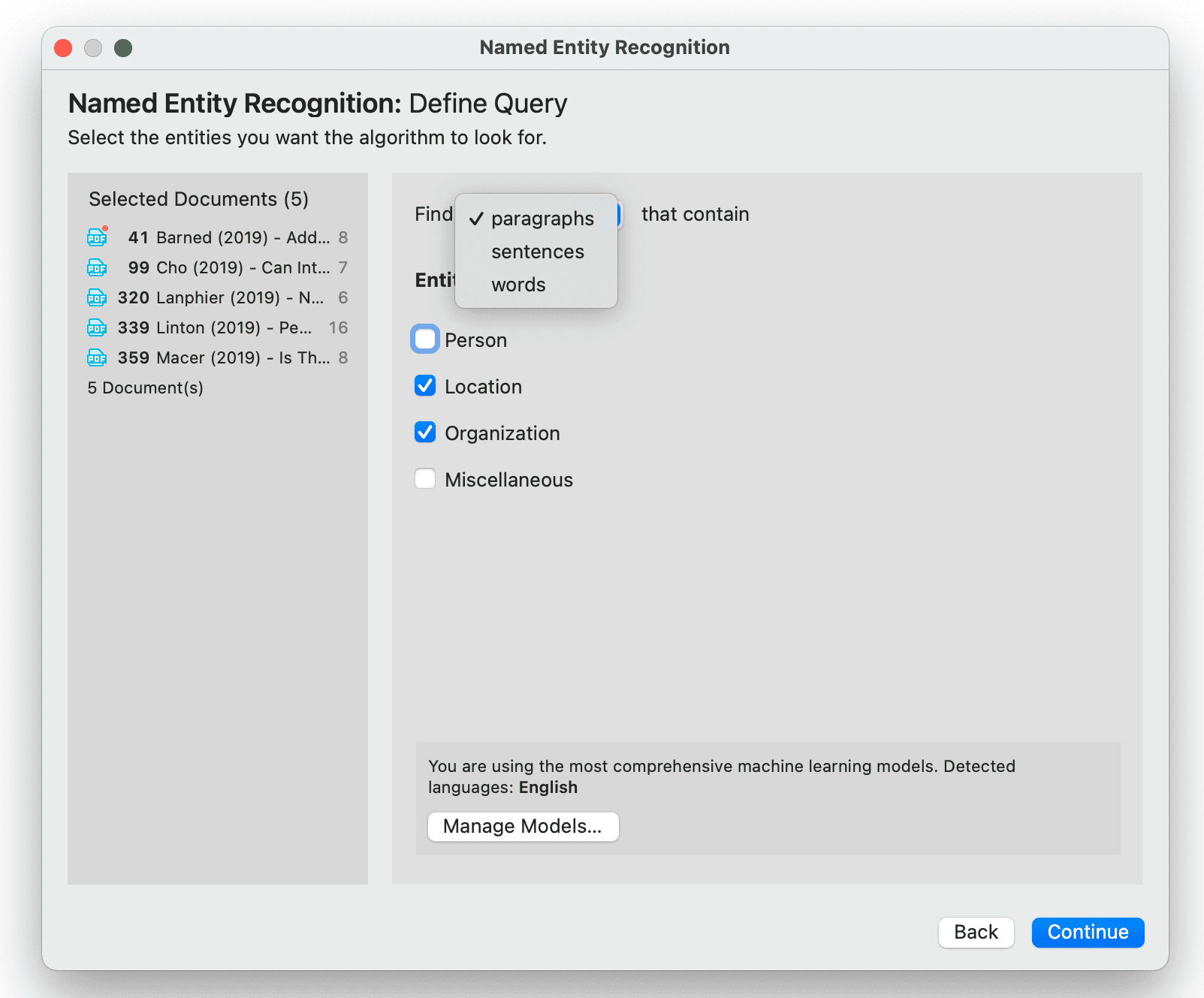
Administrar modelos: Si desea mejorar sus resultados, puede descargar e instalar un modelo más completo.
Haga clic en Administrar modelos si desea instalar o desinstalar un modelo extendido.
Haga clic en Continuar para comenzar a buscar en los documentos seleccionados. En la siguiente pantalla se presentan los resultados de la búsqueda y puede revisarlos.
La página de resultados le muestra un Lector de citas que indica dónde se encuentran las citas al codificar los datos con el código propuesto. Si ya existe una codificación en la cita, también se mostrará.
Haciendo clic en el icono del ojo, puede alternar entre vistas previas pequeñas, medianas y grandes.
Puede codificar todos los resultados con uno de los códigos propuestos o con todos los códigos propuestos a la vez; o puede revisar cada segmento de datos y luego codificarlo haciendo clic en el más junto al nombre del código.
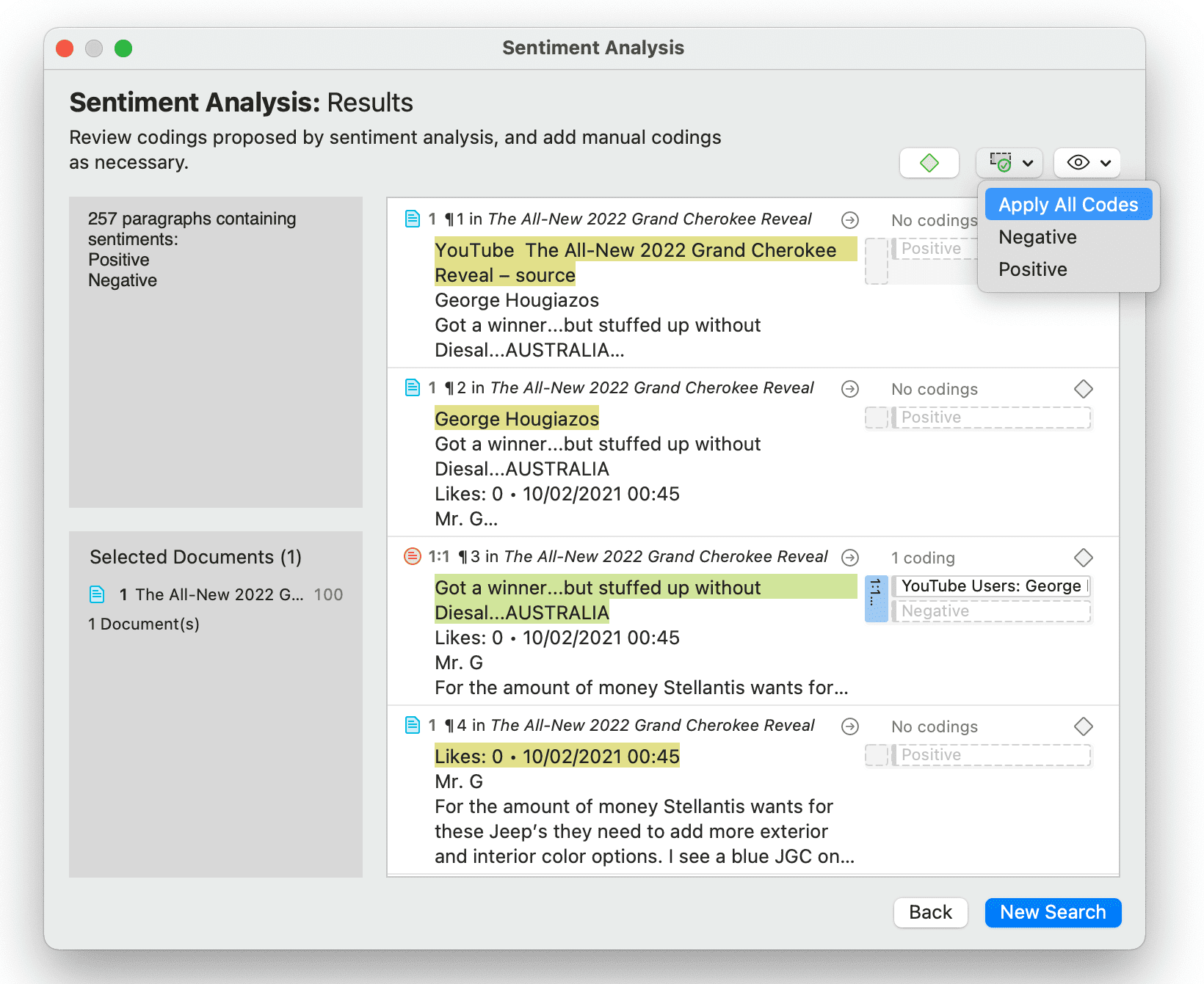
Según el área que haya seleccionado al principio, se codificará la oración o el párrafo.
El Diálogo de codificación habitual también está disponible para agregar o eliminar códigos.
El motor de búsqueda detrás del análisis de sentimientos
Utilizamos spaCy como nuestro motor de procesamiento del lenguaje natural. Puede encontrar información más detallada aquí.
Los datos de entrada se procesan en una cadena de procesamiento: paso a paso para mejorar el conocimiento derivado del paso anterior. Haga clic aquí para obtener más detalles.
El primer paso es un tokenizador para dividir un texto dado en partes significativas y reemplazar elipsis, etc. Por ejemplo, la oración:
"I should've known(didn't back then)." se tokenizará como: "I should have known ( did not back then )."
El tokenizador utiliza un vocabulario para cada idioma y asigna un vector a cada palabra. Este vector fue aprendido previamente mediante el uso de un corpus y representa un tipo de similitud de uso en el corpus utilizado. Haga clic aquí para obtener más información.
El siguiente componente es un etiquetador que asigna etiquetas de categoría gramatical a cada token y lexema si el token es una palabra. La secuencia de caracteres "mine" (en inglés), por ejemplo, tiene significados bastante diferentes dependiendo de si es un sustantivo o un pronombre.
Por lo tanto, no se usa simplemente una lista de palabras como referencia. En consecuencia, tampoco existe la opción de agregar sus propias palabras a una lista ni de ver la lista de palabras que se utiliza.
La cadena de procesamiento del análisis de sentimientos está entrenada con una variedad de textos que van desde discusiones en redes sociales hasta opiniones de personas sobre diferentes temas y productos. Utilizamos modelos preentrenados modificados o construidos desde cero, según el idioma.
Encontrar conceptos y autocodificar
Tutorial en video: Búsqueda de conceptos.
Deje que ATLAS.ti encuentre los conceptos relevantes por usted. Revíselos en contexto y autocodifique.
Esta función está disponible para los siguientes idiomas:
- Inglés
- Alemán
- Español
- Portugués
- Francés
- Neerlandés
- Ruso
- Chino simplificado
¿Qué constituye un concepto?
En un primer paso, se detectan las frases nominales significativas (por ejemplo, sistema de atención médica) con el fin de identificar los conceptos que aparecen con mayor frecuencia en los datos. En el segundo paso, se recopilan los conceptos y sus frecuencias en todos los archivos del conjunto que se está procesando.
ATLAS.ti filtra activamente los conceptos: solo se presentan en los resultados los conceptos más relevantes. Puede revisar los conceptos en su contexto circundante en el Lector de citas y decidir qué conceptos desea que se codifiquen automáticamente.
Puede buscar conceptos en documentos, grupos de documentos, códigos o grupos de códigos.
Para iniciar un análisis de conceptos, en el menú principal seleccione Análisis / Conceptos.
En el menú desplegable de la parte superior izquierda, seleccione dónde desea buscar (documentos, grupos de documentos, códigos o grupos de códigos). Luego seleccione uno o varios documentos, grupos de documentos, códigos o grupos de códigos.
En cuanto seleccione una entidad, ATLAS.ti comenzará a analizar los datos. Los resultados se muestran en forma de nube de palabras. Opcionalmente, también puede ver el resultado como lista. Solo tiene que cambiar la opción de vista a Lista.
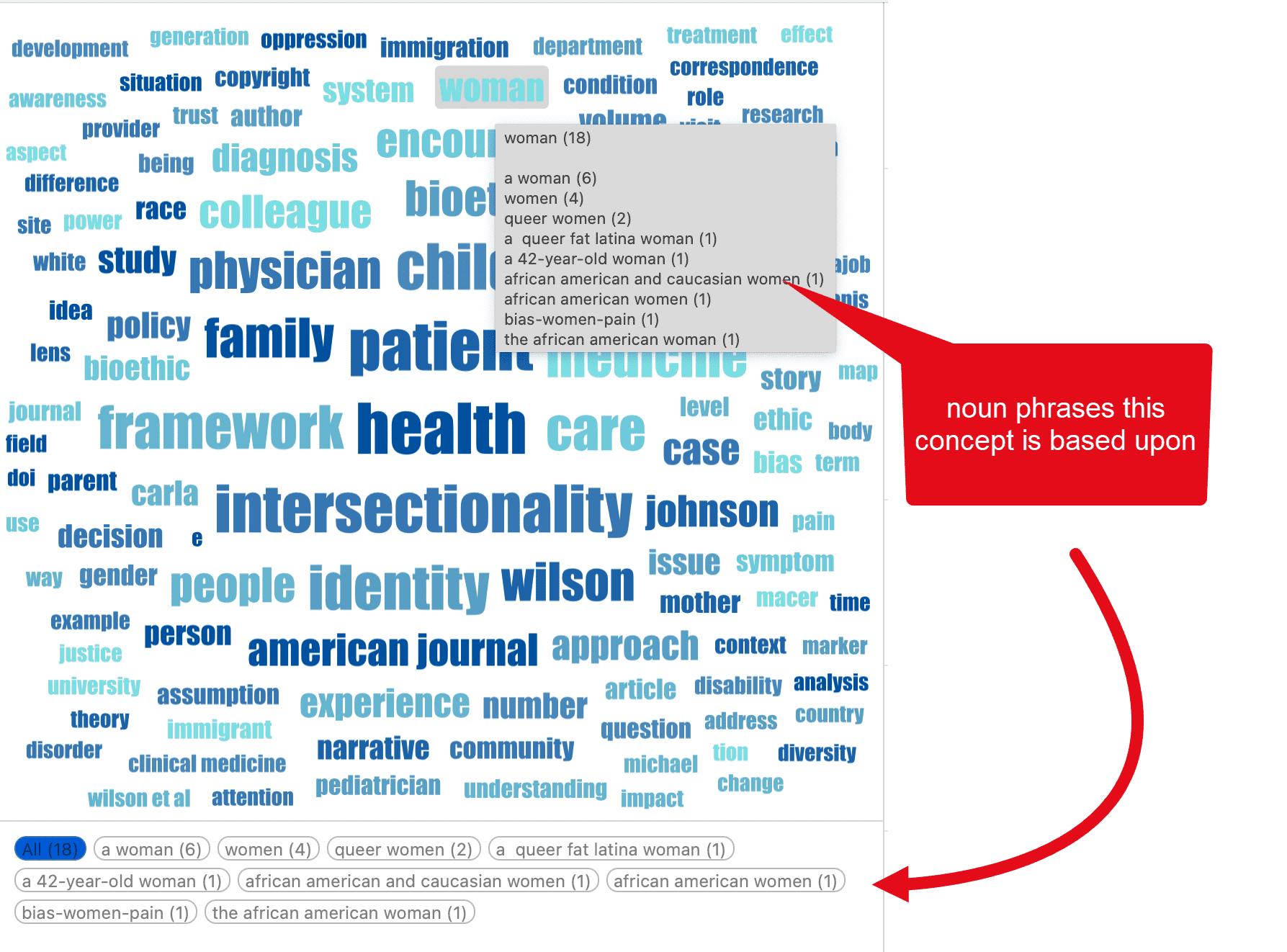
Al seleccionar un concepto o cualquiera de sus frases nominales se muestran las coincidencias de texto correspondientes en el lado derecho.

Para codificar una coincidencia de texto, selecciónela y haga clic en el botón Codificar con concepto en la barra de herramientas.

Minería de opiniones
La minería de opiniones realiza un análisis de sentimientos sobre un texto dado y luego analiza más en profundidad los segmentos de texto positivos y negativos en busca de sus aspectos principales. Estos son sustantivos y verbos que se ven modificados por afecciones como "sonido extraordinario" o "actitud fantástica". El resultado es una visualización de los aspectos más importantes para los sentimientos positivos y negativos. Revíselos en contexto y autocodifique.
Esta función está disponible para los siguientes idiomas:
- Inglés
- Alemán
- Español
- Portugués
- Francés
- Neerlandés
- Ruso
- Chino simplificado
Puede realizar minería de opiniones en documentos, grupos de documentos, códigos o grupos de códigos.
Para abrir la herramienta de minería de opiniones, en el menú principal seleccione Análisis / Minería de opiniones.
En el menú desplegable de la parte superior izquierda, seleccione dónde desea buscar (documentos, grupos de documentos, códigos o grupos de códigos). Luego seleccione uno o varios documentos, grupos de documentos, códigos o grupos de códigos.
En cuanto seleccione una entidad, ATLAS.ti comenzará a analizar los datos. Los aspectos detectados se muestran en un diseño de dos columnas. Los aspectos con sentimiento positivo forman la columna izquierda, mientras que los de sentimiento negativo se muestran en la derecha. Si se encuentran segmentos de texto tanto positivos como negativos para un sentimiento, aparecerá en ambas columnas. Como las columnas están ordenadas por número de coincidencias para su sentimiento respectivo, los resultados positivos y negativos pueden aparecer en lugares diferentes en cada columna.
Al seleccionar un aspecto se muestran sus afecciones en la parte inferior y las coincidencias de texto correspondientes en el lado derecho. Puede filtrar aún más estos resultados seleccionando una afección.
Para codificar una coincidencia de texto, selecciónela y haga clic en el botón Codificar en la barra de herramientas.
Integración de IA mediante MCP
La integración de MCP en ATLAS.ti le permite trabajar con sus proyectos de ATLAS.ti a través de un asistente de IA de su elección, utilizando lenguaje natural y sencillo. A diferencia de las herramientas de IA que solo ven los documentos o el texto que usted les proporciona, un asistente conectado mediante MCP puede trabajar en su proyecto completo —documentos, códigos, citas, memos, redes y grupos— y guardar sus resultados directamente en ATLAS.ti.
En otras palabras, la IA se convierte en un colaborador dentro de su investigación, en lugar de una ventana de chat junto a ella. Todo lo que hace se guarda en su proyecto y, dado que ATLAS.ti dispone de deshacer ilimitado, el asistente nunca puede estropear su trabajo: usted siempre tiene el control.
¿Qué es MCP?
MCP son las siglas de Model Context Protocol, un estándar abierto que conecta los asistentes de IA con aplicaciones y datos externos. Puede considerarlo como un lenguaje común que permite que un cliente de IA y un programa como ATLAS.ti se comuniquen entre sí.
ATLAS.ti incluye un servidor MCP integrado. Una vez que conecta un cliente de IA compatible a él (consulte Clientes de IA probados), la IA puede comprender sus solicitudes y utilizar las funciones de ATLAS.ti en su nombre.
A pesar del nombre, el servidor MCP de ATLAS.ti no es algo que esté en internet. Es un pequeño servicio que se ejecuta en su propio ordenador como parte de ATLAS.ti, y solo se puede acceder a él desde su máquina. Aquí, «servidor» significa simplemente la parte que escucha las solicitudes de su cliente de IA, no un sitio web ni un servicio en la nube.
Qué puede hacer con ella
A través de la integración de MCP, un asistente de IA puede tanto explorar sus proyectos como realizar cambios en ellos. Por ejemplo, puede pedirle lo siguiente:
- Encontrar y revisar su trabajo: enumerar y abrir proyectos, explorar documentos, códigos, memos, redes, citas y grupos, y leer el contenido de documentos y memos.
- Codificar y anotar: crear códigos, aplicar o quitar códigos en citas, establecer colores de códigos, añadir comentarios y vincular memos con otros ítems.
- Organizar su proyecto: crear grupos y carpetas, mover ítems a ellos y renombrar o eliminar entidades, incluida la reestructuración de un libro de códigos desordenado.
- Incorporar material nuevo: crear memos y documentos de texto, importar documentos y transcripciones, y convertir documentos en transcripciones.
Dado que el asistente trabaja en todo su proyecto a la vez, las tareas que de otro modo requerirían horas de trabajo manual —comparar un tema en todas sus entrevistas, reorganizar un libro de códigos extenso o clasificar documentos en grupos— a menudo se pueden realizar en una sola conversación, con los resultados guardados directamente en su proyecto.
Dado que el asistente también puede renombrar y eliminar ítems, trátelo como lo haría con cualquier colaborador competente: revise los cambios que propone. La función de deshacer ilimitado de ATLAS.ti significa que cualquier cambio se puede revertir.
Una buena forma de empezar es abrir un proyecto y, a continuación, pedirle a su cliente de IA algo sencillo como «Enumera todos los códigos de mi proyecto actual» o «Resume los memos de este proyecto». A partir de ahí puede pasar a tareas más complejas, por ejemplo «Tengo 200 códigos, algunos son muy similares. Ayúdame a bajar de 100» o «Lee estas entrevistas, crea grupos de documentos por franja de edad y clasifica los documentos en ellos».
Sus datos y la propiedad de los datos
Una idea central de la integración de MCP es que usted elige la IA y usted decide adónde van sus datos.
El servidor MCP se ejecuta localmente en su propio ordenador y está protegido por una clave de acceso privada. Además, está desactivado de forma predeterminada y solo se ejecuta después de que usted lo habilite explícitamente en ATLAS.ti. Utilizar la integración de MCP no envía sus proyectos a los servidores de ATLAS.ti ni de Lumivero: la nube de ATLAS.ti no interviene en absoluto en MCP. (Esto se aplica específicamente a la integración de MCP; las demás funciones de IA de ATLAS.ti —como la IA conversacional, la codificación con IA y los resúmenes con IA— utilizan los servicios en la nube de ATLAS.ti y son independientes de MCP). El destino de sus datos depende por completo del cliente de IA que conecte:
- Conecta un cliente de IA en la nube (por ejemplo, Claude Desktop). Para responder a sus solicitudes, ese cliente envía la información pertinente —incluidas las partes de su proyecto que el asistente lee— a su propio proveedor de IA. Esto se rige por su propio acuerdo con dicho proveedor, exactamente igual que si utilizara esa IA por su cuenta. ATLAS.ti no actúa de intermediario. Esto también significa que puede conectar un servicio de IA que su institución haya aprobado o contratado (por ejemplo, en el marco de un comité de ética o de una política de TI), de modo que pueda utilizar la asistencia de IA sin incumplir sus requisitos de gobernanza de datos.
- Conecta un cliente de IA que ejecuta un modelo local (por ejemplo, LM Studio ejecutando un modelo como Gemma o Mistral en su propia máquina, o un modelo alojado por su institución). En este caso, ningún dato sale de su ordenador: el modelo se ejecuta localmente, el servidor MCP es local y su proyecto permanece en su máquina.
El siguiente diagrama muestra ambas rutas:
En resumen: sus hallazgos siguen siendo suyos. Todo lo que hace el asistente se guarda en su proyecto de ATLAS.ti —estructurado, portátil y permanente—, no queda atrapado en una sesión de chat.
La opción Desactivar funciones de IA de ATLAS.ti desactiva las funciones de IA basadas en la nube propias de ATLAS.ti: la IA conversacional, la codificación con IA y los resúmenes con IA. No desactiva el servidor MCP, que se controla por separado. Si su organización desactiva la IA en la nube de ATLAS.ti por motivos de gobernanza de datos, recuerde que la integración de MCP es independiente: que algún dato salga o no de su ordenador depende por completo del cliente de IA que conecte; un modelo local mantiene todo en su máquina, mientras que un cliente en la nube envía datos a ese proveedor.
Coste
La integración de MCP está incluida en todas las suscripciones activas de ATLAS.ti Desktop sin coste adicional. No hay ningún complemento ni tarifa aparte.
Usted aporta su propio cliente de IA. Cualquier coste de ese cliente es independiente y depende de su elección: por ejemplo, una suscripción a Claude, tarifas por uso de un proveedor de IA o, simplemente, los recursos informáticos para ejecutar un modelo local en su propio hardware. Usted es responsable de obtener y mantener las cuentas o suscripciones que requiera el cliente de IA que elija.
Para evitar confusiones, mantenga separadas estas tres cosas: la integración de MCP es gratuita y está incluida en su suscripción de Desktop; el cliente de IA lo aporta usted (como se ha descrito anteriormente); y la Transcripción automática de ATLAS.ti es un servicio de pago independiente, facturado a través de sus propios minutos de transcripción.
El uso de tokens sigue la misma división. Con la integración de MCP, todos los tokens se utilizan a través del cliente de IA que conecte, por lo que los factura ese cliente (en el caso de un proveedor en la nube) o son gratuitos (en el caso de un modelo local). Las propias funciones de IA de ATLAS.ti —la IA conversacional, la codificación con IA y los resúmenes con IA— utilizan tokens de ATLAS.ti en su lugar y no consumen los de su cliente de IA.
Primeros pasos
- Elija un cliente de IA compatible: consulte Clientes de IA probados. Recomendamos Claude Desktop.
- Conéctelo a ATLAS.ti: consulte Configurar un cliente de IA para obtener instrucciones paso a paso.
- Abra un proyecto en ATLAS.ti y empiece a pedir ayuda a su asistente.
Configurar un cliente de IA
ATLAS.ti incluye un servidor MCP integrado que se ejecuta localmente en su ordenador. Para utilizar la integración de MCP, habilite este servidor en ATLAS.ti y, a continuación, conéctele un cliente MCP. Hay tres formas de conectar un cliente:
- Uso del paquete MCP: para Claude Desktop, que se conecta utilizando el paquete de ATLAS.ti.
- Uso de LM Studio: un botón de un solo clic que abre LM Studio y añade por usted el servidor MCP de ATLAS.ti.
- Uso de una configuración HTTP manual: funciona con cualquier cliente MCP que pueda conectarse a un servidor HTTP. Los pasos siguientes utilizan Claude Code como ejemplo, pero la misma configuración se aplica a otros clientes compatibles con HTTP.
ATLAS.ti funciona con diversos clientes MCP: consulte Clientes de IA probados. Para cualquier cliente no descrito aquí, utilice la configuración HTTP que se indica más abajo y consulte la documentación propia de ese cliente para saber cómo añadir un servidor MCP.
El servidor MCP en macOS requiere macOS 15 o posterior. ATLAS.ti en sí funciona en macOS 13 y versiones posteriores, pero la integración de MCP solo está disponible en macOS 15 y versiones superiores.
Habilitar el servidor MCP
Sea cual sea el método de conexión que utilice, habilite primero el servidor MCP en ATLAS.ti.
En ATLAS.ti, abra Ajustes y, en la sección Servidor Model Context Protocol, active Activar el servidor MCP.
Uso del paquete MCP (Claude Desktop)
El paquete MCP (un archivo .mcpb) es la forma más fácil de conectar Claude Desktop. Este método de paquete es específico de Claude Desktop; para otros clientes, consulte Uso de LM Studio o Uso de una configuración HTTP manual más abajo.
En Ajustes de ATLAS.ti, en la sección Servidor Model Context Protocol, haga clic en Añadir a Claude Desktop… junto a Instalar el paquete MCP.
Claude Desktop se abre y le pide que instale la extensión. Haga clic en Instalar y, en la ventana emergente de confirmación, vuelva a hacer clic en Instalar para completar la instalación.
Es posible que Claude Desktop le pida que instale las herramientas de desarrollo de línea de comandos. Esta solicitud proviene de Claude Desktop, no de ATLAS.ti, y puede cancelarla: estas herramientas no son necesarias para el servidor MCP de ATLAS.ti.
Si ya tenía instalada una versión anterior del paquete MCP, haga lo siguiente en Claude: vaya a Archivo > Configuración > Extensiones > Configuración avanzada > Instalar extensión, haga clic en Desinstalar y, a continuación, haga clic en Instalar para instalar la nueva versión.
Una vez completada la configuración, inicie ATLAS.ti e introduzca una indicación en su cliente para que enumere todos sus proyectos de ATLAS.ti. El cliente debería enumerar todos sus proyectos.
Uso de LM Studio
LM Studio puede conectarse al servidor MCP de ATLAS.ti con un solo clic. ATLAS.ti añade por usted la configuración del servidor a LM Studio, por lo que no se necesita ninguna configuración manual.
En Ajustes de ATLAS.ti, en la sección Servidor Model Context Protocol, haga clic en Añadir a LM Studio… junto a Instalar el servidor MCP.
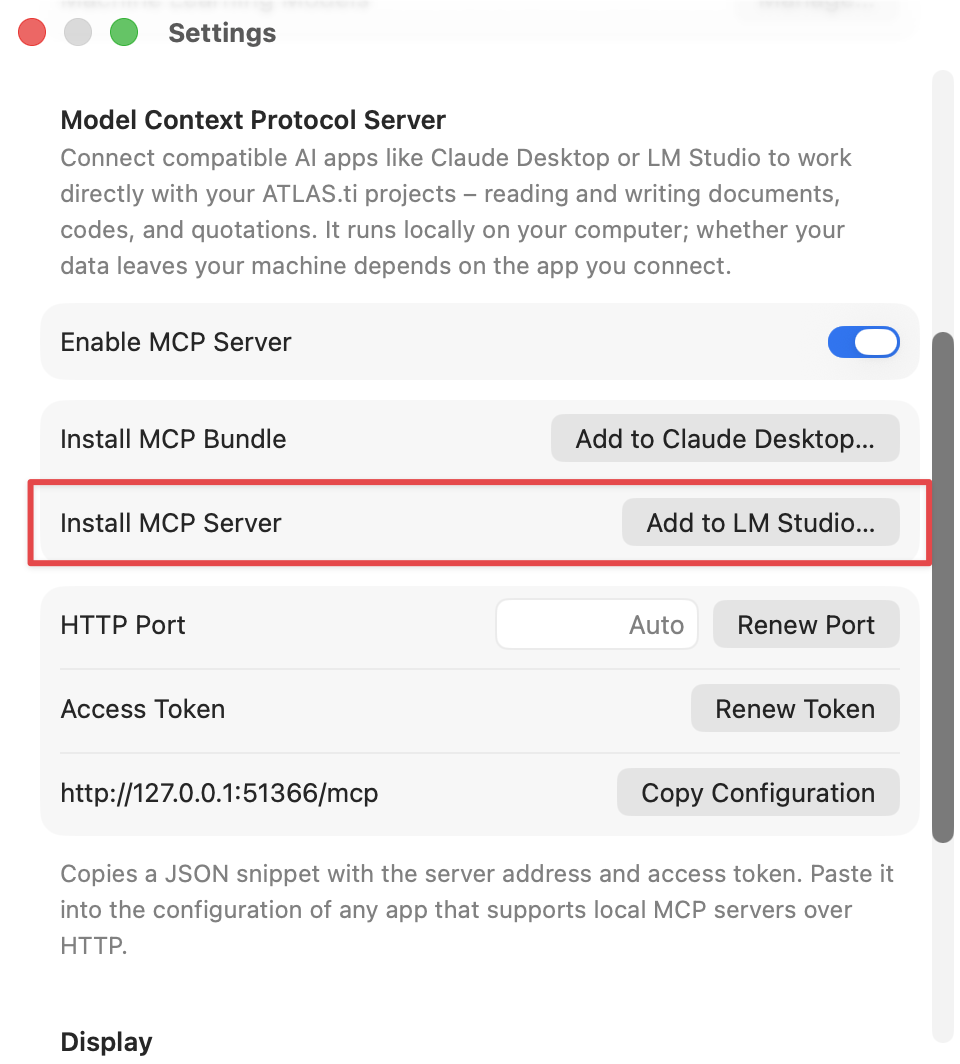
LM Studio se abre y añade automáticamente el servidor MCP de ATLAS.ti. Confirme la solicitud en LM Studio si se le pide.
En LM Studio, elija un modelo que admita el uso de herramientas (llamada a funciones). La integración de MCP depende del uso de herramientas, por lo que un modelo que no lo admita no puede trabajar con sus proyectos de ATLAS.ti.
Una vez completada la configuración, inicie ATLAS.ti e introduzca una indicación en LM Studio para que enumere todos sus proyectos de ATLAS.ti. LM Studio debería enumerar todos sus proyectos.
Uso de una configuración HTTP manual
El servidor MCP de ATLAS.ti también expone un punto de conexión HTTP local, de modo que cualquier cliente MCP que pueda conectarse a un servidor HTTP puede utilizarlo. En general, conectar otro cliente implica: habilitar el servidor MCP en ATLAS.ti (está desactivado de forma predeterminada; consulte Habilitar el servidor MCP más arriba), instalar y configurar su cliente de IA compatible con MCP, configurarlo para que se conecte al servidor MCP de ATLAS.ti utilizando la configuración que se indica a continuación y, por último, abrir un proyecto de ATLAS.ti e interactuar con él a través del cliente.
Los pasos siguientes utilizan Claude Code como ejemplo práctico; la misma configuración funciona con otros clientes compatibles con HTTP (por ejemplo, OpenAI Codex, Goose o la CLI de Gemini). Consulte la documentación de su cliente para saber dónde añadir un servidor MCP.
Paso 1: Copiar la configuración del servidor MCP desde ATLAS.ti
En ATLAS.ti, abra Ajustes y haga clic en Copiar configuración.
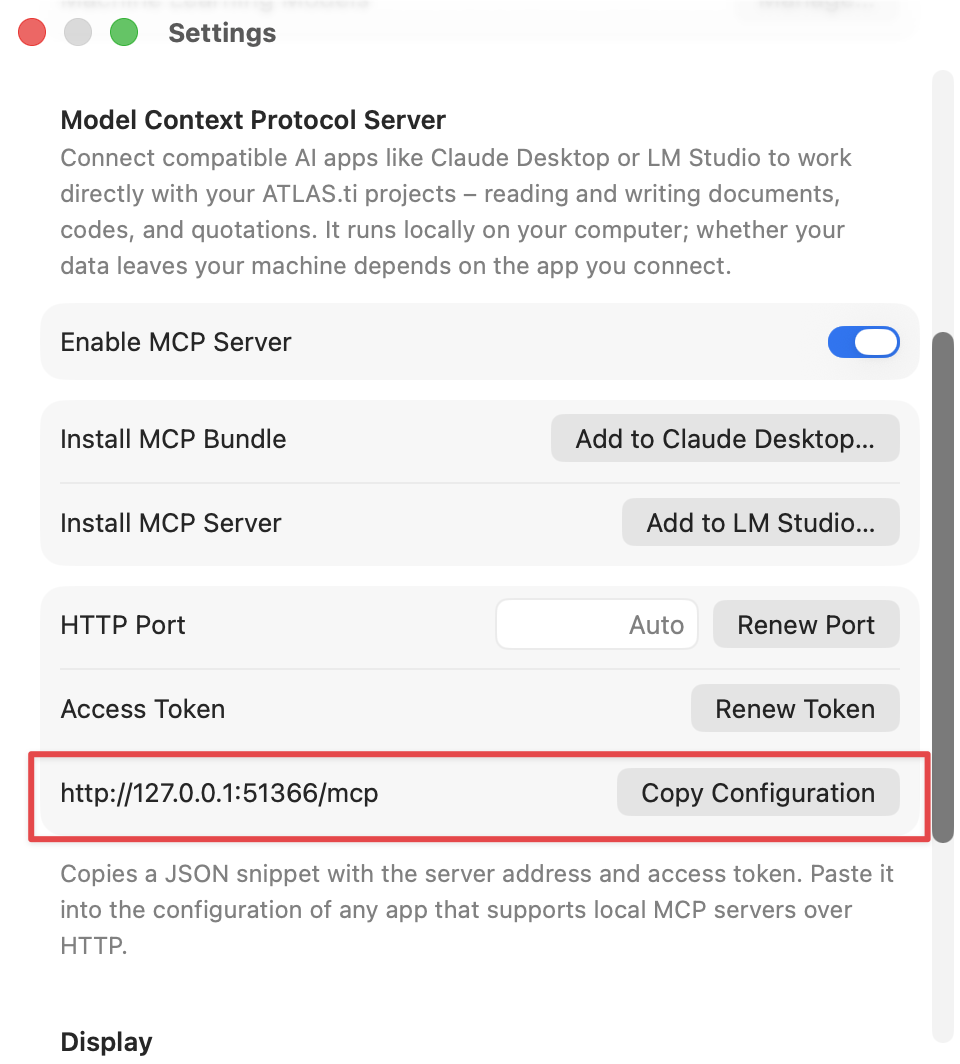
Tenga a mano los detalles de la configuración (por ejemplo, en un editor de texto), ya que los necesitará en el siguiente paso. Aquí tiene un ejemplo de configuración:
{
"mcpServers": {
"ATLAS.ti": {
"headers": {
"Authorization": "Bearer YFNqUs+T2o5ZZljQsTYrTF6eAhgzj6NQVG0Kf0IZwXg="
},
"type": "http",
"url": "http://127.0.0.1:57000/mcp"
}
}
}
Paso 2: Añadir la configuración a su cliente
Cada cliente tiene su propia forma de registrar un servidor MCP. Utilice la configuración del Paso 1 y siga la documentación de su cliente.
Para Claude Code, que puede utilizar como ejemplo representativo de otros clientes HTTP:
Si aún no tiene Claude Code, instálelo siguiendo la Guía de inicio rápido.
Añada el servidor MCP de ATLAS.ti siguiendo las instrucciones de Conectarse a servidores MCP.
Clientes de IA probados
La integración de MCP en ATLAS.ti se basa en el Model Context Protocol, un estándar abierto, por lo que puede probarla con el cliente de IA que prefiera. MCP está diseñado en torno a clientes de IA que pueden conectarse a un servidor MCP local, y la compatibilidad puede variar de un cliente a otro según cómo implemente cada uno el protocolo.
Los clientes que se enumeran a continuación son los que el equipo de ATLAS.ti ha probado y confirmado que funcionan. Iremos actualizando esta lista a medida que validemos clientes adicionales.
Última actualización: 2026-07-03
Esta lista se ofrece únicamente con fines informativos y refleja los clientes que hemos verificado en el momento de redactar este texto. El soporte de ATLAS.ti cubre el propio servidor MCP de ATLAS.ti; la configuración y el comportamiento de los clientes de IA de terceros quedan fuera del alcance del soporte del producto. Si necesita ayuda para configurar un cliente concreto, consulte la documentación propia de ese cliente. Para obtener la experiencia más fiable, recomendamos Claude Desktop.
| Cliente | Tipo |
|---|---|
| Claude Desktop (recomendado) | Aplicación de escritorio |
| Claude Code | Línea de comandos |
| OpenAI Codex | Aplicación de escritorio + línea de comandos |
| Google Antigravity | Aplicación de escritorio + línea de comandos |
| Google Gemini | Línea de comandos (CLI de Gemini) |
| Goose | Aplicación de escritorio |
| LM Studio | Aplicación de escritorio |
La integración de MCP funciona igual tanto en Windows como en macOS.
Claude Desktop es nuestro cliente principal y recomendado: es ampliamente utilizado y ofrece una instalación sencilla, con un solo clic, a través del paquete MCP. Consulte Configurar un cliente de IA para obtener instrucciones paso a paso.
¿Utiliza ChatGPT? ChatGPT es uno de los asistentes de IA más conocidos, pero actualmente no puede conectarse a ATLAS.ti. ChatGPT solo se conecta a servidores MCP alojados públicamente en internet, mientras que ATLAS.ti ejecuta su servidor MCP localmente en su ordenador para mantener la privacidad de sus datos. Esta es una limitación del cliente ChatGPT, no de ATLAS.ti. Reconsideraremos ChatGPT a medida que evolucionen sus capacidades.
Análisis de Grupos Focales
En términos generales, puede afirmarse que el análisis de datos de grupos focales no difiere mucho del análisis de cualquier otro tipo de datos de entrevistas. La mayoría de las personas que solicitan herramientas analíticas específicas para grupos focales lo hacen porque no tienen experiencia en el análisis de otros tipos de datos cualitativos y creen que debe haber algo único en los grupos focales.
Los grupos focales son diferentes hasta cierto punto, ya que existe más interacción. En la gran mayoría de los estudios, los investigadores están interesados en el contenido de lo que se dice, más que en los mecanismos de cómo se dice.
Si le interesa la interacción, entonces el análisis del discurso podría ser un método apropiado. Además de las herramientas habituales que utiliza en ATLAS.ti para el análisis de datos, considere el uso de hipervínculos para explorar la interacción: Nivel de cita e Hipervínculos.
Los métodos de análisis más utilizados tanto para datos de entrevistas como de grupos focales son versiones del análisis de contenido y el análisis temático. Para inspirarse, consulte este capítulo sobre análisis de grupos focales.
ATLAS.ti facilita la codificación de unidades de participante, de modo que puede comparar las respuestas de diferentes hablantes o diferentes grupos de hablantes según atributos como edad, género, etc.
Para que ATLAS.ti reconozca a los hablantes, es necesario usar identificadores o nombres de participantes de forma coherente al transcribir los datos. Consulte Directrices para la preparación de datos de grupos focales para obtener más detalles.
La codificación automática de grupos focales requiere documentos de texto en formato doc, docx, rtf o txt. No es posible usar documentos PDF con esta función.
Directrices para la preparación de datos de grupos focales
Solo hay un requisito al preparar datos de grupos focales: cada hablante debe tener un identificador único, y este identificador debe aplicarse de forma coherente a lo largo de toda la transcripción.
ATLAS.ti ofrece dos patrones predeterminados para reconocer hablantes:
- nombre: (patrón 1)
- @nombre: (patrón 2)
Al usar el patrón 2 al transcribir los datos, es poco probable que ATLAS.ti encuentre algo que no sean hablantes. Al buscar con el patrón 1, ATLAS.ti también puede encontrar elementos como "por ejemplo:....."
Patrón personalizado
También puede definir su propio patrón, incluido el uso de expresiones regulares.
Esto puede ser útil si ha preparado transcripciones previamente y los identificadores de hablantes no se han utilizado de forma coherente.
Por ejemplo, la expresión regular: To+(m|n) coincide con "Toom", "Ton" o "Toon" para encontrar diferentes grafías del nombre "Tom".
([A-Z]+): reconoce identificadores formados por letras de la A a la Z.
([A-Z]+[0-9]+): reconoce identificadores compuestos por una combinación de letras y números.
Para obtener más información, consulte Expresiones regulares (GREP).
Puede usar esta funcionalidad para codificar automáticamente cualquier dato que tenga una estructura específica. No tiene que ser necesariamente un hablante; podría ser una fecha, un número o cualquier otro tipo de identificador.
Transcripciones de ejemplo
Los identificadores de hablante no tienen que estar en negrita. Aquí se utilizan letras en negrita únicamente para facilitar la identificación de los identificadores de hablante.
Ejemplo A (patrón 1)
Alex: No lo sé, soy del tipo, no me cuesta mucho hacer amigos porque todos me dicen que tengo una boca grande y no paro de hablar [risas]
Tom: ¿Así fue como os conocisteis, simplemente porque tú iniciaste una conversación?
Deb: Estoy intentando recordar exactamente [risas] Creo que así fue, los dos estábamos en la misma clase de métodos de investigación...
Ejemplo B (patrón 1)
Alex:
No lo sé, soy del tipo, no me cuesta mucho hacer amigos porque todos me dicen que tengo una boca grande y no paro de hablar [risas].
Tom:
¿Así fue como os conocisteis, simplemente porque tú iniciaste una conversación?
Deb:
Estoy intentando recordar exactamente [risas] Creo que así fue, los dos estábamos en la misma clase de métodos de investigación.
Ejemplo C (patrón 1)
También es posible agregar información adicional a cada hablante, como su género, grupo de edad, nivel educativo, etc. De esta manera, esta información también se codificará automáticamente.
Alex: hombre: grupo de edad 1: bachillerato:
No lo sé, soy del tipo, no me cuesta mucho hacer amigos porque todos me dicen que tengo una boca grande y no paro de hablar [risas]
Tom: hombre: grupo de edad 2: bachillerato:
¿Así fue como os conocisteis, simplemente porque tú iniciaste una conversación?
Deb: mujer: grupo de edad 2: universidad:
Estoy intentando recordar exactamente [risas] Creo que así fue, los dos estábamos en la misma clase de métodos de investigación.
Ejemplo D (patrón 2)
@Alex: No lo sé, soy del tipo, no me cuesta mucho hacer amigos porque todos me dicen que tengo una boca grande y no paro de hablar [risas].
@Tom: ¿Así fue como os conocisteis, simplemente porque tú iniciaste una conversación?
@Deb: Estoy intentando recordar exactamente [risas] Creo que así fue, los dos estábamos en la misma clase de métodos de investigación.
Si sus datos aún no han sido transcritos, se recomienda utilizar el patrón 2, ya que es poco probable que este patrón encuentre secciones que no sean unidades de participante.
Recomendación
Para mayor legibilidad, puede considerar comenzar cada unidad de participante en una línea nueva.
Además, puede agregar una línea en blanco entre unidades de participante.
Ninguna de las dos opciones es obligatoria. Cuando se reconoce un patrón, los códigos seleccionados se aplican desde la primera letra del patrón hasta el inicio del siguiente patrón reconocido. Por lo tanto, no importa si una nueva unidad comienza en una línea nueva o si hay una línea en blanco entre ellas.
Codificación automática de hablantes en grupos focales
La codificación automática de grupos focales requiere documentos de texto en formato doc, docx, rtf o txt. No es posible usar documentos PDF con esta función.
Seleccione una transcripción de grupo focal en el Explorador de proyecto o en el Administrador de documentos. En el menú principal, seleccione Código > Codificación de grupo focal. Como alternativa, haga clic derecho en un documento y seleccione Codificación de grupo focal en el menú contextual.
A continuación, seleccione un patrón para reconocer las unidades de participante. Consulte Preparación de datos de grupos focales.
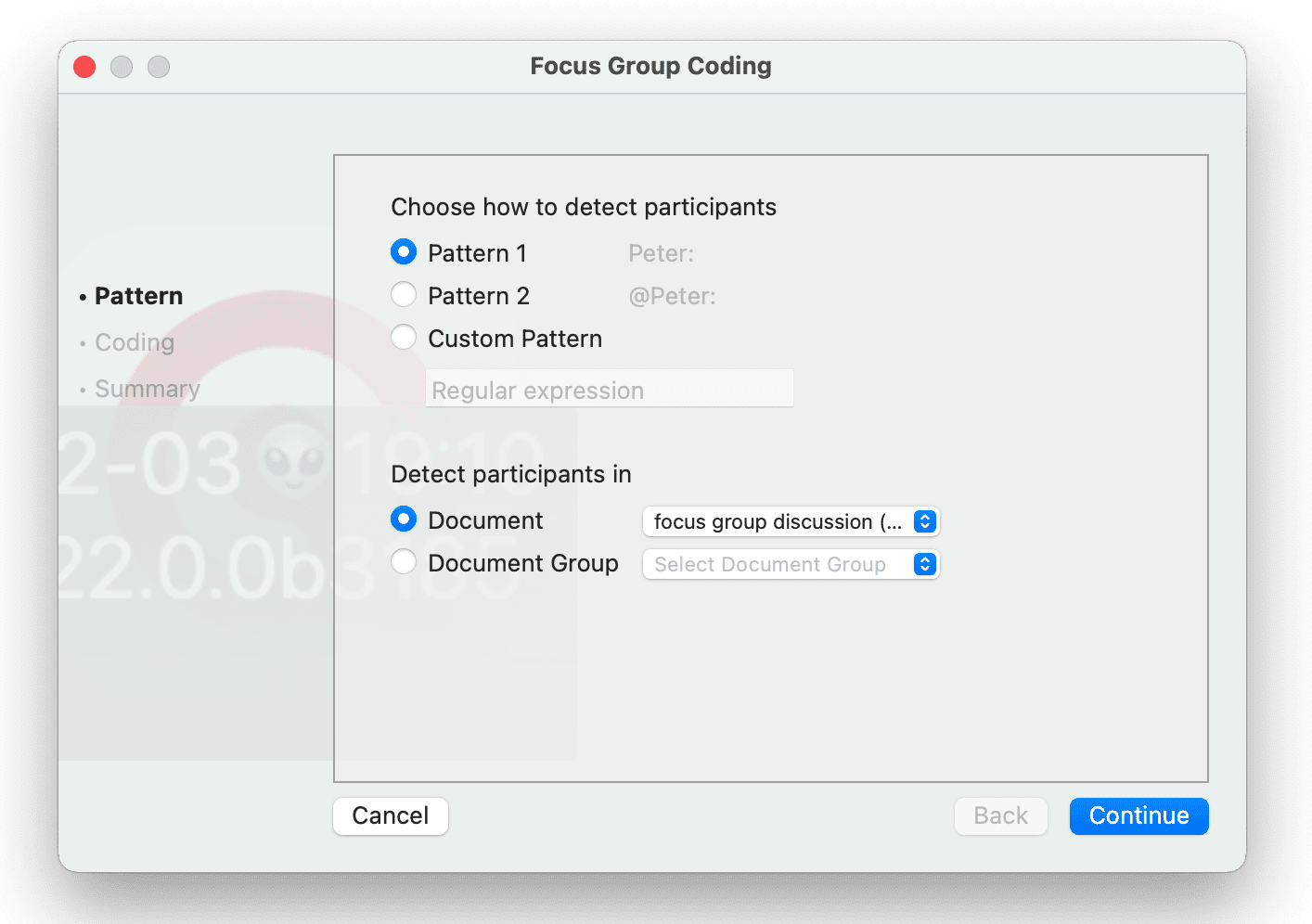
Tras seleccionar un patrón, haga clic en Continuar.
ATLAS.ti enumera todas las cadenas que se ajustan al patrón seleccionado y las usa como nombre de código. Si se utilizó un signo de dos puntos (:) en otras partes de la transcripción, no todos los resultados encontrados serán hablantes.
Deseleccione todos los resultados que no sean hablantes, si los hubiera.
Verifique los códigos sugeridos y modifique los nombres si lo desea.
Agregue códigos adicionales si desea codificar las unidades de participante con múltiples códigos. Cada código debe estar separado por un punto y coma.
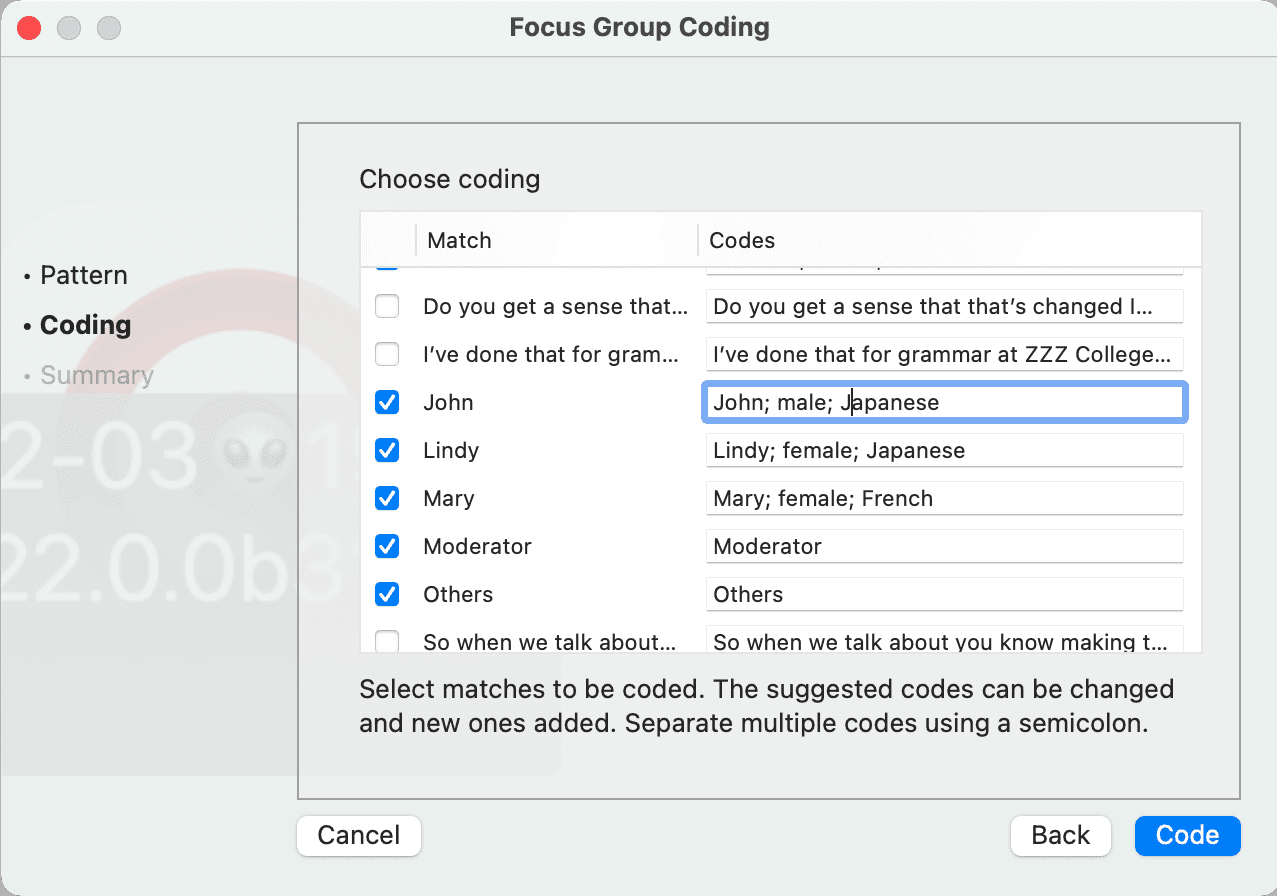
Si introduce códigos que ya existen en su lista de códigos, no se duplicarán.
Haga clic en el botón Codificar.
ATLAS.ti codifica todas las unidades de participante. Una vez finalizado el proceso, aparece una pantalla de resumen.
Verifique los resultados en contexto y consulte el Administrador de códigos. ATLAS.ti también crea un grupo de códigos con todos los códigos. Si los resultados no son los esperados, puede deshacer toda la codificación en esta etapa.
ATLAS.ti no organiza automáticamente el grupo focal en una estructura jerárquica de forma predeterminada. Sin embargo, se recomienda hacerlo manualmente, de manera similar al ejemplo que se muestra a continuación:
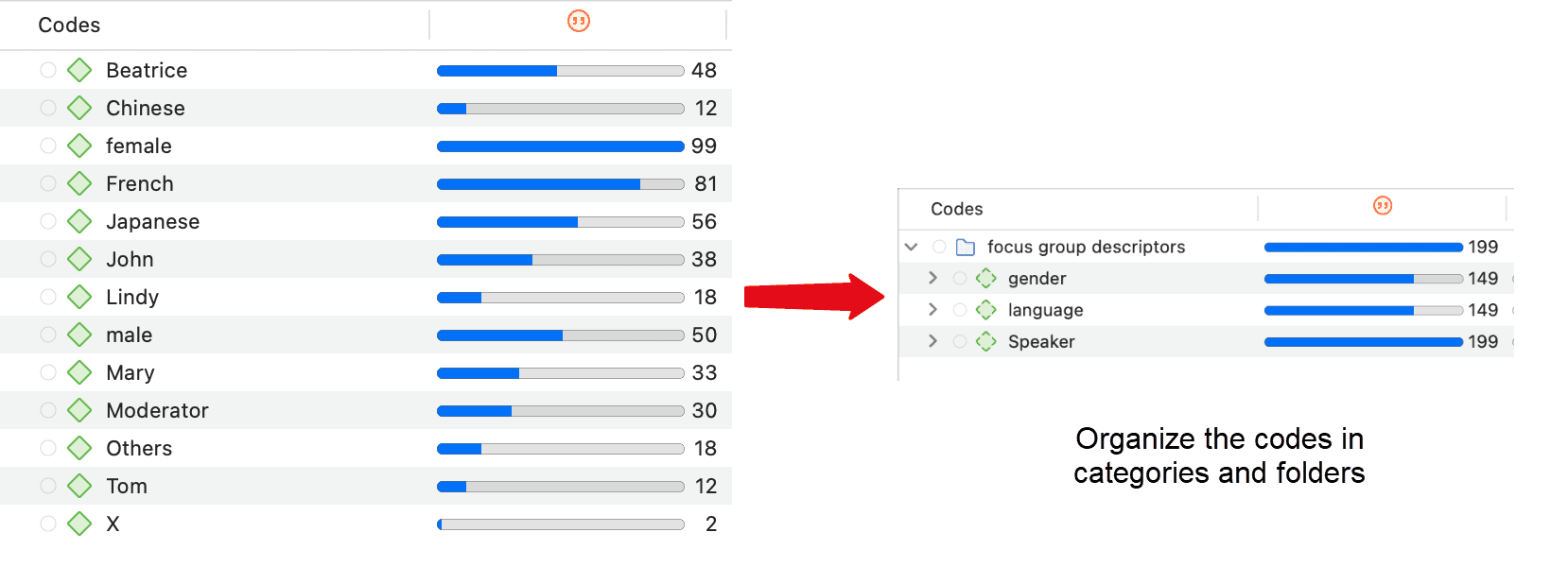
Dado que codificar todos los hablantes suele generar una codificación densa, se recomienda utilizar esta función después de haber codificado el contenido de la transcripción del grupo focal.

Datos multimedia (audio y video)
Cuando nos referimos a datos multimedia, nos referimos a archivos de audio y video. La diferencia en cuanto a la visualización de archivos de audio o video es que no hay imagen al trabajar con archivos de audio; los clics del ratón en el manejo de archivos de audio son los mismos. Por tanto, a continuación describimos todos los pasos para ambos formatos conjuntamente. A modo ilustrativo, la mayoría de las figuras muestran datos de video.
Agregar documentos multimedia a un proyecto
Dado que los archivos multimedia, especialmente los de video, pueden ser bastante grandes, se recomienda vincular los archivos multimedia a un proyecto en lugar de importarlos.
Para vincular archivos de audio o video a un proyecto, seleccione Documento > Referenciar documento multimedia externo en el menú principal.
Los documentos vinculados permanecen en su ubicación original y ATLAS.ti accede a ellos desde allí. Preferiblemente, estos archivos no deberían moverse a una ubicación diferente. Si es necesario moverlos, deberá volver a vincularlos al proyecto. ATLAS.ti le avisará si hay algún problema y un archivo ya no es accesible.
Visualización de documentos multimedia
Forma de onda de audio: En el lateral derecho se muestra la forma de onda de audio.
Imágenes de vista previa: Para los archivos de video, las imágenes de vista previa se muestran en la vista previa completa debajo del video y en el área del margen. Para verlas, pase el ratón sobre la forma de onda de audio vertical u horizontal.
Cabezal de reproducción: El cabezal de reproducción, en forma de línea roja, muestra la posición actual en el archivo de video o audio.
Zoom: Dado que el espacio de arriba abajo en la pantalla de su ordenador será demasiado pequeño en la mayoría de los casos para mostrar de forma significativa el archivo de audio o video, especialmente si está codificado, puede ampliar el archivo utilizando las técnicas estándar Opción-Comando-Signo más (+), Opción-Comando-Signo más (-), o en el panel táctil pellizcar con dos dedos para acercar o alejar.
Controles multimedia
Para iniciar y detener el audio o video, presione la barra espaciadora.
Barra de herramientas multimedia
Velocidad de reproducción: Si desea que el video se reproduzca más rápido o más lento, puede seleccionar una velocidad de reproducción entre 0,25 veces la velocidad original y 10 veces la velocidad original.
Marcar posición de inicio de cita: Establece la posición de inicio de una cita. La tecla de acceso directo es , (coma). Consulte Trabajar con archivos multimedia.
Crear cita: Establece la posición final de una cita y crea la cita al mismo tiempo. La tecla de acceso directo es . (punto). Consulte Trabajar con archivos multimedia.
Agregar una instantánea de video
Si desea analizar una situación concreta de sus datos de video con más detalle, puede crear una instantánea a partir de ella. La instantánea se agregará como nuevo documento de imagen a su proyecto.
Cargue un documento de video y muévase a la posición deseada en el video. Haga clic en el botón Instantánea de la barra de herramientas.
Manejo de datos multimedia
Ampliar la línea de tiempo
Puede ampliar el archivo utilizando las técnicas estándar cmd y (+) para alejar, cmd y (-) para acercar; o en el panel táctil pellizcar con dos dedos para acercar o alejar.
Usar las teclas de flecha para navegar
-
Use las teclas de flecha derecha e izquierda para mover la posición del cabezal de reproducción en incrementos de 1/1000 de la longitud del documento de audio/video.
-
Use las teclas de flecha arriba y abajo + cmd para mover la posición del cabezal de reproducción en incrementos de 1/20 de la longitud del documento de audio/video.
-
Haga clic en cmd + la tecla de flecha izquierda para reproducir el audio/video hacia atrás.
-
Haga clic en cmd + la tecla de flecha derecha para reproducir el audio/video a doble velocidad.
Atajos de teclado
| Acción | Atajo de teclado |
|---|---|
| Pausar/Reproducir | Espacio |
| Paso pequeño adelante | Tecla de flecha derecha |
| Paso grande adelante | cmd + tecla flecha abajo |
| Paso grande atrás | cmd + tecla flecha arriba |
| Aumentar velocidad de reproducción | cmd + tecla flecha derecha |
| Reproducir hacia atrás | cmd + tecla flecha izquierda |
| Alejar | cmd + (+) |
| Acercar | cmd + (-) |
Trabajar con datos multimedia
En esta sección se describen las siguientes opciones:
- Crear citas multimedia
- Crear citas multimedia mientras se escucha el archivo de audio o se visualiza el archivo de video
- Visualización de citas multimedia
- Codificar citas multimedia
- Activar y reproducir citas multimedia
- Ajustar el tamaño de las citas multimedia
- Renombrar una cita multimedia
- Capturar instantáneas de fotogramas de video como documentos de imagen para análisis adicional
Crear citas multimedia
También puede codificar archivos multimedia de forma inmediata. Sin embargo, dado que los archivos de video especialmente contienen mucha más información en comparación con el texto, a menudo resulta más sencillo recorrer y segmentar primero el archivo de audio o video, es decir, crear citas antes de codificar.
Para crear una cita de audio o video, mueva el puntero del ratón sobre la forma de onda de audio y marque una sección haciendo clic con el botón izquierdo del ratón donde desee que comience. Luego arrastre el cursor hasta la posición final. Se muestran los tiempos de las posiciones de inicio y fin, así como la duración total del segmento.
En cuanto suelte el ratón, se crea una cita y verá el límite azul de la cita en el área del margen.
Crear citas multimedia mientras escucha/visualiza
También puede crear una cita de audio o video mientras escucha o visualiza un documento. Para ello, puede utilizar los botones Marcar inicio de cita y Crear cita de la barra de herramientas sobre la línea de tiempo, o las teclas de acceso directo (véase más abajo).
Continúe escuchando o visualizando, y estableciendo citas.
Usar teclas de acceso directo
Para marcar la posición de inicio: use (<) o (,)
Para crear una cita: use (>) o (.)
La tecla de acceso directo que debe usar depende de su teclado. Use aquellas teclas para las que no tenga que usar Mayús.
Reproduzca el video. Si encuentra algo interesante que desee marcar como cita, haga clic en la tecla (,) o (<). Esto establece la posición de inicio.
Para establecer la posición final y crear una cita, haga clic en la tecla (.) o (>).
-
Una nueva cita aparecerá en el Administrador de citas, el Explorador de proyectos o el Navegador de citas. El ID de la cita consiste en el número del documento más un contador consecutivo en orden cronológico según el momento en que se creó la cita en el documento. El ID de cita 15:5, por ejemplo, significa que es una cita en el documento 15 y fue la quinta cita creada en dicho documento.
-
Después del ID se muestra la referencia de la cita, que es la posición de inicio de la cita de audio o video. El campo de nombre está vacío. Puede, por ejemplo, agregar un título breve para cada cita multimedia; véase más abajo.
-
Dependiendo del tipo de medio, el icono de la cita cambia.
Las citas de audio y video se reconocen fácilmente por su icono especial.
Codificar citas multimedia
Codificar citas multimedia no es diferente a codificar documentos de texto o imagen:
Haga clic derecho en la cita y seleccione Aplicar códigos. Para obtener más información, consulte: Codificar datos.
Activar y reproducir citas multimedia
En el área del margen
Para reproducir la cita, haga doble clic en la barra de cita, o pase el ratón sobre la forma de onda de audio y haga clic en el icono de reproducción.
Puede mover el cabezal de reproducción a cualquier posición dentro de un archivo de audio o video desplazándose.
Desde otros lugares
-
Al hacer doble clic en una cita multimedia en el Explorador de proyectos, el Navegador de citas o el Administrador de citas, el documento multimedia se abre en la posición donde comienza la cita. Haga clic en la barra espaciadora para reproducirla.
-
Puede obtener una vista previa de una cita multimedia en el área de vista previa del Administrador de citas o del Lector de citas.
-
Puede obtener una vista previa de una cita multimedia en una red.
-
Puede obtener una vista previa de una cita multimedia si forma parte de un hipervínculo. Consulte Trabajar con hipervínculos.
Ajustar el tamaño de las citas multimedia
Para ajustar o cambiar la duración de la cita, arrastre la posición de inicio o fin hasta la posición deseada.
Renombrar una cita multimedia
Si agrega nombres a las citas multimedia, estos pueden servir como títulos. En el comentario de la cita pueden añadirse resúmenes breves. Esto permite crear un resultado de texto significativo para los segmentos de audio y video.
Seleccione una cita multimedia y añada un nombre en el inspector.
Utilice el área de comentario para añadir más información, por ejemplo, describir el segmento y ofrecer una primera interpretación.
Consulte también Aprovechamiento del nombre y comentario de la cita con fines analíticos.
Capturar instantáneas de fotogramas de video como documentos de imagen
Si desea analizar fotogramas concretos de su video con más detalle, puede capturar una instantánea.
Mueva el cabezal de reproducción a la posición deseada en el video.
Haga clic en el icono de cámara en la barra de herramientas.
La instantánea se agrega automáticamente como nuevo documento de imagen a su proyecto. Consulte Crear citas en imágenes para obtener más información sobre cómo trabajar con archivos de imagen.
Preferencias multimedia
En Archivo > Opciones, puede establecer preferencias específicas del proyecto para los archivos multimedia:
Vista previa automática
El efecto de la Vista previa automática es que la cita de audio o video comienza a reproducirse inmediatamente cuando se activa o abre una función.
-
Al seleccionar vista previa automática para documentos, la cita multimedia comienza a reproducirse inmediatamente al seleccionar un documento multimedia en el Administrador de documentos.
-
Al seleccionar vista previa automática para citas, la cita multimedia comienza a reproducirse inmediatamente al seleccionar un documento multimedia en el Administrador de citas.
-
Al seleccionar vista previa automática para hipervínculos, la cita multimedia comienza a reproducirse inmediatamente al activar un hipervínculo.
Preferencias para crear citas
La opción predeterminada es que una cita multimedia se crea en cuanto se realiza una selección en la forma de onda de audio. Si prefiere realizar primero una selección antes de crear una cita con un clic adicional del ratón, desactive esta opción.
El área del margen
El área del margen en ATLAS.ti es un espacio de trabajo importante. No solo sirve para mostrar entidades vinculadas a los datos, como códigos, memos, hipervínculos, grupos o redes; también es un espacio donde puede interactuar con sus datos, escribir y revisar comentarios, vincular y desvincular códigos, moverlos, reemplazarlos, recorrer hipervínculos, y otras acciones similares.
Dependiendo de la actividad actual, puede establecer diversas opciones de visualización.
Arrastrar y soltar en el margen
Todos los objetos del área del margen admiten arrastrar y soltar. El efecto de una operación de arrastrar y soltar depende de las entidades que participan como origen del arrastre (las que se arrastran) y como destino (aquellas sobre las que se sueltan las entidades).
Existe una gran variedad de entidades del área del margen que pueden soltarse en el área del margen.
Además, las entidades también pueden arrastrarse desde otros administradores de entidades y navegadores. Las entidades pueden arrastrarse desde el margen hacia otras ventanas, navegadores o incluso otras aplicaciones como Word. En este último caso, las entidades de ATLAS.ti pierden su «objetividad» específica de ATLAS.ti, pero al menos se convierten en algo útil, por ejemplo, un título con formato y un comentario de texto enriquecido.
-
Arrastrar y soltar códigos: Cuando arrastra un código desde una lista de códigos o el área del margen y lo suelta sobre otro código en el área del margen, tiene la opción de reemplazarlo o fusionarlo.
-
Arrastrar y soltar citas: Cuando arrastra y suelta una cita sobre otra cita, puede vincular las citas (consulte Crear hipervínculos) o fusionarlas.
-
Arrastrar y soltar memos: Cuando arrastra y suelta un memo sobre una cita, código u otro memo, vincula el memo a la entidad correspondiente.
Imprimir con margen
Puede imprimir el documento tal como aparece en la pantalla, con numeración de párrafos y el área del margen.
Cargue el documento y seleccione Proyecto > Imprimir. Puede seleccionar el tamaño del papel, la orientación y el ancho del margen. Al cambiar la configuración, puede ver cómo quedará el documento en la vista previa.
Puede guardar el resultado en formato PDF o imprimirlo.
Memos y comentarios
Tutorial en video: Uso de memos al inicio del proyecto.
Memos
«Los memos y los diagramas son mucho más que simples repositorios de pensamientos. Son documentos vivos y activos. Cuando un analista se sienta a escribir un memo o elaborar un diagrama, se produce cierto nivel de análisis. El propio acto de escribir memos y hacer diagramas obliga al analista a reflexionar sobre los datos. Y es en esa reflexión donde ocurre el análisis» (Corbin & Strauss: 118).
«Escribir es pensar. Es natural creer que primero hay que tener clara en la mente la idea que se quiere expresar antes de poder escribirla. Sin embargo, la mayoría de las veces ocurre lo contrario. Puede creer que tiene una idea clara, pero solo cuando la escribe puede estar seguro de que así es (o, lamentablemente, a veces de que no lo es)» (Gibbs, 2005).
Como se aprecia en las citas anteriores, la escritura de memos es una tarea importante en cada fase del proceso de análisis cualitativo. Gran parte del análisis «ocurre» cuando se escriben los hallazgos, no al hacer clic en botones del software.
Las ideas recogidas en los memos suelen ser las piezas de un rompecabezas que más tarde se ensamblan en la fase de redacción del informe.
La construcción de teoría, frecuentemente asociada a la elaboración de redes, también implica la escritura de memos.
Los memos en ATLAS.ti pueden ser simplemente un texto independiente o pueden vincularse a otras entidades como citas, códigos u otros memos.
Usos típicos de los memos
-
Los memos pueden contener una descripción del proyecto.
-
Puede listar todas las preguntas de investigación en un memo.
-
Puede utilizar memos para escribir un diario de investigación.
-
Puede utilizar un memo como lista de tareas pendientes.
-
Los memos pueden usarse como tablón de anuncios para intercambiar información entre los miembros del equipo.
-
Puede almacenar definiciones, hallazgos o teorías de la literatura relevante en uno o más memos.
-
Puede redactar su análisis utilizando memos. Esos memos serán los bloques de construcción de su informe de investigación.
Los memos también pueden asignarse como documentos si desea codificarlos. Consulte Usar memos como documento.
Memos y comentarios
Desde el punto de vista metodológico, los comentarios también son memos en el sentido de que ambos son espacios para pensar y escribir.
En términos técnicos, en ATLAS.ti existe una distinción entre comentarios y memos, ya que los comentarios pertenecen exclusivamente a una entidad. Por ejemplo, el comentario de un documento forma parte del documento; un comentario de código pertenece a un código particular y suele ser una definición de dicho código. Un comentario de cita contiene notas o interpretaciones sobre la cita a la que pertenece.
Los comentarios no se muestran en los navegadores de forma independiente de la entidad a la que están vinculados.
Los memos de ATLAS.ti, en comparación,
-
pueden ser independientes o pueden vincularse a otras entidades.
-
Puede escribir un comentario para un memo, por ejemplo: usar este memo para la sección 2 del capítulo 4 de mi tesis.
Usos típicos de los comentarios
A continuación se enumeran algunas ideas sobre para qué puede utilizar los comentarios:
Comentario del proyecto
- descripción del proyecto
Comentario del documento
- Metainformación sobre un documento: fuente, dónde y cómo lo encontró o generó
- Protocolos de entrevista
La información sobre un participante, como género, edad, profesión, etc., se gestiona mejor mediante grupos de documentos. No es necesario escribir este tipo de información en el campo de comentario.
Comentario de cita
- interpretaciones que solo conciernen a un segmento de datos específico
- ideas sobre cómo una cita podría relacionarse con otra
- resúmenes de lo que escucha o ve en la cita multimedia
- interpretaciones de citas de imagen
- notas sobre una posición geográfica

Comentario de código
- primeras ideas sobre lo que significa un código
- una definición del código
- una regla de codificación, especialmente cuando se trabaja en equipo
- un ejemplo del tipo de datos que pueden codificarse con este código
- resumen de los segmentos codificados
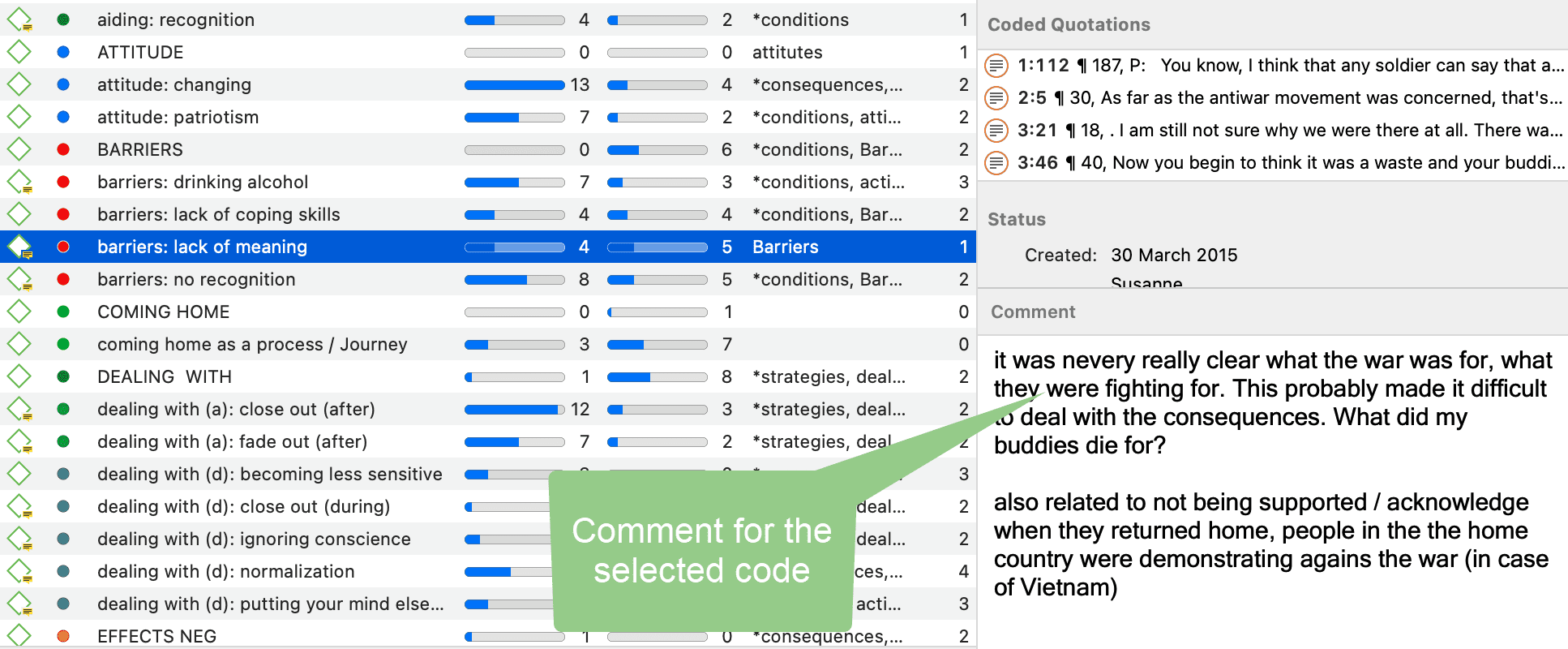
Comentario de memo
- nota para usted mismo sobre dónde desea utilizar el memo en un informe
- comentarios de supervisores o miembros del equipo
- vínculos o notas sobre literatura relevante
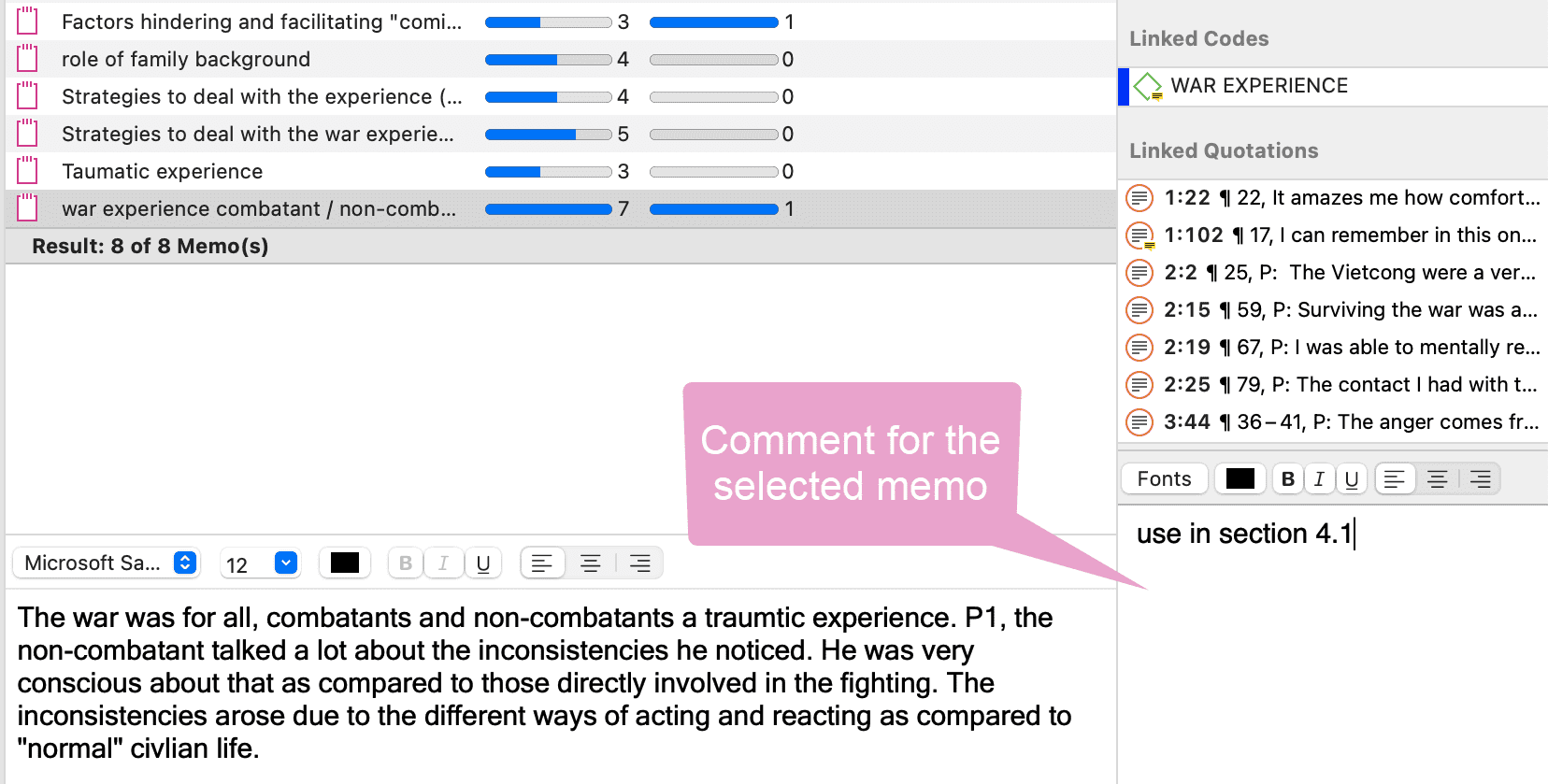
Comentario de red
- descripción de la red
- idea sobre cómo desea desarrollarla más
Comentario de vínculo
- Explicación de por qué las dos entidades están vinculadas de una manera específica.
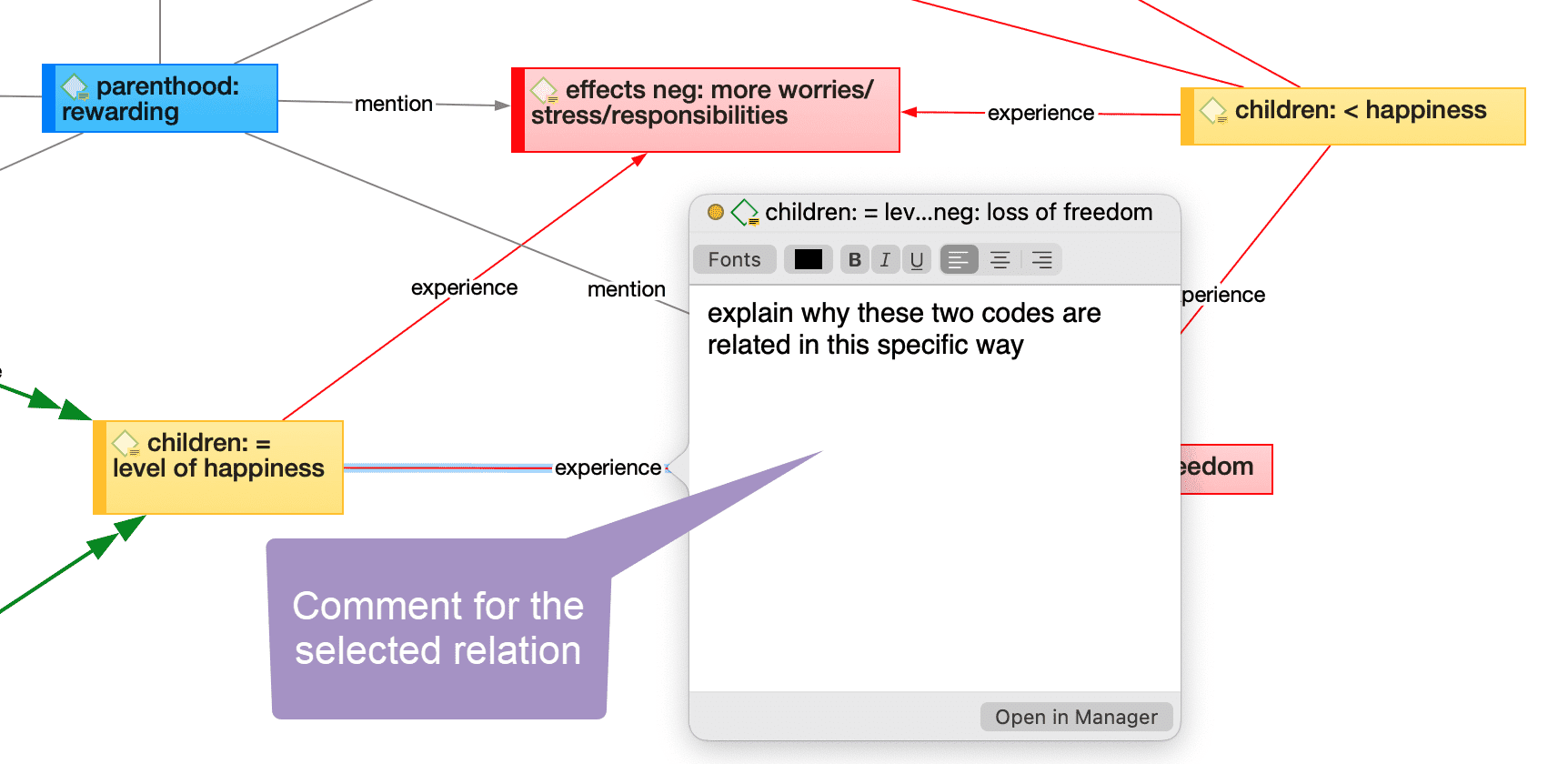
Diferencia entre memos y códigos
Los nombres de los códigos son (o deberían ser) descriptores densos y concisos de conceptos que emergen durante la fase de estudio detallado de los datos. A menudo reducen hallazgos complejos a marcadores de posición escuetos y/o conceptos teóricamente relevantes.
Los principiantes suelen incluir tratados extensos en un nombre de código, difuminando la distinción entre códigos, comentarios y memos, y confundiendo así los códigos con sus equivalentes más apropiados.
Si se encuentra utilizando más de unas pocas palabras como etiqueta de código, considere hacer uso del nombre de la cita o del comentario. Consulte Trabajar con citas, o escriba pensamientos más extensos sobre un código como comentario de código.
Al igual que los códigos, los memos tienen nombres. Estos nombres, o títulos, se utilizan para mostrar los memos en los navegadores y ayudan a encontrar memos específicos.
Al igual que los nombres de los códigos, el título de un memo debe ser breve y conciso. ¡No confunda el nombre con su contenido! El propósito es rellenar el memo con contenido, que es un texto más extenso que va más allá de simplemente describir el título del memo. Si todo lo que desea escribir en el memo cabe en el título, utilice un comentario de cita en su lugar.
Referencias
Corbin, Juliet y Strauss, Anselm (2008). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory (3.ª y 4.ª ed.). Thousand Oaks, CA: Sage.
Gibbs, Graham (2005). Writing as analysis. Online QDA.
Trabajar con comentarios y memos
Escribir un comentario
Encontrará un campo para escribir comentarios en cada Administrador de entidades.
Para escribir un comentario, seleccione un elemento y escriba algo en el campo de comentarios del inspector. En cuanto seleccione otro elemento, el comentario se guarda automáticamente.
Todos los elementos que tienen un comentario muestran un post-it amarillo dentro de su icono.
Alternativamente, puede hacer clic derecho en cualquier entidad y seleccionar la opción Editar comentario del menú contextual para escribir un comentario para la entidad seleccionada.
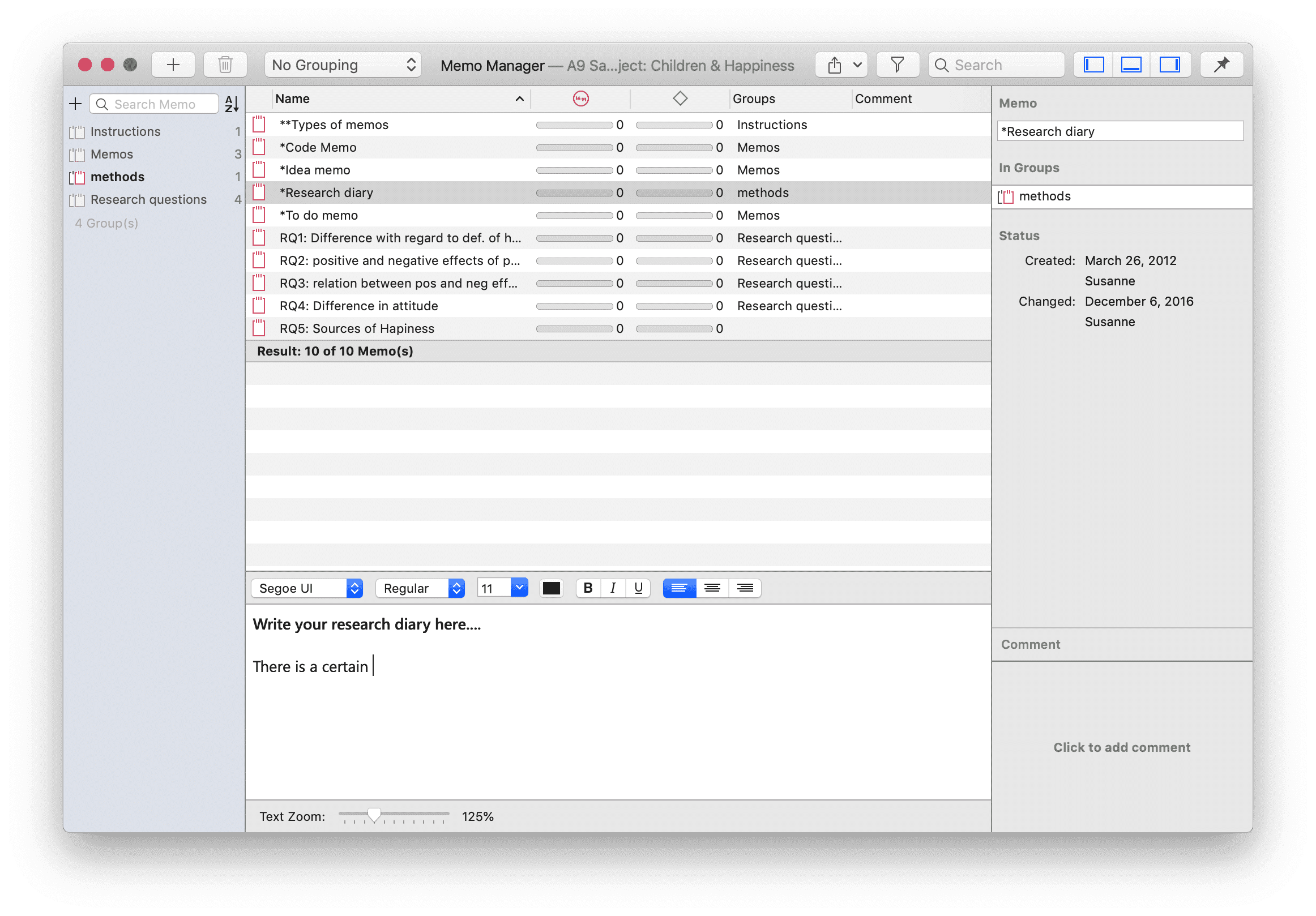
Crear memos
Los memos pueden crearse desde la barra de herramientas o en el Administrador de memos.
Para crear un memo desde la barra de herramientas:
Haga clic en el menú desplegable de Memos y seleccione Nuevo memo. Se abre un nuevo memo inmediatamente y puede cambiar el nombre predeterminado en el inspector.
Para crear un memo en el Administrador de memos
En el menú principal seleccione Memo > Mostrar Administrador de memos.
En el Administrador de memos, haga clic en el más. Se crea un nuevo memo en la lista y puede introducir un título. Puede comenzar a escribir su memo en el editor en la parte inferior del Administrador de memos.
Abrir un memo existente
Puede acceder a los memos desde cualquier lugar: el Explorador de proyectos, el Administrador de memos, en el área al margen si vinculó un memo a una cita, o desde dentro de una red.
Si desea revisar o continuar trabajando en un memo, simplemente haga doble clic en el memo. En el Administrador de memos, puede seleccionar un memo con un clic simple y revisarlo y editarlo en la parte inferior de la ventana del administrador.
Agregar una cita a un memo
Puede copiar y pegar citas en un memo. Esto es útil, por ejemplo, si desea incluir citas clave en su informe.
Seleccione una cita, haga clic derecho y seleccione Copiar del menú contextual, o use el atajo Cmd + C.
Pegue la cita en el editor de memos, ya sea usando el atajo cmd+v o la opción del menú contextual. La cita se pegará en el memo incluyendo su referencia, es decir, el nombre del documento y la ubicación dentro del documento.

También puede copiar y pegar una cita incluyendo su referencia en cualquier editor de texto, también fuera de ATLAS.ti.
Aplicar códigos en memos
Abra un memo y resalte un segmento de datos que desee codificar.
En la barra de herramientas del editor de memos, seleccione Codificación o use el atajo de teclado Cmd + J y aplique el/los código(s) requerido(s) en el diálogo de codificación.
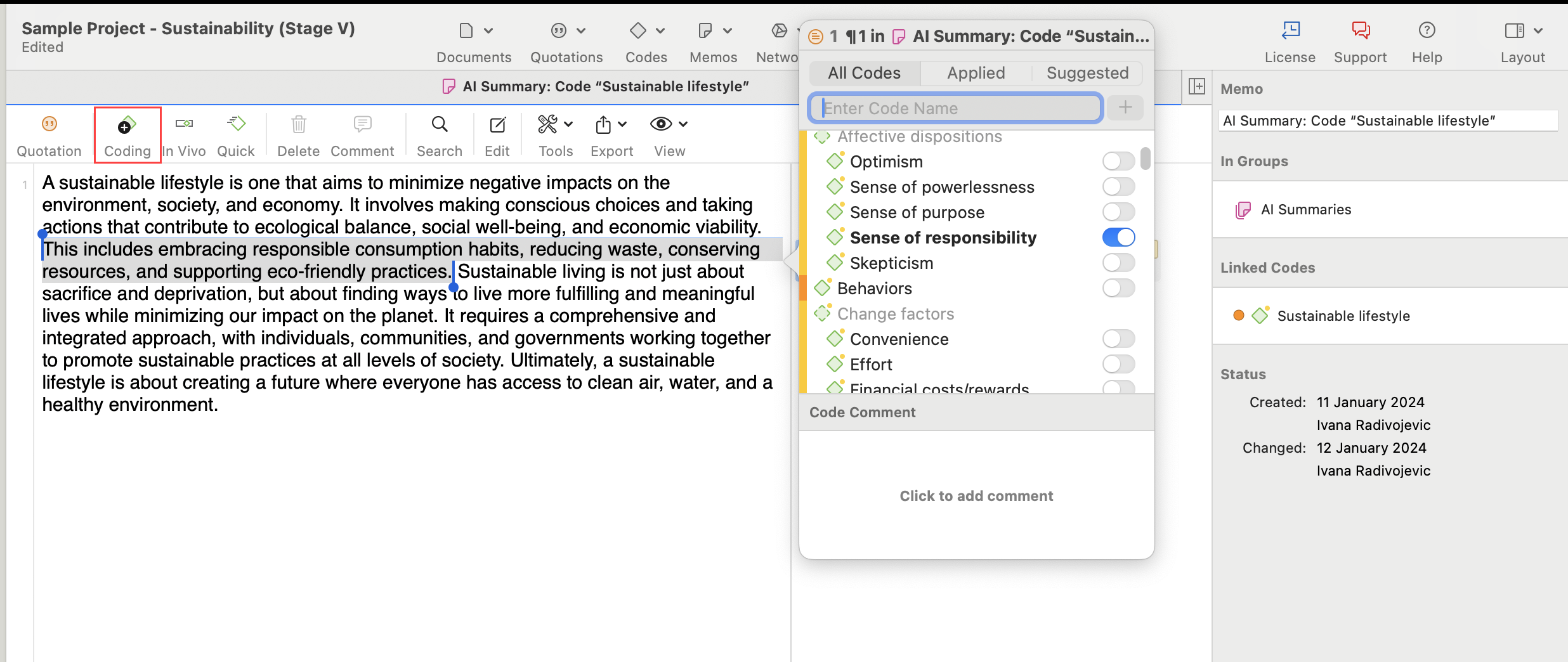
También puede usar las siguientes opciones:
- In Vivo: La codificación In vivo crea una cita a partir del texto seleccionado Y usa el texto seleccionado como nombre del código. El atajo de teclado es Shift + Cmd + V
- Rápido: Codificación con el último código usado. El atajo de teclado es Cmd + L
También puede codificar segmentos de datos dentro de un memo usando las opciones de codificación del menú contextual o arrastrando y soltando códigos sobre el texto seleccionado o directamente sobre una cita en el margen.
Crear citas en memos
Abra un memo y seleccione un segmento de datos.
En la barra de herramientas del editor de memos, seleccione Cita.

Vincular memos
Los memos pueden vincularse a citas, códigos y otros memos. Puede vincular memos mediante arrastrar y soltar prácticamente en cualquier parte del programa, o visualmente en redes. Consulte Vincular nodos. A continuación se dan algunos ejemplos.
Vincular memos a citas
Están disponibles las siguientes opciones:
-
Arrastre y suelte un memo desde el Explorador de proyectos o el Administrador de memos sobre una cita resaltada, o sobre una cita en el área al margen. También puede arrastrar la cita al memo.
-
Arrastre y suelte un memo desde el Explorador de proyectos o el Administrador de memos a una cita en una lista de resultados (o viceversa). Puede ser una lista de resultados en la herramienta de consulta, la Tabla código-documento, la Tabla de co-ocurrencia de códigos o los resultados de una búsqueda en el proyecto.
-
Arrastre y suelte un memo desde el Explorador de proyectos o el Administrador de memos a una cita en el Administrador de citas (o viceversa).
-
Vincule un memo a una cita (o viceversa) en una red. Consulte Vincular nodos.

Revisar las citas vinculadas a un memo
Para revisar todas las citas vinculadas a un memo, haga clic derecho y seleccione Abrir citas. Esto abre el Lector de citas.
También puede ver las citas vinculadas a un memo en el inspector o abriendo el subárbol del memo en el Explorador de proyectos.
Vincular memos a códigos
Están disponibles las siguientes opciones:
-
Arrastre y suelte un memo desde el Explorador de proyectos o el Administrador de memos sobre un código en el área al margen. También puede arrastrar un código al memo.
-
Arrastre y suelte un memo desde la rama de memos del Explorador de proyectos o el Administrador de memos hacia la rama de códigos del Explorador de proyectos (o viceversa).
-
Arrastre y suelte un memo desde el Administrador de memos a un código en el Administrador de códigos (o viceversa).
-
Vincule un memo a un código (o viceversa) en una red. Consulte Vincular nodos.
Vincular memos a memos
Están disponibles las siguientes opciones:
-
Arrastre y suelte un memo a otro memo en el área al margen.
-
Arrastre y suelte un memo a otro memo en la rama de memos del Explorador de proyectos.
-
Arrastre y suelte un memo a otro memo en el Administrador de memos.
-
Vincule un memo a otro memo en una red. Consulte Vincular nodos.
Convertir un memo en documento
Como gran parte del análisis ocurre mientras escribe memos, en algunos casos puede desear convertir un memo en un documento como datos secundarios para poder codificarlo.
Seleccione un memo en el Explorador de proyectos o el Administrador de memos, haga clic derecho y seleccione Convertir memo en documento del menú contextual. Si hay un memo abierto, también puede seleccionar la opción del menú principal: Memo > Convertir memo en documento.
El memo se agrega entonces a su lista de documentos.
Puede seguir usando el memo como memo. El comentario del memo no se transfiere. Se trata de forma independiente del comentario que pueda querer escribir para el documento memo.
Hipervínculos
Representación de la retórica de los datos
Una red basada en segmentos de texto vinculados entre sí se denomina a menudo hipertexto. El texto secuencial original se deslinealiza, se descompone en fragmentos que luego se reconectan, lo que permite pasar de un fragmento de datos a otro independientemente de sus posiciones originales.
Como en ATLAS.ti no solo se puede trabajar con texto, esto también se aplica a otras fuentes de datos como imágenes, audio, vídeo o datos geográficos.
Las referencias cruzadas entre pasajes de texto son muy comunes también en los medios convencionales, como los libros; basta con pensar en textos religiosos y jurídicos, literatura, revistas, etc. Las notas a pie de página y las notas finales son otra desviación habitual de la pura linealidad del texto secuencial. Sin embargo, en los medios convencionales no se ofrece mucho soporte de navegación para "desplazarse" entre los fragmentos de datos que se referencian entre sí.
Este manual es, por ejemplo, una aplicación de hipertexto relacionada con el ordenador que presenta información operativa en fragmentos adecuadamente pequeños (en comparación con la información impresa extensa), pero con una cantidad considerable de vínculos a otros fragmentos de información.
Otra conocida estructura de hipermedia es la World Wide Web, con su información textual, gráfica y multimedia distribuida por todo el mundo.
¿Cuáles son las ventajas de las conexiones directas entre segmentos de texto, en comparación con los procedimientos tradicionales del análisis cualitativo de textos?
Lo que los códigos no pueden hacer
El paradigma de codificación y recuperación, tan prevalente en muchos sistemas de apoyo al investigador cualitativo, no es adecuado para ciertos tipos de análisis. En términos formales, adjuntar códigos a segmentos de datos crea conjuntos de segmentos con nombre y casi sin estructura interna. Esto no quiere decir que no sea útil dividir grandes cantidades de segmentos de texto en conjuntos. Al contrario, la clasificación produce cantidades manejables de segmentos que luego pueden recuperarse con la ayuda de las palabras clave adjuntas. Sin embargo, puede que esta no sea la única forma en que desee analizar sus datos.
El concepto de hipertexto introduce relaciones explícitas entre pasajes. Estos vínculos deben construirse manualmente y son el resultado de un esfuerzo intelectual. El sistema no puede decidir por usted que el segmento x contradice al segmento y. Tras el trabajo de establecer los vínculos, puede realizar recuperaciones semánticamente más ricas, como: "Mostrar afirmaciones contrarias a la afirmación x."
Consulte Administrador de vínculos y Funciones analíticas de las redes.
Un código ofrece acceso rápido a un conjunto de segmentos de datos similares, definidos por una relación simple entre ellos, a saber, la equivalencia.
El hipertexto le permite crear diferentes rutas a través de los datos que está analizando. Por ejemplo, puede crear una línea de tiempo diferente a la estricta secuencia del texto original.
Los hipervínculos pueden expresar relaciones más diferenciadas entre citas, por ejemplo:
- La afirmación A contradice / apoya / hace referencia a la afirmación B.
- La cita de imagen X en el documento 7 ilustra lo que se ha dicho en la cita Y del documento 12.
Los segmentos de datos que puede relacionar entre sí pueden pertenecer al mismo documento o a documentos diferentes.
Representación de hipervínculos en redes
ATLAS.ti incorpora procedimientos para crear y explorar estructuras de hipertexto. Permite conectar dos o más citas mediante relaciones con nombre. Consulte Acerca de las relaciones.
Además, puede crear mapas gráficos, usando Redes, para acceder fácilmente a partes de su hiperespacio.
Los hipervínculos pueden conectar citas (textuales, gráficas, multimedia) entre documentos (vínculos intertextuales) o pueden vincular segmentos dentro del mismo documento (vínculos intratextuales). El límite natural de los hipervínculos, como el de todas las estructuras en ATLAS.ti, es el proyecto.
Crear hipervínculos
Un hipervínculo es un vínculo con nombre entre dos citas. Si, por ejemplo, observa que una afirmación en un informe o entrevista explica con más detalle una afirmación anterior, puede vincular las dos usando la relación "explica". O puede encontrar una afirmación contradictoria o de apoyo. Estas son solo algunas de las relaciones predeterminadas que incluye el software. Si no se ajustan a lo que desea expresar, puede crear relaciones definidas por el usuario en el Administrador de relaciones. Consulte Crear nuevas relaciones.
ATLAS.ti ofrece diversas opciones para crear y recorrer vínculos de hipertexto. De manera similar a la vinculación de códigos, puede crear hipervínculos en el editor de redes. Consulte Vincular nodos.
Además, los vínculos de hipertexto pueden crearse mientras trabaja con sus documentos. A continuación se describe cómo funciona.
Crear hipervínculos en el área de margen
Crear hipervínculos en el área de margen es adecuado para conectar dos citas que están próximas entre sí:
Abra un documento, seleccione una cita en el margen y arrástrela hasta otra cita.
Se abre un menú de selección. Bajo el encabezado "Vincular cita a cita" encontrará varias relaciones. Seleccione una de las relaciones existentes o haga clic en Crear relación. Si selecciona crear una nueva relación, introduzca un nombre, defina un color y su propiedad. Consulte Definir nuevas relaciones de hipervínculo.

Tras crear un hipervínculo, verá lo siguiente en el área de margen: una flecha gris que apunta hacia la derecha o hacia la izquierda, el nombre de la relación, el ID de la cita y las primeras letras del nombre de la cita. Los vínculos de origen apuntan hacia la derecha y los de destino hacia la izquierda.
Si hace doble clic en un hipervínculo, se muestra la cita vinculada. Tiene la opción de saltar directamente a la cita vinculada haciendo clic en la opción Ir a la cita.
Crear hipervínculos en el Administrador de citas
Este método puede aplicarse para conectar una o más citas existentes con una cita de destino.
Seleccione una o más citas de origen en el Administrador de citas (las selecciones múltiples se realizan de la manera estándar).
Mantenga presionado el botón izquierdo del ratón y arrastre la(s) cita(s) hasta una cita de destino en el Administrador de citas.
Suelte el botón izquierdo del ratón. Se abre el menú de relaciones y puede especificar la relación que se usará para los hipervínculos.
Crear hipervínculos entre documentos
Este es un buen método si desea crear hipervínculos entre dos documentos.
Cargue dos documentos uno al lado del otro. Esto significa que carga dos documentos en diferentes regiones. Consulte Trabajar con pestañas y regiones en Navegación por el software.
Haga clic izquierdo en una barra de cita de un documento y arrástrela hasta una barra de cita del otro documento, suelte el botón izquierdo del ratón y seleccione una relación.
Visualización de hipervínculos
-
En el área de margen: En el área de margen, las etiquetas de hipervínculo muestran el icono de cita, el nombre de la relación, el ID de la cita y las primeras letras del nombre de la cita. La etiqueta se visualiza como una flecha. Los vínculos de origen apuntan hacia la derecha y los de destino hacia la izquierda.
-
En el inspector: Si una cita está vinculada a una o más citas, verá una sección "Citas vinculadas" en el inspector que enumera todos los hipervínculos.
Trabajar con hipervínculos
Recorrer hipervínculos
Recorrer hipervínculos significa ver o saltar a las citas vinculadas. Para hacerlo:
Haga doble clic en un hipervínculo.
Aparecerá una ventana emergente con el contenido de la cita vinculada.
Para ver el contenido de la cita vinculada, seleccione la opción Ir a la cita.
Modificar hipervínculos
Puede modificar los hipervínculos existentes, es decir, cortar un vínculo, invertirlo o cambiar la relación desde distintos lugares.
En el área de margen
En el área de margen, puede desvincular o cambiar la dirección de un hipervínculo:
Haga clic derecho en un hipervínculo en el área de margen y seleccione la opción Desvincular o Invertir vínculo en el menú contextual.
En el Administrador de hipervínculos
En el Administrador de hipervínculos, puede desvincular o cambiar la dirección de un hipervínculo, o cambiar la relación.
Para abrir el Administrador de hipervínculos, seleccione Cita > Mostrar Administrador de vínculos en el menú principal.
Para modificar un hipervínculo, selecciónelo, haga clic derecho y elija una de las siguientes opciones en el menú contextual: Invertir vínculo, Cambiar relación o Desvincular.
Modificar hipervínculos en el editor de redes
Haga clic derecho en un hipervínculo en el área de margen y seleccione Abrir red en el menú contextual. Consulte también Redes ad hoc.
En el editor de redes, haga clic derecho en una etiqueta de vínculo y seleccione una de las siguientes opciones en el menú contextual: Invertir vínculo, Cambiar relación o Desvincular.
Para obtener más información, consulte Vincular nodos.
Editar comentarios de hipervínculos
Los vínculos entre citas utilizan relaciones completamente definidas, al igual que los vínculos entre códigos. Como un hipervínculo es una entidad de "primer nivel", puede escribir un comentario dedicado para cada hipervínculo.
Dicho comentario podría explicar por qué la cita A se ha vinculado a la cita B. Los comentarios de vínculo pueden accederse, mostrarse y editarse desde tres ubicaciones: el área de margen, el Administrador de hipervínculos y el Editor de redes.
El área de margen tiene la ventaja de estar disponible inmediatamente mientras se desplaza por los documentos.
El método del editor de redes ofrece un enfoque visual para lograr este objetivo.
Editar un comentario de hipervínculo en el área de margen
Seleccione un hipervínculo en el margen y escriba un comentario en el inspector; o haga clic derecho y seleccione Editar comentario en el menú contextual.
Editar un comentario de hipervínculo en el Administrador de hipervínculos
Abra el Administrador de hipervínculos (Cita > Mostrar Administrador de vínculos) y seleccione un hipervínculo. Edite el comentario en el inspector del panel derecho, o haga clic derecho y seleccione Editar comentario.
Editar un comentario de hipervínculo en una red
Abra una red sobre un hipervínculo; p. ej., haga clic derecho y seleccione Abrir red en el menú contextual. Consulte también Redes ad hoc.
Haga clic en el nombre de la relación y escriba un comentario en el inspector, o haga clic derecho y seleccione Editar comentario.
Crear nuevas relaciones para hipervínculos
Las nuevas relaciones pueden definirse en el Administrador de relaciones. Consulte Crear nuevas relaciones. El procedimiento para definir o editar relaciones de hipervínculo es equivalente al de definir o editar relaciones código-código.
Análisis adicional de datos
ATLAS.ti ofrece varias herramientas que ayudan a consultar los datos:
Recuperación booleana simple.
Consulte Recuperación de datos codificados.
Análisis de distribuciones de códigos
Las distribuciones de códigos se muestran en el Administrador de documentos y en el Administrador de códigos en forma de gráficos de barras. En el administrador de documentos se muestra una barra por cada código. Cuanto más alta sea la barra, más veces se ha utilizado el código. En el Administrador de códigos, cada barra representa un documento. Dentro de la barra se puede observar cómo se distribuyen los códigos en el documento.
Una vez codificados los datos, la distribución de códigos ofrece una primera impresión del material. ¿Qué temas se mencionaron con mayor o menor frecuencia, por quién y existen diferencias entre distintos grupos de encuestados? ¿Cómo se distribuyen los temas? Para más información, consulte Análisis de distribuciones de códigos.
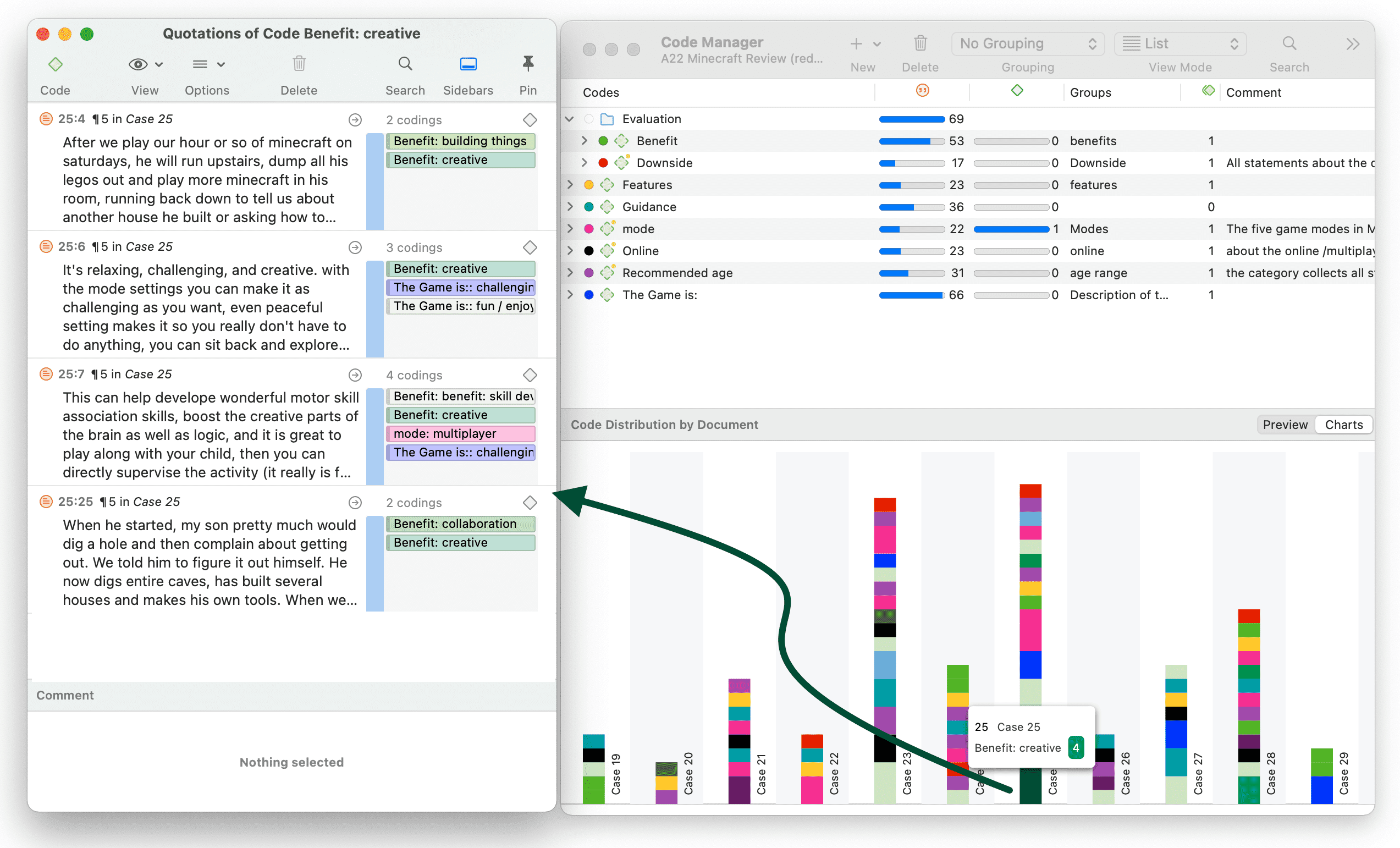
Tabla código-documento
La tabla código-documento es una tabulación cruzada de códigos o grupos de códigos por documentos o grupos de documentos. Muestra cuántas veces se ha aplicado un código (o los códigos de un grupo de códigos) a un documento o grupo de documentos. Consulte Tabla código-documento.
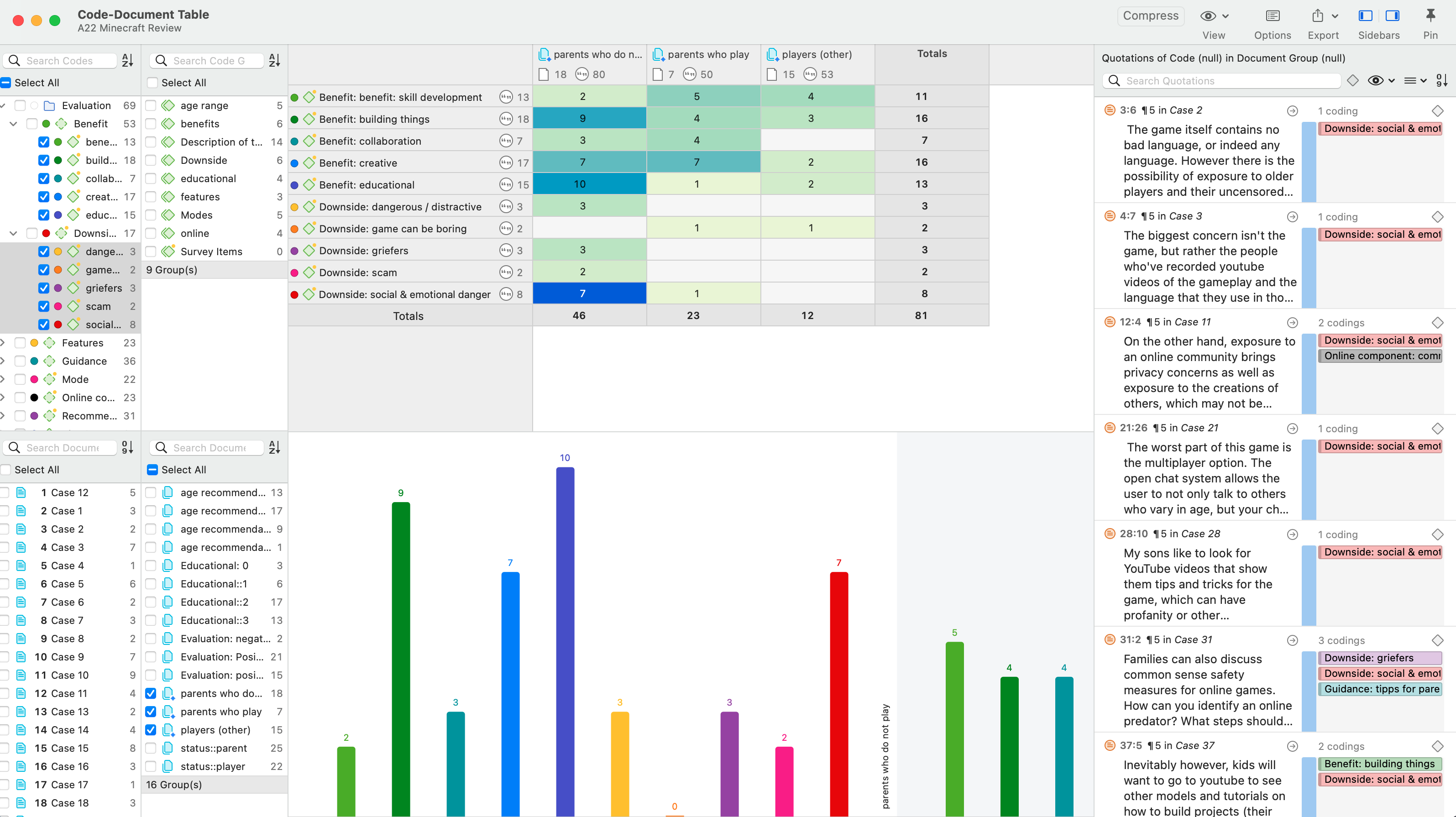
Análisis de co-ocurrencias
Para obtener una visión rápida de los posibles solapamientos en los datos codificados, haga clic derecho sobre los códigos de interés y elija una de las opciones de co-ocurrencia del submenú Analizar. Consulte Herramientas de co-ocurrencia de códigos.
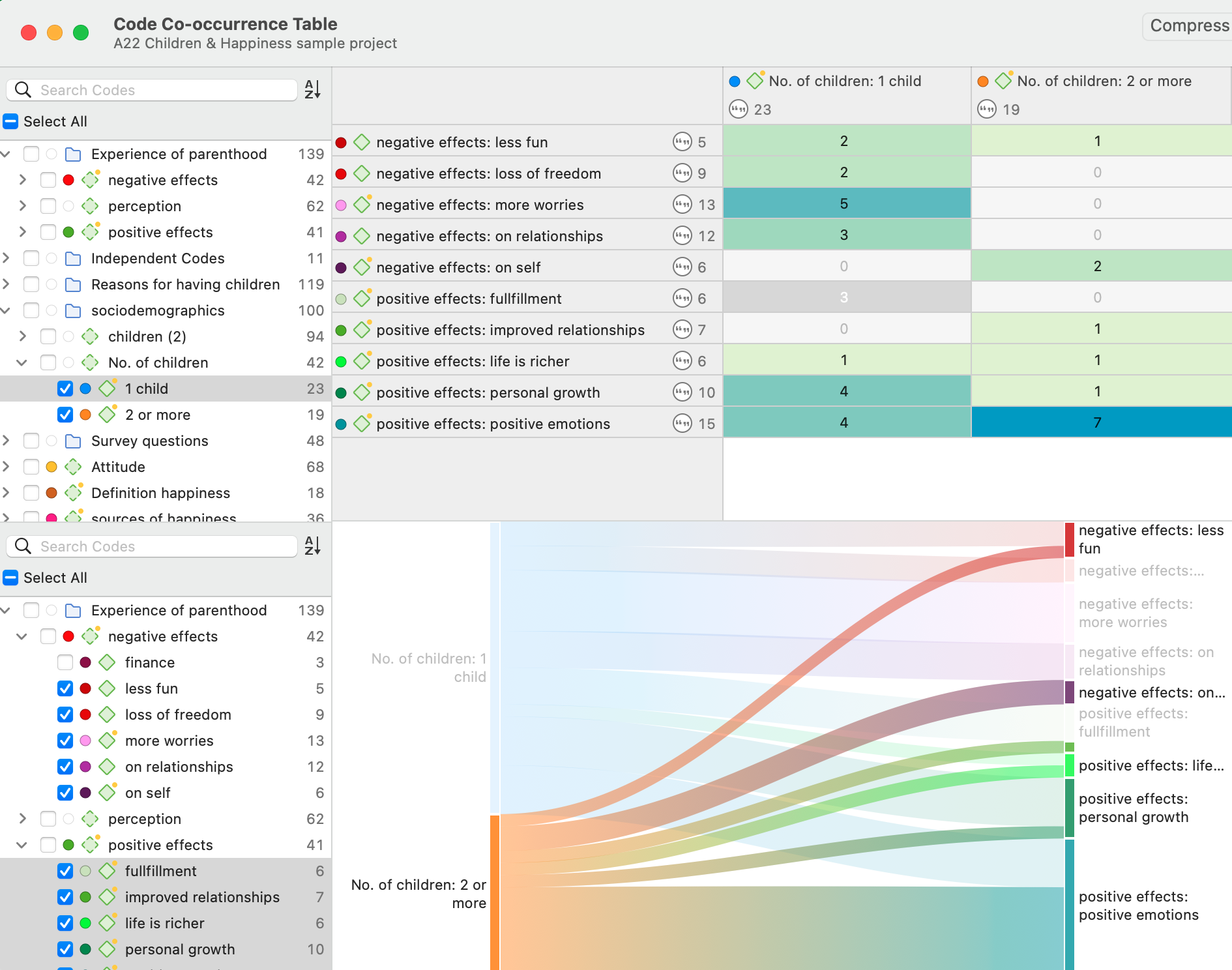
La herramienta de consulta
La herramienta de consulta busca citas a partir de una combinación de códigos mediante operadores booleanos o de proximidad. Por ejemplo: mostrar todas las citas en las que se han aplicado tanto el código A como el código B.
Este tipo de consultas también se pueden combinar con variables en forma de documentos o grupos de documentos. Esto permite restringir una consulta a partes concretas de los datos, por ejemplo: mostrar todas las citas en las que se aplican tanto el código A como el código B, pero únicamente dentro de entrevistas con expertos. Consulte La herramienta de consulta.
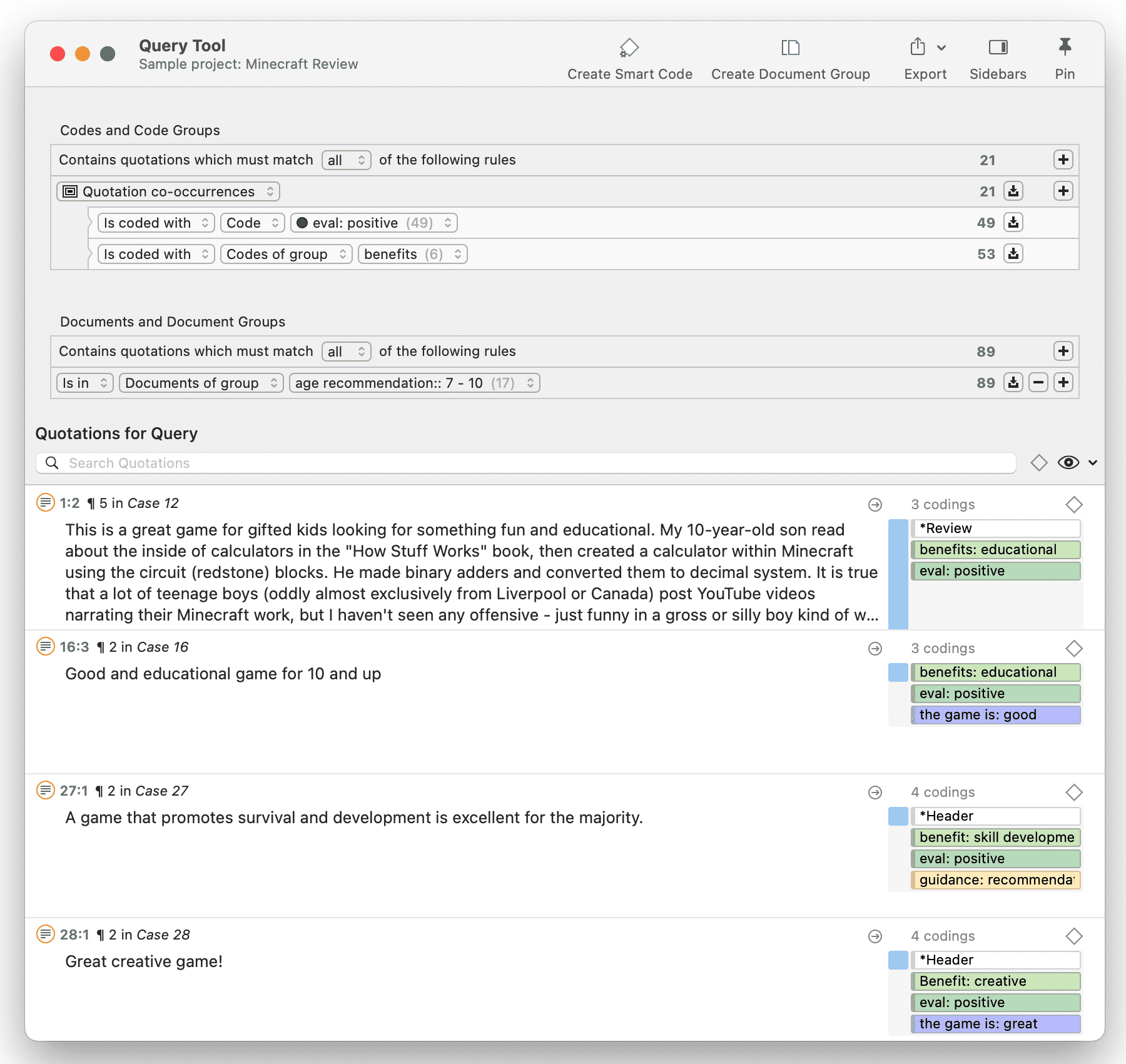
Códigos inteligentes
Los códigos inteligentes son consultas almacenadas. Se pueden reutilizar y reflejan siempre el estado actual de la codificación, por ejemplo, después de haber realizado más codificaciones o de haber modificado las existentes. También se pueden emplear como parte de otra consulta, lo que permite construir consultas complejas paso a paso. Consulte Trabajar con códigos inteligentes.
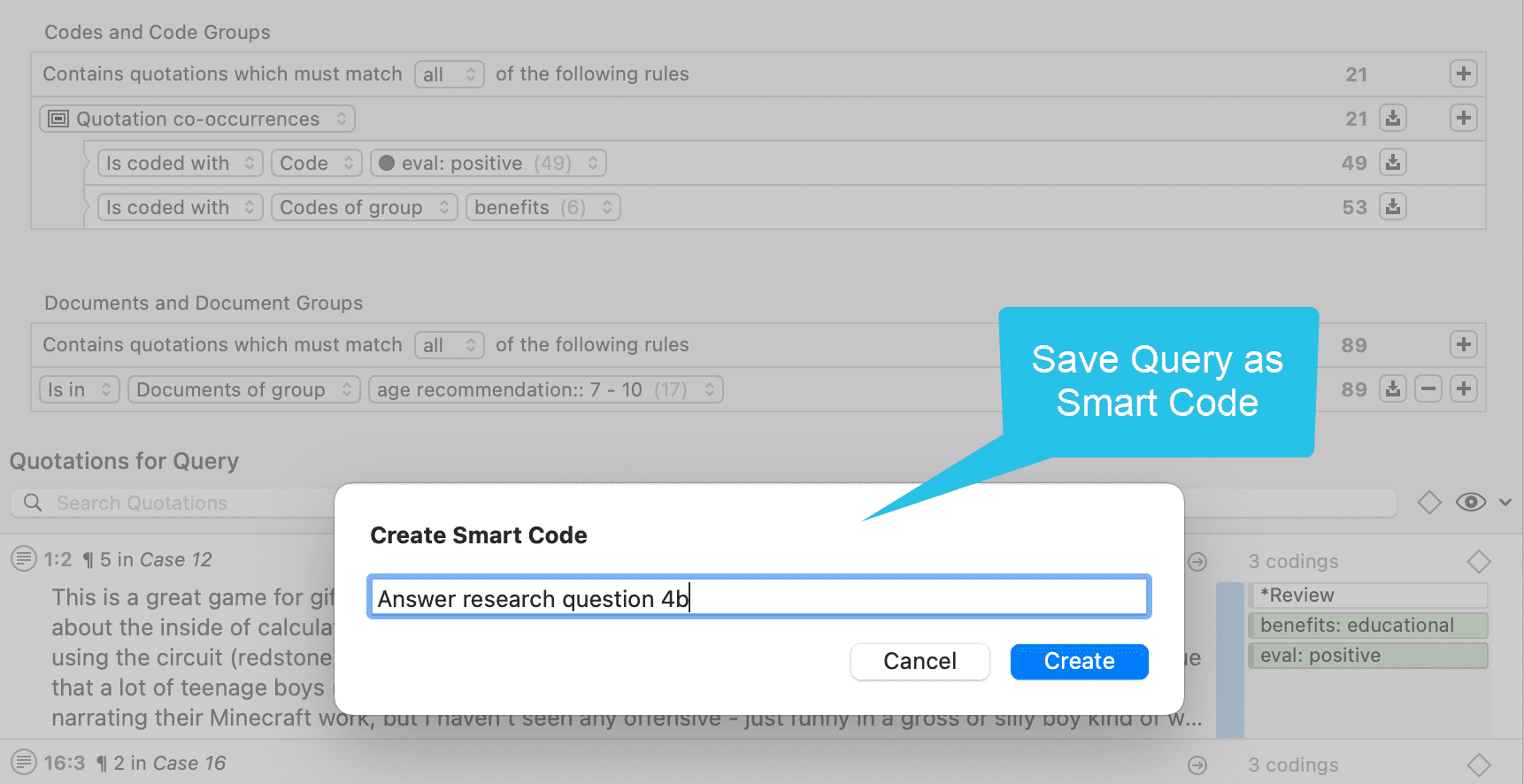
Grupos inteligentes
Al igual que los códigos inteligentes, los grupos inteligentes son consultas almacenadas basadas en grupos. Su finalidad es crear grupos a un nivel agregado. Por ejemplo, si se dispone de grupos para género, edad y ubicación, se pueden crear grupos inteligentes que reflejen una combinación de estos, como todas las mujeres del grupo de edad 1 que viven en la ciudad X. Consulte Trabajar con grupos inteligentes.
Filtros globales
Los filtros globales permiten restringir las búsquedas en todo el proyecto. Si se establece un grupo de documentos como filtro global, los resultados en la tabla código-documento o en la tabla de co-ocurrencia de códigos se calcularán en función de los datos incluidos en el filtro, y no para el proyecto completo. Los filtros globales afectan a todas las herramientas, ventanas y redes. Consulte Aplicar filtros globales para el análisis de datos.
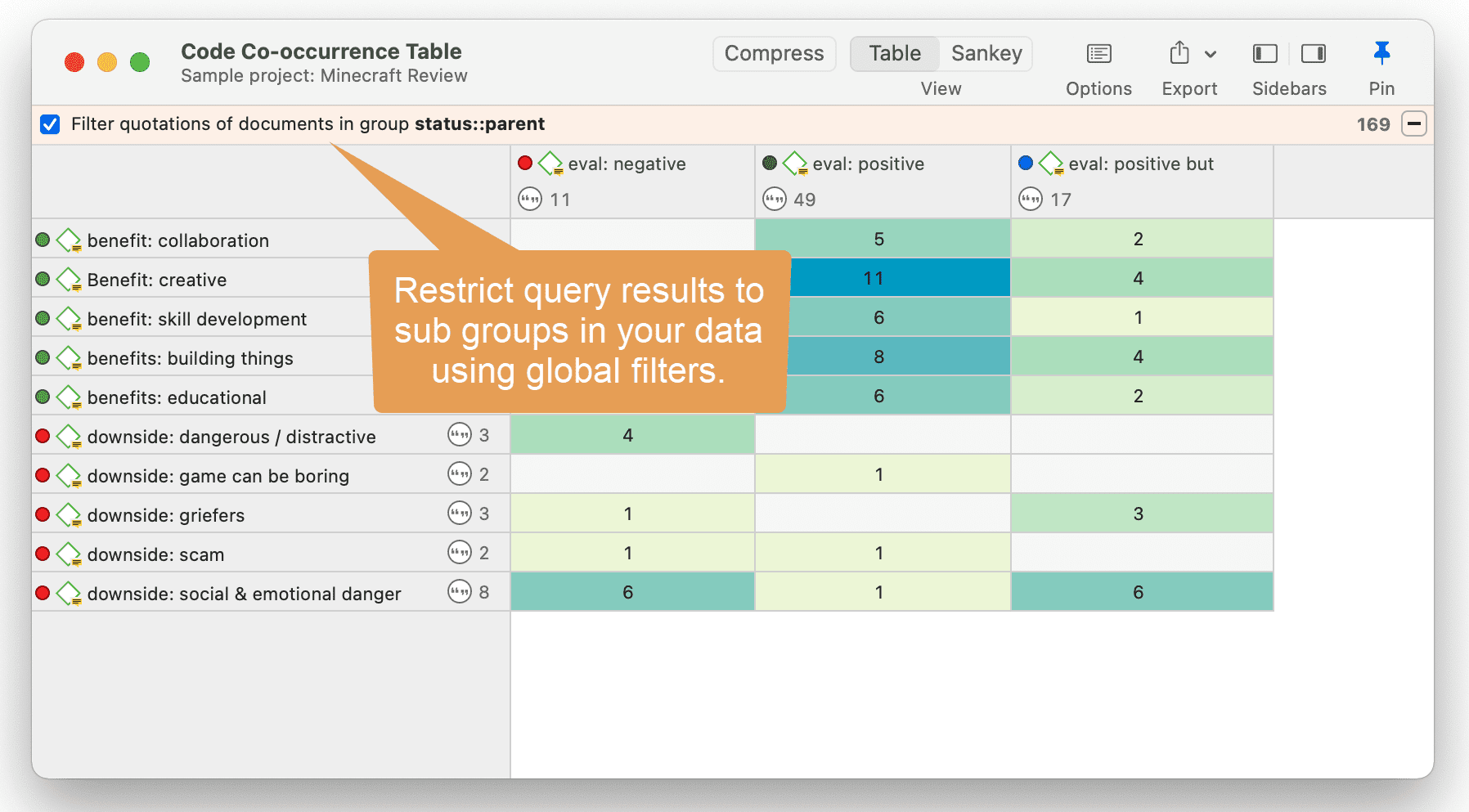
Operadores disponibles para consultar datos
Es importante conocer los operadores disponibles al utilizar las herramientas de co-ocurrencia de códigos, la herramienta de consulta, al crear códigos inteligentes y grupos inteligentes. Los siguientes tipos de operadores están disponibles:
-
Los operadores booleanos permiten combinar términos según operaciones de conjuntos. Son los operadores más comunes en los sistemas de recuperación de información.
-
Los operadores de proximidad se utilizan para analizar las relaciones espaciales (por ejemplo, distancia, inclusión/contenedor, solapamiento, co-ocurrencia) entre segmentos de datos codificados.
Operadores booleanos
Tutorial en vídeo: Explicación de los operadores booleanos

OR, AND, ONE OF (exactamente uno de los siguientes es verdadero) y NOT
- OR, AND y ONE OF (exactamente uno de los siguientes es verdadero) son operadores binarios que requieren exactamente dos operandos como entrada.
- NOT solo requiere un operando.
- Los códigos, grupos de códigos o códigos inteligentes pueden utilizarse como operandos en una consulta.
AND: TODOS los siguientes son verdaderos
El operador AND busca citas que cumplan TODAS las condiciones especificadas en la consulta. Esto significa que se han aplicado dos o más códigos a la misma cita.
Ejemplo: Todas las citas codificadas tanto con 'código A' como con 'código B'.
El operador AND es muy selectivo y con frecuencia produce un conjunto de resultados vacío, ya que requiere que todos los códigos seleccionados se hayan aplicado exactamente al mismo segmento de datos. Ofrece mejores resultados cuando se combina con operadores menos restrictivos o cuando el número total de segmentos de texto disponibles es grande.
OR: ALGUNO de los siguientes es verdadero
El operador OR no corresponde exactamente al uso cotidiano de la palabra «o». Su significado es «al menos uno de...», incluido el caso en que TODAS las condiciones se cumplan. El operador OR recupera todas las citas codificadas con cualquiera de los códigos utilizados en la expresión.
Ejemplo: Todas las citas codificadas con 'código A' OR 'código B'. La lista de resultados contendrá todas las citas codificadas con 'código A', todas las codificadas con 'código B' y las codificadas con ambos códigos.
ONE OF: Exactamente uno de los siguientes es verdadero
El operador ONE OF exige que se cumpla EXACTAMENTE una de las condiciones. Equivale al «o exclusivo» del lenguaje cotidiano.
Ejemplo: Todas las citas codificadas con 'código A' OR 'código B' (pero no con ambos).
NOT: Ninguno de los siguientes es verdadero
El operador NOT verifica la ausencia de una condición. Técnicamente, sustrae los resultados del término no negado del total de segmentos de datos disponibles. Dado un proyecto con 1000 citas y 20 citas asignadas al 'código A', la consulta NOT 'código A' recupera 980 citas, es decir, aquellas que no están codificadas con 'código A'.
El operador puede utilizarse con una expresión arbitraria, como en el argumento NOT ('código A' OR 'código B'), que equivale a «ni 'código A' ni 'código B'».
Consulte Ejemplo 2 en la sección Construcción de consultas complejas.
Operadores de proximidad
Tutorial en vídeo: Operadores de proximidad y consultas de ejemplo

La proximidad describe la relación espacial entre las citas. Las citas pueden estar anidadas unas dentro de otras, una puede seguir a otra, etc. Los operadores de esta sección aprovechan estas relaciones. Todos requieren dos operandos como argumentos.
Los operadores de proximidad difieren de los demás operadores en un aspecto importante: los operadores de proximidad son no conmutativos. Esta propiedad hace que su uso sea algo más difícil de aprender.
-
Citas que contienen otras citas: A ENCLOSES B recupera todas las citas codificadas con A que contienen citas codificadas con B.
-
Citas contenidas dentro de otras citas: A contenida dentro de B (WITHIN) recupera todas las citas codificadas con A que están contenidas dentro de segmentos de datos codificados con B.
-
Solapamientos (cita que solapa al inicio): A OVERLAPS B recupera todas las citas codificadas con A que se solapan con citas codificadas con B.
-
Solapada por (citas solapadas al final): A OVERLAPPED BY B recupera todas las citas codificadas con A que son solapadas por citas codificadas con B.
-
Co-ocurre: Cuando se está interesado en la relación entre dos o más códigos, a menudo no importa si algo se solapa o es solapado, o si está dentro o contiene a otro. En ese caso, simplemente se utiliza el operador Co-occurs.
Co-occurs es esencialmente un atajo para una combinación de los cuatro operadores de proximidad descritos anteriormente, más el operador AND. AND es un operador booleano que también detecta co-ocurrencia, concretamente todos los segmentos codificados que se solapan al 100 %.
El operador de co-ocurrencia general resulta muy útil al trabajar con transcripciones. En las entrevistas, las personas suelen saltar entre tiempos o contextos, por lo que muchas veces no tiene sentido utilizar los operadores de anidamiento o solapamiento tan específicos. Sin embargo, con otros tipos de datos son bastante útiles. Piense en datos de vídeo donde puede ser importante saber si la acción A ya estaba ocurriendo antes de que comenzara la acción B, o viceversa. O si ha codificado secciones más largas de los datos, como períodos biográficos en la vida de una persona, y luego realizó una codificación más detallada dentro de esos períodos. En ese caso, el operador WITHIN resulta muy práctico. Lo mismo se aplica al trabajar con datos de encuestas o grupos de discusión precodificados. Usando WITHIN, se pueden encontrar, por ejemplo, todos los segmentos de datos codificados con 'tema x' WITHIN 'pregunta 5', o todos los segmentos codificados con 'código A' WITHIN 'unidad de hablante: Tom'.
No conmutatividad de los operadores de proximidad
La no conmutatividad exige un orden de entrada determinado para los operandos. Mientras que A OR B es igual a B OR A, esto no se cumple para ninguno de los operadores de proximidad: A FOLLOWS B no es igual a B FOLLOWS A. Al construir una consulta, siempre se deben introducir las expresiones en el orden en que aparecen en su formulación en lenguaje natural.
Otra característica importante de estos operadores al utilizar la herramienta de consulta es la especificación del operando para el que se desean recuperar las citas. A WITHIN B especifica la restricción, pero también se debe indicar si se quieren las citas de las A o de las B. Esto se determina de forma implícita por el orden de entrada.
Si se introduce la consulta 'A Co-occur B', se recuperan todas las citas codificadas con A.
Si se introduce 'B co-occur A', se recuperan todas las citas codificadas con B.
Por ejemplo, si se quieren recuperar todos los segmentos codificados con los códigos del grupo de códigos 'Efectos positivos de la paternidad' para todos los comentarios escritos por personas con 1 hijo: 'N.º de hijos: 1 hijo', la consulta arroja 11 citas:

Como resultados, se obtienen todas las citas codificadas con los códigos del grupo de códigos 'Efectos positivos de la paternidad'.
Si se introducen los códigos en un orden diferente, es decir, primero el código 'N.º de hijos: 1 hijo', la consulta recupera 10 citas. Esto no es un error, porque en este caso el resultado serán todas las citas codificadas con el código 'N.º de hijos: 1 hijo'.
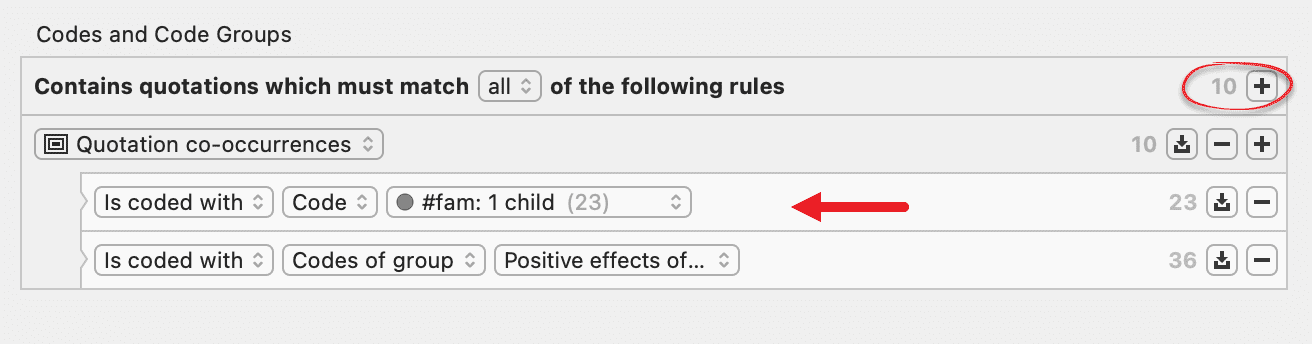
En la herramienta de consulta, el código cuyo contenido más interesa debe introducirse en la primera línea.
La herramienta de consulta
La herramienta de consulta se utiliza para recuperar citas a partir de los códigos con los que fueron asociadas durante el proceso de codificación. La recuperación más sencilla de este tipo —buscar citas por códigos— es lo que se hace con frecuencia al hacer doble clic en un código en el Administrador de códigos o en un explorador de códigos. Consulte Recuperación de datos codificados. Esto ya puede considerarse una consulta, aunque sencilla. La herramienta de consulta es más avanzada, ya que permite crear y procesar consultas que incluyen diversas combinaciones de códigos.
Una consulta es una expresión de búsqueda construida a partir de operandos (códigos y grupos de códigos) y operadores (booleanos o de proximidad) que definen las condiciones que debe cumplir una cita para ser recuperada; por ejemplo, «Todas las citas codificadas tanto con el código A como con el código B».
También puede utilizar el Administrador de citas para construir consultas. El Administrador de citas, además de las consultas de códigos, también permite establecer filtros adicionales, como incluir solo las citas que contienen una determinada palabra.
Una consulta puede construirse de forma incremental, siendo evaluada y mostrada instantáneamente como una lista de citas. Esta construcción incremental de consultas de búsqueda complejas ofrece un enfoque exploratorio incluso para las consultas más complejas.

Para abrir la herramienta de consulta:
Desde el menú principal, seleccione Análisis > Herramienta de consulta. Cuando se abra la herramienta de consulta, el primer código de la lista de códigos estará seleccionado.
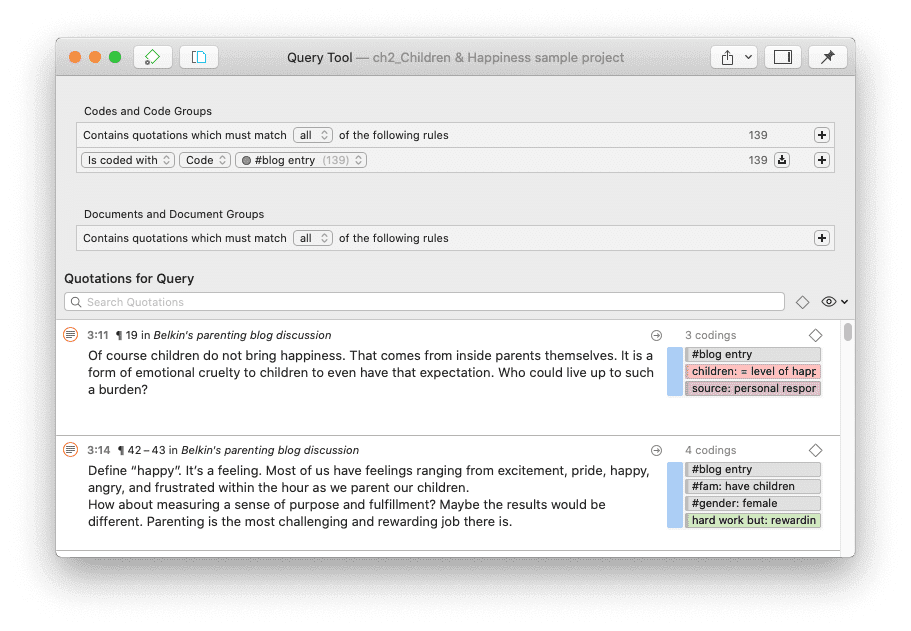
En la sección gris de la parte superior de la ventana se construye la consulta.
-
Puede seleccionar códigos y grupos de códigos y combinarlos con operadores booleanos, de proximidad o semánticos.
-
Puede restringir la búsqueda a documentos o grupos de documentos, o a una combinación de ellos usando operadores booleanos.
Consulte las siguientes páginas para ver:
- Consultas booleanas de ejemplo
- Consultas de proximidad de ejemplo
- Un ejemplo de consulta compleja basada en una combinación de operadores
Recuerde que los resultados de una consulta en la herramienta de consulta son siempre citas.
Cómo construir una consulta usando operadores booleanos
Tutorial en vídeo Creación de una consulta booleana OR en la herramienta de consulta
Los ejemplos mostrados están basados en el proyecto de muestra Children & Happiness. Puede descargarlo e importarlo si desea seguir los pasos.
Ejemplo 1
Abra la herramienta de consulta: Seleccione Análisis > Herramienta de consulta. Cuando se abra la herramienta de consulta, el primer código de la lista de códigos estará seleccionado.
Pregunta
El objetivo es encontrar todas las declaraciones en las que las personas escribieron sobre los dos efectos positivos de la paternidad: 'satisfacción' y 'la vida es más rica'.
Cambie el operador en la primera línea a cualquiera.
En la segunda línea, cambie el código a 'efectos pos: satisfacción'.
Haga clic en el más al final de la segunda línea para añadir un segundo código a la consulta. Seleccione 'efectos pos: la vida es más rica'.
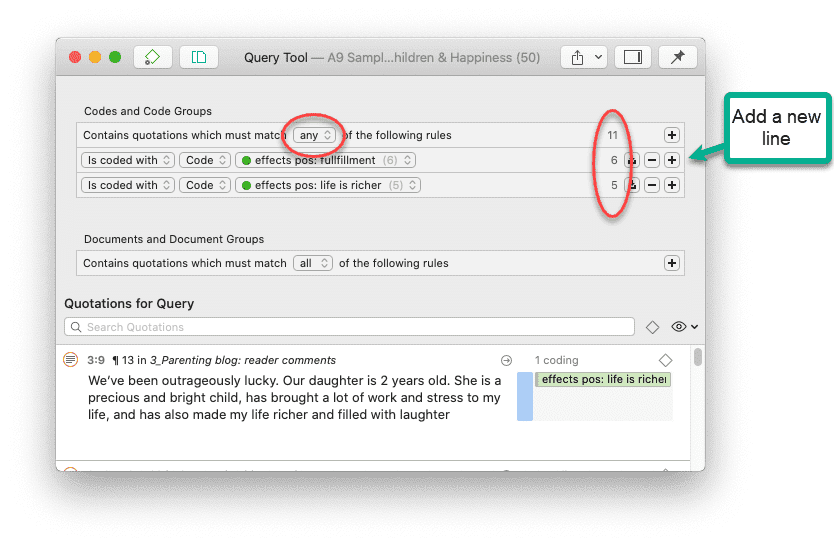
Una segunda forma de introducir una consulta booleana es la siguiente:
Deje la primera línea tal como está: Contiene citas que deben cumplir todas las siguientes reglas.
En la segunda línea, haga clic en el primer campo y seleccione el operador OR. Como el operador OR siempre requiere dos argumentos, se añaden dos líneas donde puede introducir códigos o grupos de códigos.
Cambie el código en la tercera línea a 'efectos pos: satisfacción', y el código en la cuarta línea a 'efectos pos: la vida es más rica'.
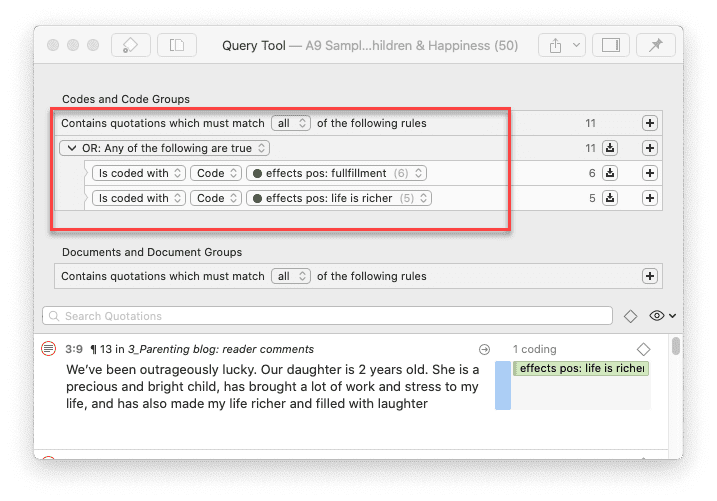
Si desea seleccionar un grupo de códigos en lugar de un código, haga clic en el campo Código y seleccione Grupo de códigos en el menú desplegable.
Lectura de los resultados de una consulta
- El número resultante de citas se muestra en el lado derecho.
- Los resultados de la consulta se muestran en el Lector de citas debajo de la consulta. Toda la funcionalidad del lector de citas también está disponible aquí.
Eliminar o modificar una consulta
Si desea agregar una nueva consulta, cambie el operador y seleccione diferentes códigos o grupos de códigos. En lugar de seleccionar un operador diferente, otra opción es seleccionar sin definir (Vacío). Así puede construir una consulta desde cero.
Si una consulta se vuelve más compleja y hay varias líneas, aparece un botón de menos. Si hace clic en él, se elimina esa parte de la consulta.
Ejemplo 2
En este ejemplo se muestra cómo construir una consulta con dos operadores booleanos.
Pregunta
El objetivo es encontrar todas las declaraciones en las que las personas escribieron que los hijos les hacen más felices o experimentan el mismo nivel de felicidad, además de mencionar una fuente de felicidad capturada por los códigos del grupo de códigos 'fuentes de felicidad'.
Esto es algo más complejo, ya que es necesario incrustar una consulta OR dentro de una consulta AND. Primero se deben encontrar todas las declaraciones en las que las personas expresan igual nivel de felicidad o mayor felicidad. Esta es la parte OR de la consulta. La parte AND consiste en encontrar solo aquellas citas que también están codificadas con alguno de los códigos del grupo de códigos 'fuentes de felicidad'.
Esta consulta arroja 1 cita como resultado.
Es necesario comenzar con el operador AND para poder incrustar la consulta OR dentro: Seleccione el operador AND. A continuación, puede hacer clic en el botón Incrustar regla en el lado derecho y seleccionar el operador OR, o cambiar el campo "está codificada con" en la tercera línea al operador OR.
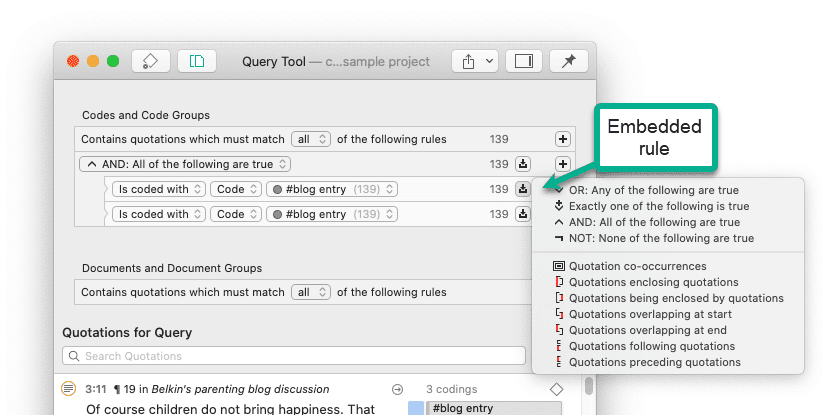
Añada los dos códigos 'niños: = igual nivel de felicidad' y 'niños: > felicidad' en la cuarta y quinta línea.
En la sexta línea, cambie el campo 'código' a grupo de códigos y como grupo de códigos seleccione 'fuentes de felicidad'. Véase la imagen a continuación.
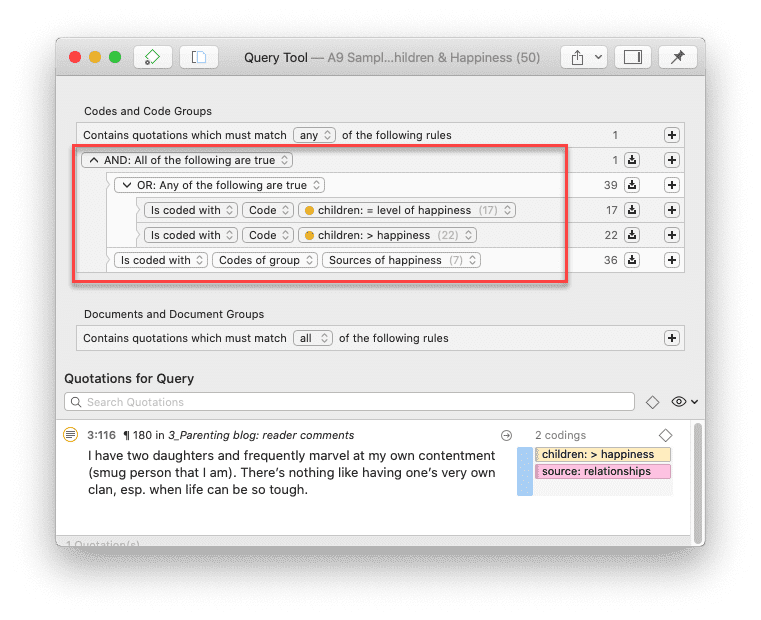
Cómo construir una consulta usando operadores de proximidad
Tutorial en vídeo: Operadores de proximidad y consultas de ejemplo
Los ejemplos mostrados están basados en el proyecto de muestra Children & Happiness.
Ejemplo 1
El objetivo es encontrar todos los segmentos de datos en los que personas que mencionan efectos positivos de la paternidad también escriben que tener hijos les ha hecho más felices.
Abra la herramienta de consulta: Seleccione Análisis > Herramienta de consulta. Cuando se abra la herramienta de consulta, el primer código de la lista de códigos estará seleccionado.
En el campo 'está codificada con', seleccione la opción Co-ocurrencia de citas. Esto añade dos líneas a la consulta, ya que todos los operadores de proximidad requieren dos argumentos.
En la tercera línea, cambie códigos a códigos del grupo y añada el grupo de códigos 'efectos de la paternidad positivos'. En la cuarta línea, añada el código 'niños: > felicidad'.
El resultado de esta consulta arroja 8 citas.
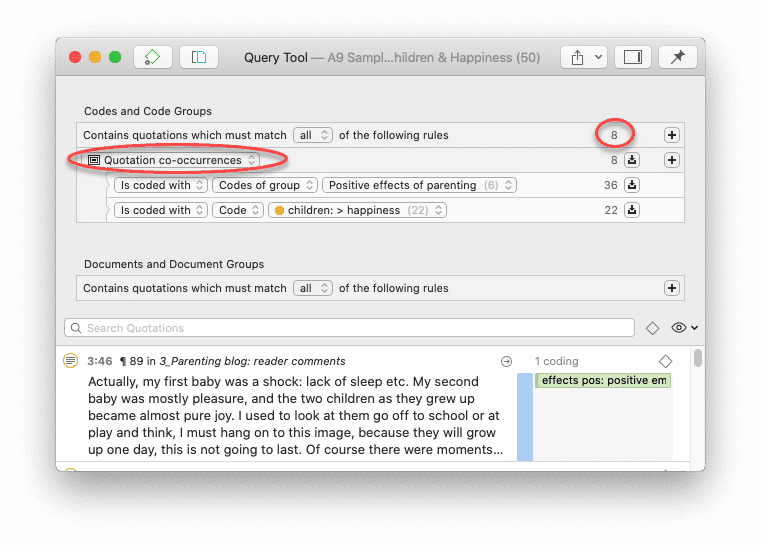
Los resultados de una consulta se muestran en el Lector de citas. Toda la funcionalidad del lector de citas también está disponible aquí.
Ejemplo 2
También se pueden combinar múltiples operadores de proximidad.
El objetivo es encontrar todos los comentarios de blog en los que las personas escribieron algo sobre efectos positivos de la paternidad y efectos negativos de la paternidad. Las declaraciones sobre efectos positivos y negativos están incluidas en el comentario de blog; pueden solaparse directamente o no.
Seleccione la opción Co-ocurrencias de citas.
Como las declaraciones sobre efectos positivos y negativos no necesariamente se solapan, primero es necesario encontrar los comentarios de blog que contienen declaraciones de efectos positivos o negativos. Por lo tanto, se debe incrustar la siguiente consulta:
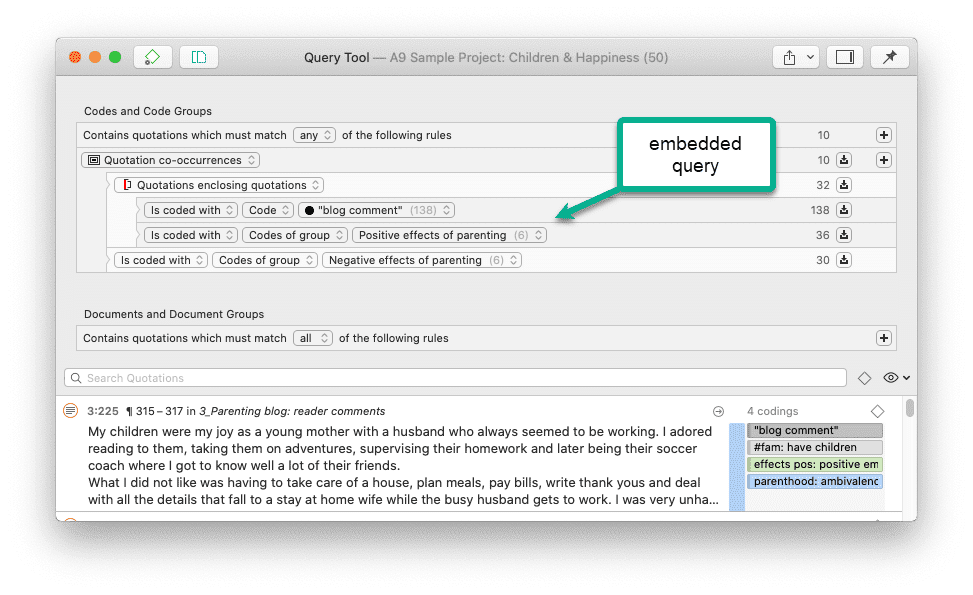
Seleccione la opción Citas que contienen otras citas y seleccione el código 'comentario de blog' en la cuarta línea y el grupo de códigos 'efectos positivos de la paternidad' en la quinta línea. En la sexta línea, seleccione el grupo de códigos 'Efectos negativos de la paternidad'.
El resultado de esta consulta arroja 10 citas. La siguiente imagen muestra una de las citas resultantes:

Cómo construir una consulta usando una combinación de operadores
Tutorial en vídeo: Más consultas de ejemplo
Los ejemplos mostrados están basados en el proyecto de muestra Children & Happiness. Puede descargarlo e importarlo si desea seguir los pasos.
Las instrucciones a continuación no son tan detalladas, ya que se asume que ha leído los ejemplos de Consultas booleanas y Consultas de proximidad.
Ejemplo 1
Pregunta: Encontrar todos los comentarios de blog escritos por personas que tienen un hijo Y que expresaron la ambivalencia de la paternidad, y que contienen una declaración de que tener hijos les hizo más felices.
La consulta AND debe estar incrustada dentro de la consulta de co-ocurrencia:
Seleccione la opción Co-ocurrencia de citas. Añada la consulta AND en la siguiente línea e introduzca los dos códigos '#fam: 1 hijo' y 'paternidad: ambivalencia de'.
Para completar la consulta de co-ocurrencia, añada el código 'niños: > felicidad' en la última línea.
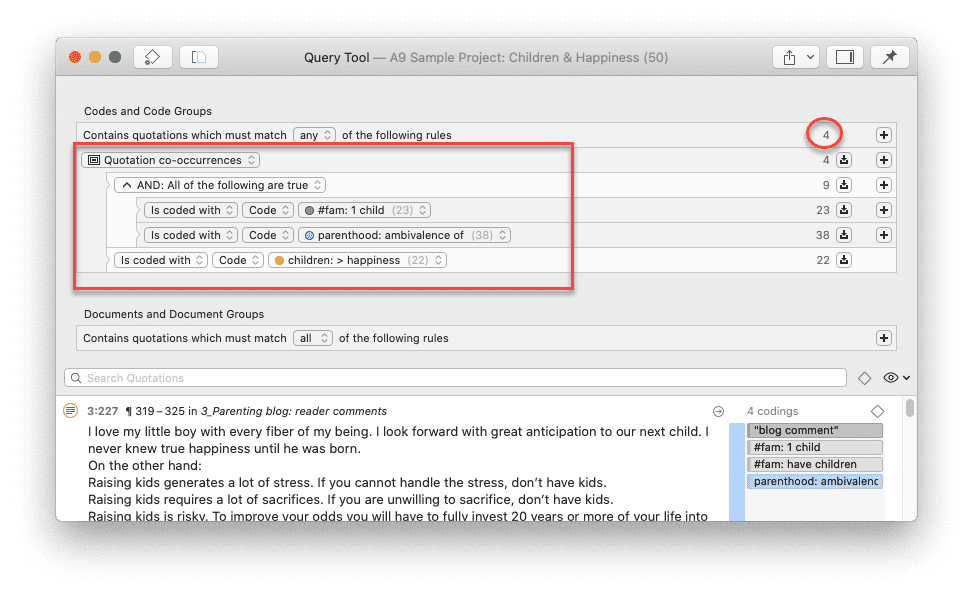
La siguiente imagen muestra una de las citas resultantes:

Para explorar los datos más a fondo, se pueden intercambiar los nodos individuales de la consulta; por ejemplo, para ver si también hay comentarios que coincidan con los mismos criterios para personas con dos hijos, o para encontrar comentarios en los que personas con 1 o 2 o más hijos escriben que tener hijos les hizo menos felices.
Ejemplo 2
El objetivo es encontrar todos los comentarios de blog escritos por personas que expresaron que los hijos les hacen felices, y que NO están codificados con el código 'paternidad: ambivalencia'.
Aquí se deben definir dos condiciones que ambas deben cumplirse:
- Comentarios de blog que contienen declaraciones de que los hijos significan > felicidad.
- Todas las citas que no han sido codificadas con 'paternidad: ambivalencia'. Como ambas condiciones deben ser verdaderas, es necesario usar el operador AND para combinarlas:
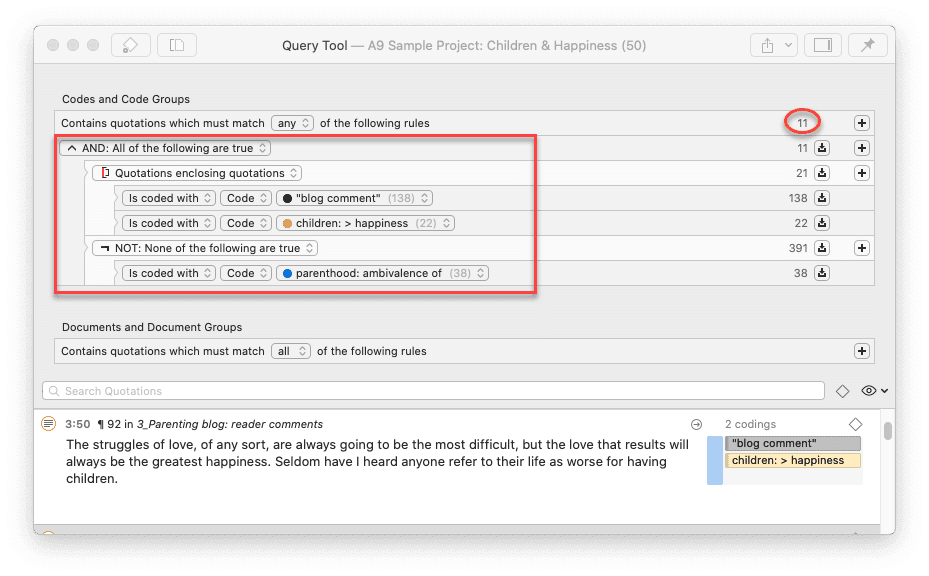
La consulta arroja 11 citas. En la imagen anterior se muestra uno de los resultados.
Restringir una consulta a subgrupos de los datos
Tutorial en vídeo: Herramienta de consulta con ámbito
Apertura de la herramienta de ámbito
Si desea restringir una búsqueda a un documento o grupo de documentos particular, por ejemplo porque le interesa comparar encuestados masculinos y femeninos, puede añadir un filtro de documento o grupo de documentos a una consulta.
Debajo del área donde se introduce la consulta de códigos, puede seleccionar documentos o grupos de documentos, o combinarlos usando operadores booleanos.
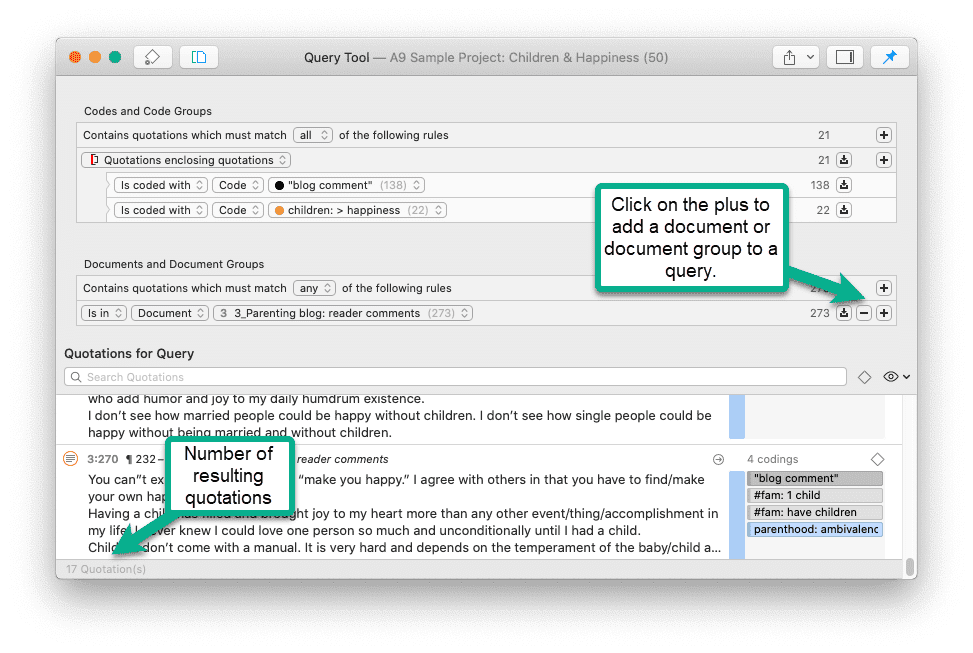
Haga clic en el botón más (+) para añadir una nueva línea. Seleccione 'está en' 'Documento' o 'Grupo de documentos', y seleccione un documento o grupo de documentos.
En lugar de 'está en', también puede seleccionar uno de los siguientes operadores booleanos: OR, Exactamente uno, AND o NOT. En la imagen a continuación, la consulta de códigos está limitada a una combinación de dos grupos de documentos, es decir, citas encontradas en documentos de encuestadas con título de bachillerato.
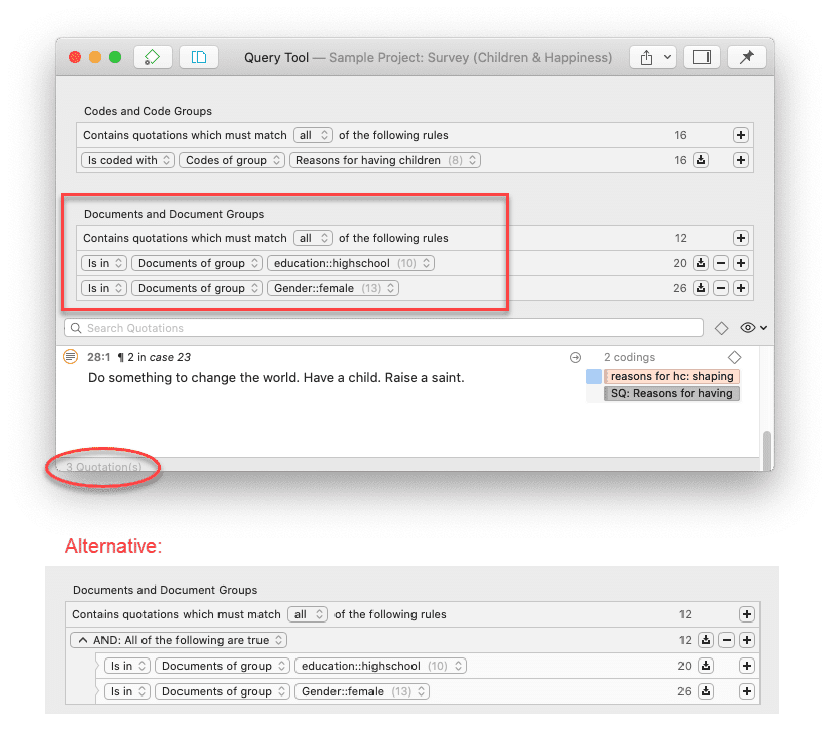
Almacenamiento de los resultados de una consulta
Puede almacenar los resultados de una consulta como código inteligente para reutilizarlos en el futuro. Puede obtener más información sobre los códigos inteligentes aquí.
Después de haber creado una consulta, haga clic en el botón Código inteligente en la barra de herramientas.
Introduzca un nombre para el código inteligente y haga clic en Crear.
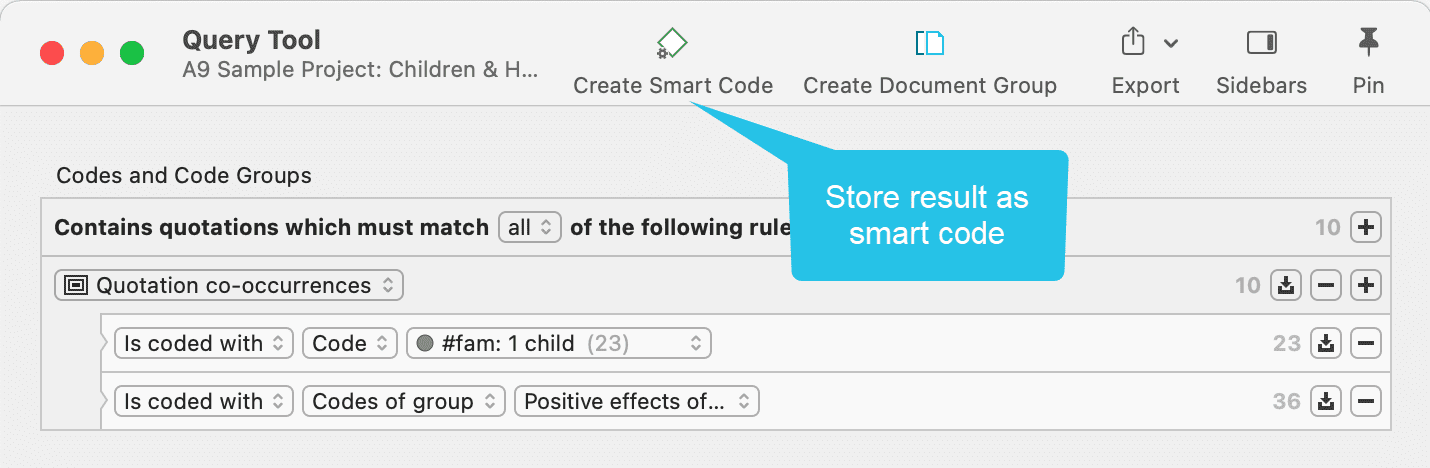
Un código inteligente siempre contiene las citas de todo el proyecto. Si estableció un ámbito para restringir la consulta a ciertos documentos o grupos de documentos, esto no se guarda en el código inteligente.
Ahora puede revisar todas las citas de esta consulta, por ejemplo en el Administrador de códigos o en el Administrador de citas, en cualquier momento. Si realiza cambios en la codificación, el código inteligente siempre mostrará los resultados actualizados.
Los códigos inteligentes se reconocen por el punto gris en la parte inferior izquierda del icono del código. Consulte Trabajar con códigos inteligentes para más información.
Si el resultado de una consulta proporciona las citas necesarias para responder a una pregunta de investigación, un código inteligente puede ser una forma conveniente de almacenar ese resultado. Esto puede reflejarse en el nombre del código inteligente, por ejemplo, Pregunta de investigación 3: Visiones positivas y negativas sobre la paternidad.
Creación de grupos de documentos a partir de resultados
Al agregar documentos a un proyecto, es sencillo crear grupos de documentos basados en características de la muestra, como género, edad, profesión, ubicación, etc.
En ocasiones, primero es necesario codificar los datos para encontrar información relevante, como años de experiencia laboral, habilidades especiales, actitudes hacia algo, relaciones con otras personas, etc. Para ello se necesita una opción que permita crear grupos de documentos a partir de los resultados de una consulta.
Cree una consulta. Consulte, por ejemplo, Consulta booleana de ejemplo. Haga clic en el botón Grupo de documentos en la barra de herramientas, introduzca un nombre para el nuevo grupo y haga clic en Crear.
ATLAS.ti crea un nuevo grupo a partir de todos los documentos que generan resultados de citas en función de la consulta.
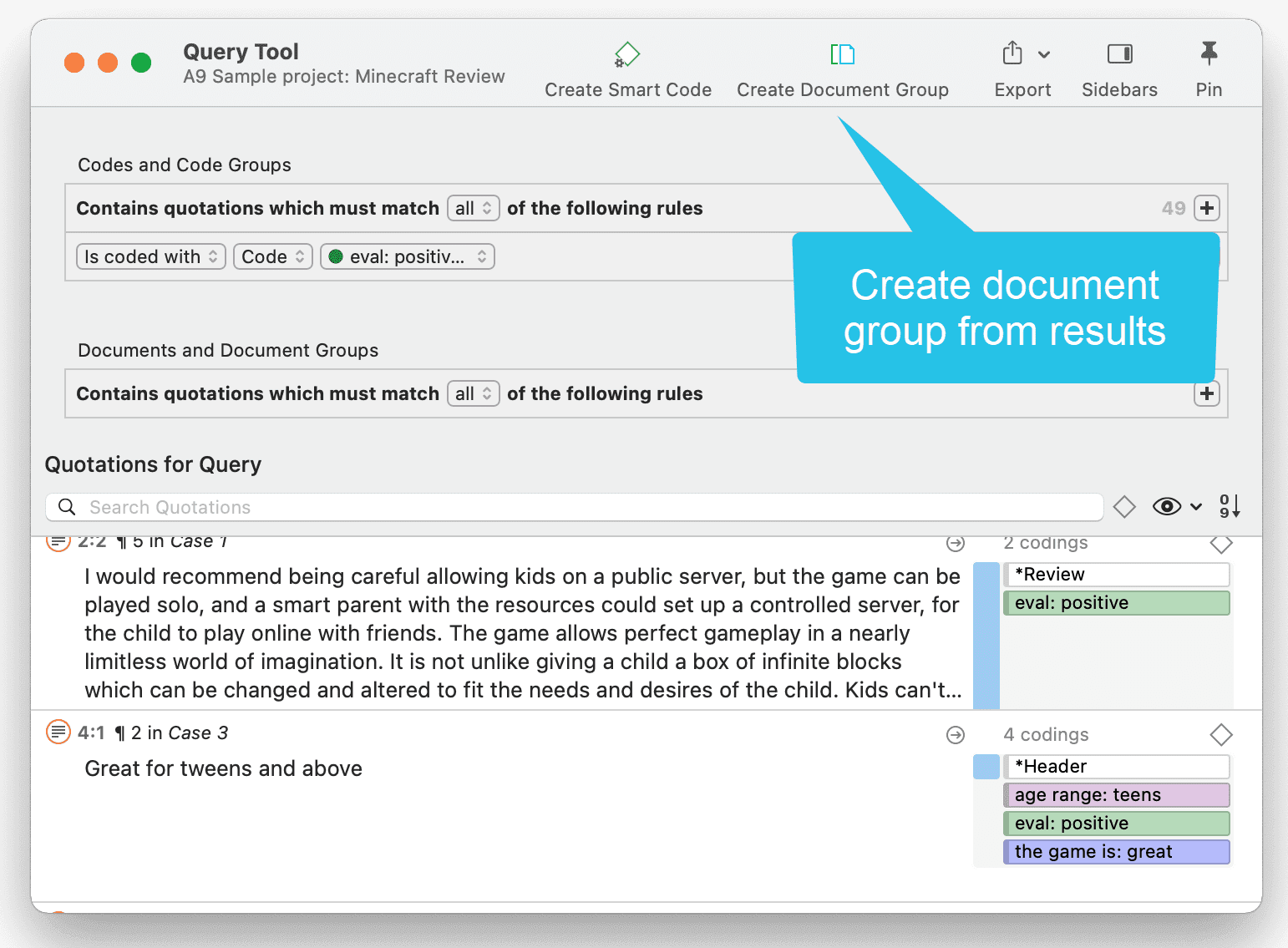
La consulta puede ser tan simple como seleccionar un único código.
Por ejemplo, si ha codificado la experiencia laboral:
- experiencia laboral: 0 - 5 años
- experiencia laboral: 6 - 10 años
- experiencia laboral: 10 - 15 años
- experiencia laboral: > 15 años
Simplemente agregue el código 'experiencia laboral: 0 - 5 años' y haga clic en el botón Grupo de documentos para crear un grupo de documentos con todos los encuestados que tienen una experiencia laboral de 0 a 5 años. Luego agregue el código 'experiencia laboral: 6 - 10 años' y cree un grupo de documentos, y así sucesivamente.
Informes de la herramienta de consulta
Exportar como hoja de cálculo
Para crear un informe, abra el menú desplegable del botón de informe en la barra de herramientas y seleccione Exportar como hoja de cálculo. El contenido del informe es el mismo que el del Lector de citas o el Administrador de citas. Contiene todas las columnas del Administrador de citas.
Exportar como informe
Al utilizar esta opción, se obtiene un informe en formato de texto o PDF. El informe es configurable, lo que significa que se puede seleccionar qué debe contener. Antes de crear el informe, se muestra una vista previa.
Haga clic en el menú desplegable del botón de informe en la barra de herramientas y seleccione Exportar como informe.
En el lado izquierdo se muestra el aspecto del informe según las selecciones actuales. En el lado derecho, se pueden seleccionar más opciones:
-
Filtro: Si seleccionó elementos antes de hacer clic en el botón de informe, puede elegir entre crear un informe solo para los elementos seleccionados o para todos.
-
Agrupación: Puede agrupar el informe por códigos, grupos de códigos, documentos, grupos de documentos, tipo de documento, usuario de creación y usuario de modificación. Seleccione una opción de agrupación si corresponde.
Si selecciona agrupar las citas por código y una cita está codificada con varios grupos de códigos, las citas de ese código aparecerán varias veces en el informe.
Si selecciona agrupar por grupos de códigos y un código pertenece a varios grupos de códigos, las citas de ese código aparecerán varias veces en el informe. Lo mismo se aplica a los grupos de documentos.
Opciones del informe
En este campo, puede seleccionar qué contenido debe mostrarse en el informe. En cuanto seleccione una opción, verá en la vista previa cómo se verá en el informe. Consulte a continuación para más detalles.
-
Tipo de contenido: texto, imagen, geo, audio o vídeo.
-
Añadir el usuario de creación y modificación al informe.
-
en Documento: Añade el nombre del documento al informe. Si está seleccionado, puede añadir más información sobre el documento desde el subárbol.
-
Codificación: Añade los códigos aplicados a la cita al informe. Si está seleccionado, puede añadir más información sobre los códigos desde el subárbol.
-
Hipervínculos: Añade las citas vinculadas a una cita al informe. Si está seleccionado, puede añadir más información sobre las citas vinculadas desde el subárbol, como su contenido.
-
Memos vinculados: Añade los memos vinculados a la cita al informe. Si está seleccionado, puede añadir más información sobre el memo desde el subárbol, como el contenido del memo.
-
Contenido: Está seleccionado por defecto. Si está seleccionado, se muestra el contenido de la cita.
-
Comentarios: Añade el comentario escrito para una cita al informe.
Guardar o imprimir
-
Guardar: Guarda el informe como documento de Word. Seleccione un nombre para el informe y una ubicación.
-
Imprimir: Puede enviar el informe directamente a una impresora e imprimirlo, o guardarlo como archivo PDF. Otras opciones son:
- Guardar como PostScript
- Enviar por correo
- Enviar a través de Mensajes
- Guardar en iCloud Drive
- Guardar en Recibos web
Análisis de códigos y documentos
Puede utilizar el Análisis de códigos y documentos para comparaciones dentro de documentos y entre documentos o grupos, relacionando códigos o grupos de códigos con documentos o grupos de documentos.
Las celdas de la tabla contienen:
-
Recuento de frecuencia del número de codificaciones. Esto puede diferir del número de citas si una cita está codificada por varios códigos. Se cuenta cada vínculo entre un código y una cita.
-
Recuento de palabras de las citas codificadas por el código o grupo de códigos seleccionado.
Ejecución de un análisis en la tabla de códigos y documentos
En el menú principal, seleccione Análisis > Análisis de códigos y documentos.
Seleccione códigos o grupos de códigos para las filas de la tabla. Los códigos / grupos de códigos seleccionados se añaden a la tabla.
Seleccione documentos o grupos de documentos para las columnas de la tabla. Los documentos / grupos de documentos seleccionados se añaden a la tabla.
Cómo hacer selecciones: Para seleccionar un elemento, hay que hacer clic en la casilla de verificación que aparece delante de él. También es posible seleccionar varios elementos mediante las técnicas de selección estándar usando las teclas Ctrl/Cmd o Shift. Después de resaltar varios elementos, pulse la barra espaciadora para activar las casillas de verificación de todos los elementos seleccionados, o haga clic derecho y elija Verificar seleccionados.
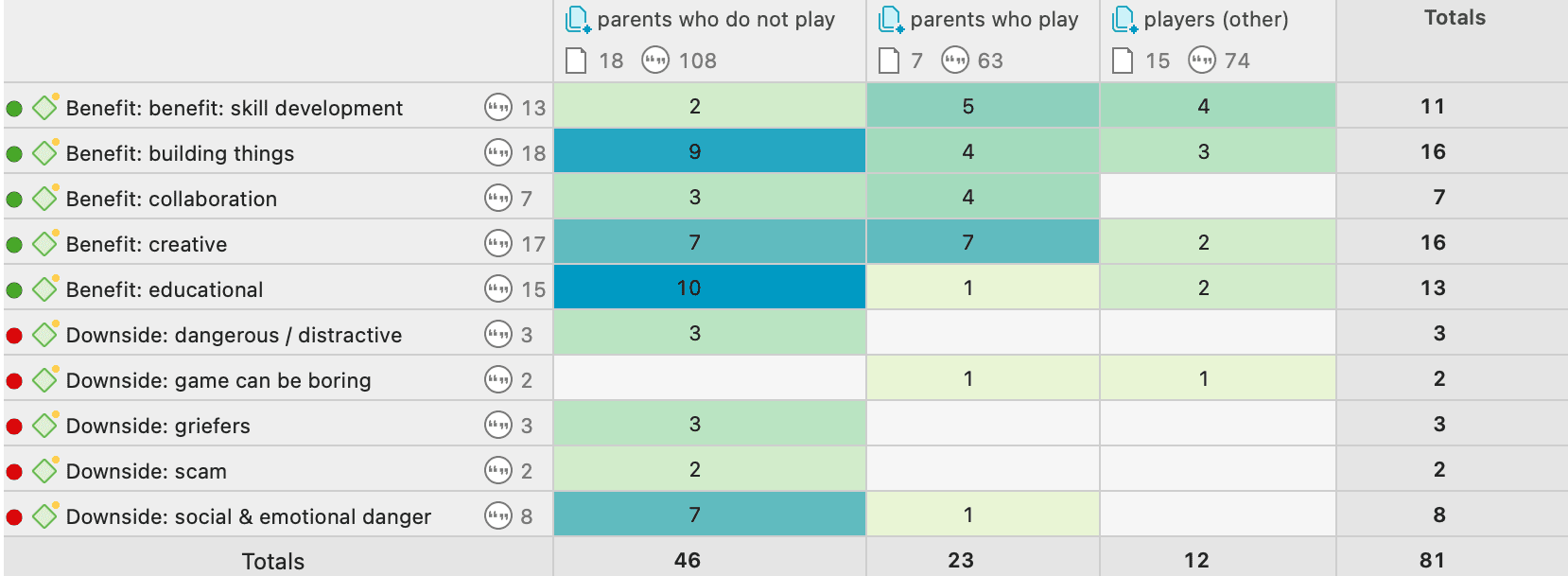
Cómo leer la tabla
De forma predeterminada, los códigos / grupos de códigos se muestran en la columna izquierda y los documentos / grupos de documentos en la fila superior.
Columna izquierda
-
Junto a cada código, el número indica cuántas veces se aplica el código en todo el proyecto.
-
Junto a un grupo de códigos, aparecen dos números: el primero indica cuántos códigos hay en el grupo; el segundo número indica el número de codificaciones. Esto difiere del número de citas, ya que varios códigos del mismo grupo de códigos podrían estar vinculados a la misma cita.
Fila superior
-
Debajo de un documento, se ve el número total de citas en cada documento.
-
Debajo de un grupo de documentos, aparecen dos números: el primero indica cuántos documentos hay en el grupo de documentos, y el segundo número indica el número de citas de todos los documentos del grupo.
La información adicional que se obtiene para cada elemento de fila o columna seleccionado permite evaluar mejor los números dentro de las celdas de la tabla. Si el valor en la celda es 10, pero el código se aplicó en total 100 veces, esto lleva a una interpretación diferente que si el código solo se aplicó 12 veces en todo el proyecto.
Celdas de la tabla
-
Los resultados en las celdas de la tabla muestran cuántas veces se aplicó cada código seleccionado (o los códigos de un grupo de códigos) en cada documento o grupo de documentos. Se cuentan los número de codificaciones, a menos que se seleccione contar palabras (véanse las opciones).
-
Si hace clic en una celda de la tabla, el contenido de las citas se muestra en el Lector de citas en el lado izquierdo.
-
Debajo de la tabla se muestra un diagrama de Sankey. Puede ver ambos al mismo tiempo, o ver solo la tabla o el diagrama de Sankey. Véase más adelante.
Barra de herramientas del análisis de códigos y documentos

Comprimir: Esta es una forma rápida de eliminar todas las filas o columnas que solo muestran celdas vacías. Es equivalente a desactivar manualmente los códigos o documentos que no arrojan resultados. Por tanto, no es posible descomprimir una tabla.
Modo de vista: En Modo de vista, puede cambiar entre Vista de tabla, Diagrama de Sankey o Gráfico de columnas.

La visualización de tabla está disponible como diagrama de Sankey o gráfico de barras. A continuación se muestra un ejemplo de diagrama de Sankey en modo claro.
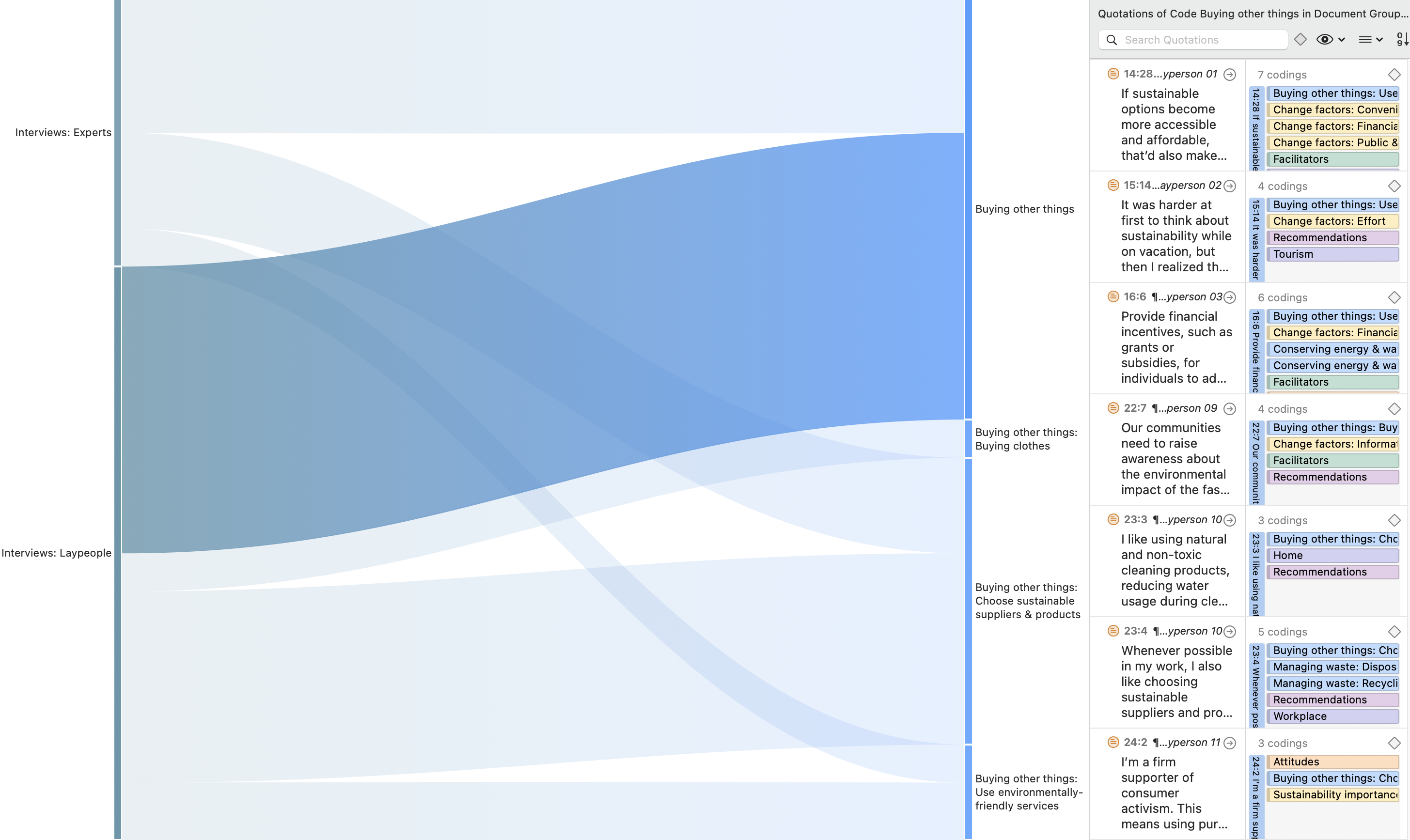
Opciones: Véase más adelante.
Exportar: Puede exportar la tabla como hoja de cálculo de Excel, y el diagrama de Sankey y el gráfico de columnas como archivos de imagen PNG.
Opciones del análisis de códigos y documentos
Haga clic en el botón opciones para abrir el panel de opciones.
Encabezados: Puede ocultar la información adicional sobre el número de citas por código o documento / número de miembros en un grupo que se muestra en los encabezados de la tabla.
Incluir: Muestra/oculta los totales de fila o columna.
Mostrar frecuencias: Puede mostrar frecuencias absolutas, o frecuencias relativas de fila / columna / tabla.
Frecuencias absolutas: Las celdas de la tabla muestran el número de codificaciones. Este es el número de veces que un código está vinculado a una cita. Para los códigos individuales, el número de codificaciones es el mismo que el número de citas, pero para los grupos de códigos puede diferir si los códigos que pertenecen al mismo grupo de códigos se han aplicado a la misma cita.
-
Frec. relativas de columna: Las celdas de la tabla muestran frecuencias relativas basadas en las celdas de la columna. El total de cada columna sumará el 100%.
-
Frec. relativas de fila: Las celdas de la tabla muestran frecuencias relativas basadas en las celdas de la fila. El total de cada fila sumará el 100%.
-
Frec. relativas de tabla: Muestra frecuencias relativas basadas en todos los códigos usados en la tabla. Los totales de todos los códigos de filas y columnas sumarán el 100%.
-
Recuento: Puede seleccionar contar el número de codificaciones o el número de palabras de las citas.
-
Contar codificaciones: Cuenta el número de veces que un código se ha aplicado a una cita. Tenga en cuenta que el número de codificaciones puede ser mayor que el número de citas si se usan grupos de códigos, ya que puede aplicar varios códigos a una misma cita.
-
Contar palabras: Cuenta las palabras de las citas codificadas por el código seleccionado, o los códigos del grupo de códigos seleccionado.
Normalizar: Si los documentos tienen longitudes desiguales, o los grupos de documentos tienen tamaños desiguales, las frecuencias absolutas pueden ser engañosas como medida de comparación. Son indicativos el número total de citas en un documento o grupo de documentos (véase la fila superior).
Si normaliza los datos, el número de codificaciones se ajusta. Como referencia, se utiliza la columna o fila de documento / grupo de documentos con el total más alto. Por ejemplo, si compara dos documentos y el número total de codificaciones del primer documento es 100 y del segundo documento es 50, entonces todas las codificaciones del segundo documento se multiplican por 100/50 = 2. Consulte Normalización de datos.
Binarizar tabla: Esta opción reduce todos los valores de las celdas a 0 y 1. Muestra si un código, o los códigos de un grupo de códigos, aparecen o no en un documento o grupo de documentos. Si aparecen, se muestra un punto negro; si no, la celda está vacía. Esto facilita la identificación de patrones en los datos.
Cuando exporta la tabla a Excel, los puntos se convierten en 1 y las celdas vacías en 0. Esto permite, por ejemplo, realizar un análisis discriminante en un programa estadístico. Consulte Binarizar tabla.
Orientación: Cambia filas y columnas.
Opciones de diseño del análisis de códigos y documentos
Si necesita más espacio en su pantalla, puede ocultar las dos listas de la derecha y la izquierda (ámbito y citas).
Si desea más espacio para las visualizaciones, puede ocultar la tabla.
La visualización de tabla está disponible como diagrama de Sankey o gráfico de barras. A continuación se muestra un ejemplo de diagrama de Sankey en modo oscuro.
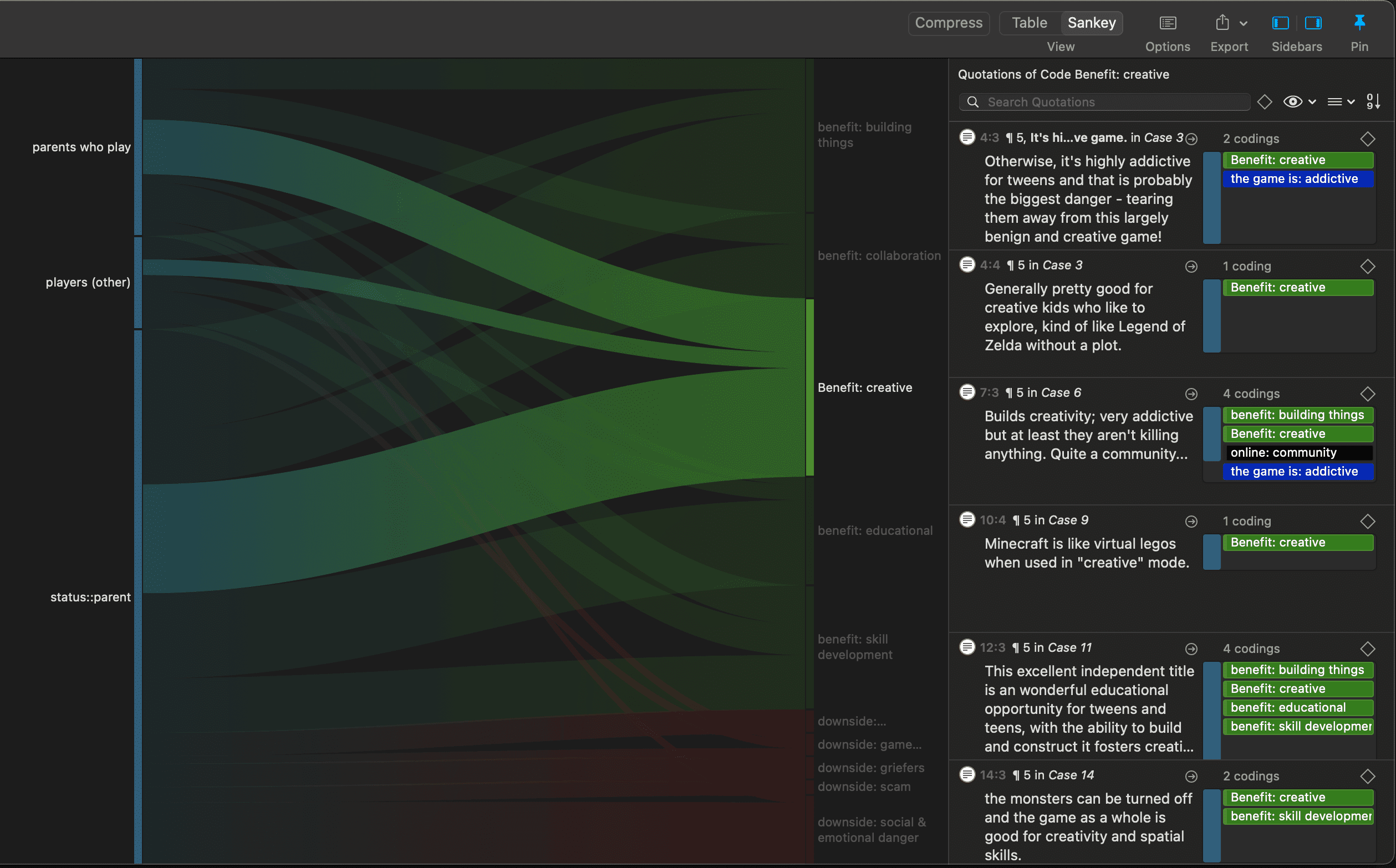
Análisis de códigos y documentos: frecuencias relativas
Las frecuencias relativas son útiles para comparar distribuciones de códigos entre documentos o grupos de documentos, o dentro de ellos, ya que los porcentajes son más fáciles de comprender.
Si los documentos tienen longitudes desiguales, o si los grupos de documentos tienen un número desigual de miembros, se recomienda normalizar los recuentos, ya que los recuentos absolutos pueden distorsionar los resultados. Consulte Normalización de datos.
Comparación entre grupos: frecuencias relativas de fila
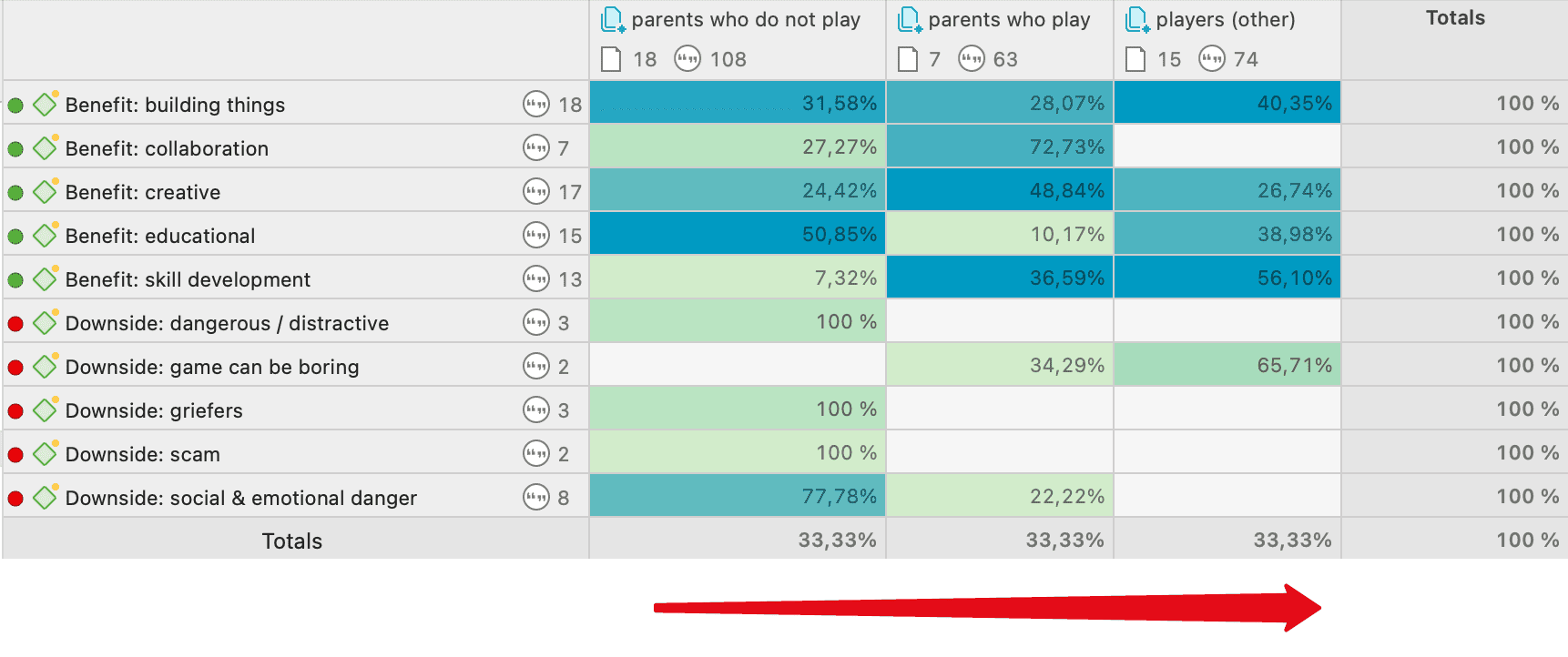
La tabla muestra datos de entrevistas sobre sostenibilidad. Puede descargar el proyecto aquí.
Esta tabla debe leerse de izquierda a derecha a lo largo de las filas. Muestra la distribución de los códigos seleccionados en los dos grupos de documentos siguientes:
Entrevistas con expertos y entrevistas con personas no especializadas. Un vistazo rápido al mapa de calor sugiere que los expertos hablaron más sobre el transporte público como opción de transporte sostenible, mientras que las personas no especializadas hablaron más sobre el transporte activo, como caminar o ir en bicicleta.
Si debe seleccionar frecuencias relativas de fila o de columna depende de la orientación en que se muestre la tabla. Si los documentos/grupos de documentos están listados como filas y los códigos como columnas, se usan frecuencias relativas de fila para una comparación dentro del grupo.
Comparaciones dentro del grupo: frecuencias relativas de columna
El siguiente ejemplo pertenece al proyecto de muestra: Children & Happiness. Se compara en qué tipo de relaciones los lectores escribieron sobre experiencias positivas y negativas de la paternidad.
Esta tabla del proyecto de muestra de Sostenibilidad compara cómo expertos y personas no especializadas discutieron las barreras (dificultades para adoptar comportamientos sostenibles) y los facilitadores (factores que facilitan el estilo de vida sostenible) en la vida cotidiana.

Como puede observarse en la tabla, las entrevistas con expertos mencionan los factores que facilitan el estilo de vida sostenible en la vida cotidiana ligeramente más a menudo que las entrevistas con personas no especializadas.
Frecuencias relativas totales
Si selecciona frecuencias relativas totales, el cálculo se basa en el número total de codificaciones de todos los códigos seleccionados en la tabla. A continuación se compara quién ha aportado más o menos razones para tener o no tener hijos:
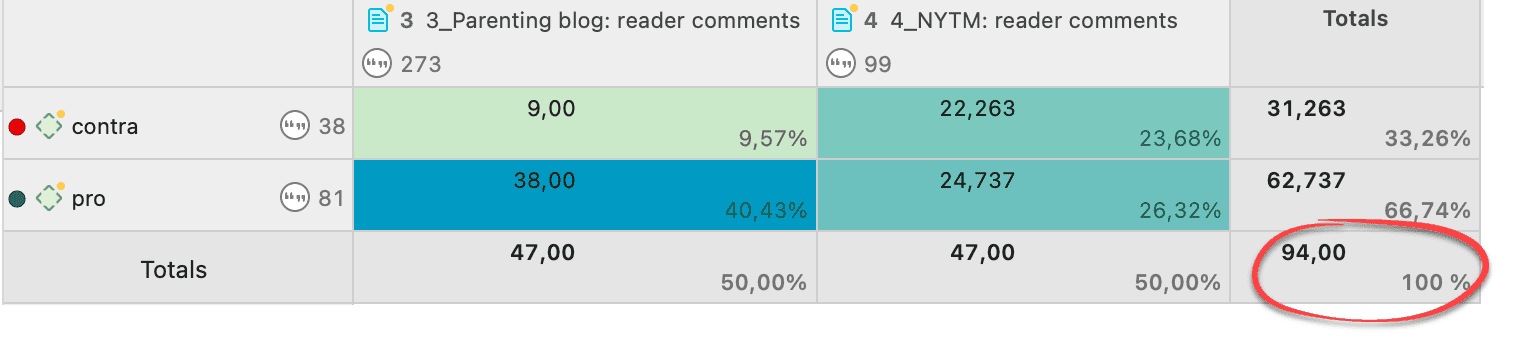
Ambos grupos de participantes hablaron ampliamente sobre los costes y beneficios financieros relacionados con el estilo de vida sostenible. Los expertos contribuyeron con 30,33 de 168 en total (18,06%), mientras que las personas no especializadas contribuyeron con 24 de 168 (14,29%), lo que indica que los expertos hablaron más sobre cómo los costes y beneficios financieros pueden influir en las actitudes de las personas hacia la sostenibilidad.
Puede mostrar todos los valores: frecuencias absolutas y todas las frecuencias relativas en una sola tabla seleccionando todas las opciones. Depende del propósito para el que desee usar la tabla. Para interpretar los datos, probablemente sea más fácil examinar cada uno de los recuentos de frecuencias relativas por separado. Para un informe completo en un apéndice, puede exportar la tabla con todas las opciones incluidas.
Tabla de códigos y documentos: normalización
Si los documentos tienen longitudes desiguales, o los grupos de documentos tienen tamaños desiguales, las frecuencias absolutas pueden ser engañosas como medida de comparación. Si realiza entrevistas y algunas solo duran media hora mientras que otras duran 2 horas, la probabilidad de que alguien hable sobre ciertos temas y con qué frecuencia durante la entrevista es mayor en las entrevistas largas. Por tanto, si se compararan números absolutos, los resultados podrían reflejar únicamente las diferentes duraciones de las entrevistas. Lo mismo ocurre si se analizan informes. Si un informe tiene 25 páginas y otro 100, y se codifican los informes completos, las frecuencias absolutas no son una medida válida para la comparación. El número total de citas en un documento o en un grupo de documentos (véase la primera fila) puede ayudar a decidir si la normalización de los datos es apropiada.
Si normaliza los datos, el número de codificaciones se ajusta. Como referencia, se utiliza la columna o fila de documento / grupo de documentos con el total más alto. Las imágenes a continuación muestran un ejemplo.
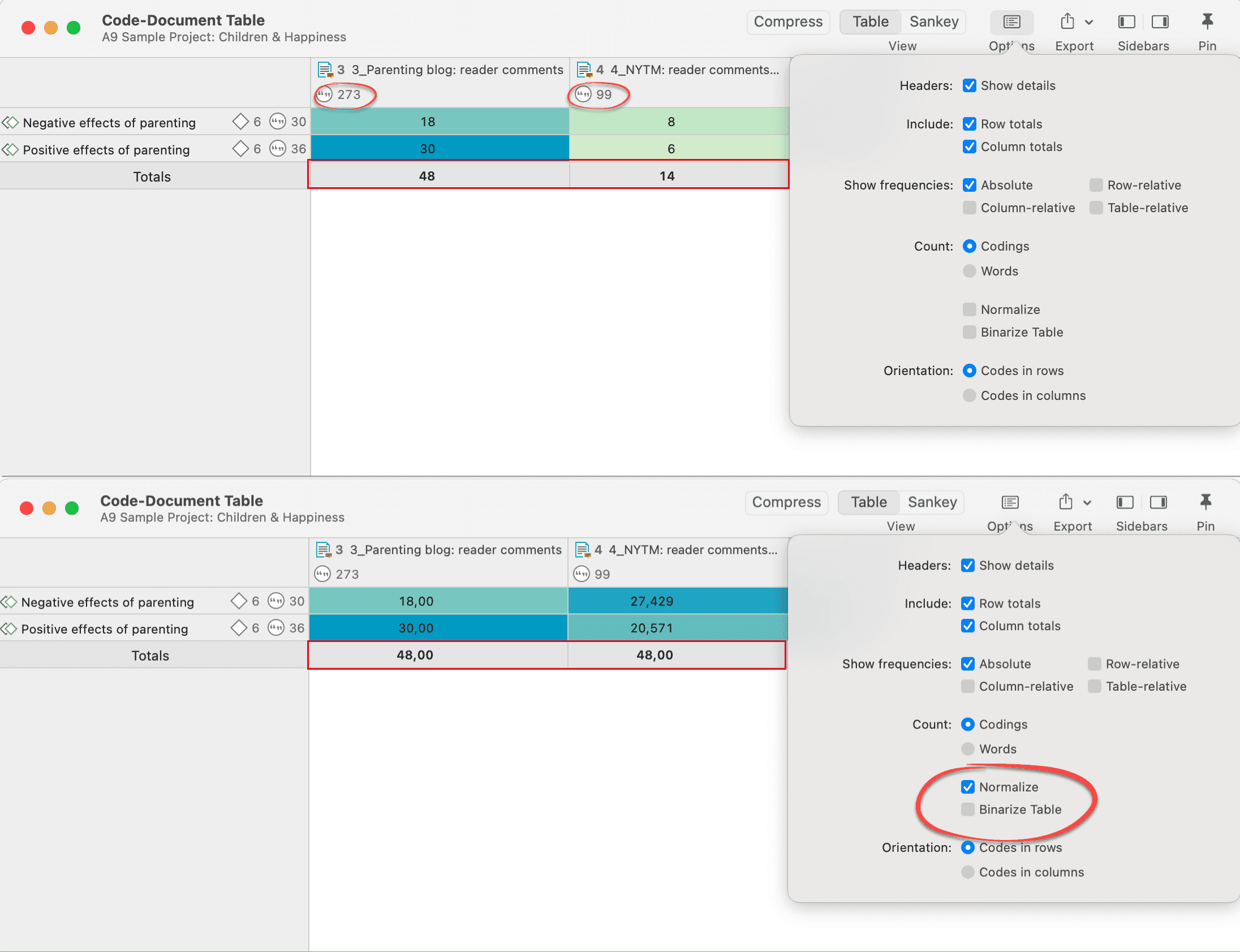
El número de citas en cada documento es muy diferente: 273 frente a 99. De hecho, el documento 3 también es tres veces más largo que el documento 4. Por tanto, no es sorprendente que contenga más citas. Interpretar los resultados numéricos basándose en números absolutos sería engañoso. Al normalizar los datos, el recuento de citas del código seleccionado para el documento con el menor número de citas se ajusta; en este caso, por el factor 48/14 = 3,428 (redondeado al tercer dígito).
Como puede verse en la tabla con los datos normalizados, esto cambia los resultados y también la interpretación. Dado que no es necesario basarse en los números al trabajar con ATLAS.ti, puede hacer clic en cada celda y leer los datos que la respaldan, antes de escribir los resultados en un memo.
Como la normalización a menudo genera números irregulares, es útil trabajar con frecuencias relativas en lugar de absolutas. Consulte Frecuencias relativas.
Binarizar los resultados de una tabla de códigos y documentos
En ocasiones, puede que solo le interese saber si un código aparece o no en un documento.
Para activar esta opción, haga clic en el icono de rueda dentada y seleccione Binarizar tabla.
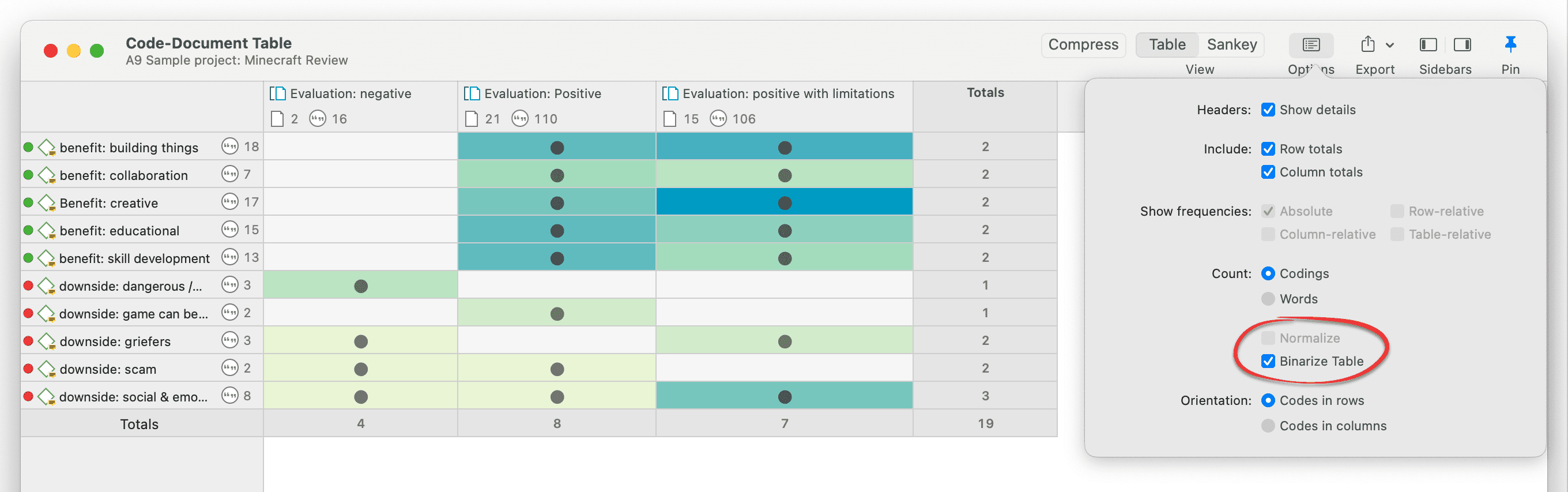
Tabla de códigos y documentos con datos binarizados
La tabla mostrará puntos negros si un código o los códigos de un grupo de códigos se han aplicado a un documento o grupo de documentos. Si no se ha aplicado, la celda está vacía.
Los totales de filas y columnas cuentan el número de ocurrencias afirmativas / negativas. Este tipo de tabla puede usarse, por ejemplo, para un análisis discriminante en un programa estadístico.
Si exporta la tabla a Excel, la tabla de Excel mostrará 1 y 0. Esto permite, por ejemplo, realizar un análisis discriminante en un programa estadístico.
Tabla exportada a Excel:
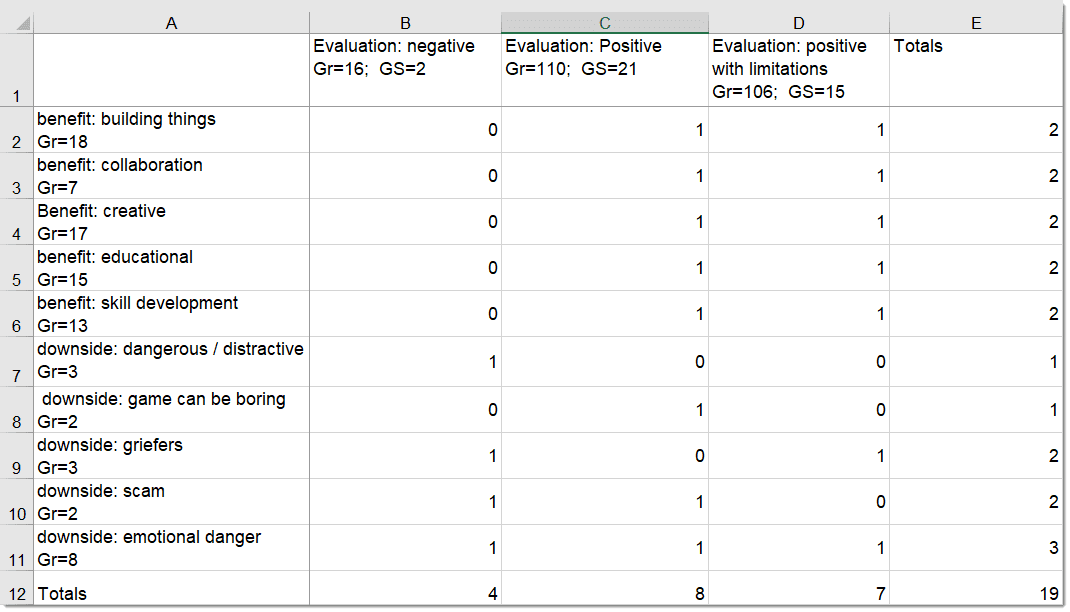
Visualización de la tabla de códigos y documentos
Diagrama de Sankey
La visualización de datos es una excelente forma de simplificar la complejidad de la comprensión de las relaciones entre los datos. El diagrama de Sankey es una de esas potentes técnicas para visualizar la asociación de elementos de datos. Originalmente, los diagramas de Sankey recibieron su nombre del capitán irlandés Matthew Henry Phineas Riall Sankey, quien utilizó este tipo de diagrama en 1898 en una figura clásica que mostraba la eficiencia energética de una máquina de vapor. Hoy en día, los diagramas de Sankey se usan para presentar flujos de datos y conexiones entre datos en diversas disciplinas.
-
Los diagramas de Sankey permiten mostrar procesos complejos visualmente, con énfasis en un aspecto o recurso concreto que se desea destacar.
-
Ofrecen el beneficio adicional de admitir múltiples niveles de visualización. Los espectadores pueden obtener una vista general, ver detalles específicos o generar vistas interactivas.
-
Los diagramas de Sankey hacen que los factores dominantes destaquen, y ayudan a ver las magnitudes relativas y/o las áreas con las mayores contribuciones.
En ATLAS.ti, el diagrama de Sankey complementa la tabla de co-ocurrencias de códigos. Tan pronto como se crea una tabla, aparece debajo de ella un diagrama de Sankey que visualiza los datos.
Lecturas adicionales
-
Cómo usar diagramas de Sankey para contar una historia con datos
-
Visualización del recorrido del cliente con diagrama de Sankey
Tan pronto como crea la tabla de códigos y documentos, aparece un gráfico de barras en el área debajo de la tabla. Para ver un diagrama de Sankey en su lugar, haga clic en el botón Sankey en la barra de herramientas.
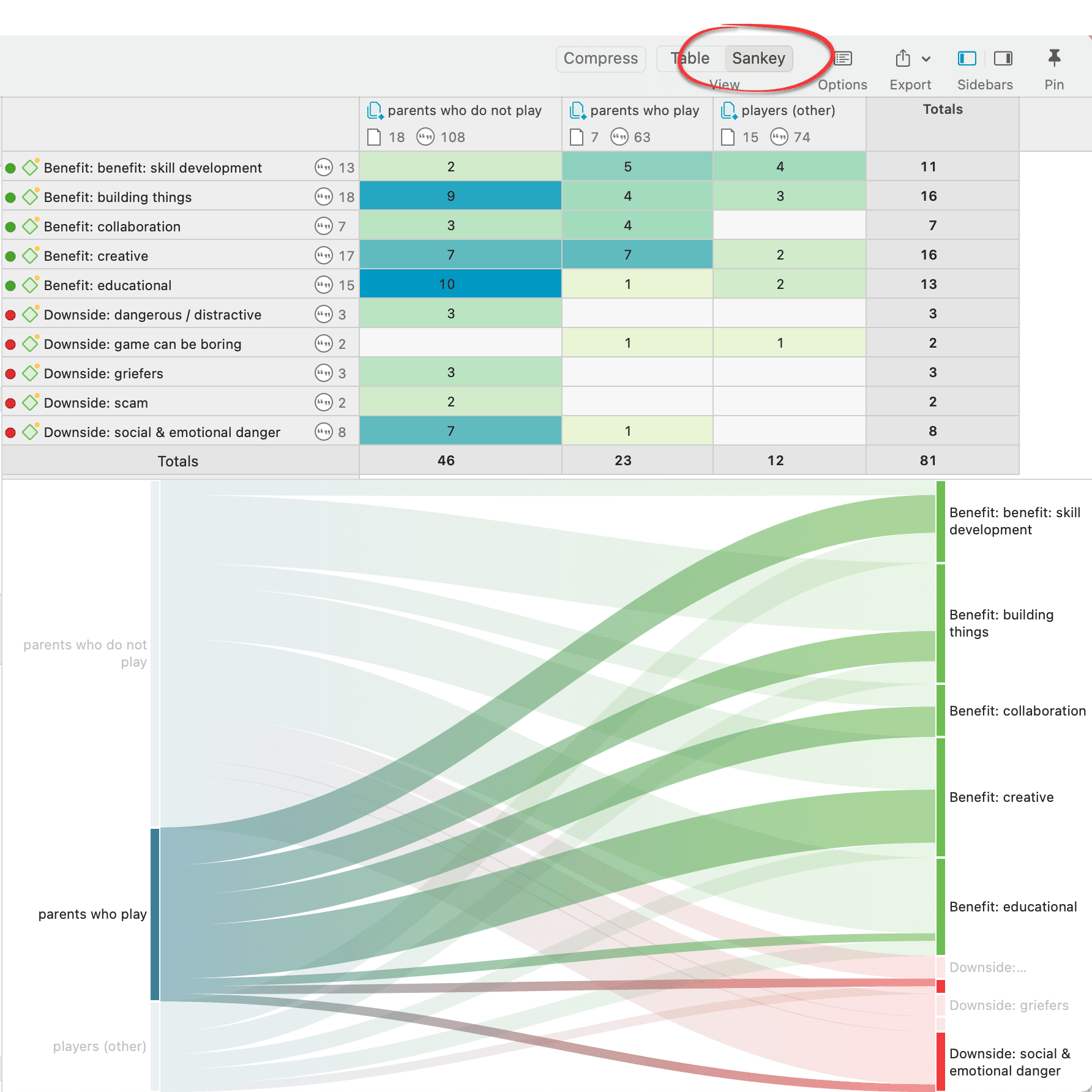
Las entidades de filas y columnas de la tabla se representan en el modelo de Sankey como nodos y aristas, mostrando la intensidad de la co-ocurrencia entre los pares de nodos. En la tabla de códigos y documentos, los pares conectados pueden estar formados por:
- códigos - documentos
- códigos - grupos de documentos
- grupos de códigos - documentos
- grupos de códigos - grupos de documentos
Arista: Para cada celda de la tabla que contiene un valor, se muestra una arista entre los nodos del diagrama. El grosor de las aristas refleja los valores de las celdas de la tabla. Las celdas con valor 0 no se muestran en la vista de Sankey.
La clave para leer e interpretar los diagramas de Sankey es recordar que el ancho es proporcional a la cantidad representada.
Diseño
El diagrama de Sankey, de manera similar al editor de redes, aplica un diseño para sus nodos y, en consecuencia, para las aristas que conectan los nodos, con el fin de crear una visualización fácil de comprender. Este diseño básico coloca las entidades seleccionadas (nodos en terminología Sankey) en «capas» verticales, con las entidades de filas a la izquierda y las entidades de columnas a la derecha. Si los nodos tienen vínculos tanto entrantes como salientes en el conjunto de nodos visible actualmente, se colocarán en carriles o capas intermedias.
Interactividad
-
Para mostrar las citas responsables de la co-ocurrencia de dos entidades, haga clic en la arista de conexión. Esto tiene el mismo efecto que hacer clic en una celda de la tabla. Las citas se muestran en el Lector de citas a la derecha.
-
Si pasa el cursor del ratón sobre una arista, se muestran los números que también aparecen en las celdas de la tabla. De forma predeterminada, estos son el número de codificaciones en el documento o grupo de documentos seleccionado.

-
Para facilitar la identificación del vínculo correcto, al mover el ratón se resaltan las aristas sobre las que se pasa el cursor. Tras seleccionar una arista, las aristas no seleccionadas se atenúan para aumentar aún más la visibilidad de la arista considerada.
-
Al seleccionar un nodo, se resalta dicho nodo junto con todas sus aristas entrantes y salientes. Esto facilita identificar las áreas de conectividad.
Eliminación de aristas
Para eliminar un nodo del diagrama, haga clic derecho y seleccione Quitar de la vista.
Además de las opciones de Quitar de la vista, el menú contextual ofrece otras opciones, como por ejemplo cambiar el color del código.
Lo mismo puede conseguirse modificando las listas de selección, pero esto es un poco más «pesado» y puede no resultar claro qué entidades hay que deseleccionar.
Gráfico de barras
Tan pronto como crea una tabla de códigos y documentos, aparece un gráfico de barras en el área debajo de la tabla.
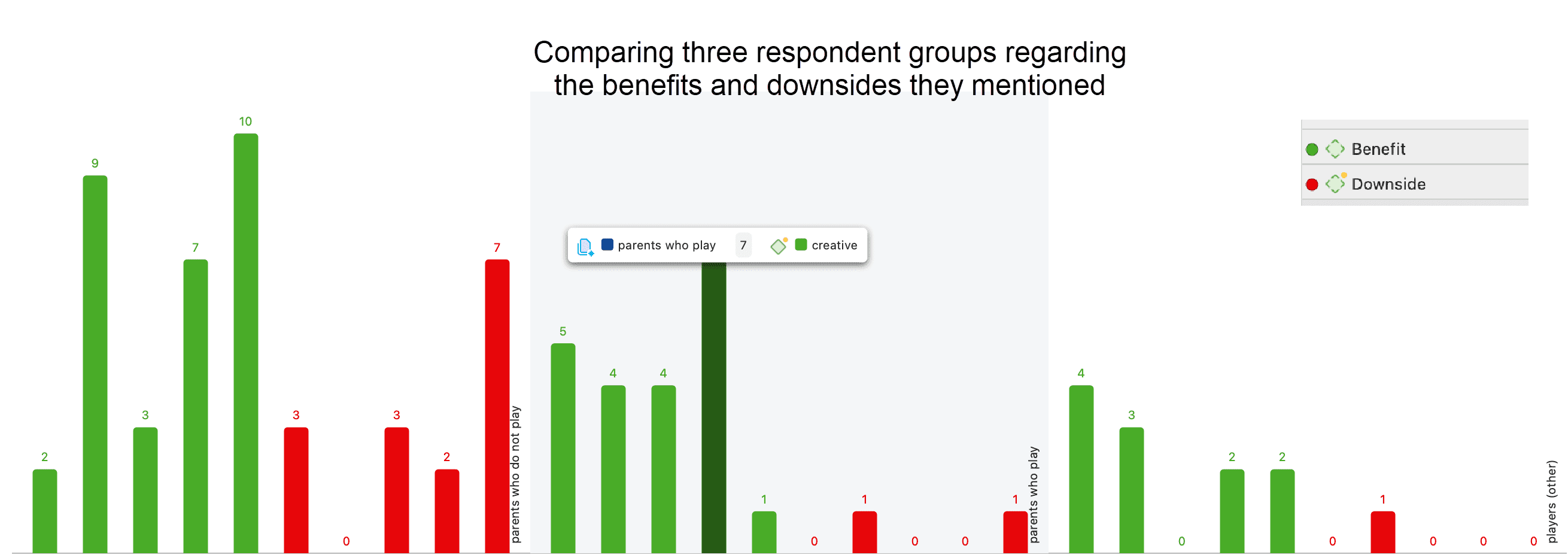
Si pasa el cursor sobre una barra, se muestra el par código (grupo de códigos) - documento (grupo de documentos).
Para la visualización como gráfico de barras, a menudo es preferible cambiar los colores de los códigos. También puede querer intercambiar las filas y las columnas. Esta opción se encuentra en la cinta de la tabla de códigos y documentos.
.
La tabla a continuación muestra la misma comparación que la anterior, pero esta vez se asignó un color diferente a cada subcódigo. Los subcódigos de beneficios van del verde al azul; los subcódigos de aspectos negativos van del rojo al amarillo.
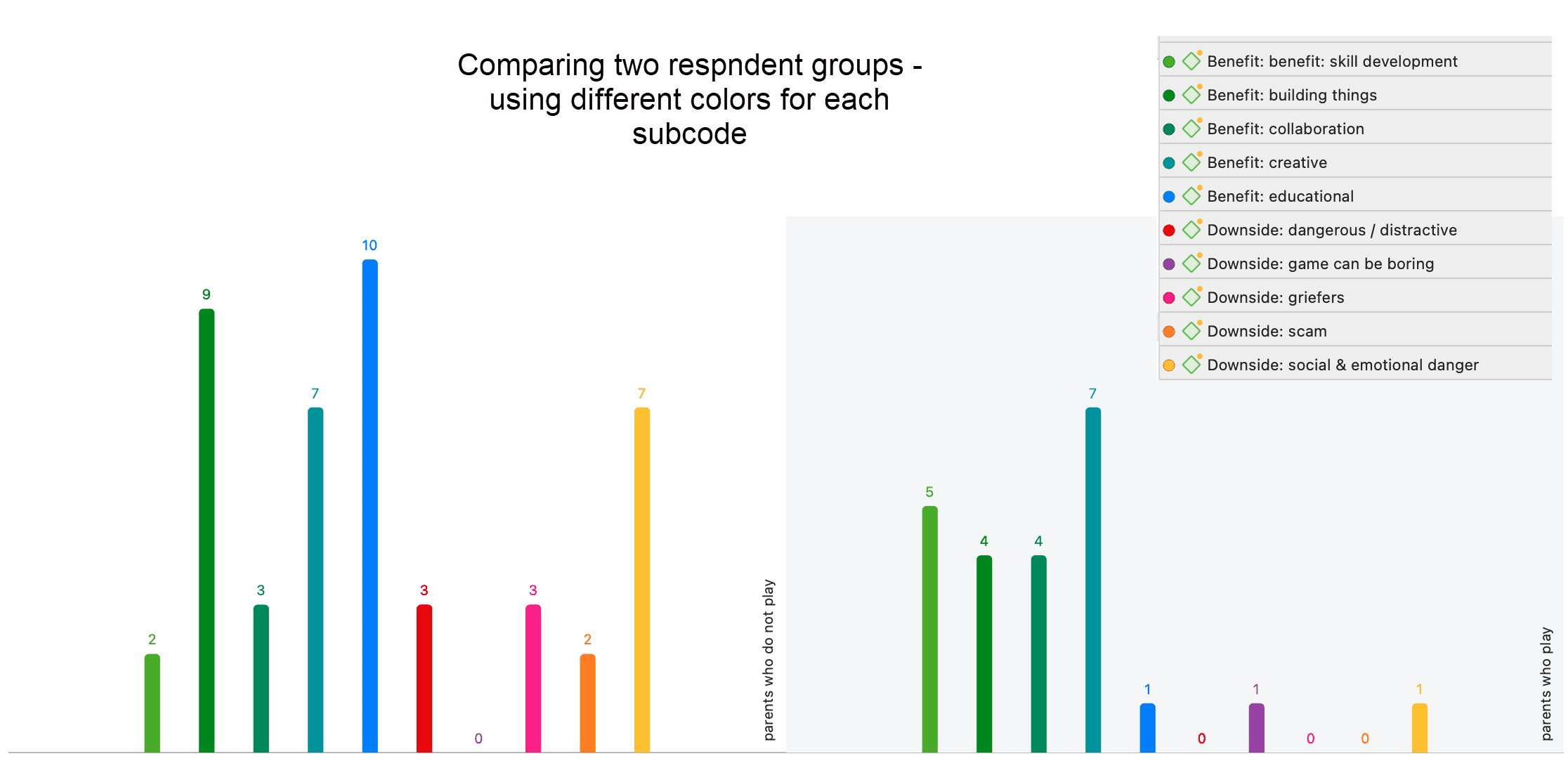
Actualmente no hay leyenda. La que aparece en las imágenes son capturas de pantalla pegadas. Además, los colores de los códigos deben cambiarse manualmente. Para trabajar con los gráficos de manera más conveniente, se añadirán más opciones en futuras actualizaciones.
Exportar como imagen
Para guardar el diagrama de Sankey como imagen, haga clic en el icono Exportar en la esquina superior derecha y seleccione la opción Exportar imagen. El diagrama de Sankey se guardará en formato PNG.
Herramientas de co-ocurrencias de códigos
Las herramientas de co-ocurrencia buscan códigos que se hayan aplicado a la misma cita o a citas superpuestas. Mediante estas herramientas se puede averiguar qué temas se mencionan juntos o están próximos entre sí.
El operador co-ocurrencia es una combinación de los operadores WITHIN (dentro de), ENCLOSES (engloba), OVERLAPS (se superpone a), OVERLAPPED BY (superpuesto por) y AND (y).
De forma predeterminada, la tabla busca todas las co-ocurrencias, pero también es posible solicitar de manera más específica solo las ocurrencias AND. Una ocurrencia «AND» significa que dos códigos codifican exactamente la misma cita.
Consulte los operadores disponibles para más información.
Los resultados dependen de cómo se hayan codificado los datos. Si se desea examinar la proximidad de ciertos temas, es necesario codificar segmentos superpuestos o crear una cita y aplicarle múltiples códigos.
Si los temas que se desean codificar aparecen muy próximos entre sí en los datos, se recomienda crear una cita y aplicarle dos o más códigos. Si estos temas están distribuidos a lo largo de un párrafo o sección extensa, se recomienda crear múltiples citas superpuestas para que la precisión de la codificación sea mayor.
La Tabla de Co-Ocurrencias de Códigos
La herramienta de análisis de co-ocurrencias muestra las frecuencias de co-ocurrencia de múltiples maneras: por ejemplo, una matriz similar a una matriz de correlación que puede conocerse de los programas de estadística, un diagrama de Sankey o un grafo dirigido por fuerzas.
El objetivo es relacionar entre sí los códigos que se han aplicado a las mismas citas o a citas superpuestas. Se puede averiguar qué temas se mencionan juntos o están próximos entre sí. Por tanto, los resultados dependen de cómo se hayan codificado los datos.
Para abrir la herramienta, seleccione Análisis > Tabla de co-ocurrencias de códigos.
Seleccione uno o varios códigos de la primera lista para las columnas de la tabla, y de la segunda lista para las filas de la tabla. Es posible intercambiar las filas y los códigos una vez creada la tabla (véanse las Opciones).
Para seleccionar un elemento, hay que hacer clic en la casilla de verificación que aparece delante de él. También es posible seleccionar varios elementos mediante las técnicas de selección estándar usando las teclas Cmd o Shift. Después de resaltar varios elementos, pulse la barra espaciadora para activar las casillas de verificación de todos los elementos seleccionados.
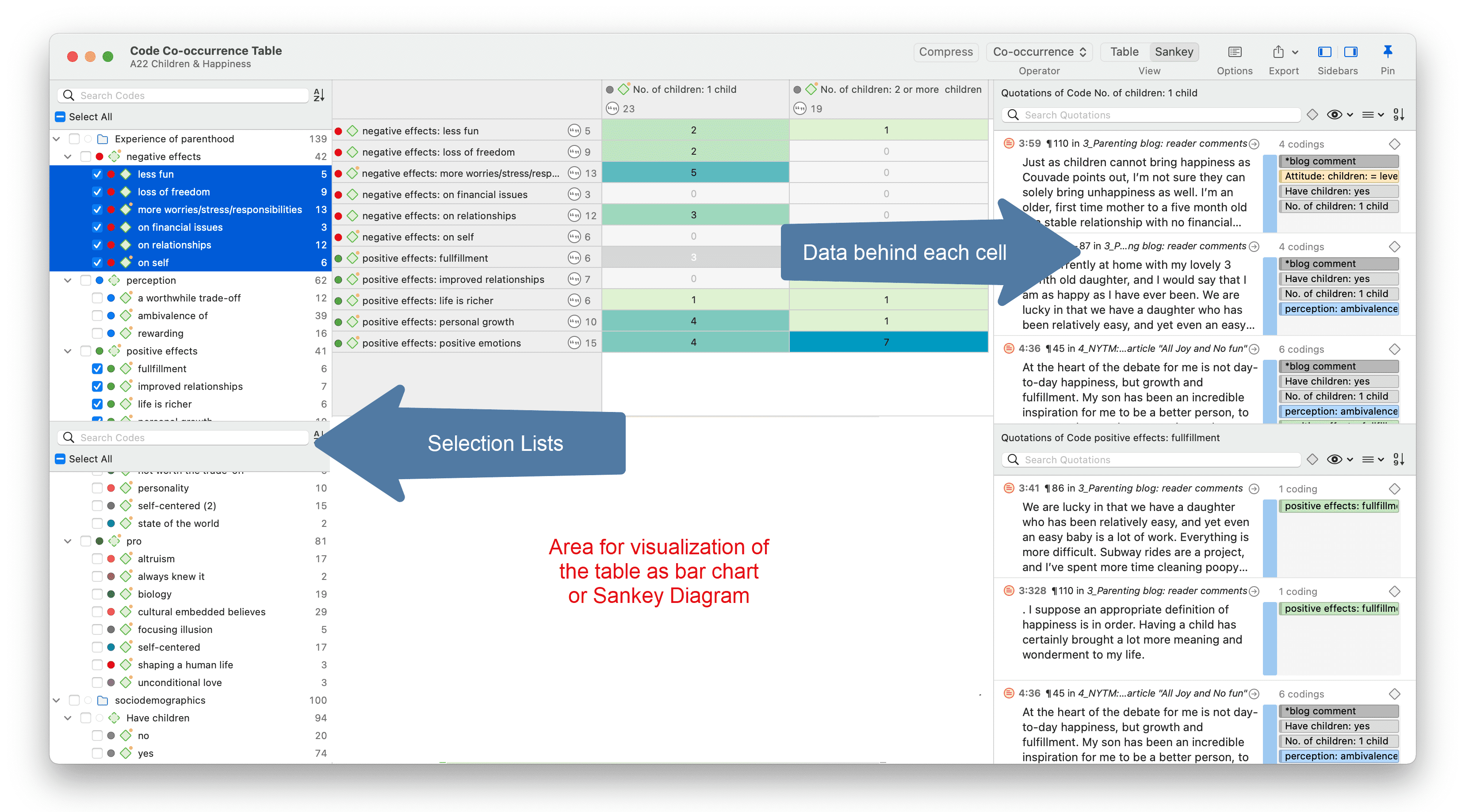
También es posible inspeccionar las co-ocurrencias desde cualquier lugar de la aplicación haciendo clic derecho sobre los códigos y seleccionando una de las opciones de co-ocurrencia en el submenú Análisis. Esto abrirá la misma herramienta descrita aquí y realizará las selecciones correspondientes.
Es posible cambiar los modos de vista en la barra de herramientas de la parte superior. Diferentes visualizaciones son más adecuadas para distintas tareas de análisis, así que pruébelas.
El enfoque de tabla reduce el análisis a una comparación por pares. Si se necesita una co-ocurrencia de orden superior, se pueden usar los códigos de categoría en lugar de los subcódigos.
Si desea comparar las co-ocurrencias de códigos dentro de subconjuntos de sus datos, puede establecer un grupo de documentos como filtro global
Cómo leer la tabla
-
Primera columna / primera fila: El número que aparece debajo y detrás de cada código indica cuántas veces se ha aplicado ese código en todo el proyecto. Esto ayuda a evaluar mejor el número de co-ocurrencias en las celdas de la tabla.
-
El número en la celda indica el número de coincidencias, es decir, cuántas veces co-ocurren los dos códigos. Esto significa que se cuentan los «eventos» de co-ocurrencia y no el número de citas. Si una sola cita está codificada con dos códigos, o si dos citas superpuestas están codificadas con dos códigos, en ambos casos se cuenta como una sola co-ocurrencia.
-
Si se hace clic en una celda, las citas de los códigos de fila y columna correspondientes se muestran junto a la tabla en el Lector de citas. El lector de citas muestra siempre dos listas de citas: las citas del código de columna y las citas del código de fila.
Barra de herramientas de la tabla de co-ocurrencias de códigos

Comprimir: Esta es una forma rápida de eliminar todas las filas o columnas que solo muestran celdas vacías. Es equivalente a desactivar manualmente los códigos que no arrojan resultados. Por tanto, no es posible descomprimir una tabla.
Operador: Es posible cambiar entre el operador de co-ocurrencia y el operador AND. Si las celdas de la tabla solo deben mostrar un resultado cuando las citas se superponen al 100%, es decir, cuando los dos códigos codifican exactamente el mismo segmento de datos, seleccione AND.
Modo de vista:
Tabla: Cambia la vista para mostrar una tabla o matriz de co-ocurrencias.
Sankey: Cambia la vista a un diagrama de Sankey. Consulte más información en el capítulo sobre visualización de co-ocurrencias.
Gráfico de barras: Visualiza las co-ocurrencias como un gráfico de barras. Consulte más información en el capítulo sobre visualización de co-ocurrencias.
Grafo dirigido por fuerzas: Visualiza las co-ocurrencias como un grafo interactivo dirigido por fuerzas. Consulte más información en el capítulo sobre visualización de co-ocurrencias.
Opciones: Véase más adelante.
Exportar: Puede exportar la tabla como hoja de cálculo de Excel, o una imagen de la visualización actualmente activa (incluida la tabla).
Exportación de tabla:
-
Si se selecciona Mostrar recuento, solo se exporta el número de co-ocurrencias.
-
Si se selecciona Mostrar coeficiente, solo se exporta el coeficiente c y no el número absoluto de coincidencias.
-
Si se han seleccionado ambas opciones, se exportan las dos.
Opciones de diseño de la tabla de co-ocurrencias de códigos
Si necesita más espacio en su pantalla, puede ocultar las dos listas de la derecha y la izquierda (ámbito y citas).
Si desea más espacio para las visualizaciones, puede ocultar la tabla.
La visualización de tabla está disponible como diagrama de Sankey o gráfico de barras.
Opciones de la tabla de co-ocurrencias de códigos
Para acceder a las opciones, haga clic en el botón opciones.
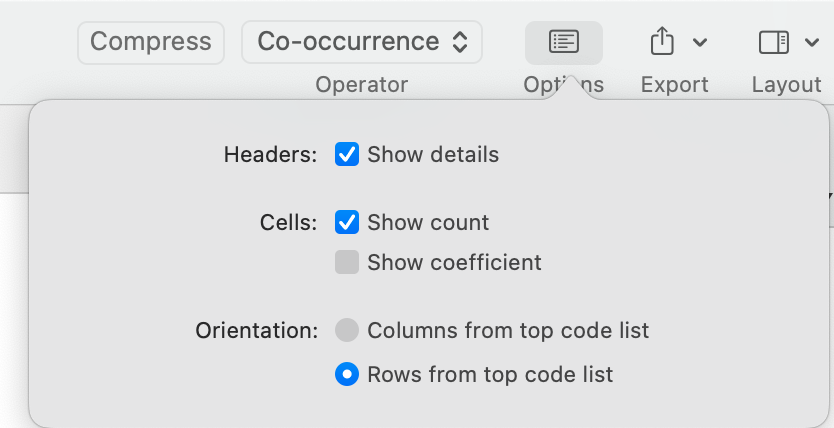
Mostrar detalles: Si está activado, se ve el número total de veces que el código se ha aplicado a una cita. Esto ayuda a evaluar mejor los números de cada celda. La interpretación probablemente sea diferente si el número de coincidencias es 10 y si cada uno de los códigos se ha aplicado 50 o solo 15 veces.
Mostrar recuento: El recuento muestra el número de veces que dos códigos co-ocurren.
Mostrar coeficiente: El coeficiente c ofrece una indicación de la intensidad de la relación entre un par de códigos. Consulte Coeficiente c para más información.
Orientación: Es posible cambiar qué códigos se muestran como filas y cuáles como columnas: columnas de la lista de códigos superior, o filas de la lista de códigos superior.
Coeficiente c de co-ocurrencias de códigos
El coeficiente c indica la intensidad de la relación entre dos códigos.
Para activar el coeficiente c, haga clic en opciones.
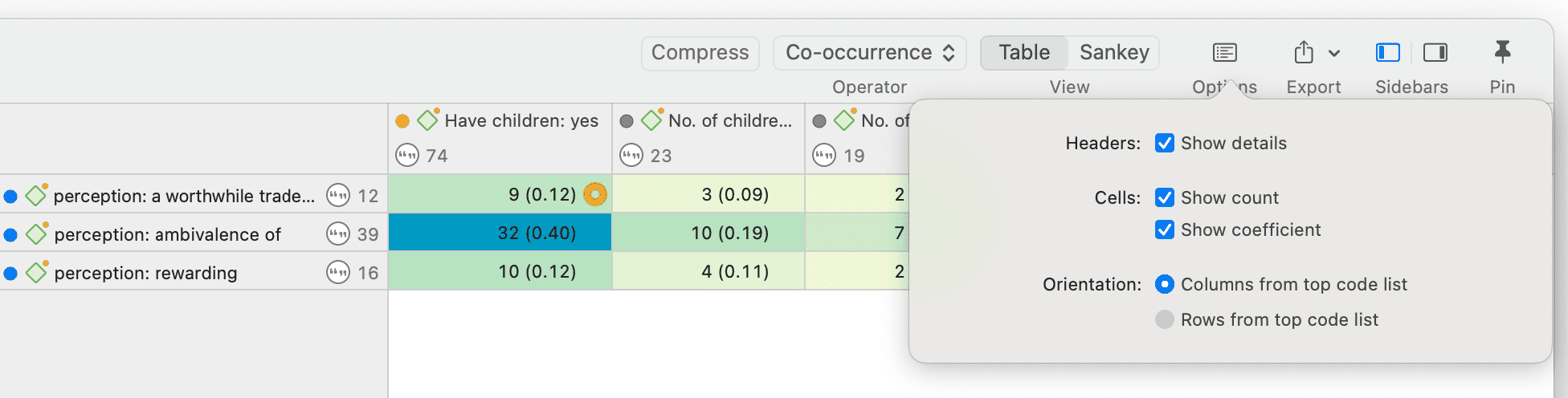
El rango del coeficiente c está entre 0 y 1:
- 0 significa que los códigos no co-ocurren
- 1 significa que estos dos códigos co-ocurren dondequiera que se usen
El cálculo del coeficiente c se basa en enfoques tomados del análisis de contenido cuantitativo. Se calcula de la siguiente manera:
c = n12 / (n1 + n2 - n12)
n12 = número de co-ocurrencias para los códigos n1 y n2
El coeficiente c es útil cuando se trabaja con grandes cantidades de casos y datos estructurados, como preguntas abiertas de encuestas. Si utiliza el índice c, preste atención a las indicaciones de color adicionales. Como su base de datos es cualitativa, el coeficiente c no es equivalente, por ejemplo, al coeficiente de correlación de Pearson y, por tanto, tampoco se proporcionan valores p.
Distorsión debida a frecuencias desiguales
Un problema inherente al índice c y a medidas similares es que se distorsiona cuando las frecuencias de los códigos difieren demasiado. En tales casos, el coeficiente tiende a ser mucho menor que la posible significación de la co-ocurrencia. Por ejemplo, si se han codificado 100 citas con el código «A» y 10 con el código «B», y se tienen 5 co-ocurrencias, entonces el coeficiente c es:
c = 5/(100 + 10 - 5) = 5/105 = 0,048
Un coeficiente de solo 0,048 puede pasarse por alto fácilmente, aunque el código B aparece en el 50% de todas sus aplicaciones junto con el código A.
Si uno de los códigos de un par se ha aplicado más de 5 veces más que el otro código, aparece un punto amarillo en la parte superior derecha de la celda de la tabla. Por tanto, cuando una celda muestra el marcador amarillo, es una invitación a examinar las co-ocurrencias de esa celda a pesar de que el coeficiente sea bajo.
Fuera de rango
El índice c asume entidades de texto separadas y no superpuestas. Solo entonces se puede esperar un rango correcto de valores.
El coeficiente puede superar el rango de 0 a 1 en el que se supone que debe mantenerse si existe codificación redundante. Veamos el siguiente ejemplo:
- La cita 1 está codificada con los códigos A y B
- Una cita 2 superpuesta está codificada con el código B.
Entonces la cita 1 cuenta como 1 evento de co-ocurrencia y la cita 2 superpuesta como otro. Esto da como resultado un valor del doble del máximo permitido:
c = 2/(1 + 2 - 2) = 2
Todas las celdas que muestran un número fuera de rango (> 1) tienen un punto rojo en la esquina superior derecha.
En caso de que el coeficiente c supere 1, es necesario realizar una limpieza y eliminar los códigos redundantes. Consulte Búsqueda de codificaciones redundantes.
Resumen de indicadores de color
Punto amarillo: Frecuencias de citas desiguales: la proporción entre las frecuencias del código de columna y del código de fila supera el umbral de 5.
Punto rojo: El índice c supera el rango de 0 a 1.
Punto naranja: El punto naranja es simplemente una combinación de las condiciones rojo y amarillo.
Visualización de la tabla de co-ocurrencias de códigos
ATLAS.ti puede presentar sus co-ocurrencias de múltiples maneras, desde una vista de tabla hasta el dinámico grafo dirigido por fuerzas. Aunque todas estas opciones de visualización presentan los mismos datos, son más adecuadas para diferentes tareas de análisis y exploración, y por supuesto también pueden utilizarse para ilustrar los hallazgos. Además, no son simples imágenes decorativas, sino que son completamente interactivas.
Le invitamos a explorar los diferentes modos de vista y a cambiar entre ellos con frecuencia. Distintos aspectos de sus datos pueden destacarse según la visualización elegida.
Es posible cambiar los modos de vista en la barra de herramientas de la parte superior. Diferentes visualizaciones son más adecuadas para distintas tareas de análisis, así que pruébelas.
Tabla
La tabla con filas y columnas nos resulta tan familiar que casi no la consideramos una visualización. Es una forma muy fácil de comprender y clara para presentar los datos, aunque quizás un poco austera. La vista de tabla es la única que puede mostrar el coeficiente y sumar todas las co-ocurrencias para cada código. Puede exportar la tabla como hoja de cálculo de Excel.
Diagrama de Sankey
Los diagramas de Sankey reciben su nombre del capitán irlandés Matthew Henry Phineas Riall Sankey, quien utilizó este tipo de diagrama en 1898 en una figura clásica que mostraba la eficiencia energética de una máquina de vapor. Hoy en día, los diagramas de Sankey se usan para presentar flujos de datos y conexiones entre datos en diversas disciplinas. El diagrama de Sankey puede exportarse como imagen.
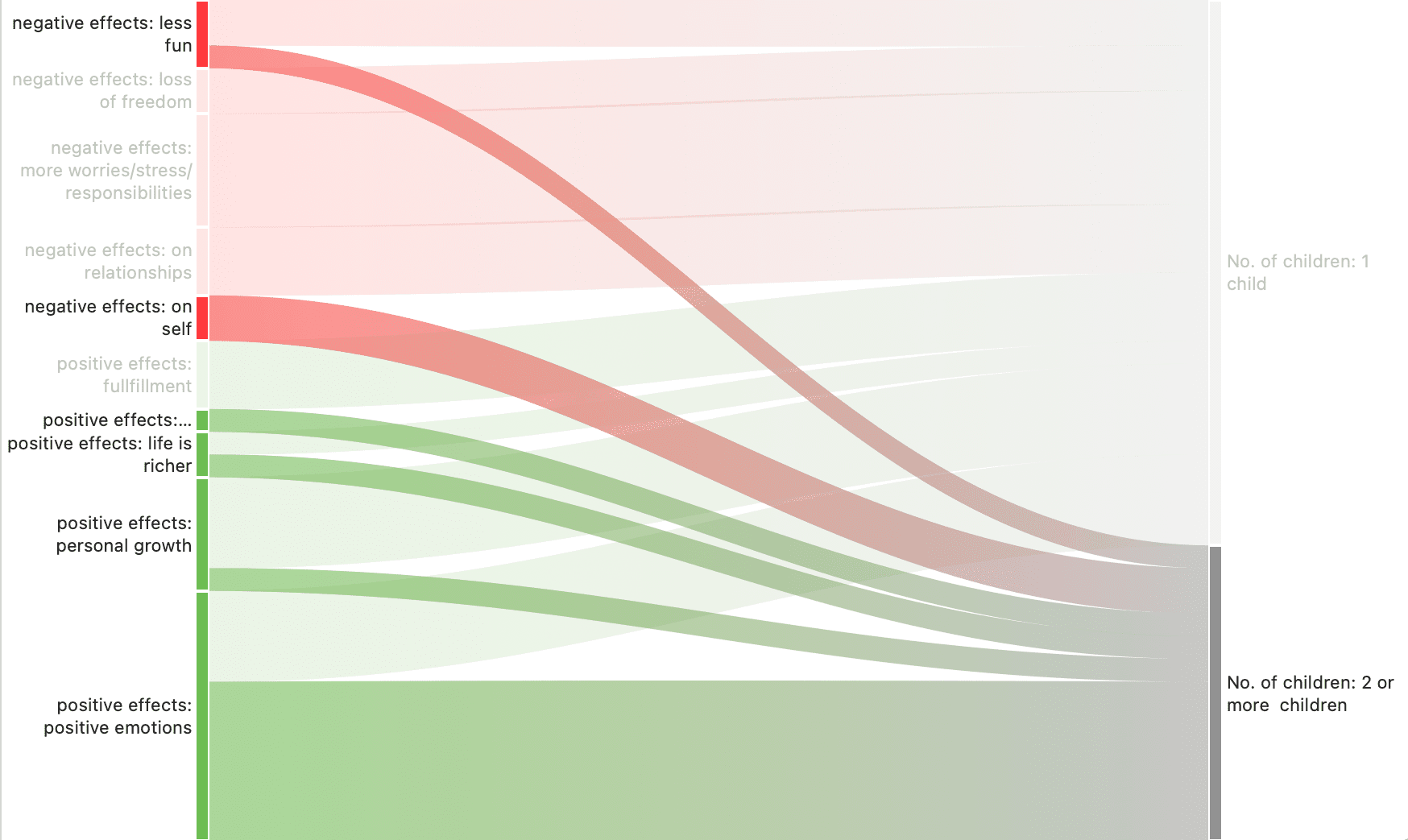
Las entidades de filas y columnas de la tabla se representan en el modelo de Sankey como nodos y aristas, mostrando la intensidad de la co-ocurrencia entre los pares de nodos. En la tabla de co-ocurrencias de códigos, los pares conectados son códigos tanto para las filas como para las columnas.
Arista: Para cada celda de la tabla que contiene un valor, se muestra una arista entre los nodos del diagrama. El grosor de las aristas refleja los valores de las celdas de la tabla. Las celdas con valor 0 no se muestran en la vista de Sankey.
La clave para leer e interpretar los diagramas de Sankey es recordar que el ancho es proporcional a la cantidad representada.
Diseño
El diagrama de Sankey, de manera similar al editor de redes, aplica un diseño para sus nodos y, en consecuencia, para las aristas que conectan los nodos, con el fin de crear una visualización fácil de comprender. Este diseño básico coloca las entidades seleccionadas (nodos en terminología Sankey) en «capas» verticales, con las entidades de filas a la izquierda y las entidades de columnas a la derecha. Si los nodos tienen vínculos tanto entrantes como salientes en el conjunto de nodos visible actualmente, se colocarán en carriles o capas intermedias.
Interactividad
-
Para mostrar las citas responsables de la co-ocurrencia de dos entidades, haga clic en la arista de conexión. Esto tiene el mismo efecto que hacer clic en una celda de la tabla. Las citas se muestran en el Lector de citas a la derecha.
-
Si pasa el cursor sobre una arista, verá el número que también se muestra en la celda de la tabla, es decir, el número de veces que el par de códigos co-ocurre.
-
Para facilitar la identificación del vínculo correcto, al mover el ratón se resaltan las aristas sobre las que se pasa el cursor. Tras seleccionar una arista, las aristas no seleccionadas se atenúan para aumentar aún más la visibilidad de la arista considerada.
-
Al seleccionar un nodo, se resalta dicho nodo junto con todas sus aristas entrantes y salientes. Esto facilita identificar las áreas de conectividad.
Eliminación de aristas
Para eliminar un nodo del diagrama, haga clic derecho y seleccione Quitar de la vista.
Además de las opciones de Quitar de la vista, el menú contextual ofrece otras opciones, como por ejemplo cambiar el color del código.
Lo mismo puede conseguirse modificando las listas de selección, pero esto es un poco más «pesado» y puede no resultar claro qué entidades hay que deseleccionar.
Gráfico de barras
Tan pronto como crea una tabla de co-ocurrencias, aparece un gráfico de barras en el área debajo de la tabla.
Para la visualización como gráfico de barras, a menudo es preferible cambiar los colores de los códigos. También puede querer intercambiar las filas y las columnas. Esta opción se encuentra en la cinta de la tabla de co-ocurrencias de códigos.
Para crear la tabla a continuación, se cambiaron los colores de los dos subcódigos «1 hijo» y «2 o más» a naranja y azul. El resultado es, por supuesto, el mismo: para las personas con dos o más hijos, la tabla se desplaza significativamente hacia la derecha, hacia los códigos que registran las experiencias positivas. O dicho de otra manera, para las personas con un hijo, se reportan tanto experiencias positivas como negativas, con un énfasis algo mayor en las negativas.
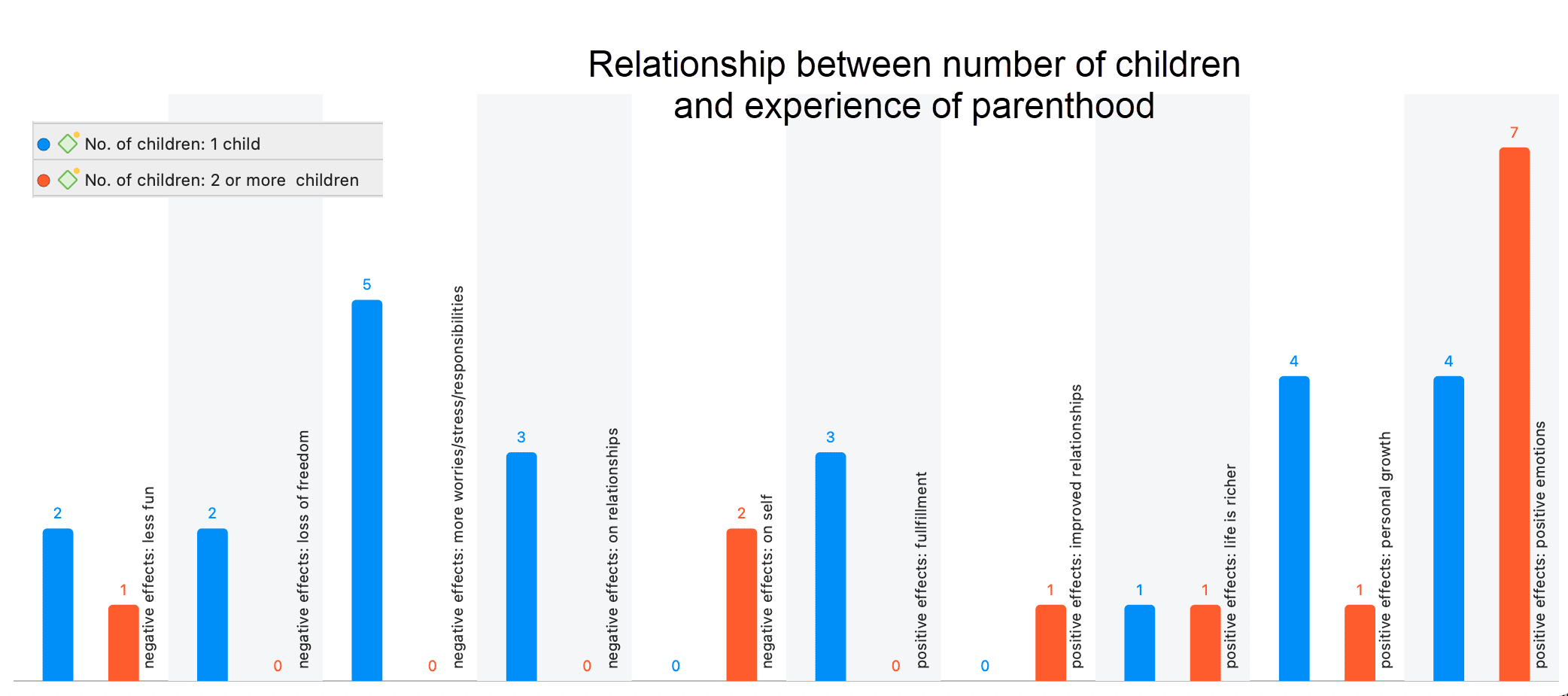
Si intercambiamos las filas y las columnas, de modo que el número de hijos quede en el eje x, obtenemos un gráfico más significativo si cambiamos los colores de los códigos para los subcódigos de efectos positivos y negativos. Los efectos negativos tienen colores que van del amarillo al rosa, y los colores para los efectos positivos van del verde al azul.
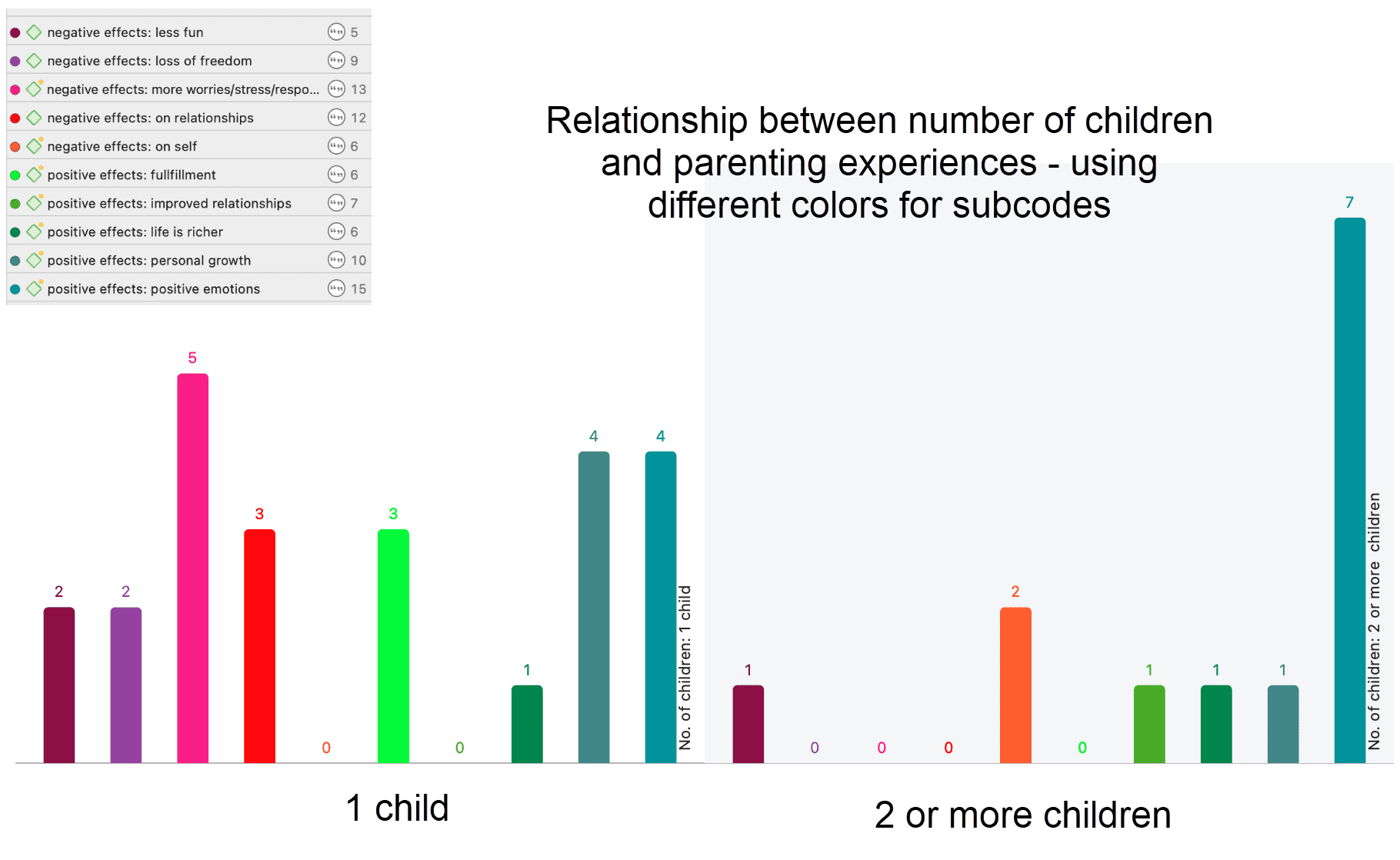
Actualmente no hay leyenda. La que aparece en las imágenes son capturas de pantalla pegadas. Además, los colores de los códigos deben cambiarse manualmente. Para trabajar con los gráficos de manera más conveniente, se añadirán más opciones en futuras actualizaciones.
Entidades inteligentes e instantáneas
Una entidad inteligente en ATLAS.ti es siempre una consulta. Se pueden crear entidades inteligentes para códigos y grupos.
En el Administrador de códigos se pueden crear códigos inteligentes utilizando el operador OR. Esto resulta útil cuando se necesita una combinación de dos o más códigos para el análisis de datos. En la Herramienta de consulta, un código inteligente se puede usar para almacenar los resultados de una consulta.
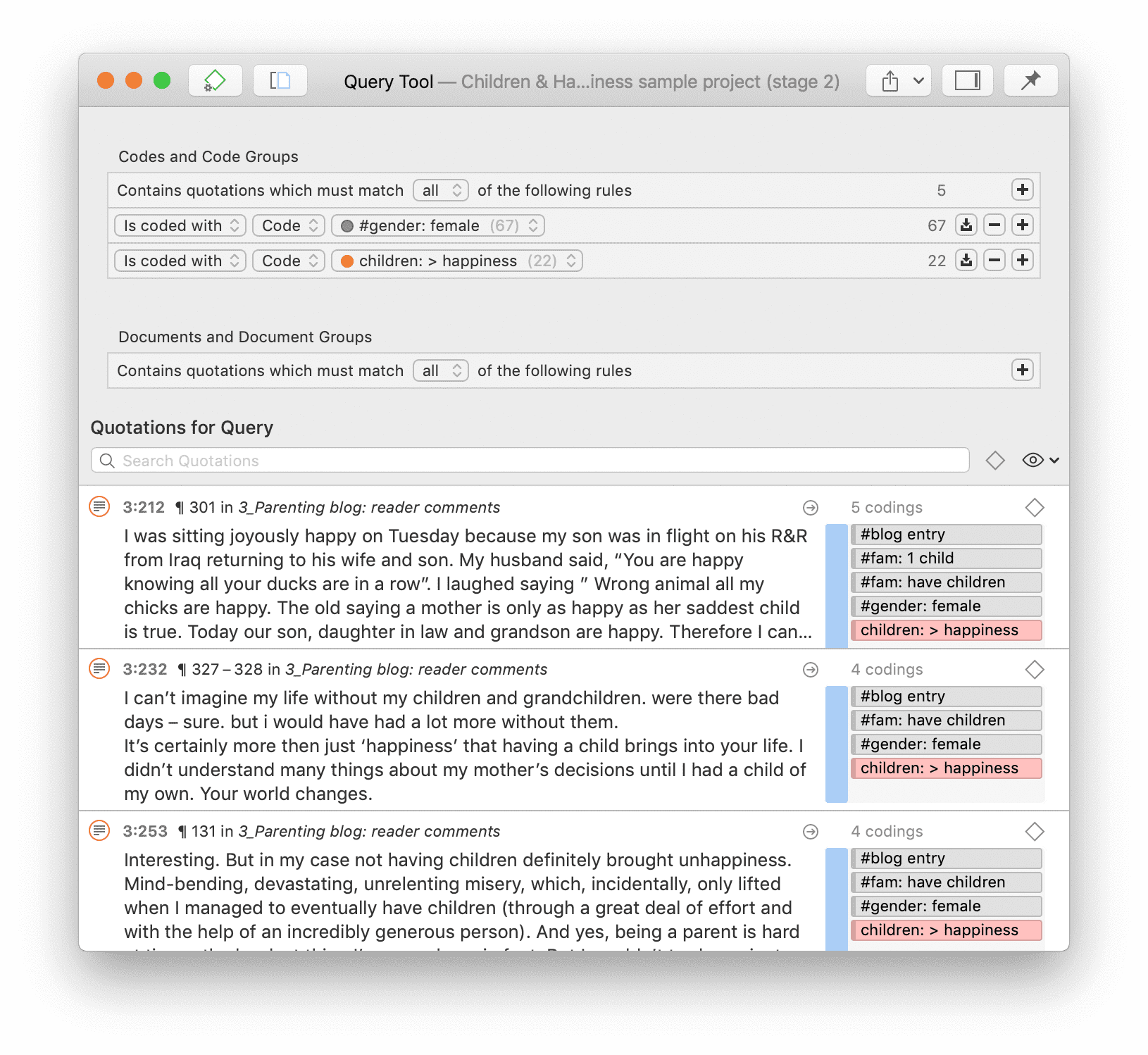
Los grupos inteligentes se pueden crear en los Administradores de grupos. Son especialmente útiles para los grupos de documentos cuando se utilizan como variables, ya que permiten crear combinaciones de variables.
La razón por la que estos códigos y grupos se denominan inteligentes es porque cambian junto con el proyecto. Si se modifica alguna de las codificaciones de un código que forma parte de un código inteligente, este cambio se reflejará en el código inteligente al recuperar sus citas. Si se agregan o eliminan documentos que son miembros de los grupos que componen un grupo inteligente, el grupo inteligente recuperará los documentos que reflejen el estado actual del proyecto.
Cada vez que se hace clic en un código inteligente o en un grupo inteligente, se ejecuta la consulta subyacente y se ven los resultados actualizados.
Una entidad instantánea transforma una entidad inteligente en un código o grupo de códigos regular. Se puede pensar en ella como una fotografía tomada con una cámara: preserva el momento actual. Por tanto, las entidades instantáneas ya no cambian automáticamente.
¿Qué son los códigos inteligentes?
Los códigos inteligentes son una manera conveniente de almacenar consultas. Son muy similares en apariencia y comportamiento a los códigos normales, con una diferencia importante: en lugar de conexiones fijas con citas, los códigos inteligentes almacenan una consulta para calcular sus referencias virtuales cuando sea necesario.
-
Los códigos inteligentes cambian automáticamente su comportamiento durante el análisis. Si se tiene un código inteligente basado en una consulta como: (Código A | Código B) COOCCUR Código C), y se agregan o eliminan citas vinculadas al Código A, B o C, el código inteligente se ajustará automáticamente.
-
Como un código inteligente es una consulta, no puede utilizarse para codificar. Por la misma razón, los códigos inteligentes no se muestran en el área de margen.
-
Los códigos inteligentes se muestran en el Administrador de códigos. Se reconocen por un punto gris en la esquina inferior izquierda del icono del código.
-
Si se hace doble clic en un código inteligente, se pueden recuperar todas las citas que son resultado de la consulta subyacente.
-
Se puede cambiar la consulta subyacente de un código inteligente editando la consulta.
-
Los códigos inteligentes se pueden usar en grupos de códigos, redes y, por último, como poderosos operandos en consultas, lo que permite construir consultas complejas de forma incremental.
-
Los códigos inteligentes se pueden convertir en un código regular creando un código instantáneo.
Lo que no se puede hacer con los códigos inteligentes
Como los códigos inteligentes no están directamente asociados con citas, se aplican ciertas restricciones.
-
Codificación: No es posible vincular un código inteligente directamente a una cita. Por lo tanto, los códigos inteligentes no se muestran en la lista de códigos al codificar los datos. Las operaciones de arrastrar y soltar desde listas de códigos a otras listas no son posibles.
-
Fusión: No es posible fusionar un código inteligente con otros códigos.
-
No es posible incluir un grupo de códigos en la consulta del código inteligente y asignar el código inteligente a ese grupo de códigos posteriormente. Esto crearía una estructura cíclica y, por tanto, no está permitido.
Trabajar con códigos inteligentes
Crear un código inteligente con OR en el Administrador de códigos
Si solo se necesita una combinación OR simple de dos o más códigos como código inteligente, la manera más sencilla es usar el Administrador de códigos.
Abra el Administrador de códigos, seleccione dos o más códigos, haga clic derecho y seleccione la opción Crear código inteligente en el menú contextual.
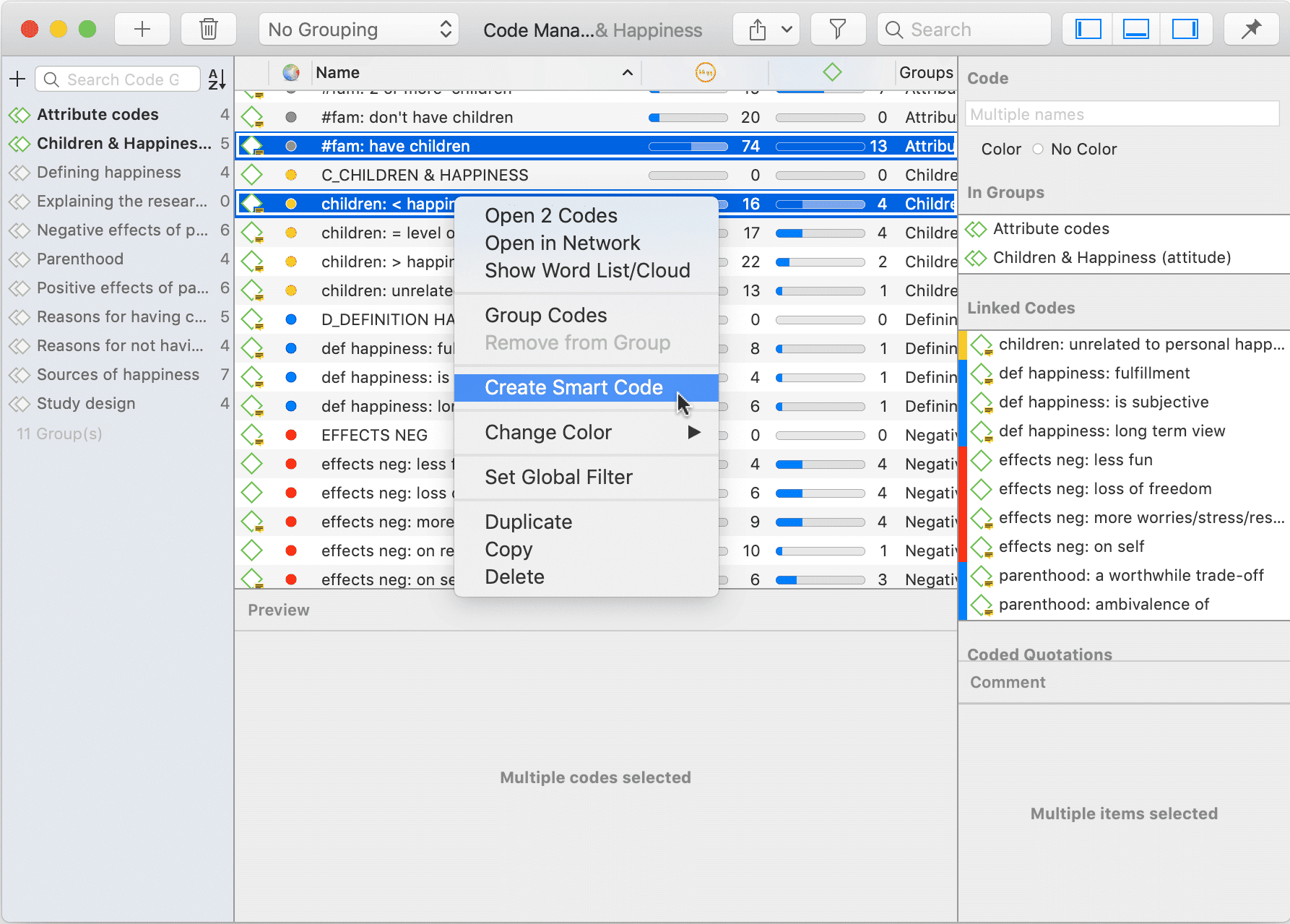
Si se pregunta por qué una combinación OR es útil en lugar de simplemente fusionar los códigos, en ocasiones se desea mantener los códigos como códigos regulares en la lista de códigos. Si se fusionan códigos, solo queda el código fusionado. Por ejemplo, si se codifican los participantes en la transcripción de un grupo focal, se pueden crear códigos inteligentes para todos los participantes masculinos y femeninos sin perder el código de cada participante individual. Si se añaden estos atributos a cada unidad de participante, el margen se vuelve muy desordenado. Los códigos inteligentes no se muestran en el margen.
Crear un código inteligente en el Administrador de citas
También se pueden crear códigos inteligentes en el Administrador de citas, donde es posible combinar códigos usando los operadores booleanos AND y OR. Consulte Operadores disponibles para consultar datos > Operadores booleanos.
Use AND para:
- limitar los resultados
- indicar a la base de datos que TODOS los términos de búsqueda deben aplicarse. Esto significa que el código inteligente solo recupera citas vinculadas a todos los códigos de la consulta. En otras palabras, la cita está codificada con múltiples códigos.
Use OR para:
- conectar dos o más conceptos similares
- ampliar los resultados, indicando a la base de datos que CUALQUIERA de los términos de búsqueda se aplica. Esto significa que el código inteligente recupera todas las citas de todos los códigos de la consulta. Es aditivo.
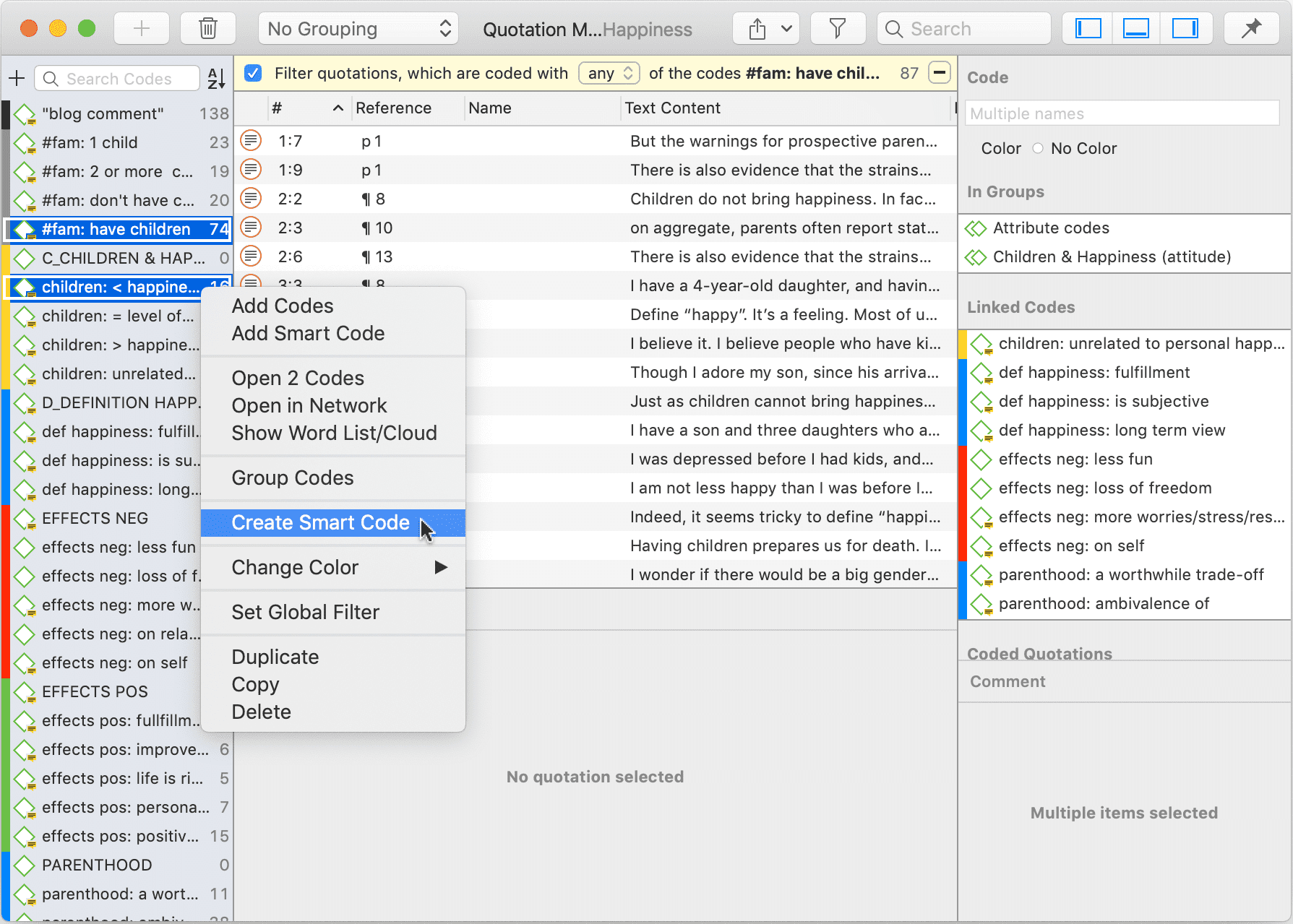
Abra el Administrador de citas y seleccione dos o más códigos en el área de filtros de la izquierda.
El operador predeterminado en la barra de filtros amarilla encima de la lista de citas es 'ANY'. Si desea cambiarlo, haga clic sobre él y seleccione el operador 'ALL'.
Para guardar los resultados como código inteligente, haga clic derecho sobre cualquiera de los códigos seleccionados y seleccione Crear código inteligente en el menú contextual.
Introduzca un nombre y haga clic en Crear.
Crear un código inteligente en la Herramienta de consulta
Abra la Herramienta de consulta y construya una consulta.
Para guardar la consulta, haga clic en el icono Código inteligente en la barra de herramientas.
Editar un código inteligente
Si desea ver la consulta subyacente de un código inteligente, o si desea modificar la consulta, puede editar el código inteligente.
Abra el Administrador de códigos, seleccione el código inteligente, haga clic derecho y seleccione Editar consulta en el menú contextual.
Esto abre la herramienta de consulta donde puede revisar y modificar el código inteligente. Consulte Cómo construir una consulta.
No es posible eliminar un código si forma parte de la consulta de un código inteligente. Si desea eliminar un código que es parte de la consulta de un código inteligente, primero debe eliminar el código inteligente. Si no desea perder los resultados almacenados por el código inteligente, puede convertirlo en un código instantáneo antes de eliminarlo.
¿Qué son los grupos inteligentes?
Los grupos inteligentes son muy similares en apariencia y comportamiento a los grupos normales, con una diferencia importante: en lugar de conexiones fijas con sus miembros, los grupos inteligentes almacenan una consulta para calcular sus referencias virtuales cuando sea necesario.
Aunque también es una opción para grupos de códigos, memos y redes, la aplicación más común de los grupos inteligentes son los grupos inteligentes de documentos. Permiten combinar dos o más variables. Por ejemplo, género y ubicación. Esto requiere que existan grupos de documentos para las variables de base. En este caso, para género: masculino y femenino, y para ubicación: urbano y rural. Si se necesita la combinación de género y ubicación con frecuencia, una buena manera de hacerlo es crear grupos inteligentes:
- encuestados femeninos de zonas urbanas
- encuestados femeninos de zonas rurales
- encuestados masculinos de zonas urbanas
- encuestados masculinos de zonas rurales
Para crear grupos inteligentes se utilizan operadores booleanos. Consulte Operadores disponibles para consultar datos > Operadores booleanos para obtener más información.
Una razón para crear un grupo inteligente es aplicarlo como filtro global. Consulte Aplicar filtros globales para el análisis de datos. Otra aplicación es agregarlo a una red y mostrar las conexiones entre grupos de documentos y códigos.
Trabajar con grupos inteligentes
Una razón para crear un grupo inteligente es aplicarlo como filtro global. Consulte Aplicar filtros globales para el análisis de datos. Otra aplicación es agregarlo a una red y mostrar las conexiones entre grupos de documentos y códigos.
Crear un grupo inteligente
Para crear un nuevo grupo inteligente, abra un Administrador y seleccione dos o más grupos, haga clic derecho y seleccione Crear nuevo grupo inteligente en el menú contextual.
Acepte el nombre predeterminado o modifíquelo y haga clic en Crear.
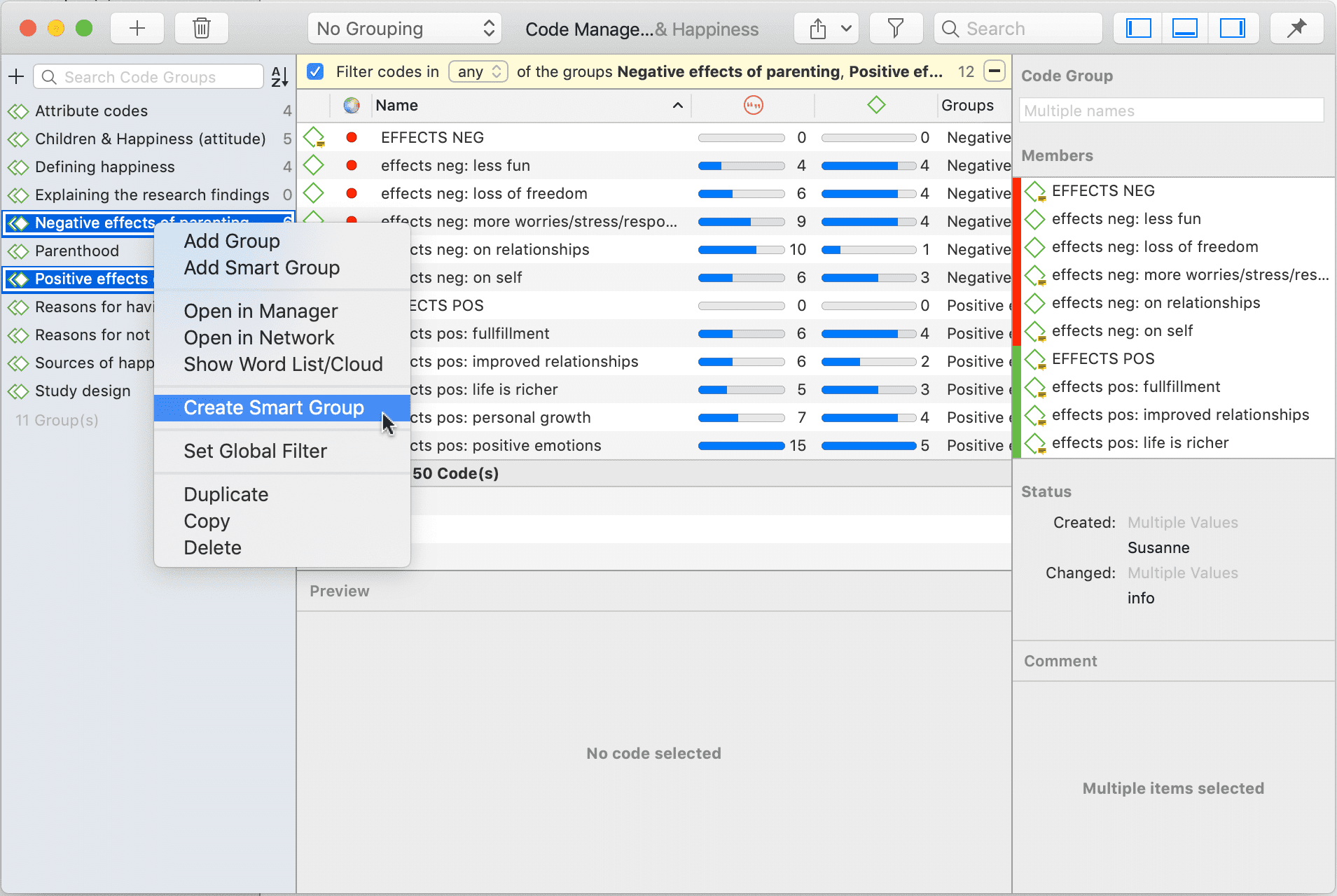
Las entidades inteligentes se reconocen por el pequeño círculo gris en la esquina inferior izquierda del icono.
Editar un grupo inteligente
Abra el Administrador correspondiente. Seleccione el grupo inteligente que desea editar, haga clic derecho y seleccione Editar consulta.
Esto abre el Editor de grupos inteligentes, que es similar a la herramienta de consulta.
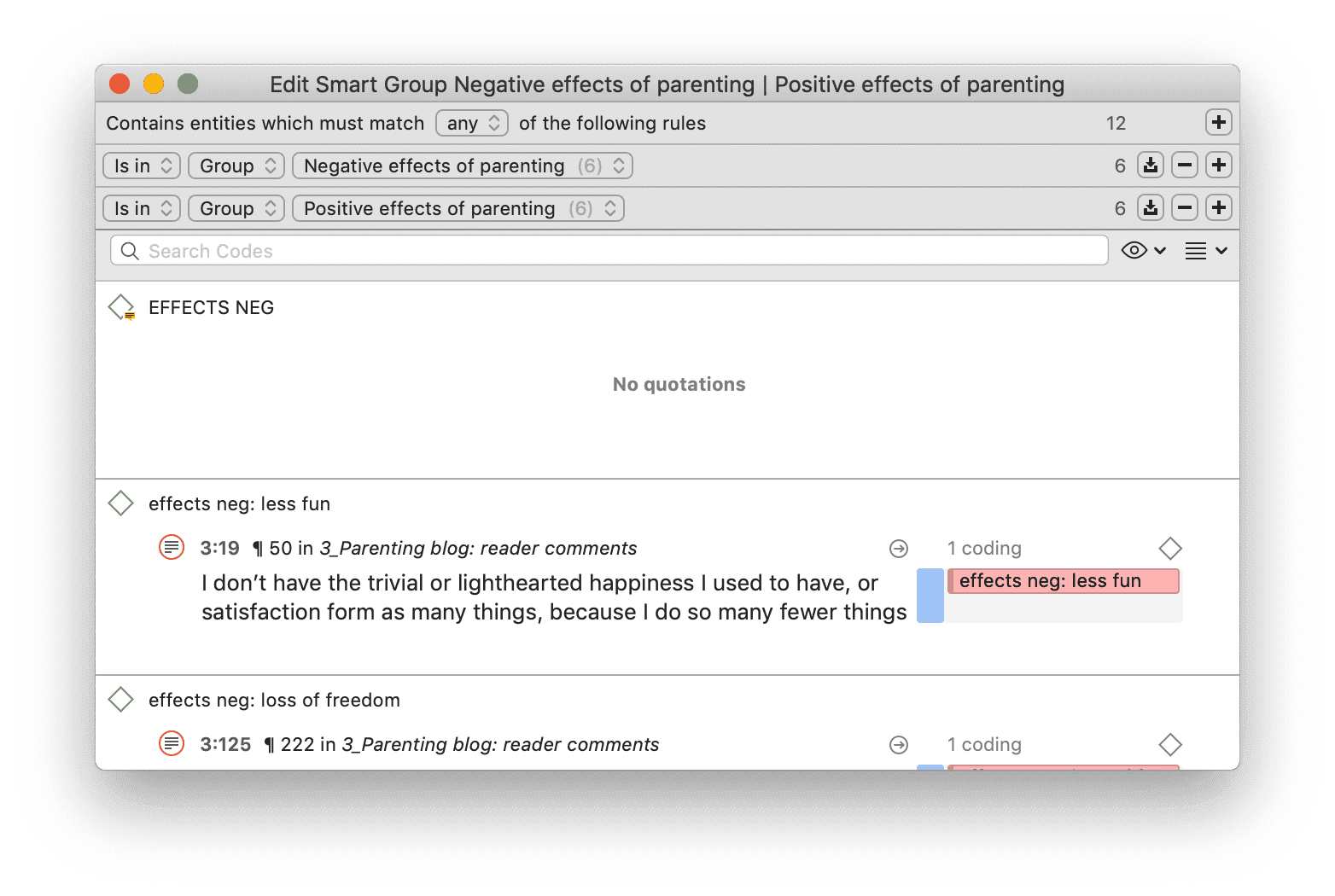
Los siguientes operadores están disponibles:
any: combina todos los grupos seleccionados y forma un grupo más amplio
all: crea un grupo inteligente formado por la intersección de los grupos seleccionados, como "encuestados femeninos de zonas urbanas".
exactly one: crea un grupo inteligente que solo contiene miembros que son únicos en cada grupo y no aparecen en ninguno de los otros grupos seleccionados.
Ejemplo: En el proyecto de muestra Evaluación de un videojuego, los encuestados evalúan el juego de distintas maneras. Si se desea encontrar aquellos encuestados que evalúan el juego como creativo o educativo (pero no ambos), se puede usar el operador one of.
IMAGE
Consulte cómo construir una consulta para obtener más información sobre cómo entender y modificar la consulta de un grupo inteligente.
¿Qué son los códigos y grupos instantáneos?
Códigos instantáneos
Un código instantáneo transforma un código inteligente en un código regular. Este código preserva el estado actual de un código inteligente en el momento de su creación, como si se tomara una fotografía que captura el instante, y crea vínculos directos con todas las citas.
- Un código instantáneo se muestra en el área de margen.
- Un código instantáneo se puede usar para codificar.
Se puede crear un código instantáneo a partir de un código inteligente. Esto puede ser útil para el análisis de datos cuando se construyen consultas.
Otra aplicación consiste en usar esta opción para fijar sistemas de códigos cuando los grupos de códigos se han usado como categorías. Esto a menudo conduce a sistemas de códigos poco desarrollados, largas listas de códigos y un uso limitado de las herramientas de análisis adicionales. Para solucionarlo, primero hay que convertir todos los grupos de códigos en códigos inteligentes usando la herramienta de consulta. Luego se crean códigos instantáneos a partir de estos códigos inteligentes, transformando los grupos de códigos en códigos regulares. En el paso siguiente, los miembros de los grupos de códigos se pueden convertir en subcódigos agregando prefijos y fusionándolos según corresponda. Consulte Construir un sistema de códigos.
Grupos instantáneos
Un grupo instantáneo transforma un grupo inteligente en un grupo regular. Este grupo preserva el estado actual de un grupo inteligente en el momento de su creación, como si se tomara una fotografía que captura el instante, y crea vínculos directos con todos sus miembros.
Aplicación: Puede ser útil, por ejemplo, cuando se desea eliminar documentos de un proyecto que forman parte de un grupo inteligente. Mientras forman parte del grupo inteligente, esto no es posible. Para no perder la combinación de documentos definida por el grupo inteligente, se puede convertir en un grupo instantáneo, eliminar el grupo inteligente y luego eliminar el o los documentos que ya no se desean en el proyecto.
Crear instantáneas
Se pueden crear instantáneas a partir de códigos inteligentes y grupos inteligentes.
Crear un código instantáneo
Abra el Administrador de códigos, seleccione un código inteligente, haga clic derecho y seleccione Crear instantánea en el menú contextual.
El nombre predeterminado para el código instantáneo es el nombre del código inteligente más el sufijo [SN 1]; [SN 2] si se crea un segundo código instantáneo del mismo código inteligente, y así sucesivamente.
Crear un grupo instantáneo
Abra el Administrador o el Administrador de grupos de la entidad correspondiente, haga clic derecho y seleccione Crear instantánea en el menú contextual.
Trabajar con filtros globales
Los filtros globales son una herramienta poderosa para analizar los datos. A diferencia de los filtros locales que se pueden activar en cada administrador, los filtros globales tienen efecto sobre todo el proyecto.
Todos los grupos, documentos y códigos se pueden establecer como filtro global.
Para establecer un filtro global
Haga clic derecho sobre un código, documento o grupo en el Navegador de proyectos o en un Administrador y seleccione la opción Establecer filtro global en el menú contextual.
Después de establecer un filtro global, aparecerán una o varias filas en todas las ventanas afectadas por el filtro global. Las filas tienen el color de la entidad que se filtra.
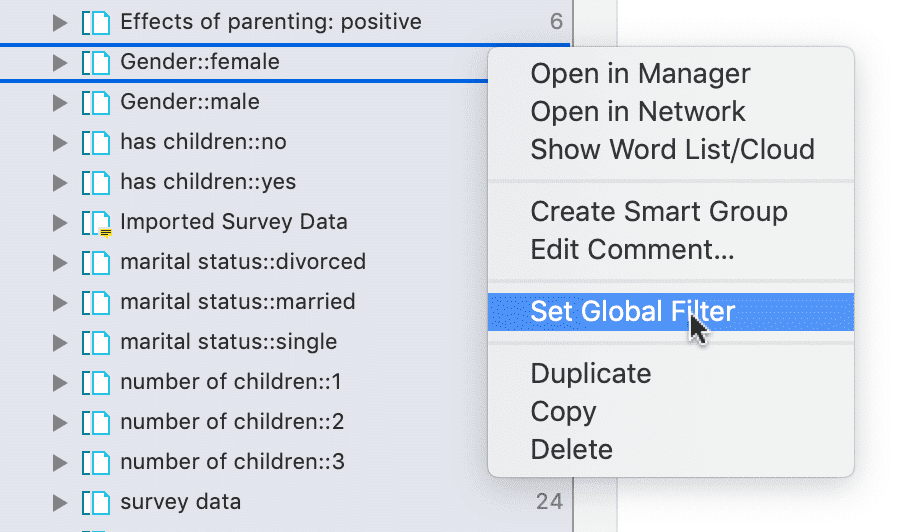
En la captura de pantalla siguiente se puede ver que los códigos (verde), los documentos (azul) y las citas (naranja) están filtrados en el Navegador de proyectos, y que los códigos y las citas están filtrados en el espacio de trabajo principal.
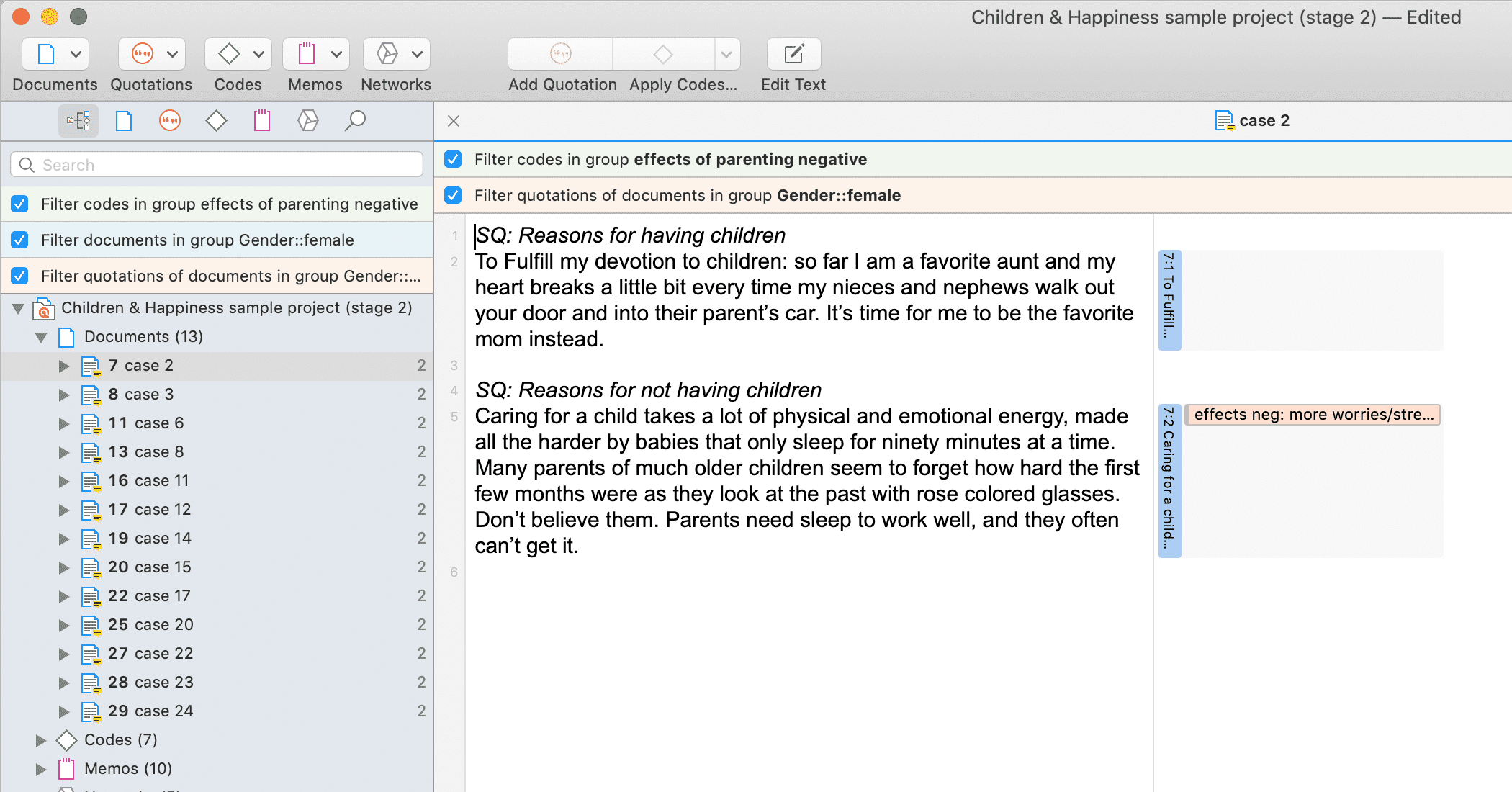
Activar / Desactivar filtros globales
Mientras un filtro global está activo, puede desactivarlo temporalmente haciendo clic en la casilla de verificación de la barra del filtro global que aparece encima de cada lista o tabla filtrada.
Cambiar un filtro global
Para cambiar un filtro global, simplemente seleccione otra entidad como filtro global.
Eliminar un filtro global
Para eliminar un filtro global, haga clic en el menos (-) en el lado derecho de la barra del filtro global.
Documentos como filtro global
Los grupos de documentos como filtro global afectan la lista de documentos y citas. Por ello, la lista de citas que se muestra en el administrador de citas o como resultados de consultas se reduce a aquellos documentos que se encuentran en el filtro.
-
Al recuperar citas haciendo doble clic sobre un código en el administrador de códigos, el lector de citas solo mostrará citas de los documentos que están en el filtro.
-
En la tabla código-documento, permite agregar una capa al análisis. Si, por ejemplo, se compara la frecuencia de códigos por encuestados con distintos niveles educativos, se puede establecer un grupo de documentos género::masculino como filtro global para refinar el análisis a solo los encuestados masculinos.

-
Si se ejecuta un análisis de co-ocurrencia de códigos, este se aplicará a todos los datos del proyecto. Si se desea restringir el análisis a un grupo particular de encuestados o tipo de datos, se puede establecer un grupo de documentos como filtro global.
-
En una red, todos los documentos que no estén en el grupo de documentos establecido como filtro global aparecerán atenuados.
Filtrar la distribución de códigos entre documentos en el Administrador de documentos
El diagrama de distribución de códigos entre documentos en el Administrador de documentos muestra la frecuencia de cada código utilizado en un documento. Puede haber muchos códigos; no es fácil comparar documentos sin enfocarse en códigos específicos. Esto se puede hacer estableciendo un grupo de códigos como filtro global.
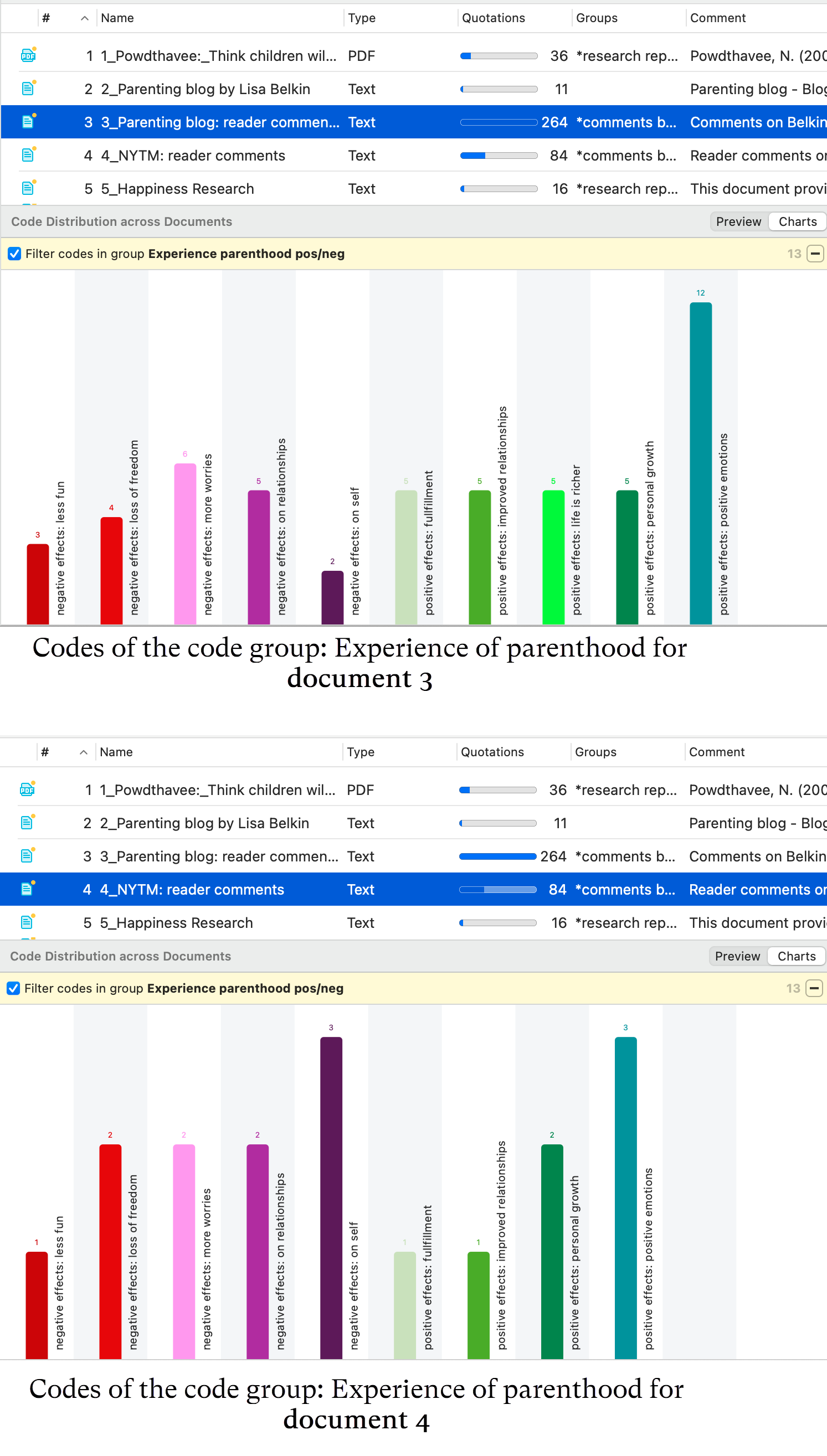
Filtros globales en redes
- Los grupos de códigos como filtros globales son muy útiles en redes cuando se usan las opciones: Agregar vecinos y Agregar códigos co-ocurrentes. En ese caso, solo se agregan los códigos del grupo de códigos establecido como filtro global.
- En una red, todos los códigos que no estén en el grupo de códigos establecido como filtro global aparecerán atenuados.
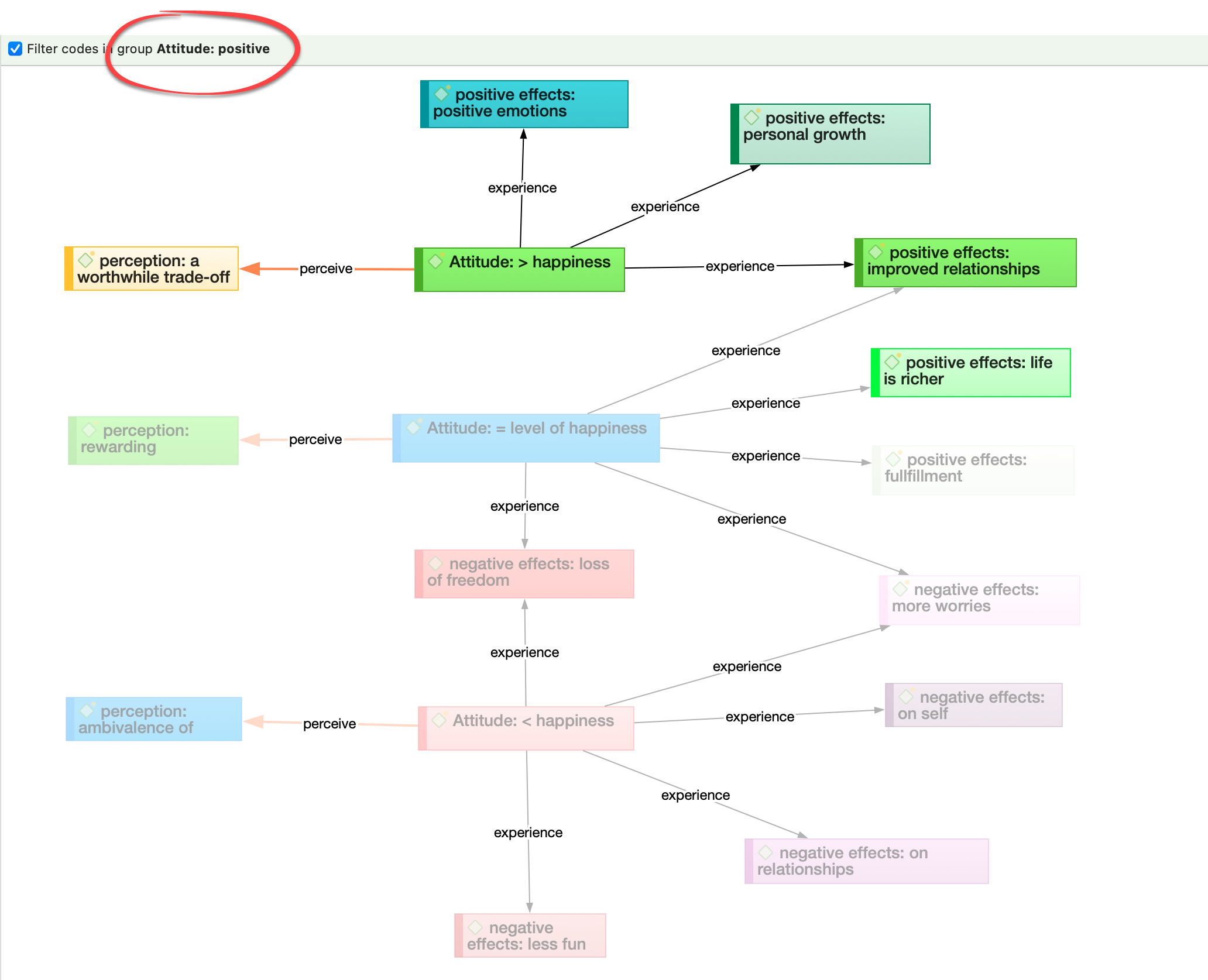
Grupos de memos como filtro global
- Los grupos de memos como filtros afectan la lista de memos que se ve en el administrador de memos y en todas las listas de selección.
- Solo se muestran en el área de margen los memos que estén en el grupo de memos establecido como filtro global.
- En una red, todos los memos que no estén en el grupo de memos establecido como filtro global aparecerán atenuados.
Grupos de redes como filtro global
- Los grupos de redes como filtros afectan la lista de redes que se ve en el administrador de redes y en todas las listas de selección.
- En el área de margen, solo se muestran las redes que estén en el grupo de redes establecido como filtro global.
- En una red, todas las redes que no estén en el grupo de redes establecido como filtro global aparecerán atenuadas.
Crear un filtro global
Crear un filtro global significa crear un grupo.
- Los grupos de documentos como filtro global filtran documentos y sus citas.
- Los grupos de códigos como filtro global filtran códigos.
- Los grupos de memos como filtro global filtran memos.
- Los grupos de redes como filtro global filtran redes.
Analizar distribuciones de códigos
Las distribuciones de códigos se muestran en el Administrador de documentos y en el Administrador de códigos en forma de gráficos de barras. En el Administrador de documentos se verá una barra por cada código. Cuanto más alta sea la barra, más veces se utilizó el código. En el Administrador de códigos, cada barra representa un documento. Dentro de la barra se puede ver cómo se distribuyen los códigos en el documento.
Después de codificar los datos, observar la distribución de códigos da una idea general de los datos. ¿Qué temas se mencionaron con más o menos frecuencia, por quién, hay diferencias entre distintos grupos de encuestados? ¿Cómo se distribuyen los temas?
Distribución de códigos entre documentos
En la primera imagen siguiente se puede ver la distribución de tres categorías: beneficios, desventajas y características del videojuego Minecraft en todos los documentos. En la segunda imagen, los datos se han filtrado a) por encuestados que evaluaron el juego de forma positiva, y b) por encuestados que lo evaluaron de forma negativa. Se puede apreciar rápidamente que hay una diferencia: los encuestados que evaluaron el juego negativamente no mencionaron ningún beneficio (barras verdes).
Distribución de códigos por documentos
En la imagen siguiente se puede ver la distribución de los distintos temas de alto nivel dentro de cada documento. Se observa, por ejemplo, que el caso 23 y el caso 25 abordan una mayor variedad de temas que los demás encuestados. Para generar este gráfico, cada categoría tiene un color diferente y todos los subcódigos dentro de una categoría también tienen el mismo color.
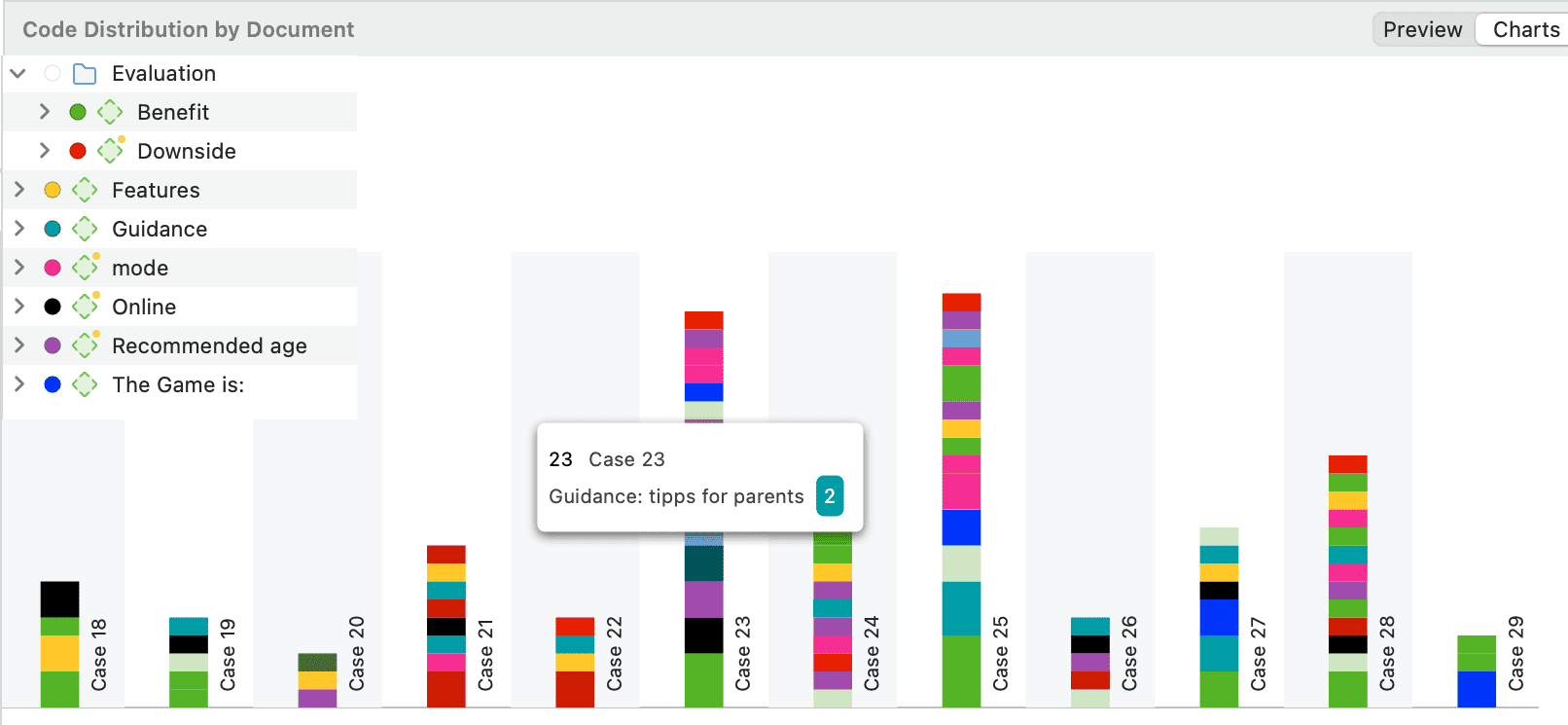
En la imagen siguiente, el foco está en dos categorías: beneficios y desventajas. Para poder diferenciar entre los distintos subcódigos de una categoría, cada subcódigo tiene un color diferente. Si se analizan datos de entrevistas, por ejemplo, esta es una excelente manera de revisar los datos categoría por categoría y comparar las respuestas de los encuestados. Se puede ver quién habló sobre beneficios o desventajas, estrategias o consecuencias, y sobre qué aspectos de esos temas principales hablaron.
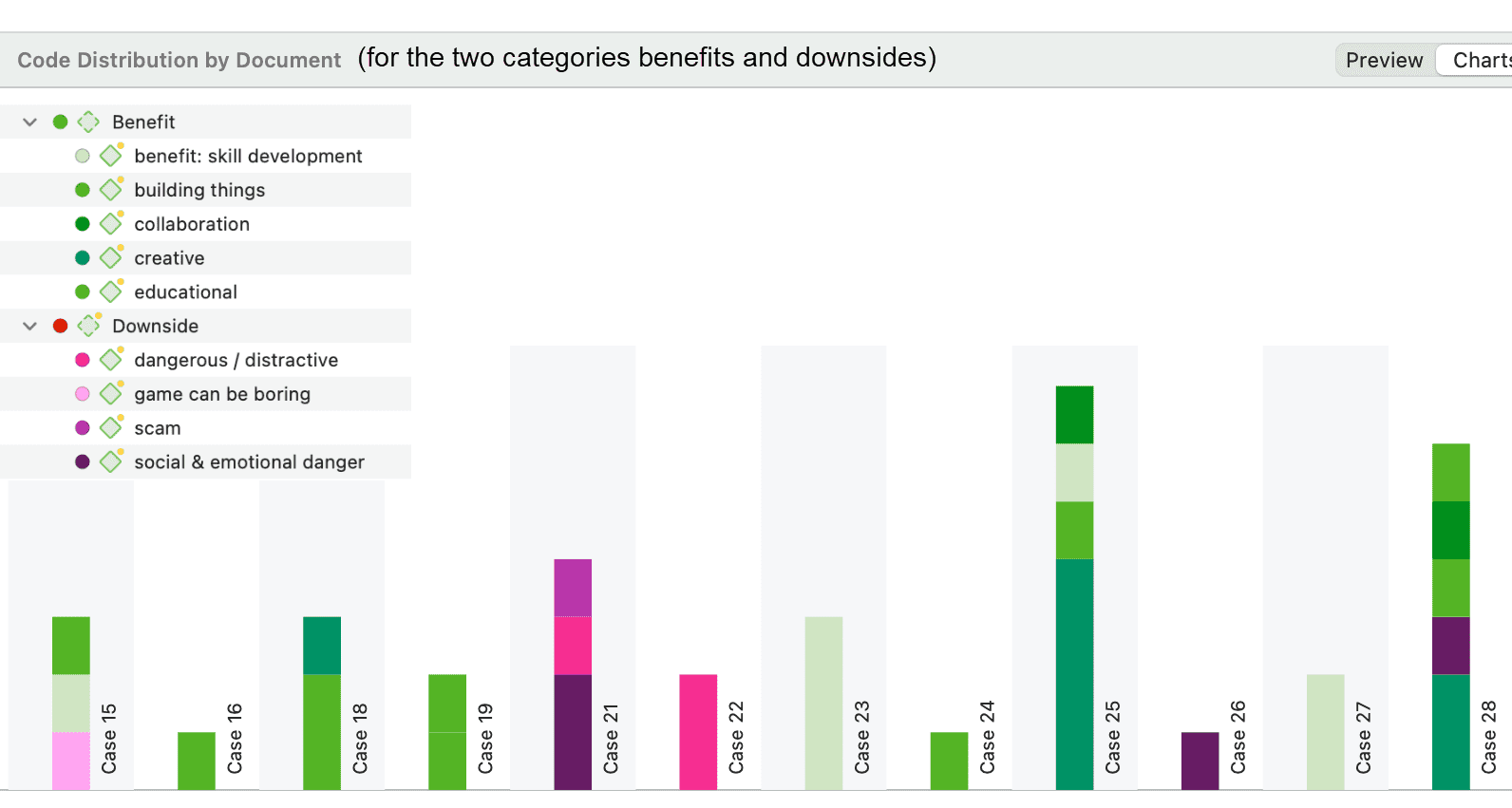
Con un clic en una barra, se pueden recuperar los datos codificados por código para cada encuestado.
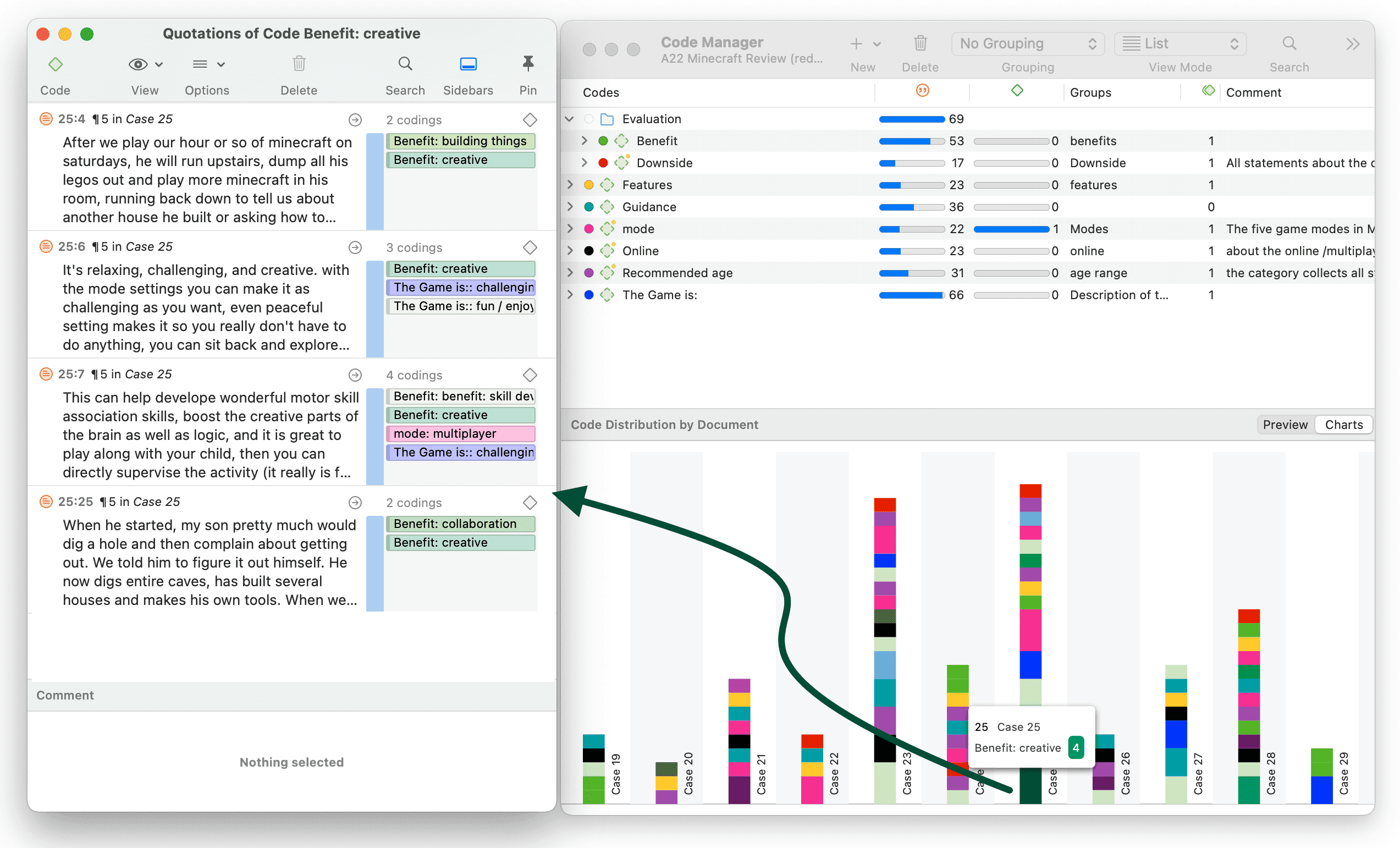
Establecer un filtro global
Los filtros globales se pueden establecer en el Explorador de proyectos de la izquierda y en cada Administrador.
Haga clic derecho sobre un grupo en la sección de grupos de documentos del Explorador de proyectos (o en un Administrador) y seleccione la opción Establecer filtro global.
Visualización de los filtros globales
Si se ha establecido un filtro global, todos los administradores, exploradores, listas y herramientas afectados muestran una barra de color en la parte superior que indica qué filtro se ha establecido.
- Los filtros globales de documentos son azules.
- Los filtros globales de citas son naranja.
- Los filtros globales de códigos son verdes.
- Los filtros globales de memos son magenta.
- Los filtros globales de redes son morados.
Activar / Desactivar filtros globales
Mientras un filtro global está activo, puede desactivarlo temporalmente haciendo clic en la casilla de verificación de la barra del filtro global que aparece encima de cada lista o tabla filtrada.
Cambiar un filtro global
Para cambiar un filtro global, haga clic derecho sobre un grupo diferente del mismo tipo y establézcalo como filtro global. Esto desactivará automáticamente el filtro activo en ese momento.
Eliminar un filtro global
Para eliminar un filtro global, haga clic en el menos (-) en el lado derecho de la barra del filtro global.
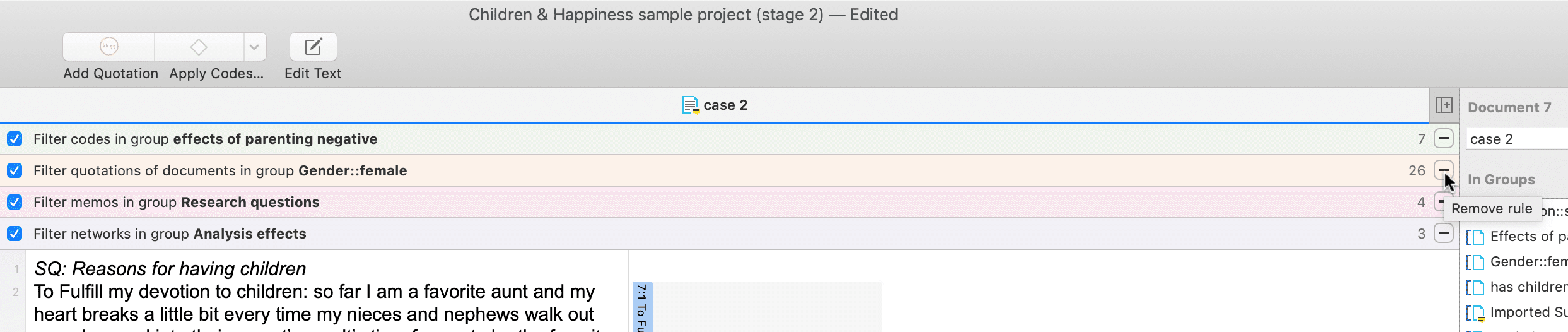
Eliminar / Cambiar / Activar / Desactivar un filtro global
Si se cambia un filtro global, el filtro activo en ese momento se restablece automáticamente (véase a continuación).
Eliminar un filtro global
Haga clic en el menos (-) en el lado derecho de la barra del filtro global.
Cambiar un filtro global
Para cambiar un filtro global, haga clic derecho sobre un grupo diferente del mismo tipo y establézcalo como filtro global. Esto desactivará automáticamente el filtro activo en ese momento.
Activar o desactivar filtros globales
Mientras un filtro global está activo, puede desactivarlo temporalmente haciendo clic en la casilla de verificación de la barra del filtro global que aparece encima de cada lista o tabla filtrada.
Filtros globales en la tabla de co-ocurrencias de códigos
La captura de pantalla siguiente muestra un filtro global activo en la tabla de co-ocurrencias de códigos. Se verá una barra en la parte superior de la tabla que indica qué tipo de filtro está establecido. Los resultados de la tabla solo mostrarán los datos que pasen el filtro.
Si se desactiva el filtro desmarcando la casilla, se verán los resultados correspondientes a todo el proyecto.
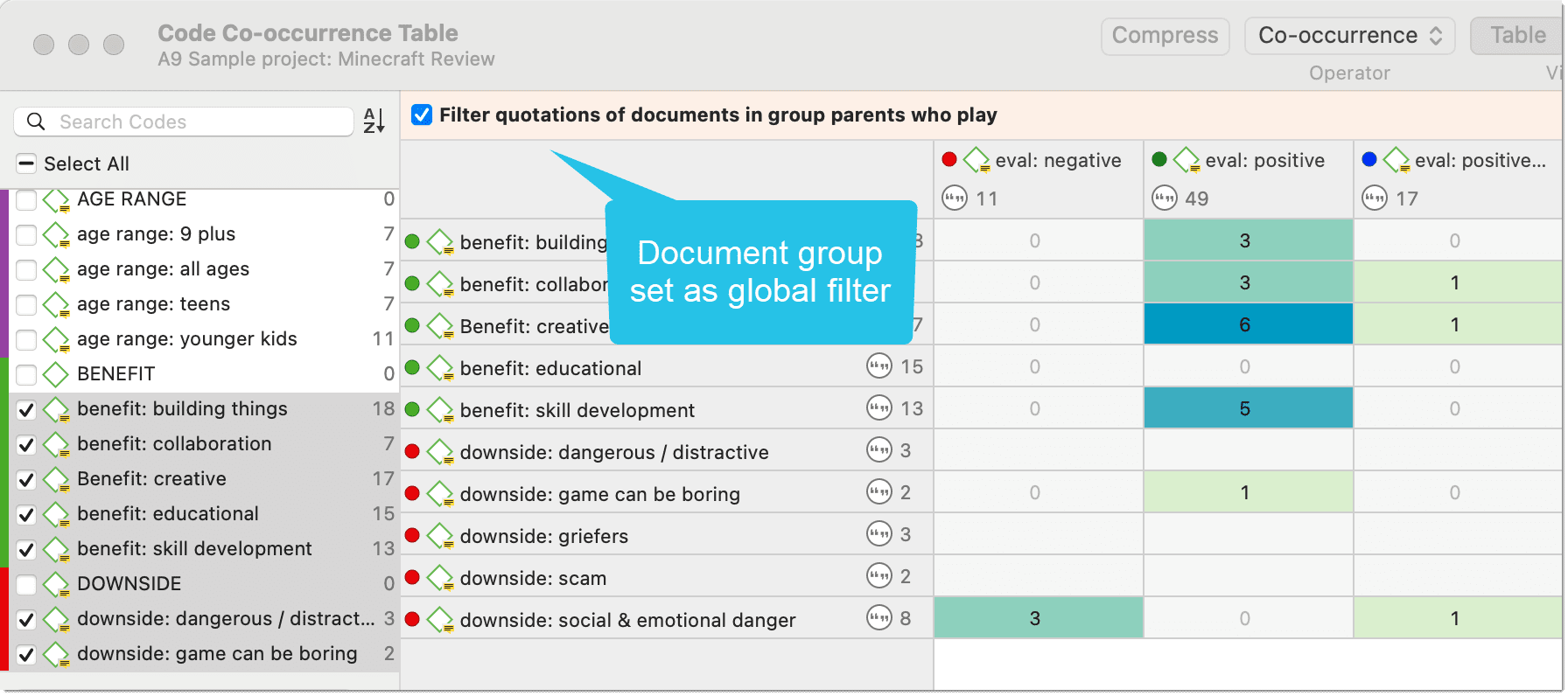
Filtros globales en la tabla código-documento
La captura de pantalla siguiente muestra un filtro global activo en la tabla código-documento. Se verá una barra en la parte superior de la tabla que indica qué tipo de filtro está establecido. Los resultados de la tabla solo mostrarán los datos que pasen el filtro.
Si se desactiva el filtro desmarcando la casilla, se verán los resultados correspondientes a todo el proyecto.

Consulta de datos en el Administrador de citas
La herramienta estándar para consultar datos puede ser la Herramienta de consulta. Sin embargo, también es posible crear consultas en el Administrador de citas. Además de las consultas de códigos, también se pueden combinar, por ejemplo, una búsqueda de texto con la consulta.
El Administrador de citas era la herramienta original para consultar datos en ATLAS.ti Mac. El problema era que los usuarios siempre buscaban una herramienta de consulta dedicada, como la que tiene ATLAS.ti Windows, y por eso pasaban por alto que construir consultas con el Administrador de citas en ATLAS.ti Mac era en realidad más potente que usar la herramienta de consulta de ATLAS.ti Windows. ATLAS.ti Mac ahora también dispone de una Herramienta de consulta que ofrece la misma funcionalidad que la herramienta de consulta de ATLAS.ti Windows.
Una consulta es una expresión de búsqueda construida a partir de operandos (códigos y grupos de códigos) y operadores (booleanos, de proximidad o semánticos), u otros filtros, que definen las condiciones que debe cumplir una cita para ser recuperada; por ejemplo, «Todas las citas codificadas tanto con el código A como con el código B que contienen la palabra XY».
Esta es la lista de filtros y operadores disponibles:

-
Cita: Seleccione esta opción si desea filtrar por citas específicas.
-
Número: Seleccione esta opción si desea filtrar por número de cita. Por ejemplo, si introduce «3», encontrará citas como 1:3; 2:3; 3:3; 4:3, etc. Si introduce «33», encontrará citas como 1:33; 3:33; 10:33, etc.
-
Nombre: Esta opción requiere que las citas hayan sido nombradas. En ese caso, puede buscar nombres de citas que contengan una determinada palabra o secuencia de letras.
-
Comentario: Esta opción permite buscar citas que contengan una determinada palabra o secuencia de letras en el comentario.
-
Tiene comentario: Esta opción permite buscar citas que tengan o no tengan comentario.
-
Contenido de texto: Seleccione esta opción si desea buscar citas que contengan una palabra o secuencia de letras específica.
-
Tipo: Utilice esta opción para filtrar citas por tipo de documento (PDF, imagen, vídeo, audio, texto o geográfico).
-
Fecha de creación: Busque citas que hayan sido creadas en una fecha específica.
-
Creado por: Busque citas que hayan sido creadas por un usuario específico.
-
Fecha de modificación: Busque citas que hayan sido modificadas en una fecha específica.
-
Modificado por: Busque citas que hayan sido modificadas por un usuario específico.
-
Está codificada con código o grupo de códigos: Busque citas que estén codificadas con un código específico o con los códigos de un grupo de códigos.
-
Vinculada con cita: Busque citas que estén vinculadas con una cita específica que seleccione de la lista de citas.
-
Vinculada con memos: Busque citas que estén vinculadas con un memo específico que seleccione de la lista de memos.
-
Está en documento o grupo de documentos: Busque citas en un documento o grupo de documentos específico. Esta opción es útil para combinarla con otra solicitud de búsqueda y restringir los resultados a un documento o grupo de documentos concreto, o a combinaciones de documentos o grupos de documentos. Véase el ejemplo a continuación.
Una consulta puede construirse de forma incremental, siendo evaluada y mostrada instantáneamente como una lista de citas. Esta construcción incremental de consultas de búsqueda complejas ofrece un enfoque exploratorio incluso para las consultas más complejas.
Así se construye una consulta en el Administrador de citas:
Abra el Administrador de citas y haga clic en el icono de filtro. A continuación, haga clic en el botón más para introducir la primera línea de la consulta.
Puede encontrar instrucciones paso a paso sobre cómo construir una consulta en los siguientes capítulos:
- Consultas booleanas de ejemplo
- Consultas de proximidad de ejemplo
- Un ejemplo de consulta compleja basada en una combinación de operadores
En la siguiente imagen se puede ver un ejemplo de una consulta construida en el Administrador de citas:
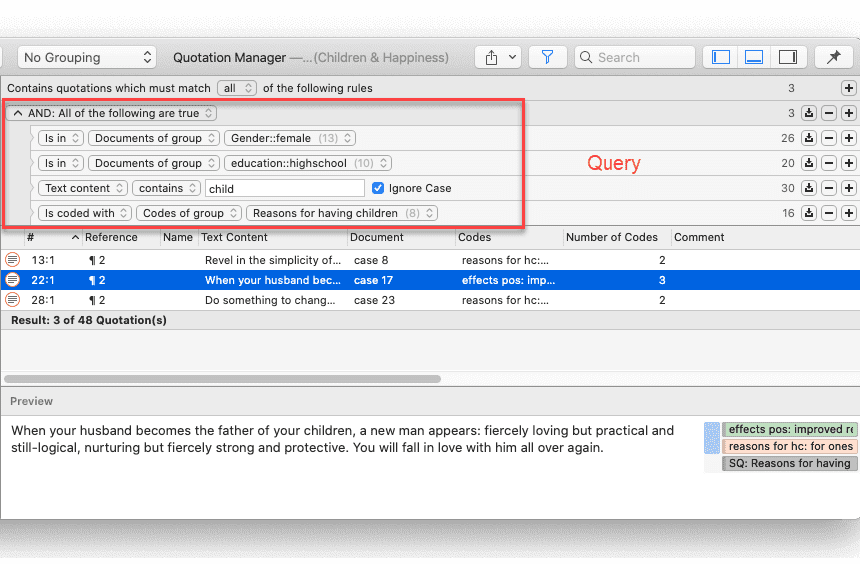
Redes en ATLAS.ti
Tutorial en video: Visualizations in Building the Understanding
La visualización puede ser un elemento clave para descubrir conexiones entre conceptos, interpretar los hallazgos y comunicar los resultados de manera efectiva. Las redes en ATLAS.ti permiten alcanzar estos tres objetivos importantes. Estos pequeños segmentos de la red de análisis más amplia se modelan mediante el editor de redes, un espacio de trabajo intuitivo que también resulta agradable a la vista.
La palabra red es una metáfora ubicua y poderosa presente en muchos campos de investigación y aplicación. Los diagramas de flujo en la planificación de proyectos, los grafos de texto en los sistemas de hipertexto y los modelos cognitivos de memoria y representación del conocimiento (redes semánticas) son todos redes que sirven para representar información compleja mediante medios gráficos intuitivamente accesibles. Una de las propiedades más atractivas de los grafos es su presentación gráfica intuitiva, principalmente en forma de disposiciones bidimensionales de nodos y vínculos etiquetados.
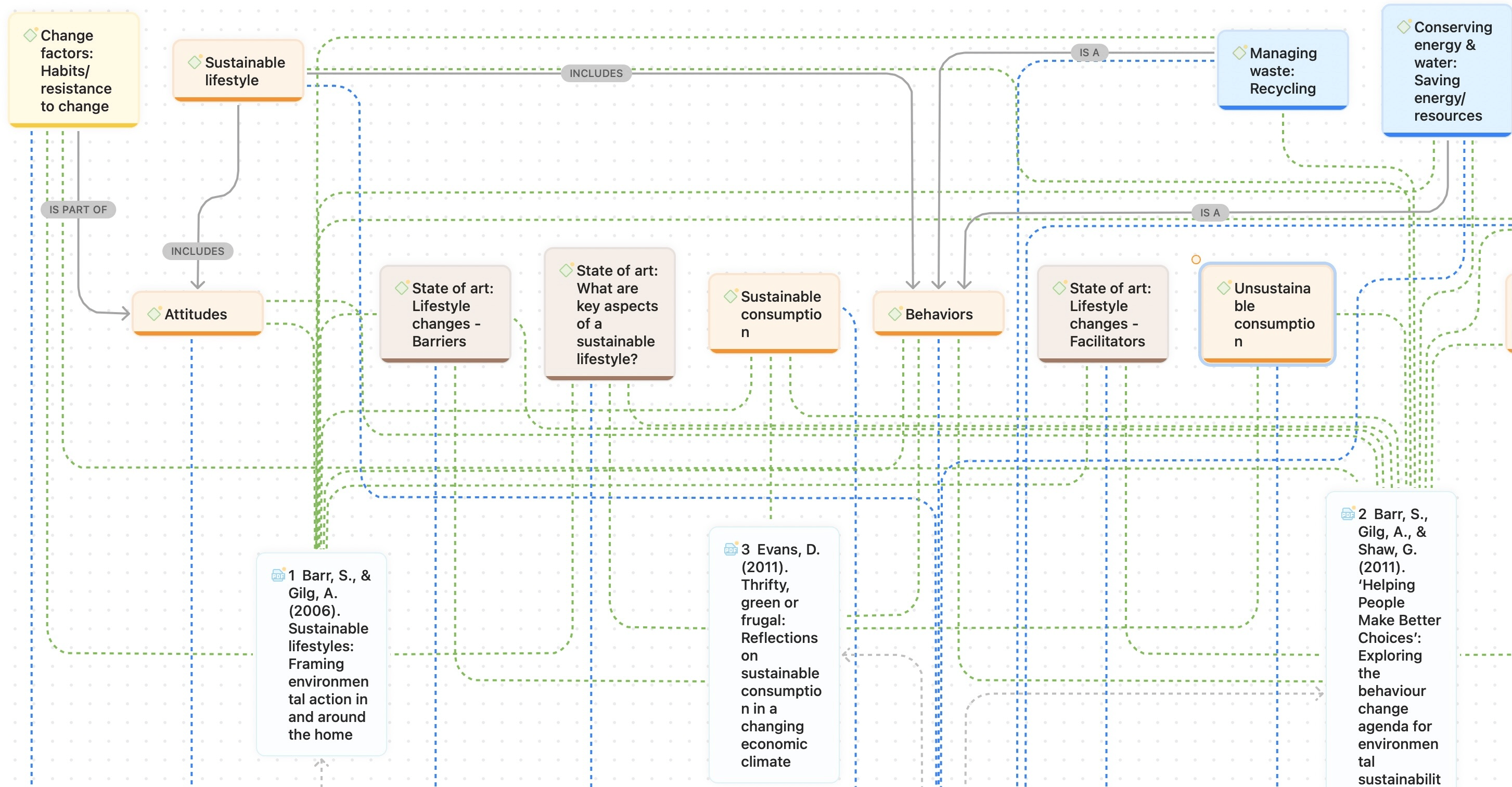
En contraste con las representaciones lineales y secuenciales (por ejemplo, el texto), las presentaciones de conocimiento en redes se asemejan más a la forma en que se estructuran la memoria y el pensamiento humanos. La "carga" cognitiva al manejar relaciones complejas se reduce con la ayuda de técnicas de representación espacial. ATLAS.ti utiliza redes para ayudar a representar y explorar estructuras conceptuales. Las redes añaden un enfoque heurístico del "hemisferio derecho" al análisis cualitativo.
El usuario puede manipular y mostrar casi todas las entidades de un proyecto como nodos en una red: citas, códigos, grupos de códigos, memos, grupos de memos, otras redes, documentos, grupos de documentos y todas las entidades inteligentes.
Nodos y vínculos
El término red se define formalmente dentro de la teoría de grafos, una rama de las matemáticas discretas, como un conjunto de nodos (o "vértices") y vínculos. Un nodo en una red puede estar vinculado a un número arbitrario de otros nodos.
El número de vínculos de cualquier nodo se denomina su grado; por ejemplo, un nodo con grado cero no está vinculado en absoluto. Otra propiedad formal simple de una red es su orden: el número de sus nodos. El grado de los nodos puede aprovecharse como criterio de ordenación en la ventana de lista de códigos. La columna "Densidad" en el Administrador de códigos representa el grado de un código.
Vínculos dirigidos y no dirigidos
Los vínculos se representan habitualmente como líneas entre los nodos conectados en las presentaciones gráficas de las redes.
Además, un vínculo entre dos nodos puede ser dirigido o no. Una conexión dirigida se representa con una flecha. En los vínculos dirigidos, se deben distinguir los nodos de origen y de destino. El nodo de origen es donde comienza el vínculo, y el nodo de destino es donde termina: el destino al que apunta la flecha.
Los vínculos se crean de forma implícita (por ejemplo, al codificar una cita, la cita queda "vinculada" a un código) o de forma explícita por el usuario. Consulte Vincular nodos.
En sentido estricto, las asociaciones código-cita ("codificaciones") también forman una red. Sin embargo, estos vínculos no pueden nombrarse; el código simplemente se asocia con una cita mediante el acto de codificar. En una red es posible visualizar estos vínculos. En ATLAS.ti, todos los vínculos sin nombre se denominan vínculos de segunda clase, y todos los vínculos con nombre se denominan vínculos de primera clase.
Vínculos de primera clase
Los vínculos de primera clase son vínculos basados en relaciones. Son entidades en sí mismos, con nombres, autores, comentarios y otras propiedades. Están disponibles para:
-
Vínculos entre dos códigos. Estos incluyen:
- vínculos entre dos códigos de categoría
- vínculos entre dos subcódigos (dentro o entre categorías)
- vínculos entre un subcódigo y sus propios códigos de categoría u otros
-
Vínculos entre dos citas. Estos últimos se denominan hipervínculos. Consulte Trabajar con hipervínculos.
Vínculos de segunda clase
Los vínculos de segunda clase son vínculos que no tienen propiedades individuales. Estos son:
-
vínculos entre citas y códigos
-
todos los vínculos hacia memos
-
todos los vínculos entre un grupo y sus miembros
-
todos los vínculos jerárquicos:
- vínculos entre categorías y sus subcódigos
- vínculos entre carpetas
- vínculos entre carpetas y categorías
- vínculos entre carpetas y códigos independientes
- vínculos entre carpetas y subcódigos
- vínculos entre carpetas
Si se modifican los vínculos jerárquicos en la red, esto afecta a la jerarquía de códigos y carpetas en todo el proyecto.
Por qué los grupos no pueden vincularse
Los grupos no pueden vincularse porque, por definición, no son mutuamente excluyentes. Un documento puede agregarse a tantos grupos de documentos como se desee. Lo mismo aplica a los grupos de códigos. Un código puede ser miembro de múltiples grupos de códigos.
Los grupos son filtros. Los grupos de códigos son considerados a veces por los usuarios como una categoría de orden superior, lo cual no son. Consulte Construir un sistema de códigos para más detalles.
Para comparar y analizar documentos según determinados criterios, como características sociodemográficas, se agregan a grupos de documentos como género::masculino / femenino, estado civil::soltero / casado / separado / divorciado, etc. Esto también permite combinar ciertos criterios, por ejemplo, ejecutar un análisis para todas las encuestadas que están casadas. Consulte Trabajar con grupos de documentos y Trabajar con grupos inteligentes.
Del mismo modo, el propósito de los grupos de códigos es ser utilizados como filtros. Un filtro útil podría ser todos los códigos de una categoría, pero también todos los códigos relevantes para una determinada pregunta de investigación, o todos los códigos que podrían clasificarse como una estrategia, una consecuencia o un contexto a través de diferentes categorías.
Así, podría haber un grupo de códigos que contenga los códigos A, B, C y D, y otro grupo de códigos que contenga los códigos B, D, E y F. Si se relacionaran estos dos grupos de códigos entre sí, se obtendrían relaciones circulares o ilógicas.
Relaciones
ATLAS.ti permite establecer vínculos con nombre para expresar con mayor claridad la naturaleza de las relaciones entre conceptos. Con vínculos con nombre, es posible expresar una frase como "una pierna rota causa dolor" mediante dos nodos (el nodo de origen "pierna rota" y el nodo de destino "dolor") conectados con un vínculo con nombre ("causa" o "es-causa-de").
El nombre de un vínculo se muestra en el editor de redes como una etiqueta adjunta al vínculo, a mitad de camino entre los dos nodos conectados.
En ATLAS.ti se dispone de seis relaciones preestablecidas. Estas relaciones estándar pueden sustituirse, modificarse o complementarse con relaciones definidas por el usuario.
Vínculo vs. relación
Es importante comprender la diferencia entre una relación (o tipo de vínculo) y el vínculo en sí: solo existe una relación "es parte de", pero potencialmente muchos vínculos pueden usarla.
Si se observa el Administrador de vínculos código-código que se muestra a continuación, es fácil ver cómo funciona:
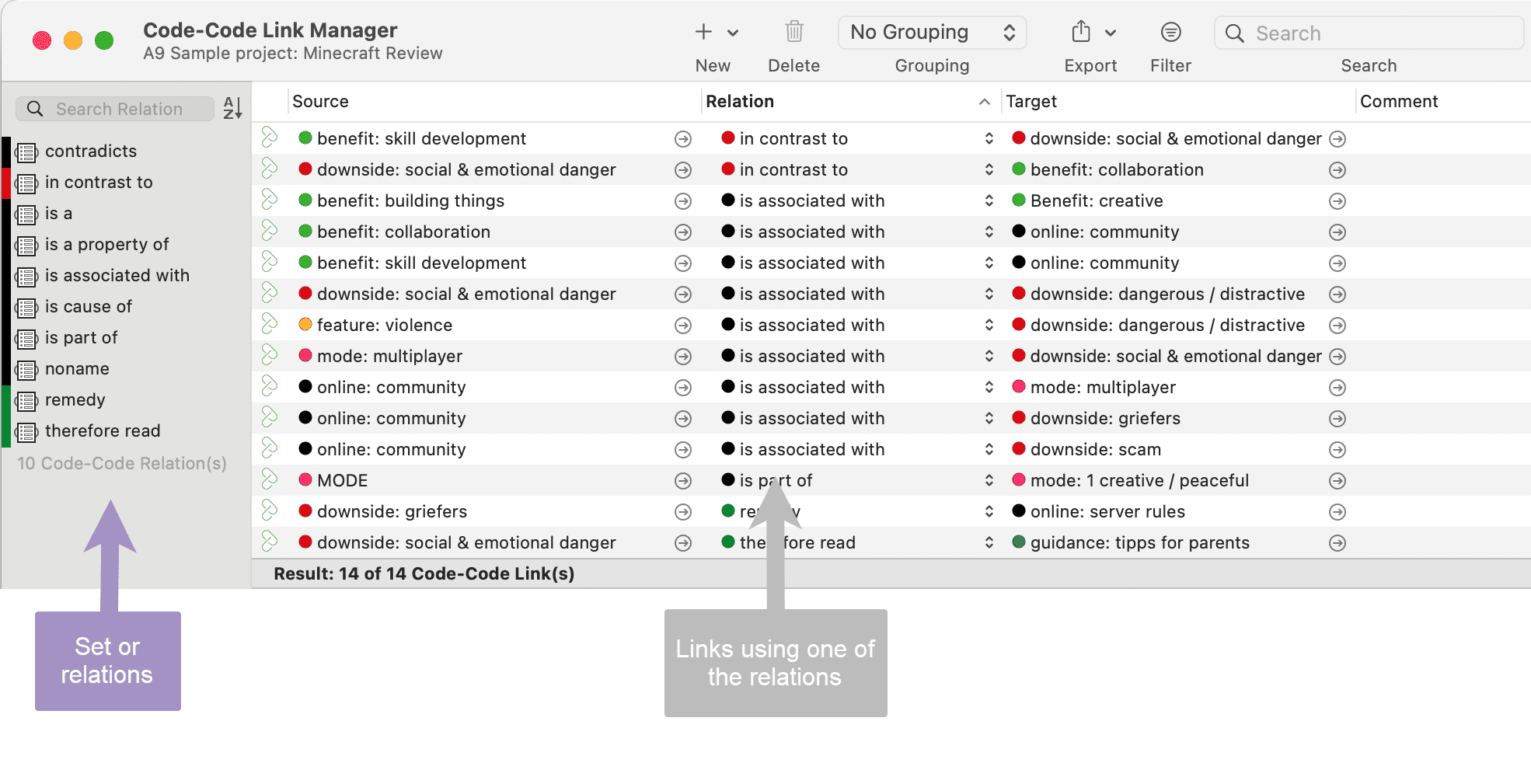
Otra forma de entender los vínculos y las relaciones es considerar los vínculos como instancias de relaciones. Los vínculos se rigen por las características de las relaciones, que definen sus estilos. Si se cambia una característica de una relación (por ejemplo, el grosor de línea, el color o el símbolo), estos cambios se propagan a todos los vínculos que la utilizan.
Relaciones predeterminadas de ATLAS.ti
Las relaciones predeterminadas que incluye el software se enumeran en la tabla siguiente. C1 y C2 son los nodos de origen y de destino, respectivamente.
| Nombre de la relación | nombre corto | nombre simbólico | grosor | color | propiedad |
|---|---|---|---|---|---|
| is associated with | R | == | 1 | Negro | Simétrica |
| is part of | G | [] | 1 | Negro | Asimétrica |
| is cause of | N | => | 1 | Negro | Asimétrica |
| contradicts | A | <> | 1 | Negro | Simétrica |
| is a | Isa | 0 | 2 | Negro | Asimétrica |
| noname | 1 | Negro | Simétrica | ||
| is property of | P | *} | 1 | Negro |
Algunas de estas características afectan directamente a la visualización de los vínculos, mientras que otras afectan al procesamiento (por ejemplo, rutinas de búsqueda, disposición automática). Un vínculo entre conceptos se muestra en el editor de redes mediante una línea con la etiqueta de la relación. Se puede elegir entre tres etiquetas diferentes (nombre, nombre corto y nombre simbólico).
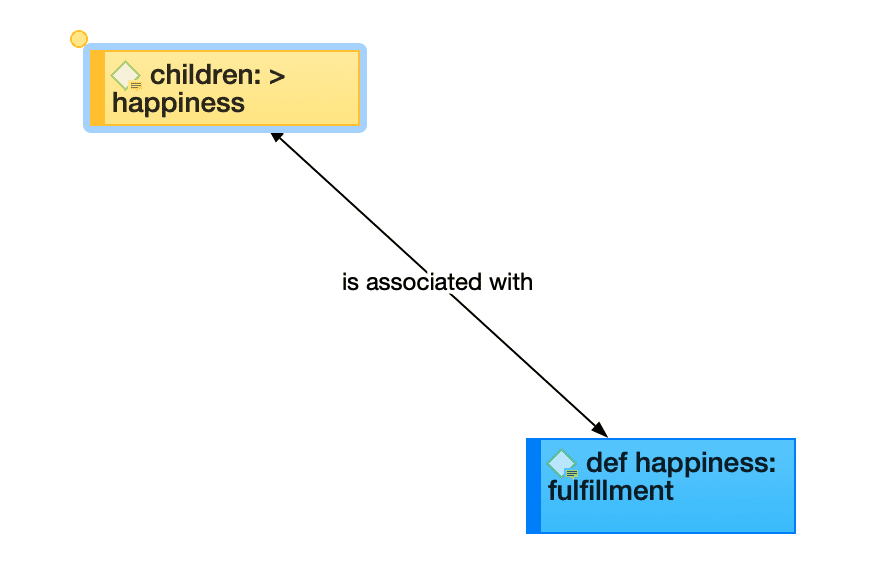
La propiedad de la relación afecta a la visualización de una relación. Todas las relaciones asimétricas se simbolizan en el editor de redes con una flecha que apunta hacia el código de destino. Las relaciones simétricas se muestran como una línea con dos flechas que apuntan hacia ambos extremos del vínculo.
Las siguientes propiedades son definibles por el usuario: las etiquetas, el grosor y el color de la línea que une dos nodos, la propiedad y la dirección de disposición preferida.
La dirección de disposición preferida afecta a la disposición de una red al abrir una red ad hoc.
Propiedades formales - algunas definiciones
Relación simétrica
Una relación R es simétrica si se cumple para todos los pares A y B relacionados mediante R que: A está relacionado con B si, y solo si, B está relacionado con A.
Ejemplos:
- A está casado con B (en la mayoría de los sistemas legales)
- A es hermano biológico completo de B
- A es un homófono de B
Ejemplos de AQC:
- predicar con el ejemplo está asociado con ser un modelo a seguir
- tener una visión clara está relacionado con orientación al rendimiento
- comunicarse bien está asociado con el empoderamiento
Relaciones asimétricas
Un grafo es asimétrico si:
- para cada arista, no existe una arista en la dirección contraria; entonces la relación es asimétrica
- no se permiten bucles en un dígrafo asimétrico
Si x tiene una relación R con y, pero y no tiene una relación R con x.
Ejemplos:
- Martín es hijo de Marilyn: si Martín es hijo de Marilyn, entonces Marilyn no puede ser hija de Martín.
Ejemplos de AQC:
Si se usa el mismo ejemplo anterior, pero en cambio se define la relación da como resultado como asimétrica, no se infiere que el buen tiempo esté necesariamente relacionado con el hecho de ser una persona feliz, ni que ser una persona feliz tenga algún efecto sobre el clima. Esto último ocurriría si se usara una relación simétrica.
Las relaciones en el siguiente ejemplo se definen como relaciones asimétricas: Un entorno favorable motiva el aprendizaje y el desarrollo, que da como resultado una mayor satisfacción laboral. Esto no implica que un entorno favorable dé como resultado una mayor satisfacción laboral.
Administrador de relaciones
El Administrador de relaciones se utiliza para revisar las propiedades de las relaciones existentes, editar relaciones existentes o crear nuevas relaciones. Puede cambiar entre las relaciones para vínculos código-código y las relaciones para hipervínculos. Como la información de las columnas y las opciones de la cinta son las mismas para ambos, a continuación encontrará una única descripción. Para obtener más información, consulte Trabajar con redes.
Puede acceder al Administrador de relaciones para códigos a través del menú Código, y al Administrador de relaciones para hipervínculos a través del menú Cita.
Nombre: Puede mostrar el nombre completo, el nombre abreviado o el nombre simbólico de todas las relaciones en una red.
Formal: La propiedad formal de una relación: simétrica, asimétrica o transitiva. Consulte Acerca de las relaciones.
Comentario: Descripción breve del tipo de relación.
Para obtener más información, consulte Crear nuevas relaciones.
El editor de redes
El editor de redes ofrece un método intuitivo y potente para crear y manipular estructuras de red. Favorece una técnica de manipulación directa: literalmente se pueden "agarrar" códigos, citas, memos u otras entidades con el cursor y moverlos por la pantalla, así como trazar y cortar vínculos entre ellos.
Las redes tienen ciertas características importantes:
- Las redes pueden recibir nombres con los que se almacenan y se accede a ellas dentro del proyecto.
- Las redes pueden comentarse.
- Las redes se muestran y editan en el editor de redes.
- Las redes permiten disposiciones individuales de los nodos.
- Como nodo, una entidad individual puede ser miembro de cualquier número de redes.
- Una entidad, por ejemplo un código específico, solo puede aparecer una vez en cualquier red.
Las redes permiten una visualización flexible pero lógicamente coherente de vínculos y relaciones, por lo que existen algunas restricciones a tener en cuenta:
- Si el código A está vinculado al código B mediante la relación is associated with, entonces toda red que contenga el código A y el código B incluirá necesariamente la relación is associated with entre ambos.
- Además, dado que solo puede existir un vínculo entre dos nodos en cualquier momento dado, ninguna red mostrará otra relación entre esos dos nodos.
Si se desea vincular el código A y el código B de diferentes maneras en distintas redes, es necesario trabajar con códigos "ficticios" que modifiquen una relación. Por ejemplo:
Un contexto específico X resulta en la emoción A que lleva al comportamiento B; entonces vincular directamente A con B sería incorrecto:
Emoción A ---- lleva a ----> Comportamiento B
Sin embargo, puede expresarse de esta manera:
Emoción A ---- si ----> contexto X -----lleva a-----> Comportamiento B
"Contexto X" es un código ficticio ya que no existía previamente en el sistema de códigos. Fue necesario añadirlo para expresar una relación que emerge al trabajar e interpretar los datos.
Para visualizar tales relaciones, existe la opción de crear nuevos códigos en el editor de redes. Estos aparecerán en la lista de códigos con una fundamentación de 0 y una densidad de 1 o más, dependiendo de su nivel de conectividad en la red.
Tipos de nodos
Las siguientes clases de objetos pueden mostrarse y editarse como nodos dentro del editor de redes.
Códigos como nodos
Los códigos son probablemente los objetos más destacados en las redes de ATLAS.ti. Proporcionan los ingredientes principales para los modelos y las teorías.
Memos como nodos
Los memos en las redes son a menudo un complemento importante de las redes de códigos.
Varios memos teóricos pueden importarse a una red para mapear sus relaciones. La disposición visual proporciona un espacio cómodo para desplazarse de memo en memo, con el fin de leer y reflexionar sobre cada uno individualmente y sobre las relaciones entre ellos.
Documentos como nodos
Los documentos como nodos son útiles para comparaciones de casos combinados con la opción de agregar vecinos de código.
Los documentos como nodos conforman un agradable índice de contenido gráfico para documentos gráficos al seleccionar la vista previa.
Los íconos de los nodos de documentos varían según el tipo de medio.
Citas como nodos
Las citas y los códigos tienen algo en común que difiere de las otras entidades: pueden vincularse entre sí (citas con citas y códigos con códigos) con vínculos "de primera clase" completamente calificados. Consulte Nodos y vínculos.
La inclusión de citas en una red apoya la construcción e inspección de estructuras de hipervínculos. Los íconos de los nodos de citas varían según el tipo de medio.
Grupos como nodos
Mostrar grupos y sus miembros en redes es útil para presentar todos los miembros que forman parte del grupo. Los vínculos entre un grupo y sus miembros se representan mediante una línea roja punteada. La propiedad de la línea no puede modificarse.
Redes como nodos
Las redes como nodos permiten incluir redes dentro de otras redes. No pueden vincularse a nada, pero mediante el menú contextual se puede abrir la red en un editor de redes independiente.
Si se hace doble clic en un nodo de red, se muestra su comentario y desde allí se puede hacer clic para abrirlo. Esto es útil, por ejemplo, cuando el espacio en pantalla es limitado. En lugar de intentar representar todo en una sola red, se pueden crear varias redes que se construyan unas sobre otras. A través de un nodo de red dentro de una red, se puede continuar contando la historia que se desea transmitir.
Opciones de vista de la red
En ATLAS.ti para Mac dispone de las siguientes opciones de vista:
Mostrar conexiones código-documento: A veces es interesante ver qué códigos se han aplicado a un documento o grupo de documentos. Al codificar datos, se aplican códigos a citas, que forman parte de los documentos, pero no se aplican códigos directamente a los documentos. Por lo tanto, no existen vínculos directos entre documentos y códigos. Para ver esas conexiones, es necesario activar esta opción.
Mostrar vistas previas de entidades: Puede activar una vista previa para documentos, citas y memos. Los documentos o citas de audio y video pueden reproducirse en la ventana de vista previa. Si solo desea ver la vista previa de una entidad específica, haga clic derecho sobre la entidad y seleccione la opción Vista previa en el menú contextual.
Mostrar comentarios de entidades: Si está activado, se muestran los comentarios de todos los nodos que tienen comentarios.
Mostrar densidad:
- Número de conexiones código-código
- Número de códigos y memos con los que está conectado un memo
- Número de códigos con los que está codificada una cita
Mostrar fundamentación: Muestra cuántas citas están vinculadas a un código o memo.
Editor de redes – Opciones de disposición y enrutamiento
Disposición

Abra el menú desplegable del botón Disposición en la barra de herramientas. Tiene las siguientes opciones:
Circular: La disposición circular coloca los nodos en un círculo, eligiendo cuidadosamente el orden de los nodos alrededor del círculo para reducir los cruces y colocar los nodos adyacentes cerca entre sí. Enfatiza las estructuras de grupos y árboles dentro de una red. Crea particiones de nodos al analizar la estructura de conectividad de la red y organiza las particiones como círculos separados. Los propios círculos se organizan de manera similar a una disposición de árbol radial. Este algoritmo se adapta muy bien al análisis de redes sociales.
Jerárquica: El estilo de disposición jerárquica tiene como objetivo resaltar la dirección o flujo principal dentro de un grafo dirigido. Los nodos de un grafo se colocan en capas organizadas jerárquicamente de tal manera que la mayoría de las aristas del grafo muestran la misma orientación general, por ejemplo, de arriba hacia abajo. Además, el orden de los nodos dentro de cada capa se elige de manera que el número de cruces de aristas sea pequeño.
-
De arriba hacia abajo: Prefiere colocar los nodos hacia abajo, de arriba a abajo, siguiendo los vínculos dirigidos.
-
De abajo hacia arriba: Prefiere colocar los nodos hacia arriba, de abajo a arriba, siguiendo los vínculos dirigidos.
-
De izquierda a derecha: Prefiere colocar los nodos de izquierda a derecha siguiendo los vínculos dirigidos.
-
De derecha a izquierda: Prefiere colocar los nodos de derecha a izquierda siguiendo los vínculos dirigidos.
Enrutamiento
Enrutamiento ortogonal: Este es un algoritmo de disposición versátil y potente para enrutar las aristas de un diagrama usando únicamente segmentos de línea verticales y horizontales. Las posiciones de los nodos del diagrama permanecen fijas. Por lo general, las aristas enrutadas no cortarán ningún nodo ni se superpondrán a otras aristas.
Enrutamiento recto: Traza los vínculos entre nodos como líneas rectas sin considerar los cruces de nodos y aristas.
La disposición de enrutamiento no se guarda. Si cierra la red y la vuelve a abrir, el enrutamiento se pierde y debe seleccionar nuevamente una opción de enrutamiento. Si está satisfecho con la disposición y desea conservar la red tal como está, debe exportarla.
Organizar
Al construir la red y organizar los nodos, las siguientes opciones ayudan a alinear los nodos seleccionados:
- Alinear a la izquierda
- Alinear al centro
- Alinear a la derecha
- Alinear arriba
- Alinear al medio
- Alinear abajo
- Distribuir horizontalmente
- Distribuir verticalmente
- Traer nodo al frente
- Enviar nodo al fondo
- Restablecer tamaños de nodos
Procedimientos básicos de redes
Existen dos métodos para crear redes. El primero crea una red vacía y luego se van agregando entidades de forma secuencial. El otro método crea una red a partir de una entidad seleccionada y sus vecinos.
Crear una nueva red
Abra el menú desplegable de Redes en la barra de herramientas y seleccione Nueva red. La red se abre de inmediato en el espacio principal. Se recomienda cambiar el nombre predeterminado en el inspector.
Otra opción es abrir el Administrador de redes y crear una nueva red allí haciendo clic en el botón de más.
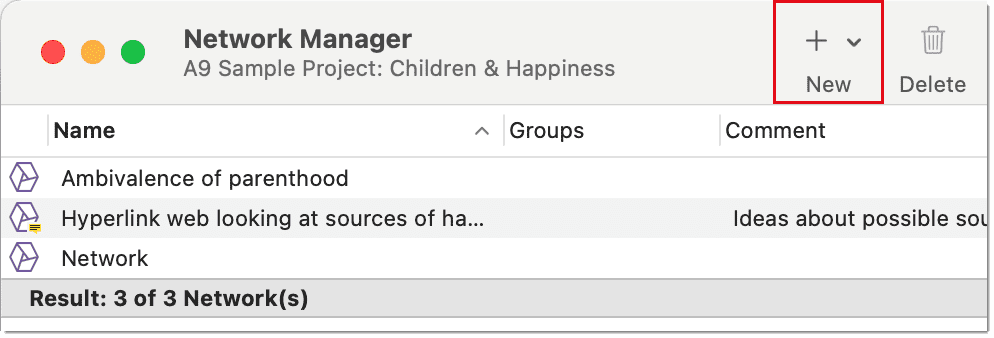
Agregar nodos a una red
Puede agregar nodos mediante el botón Agregar nodos en la barra de herramientas, o mediante arrastrar y soltar.
Agregar nodos usando la lista de selección
Haga clic en el botón Agregar nodos en la barra de herramientas.

Agregar nodos usando la lista de selección
Haga clic en el botón Agregar nodos en la barra de herramientas.
Esto abre una lista de selección anclada en el lado izquierdo de la red. En la parte inferior de la lista de selección se muestran los comentarios de una entidad. Use los campos de búsqueda para encontrar entidades más rápido.
Seleccione el tipo de entidad y luego las entidades que desea agregar a la red. Haga doble clic para agregar la entidad a una red; o arrastre y suelte las entidades seleccionadas en la red; o haga clic en el botón Agregar.
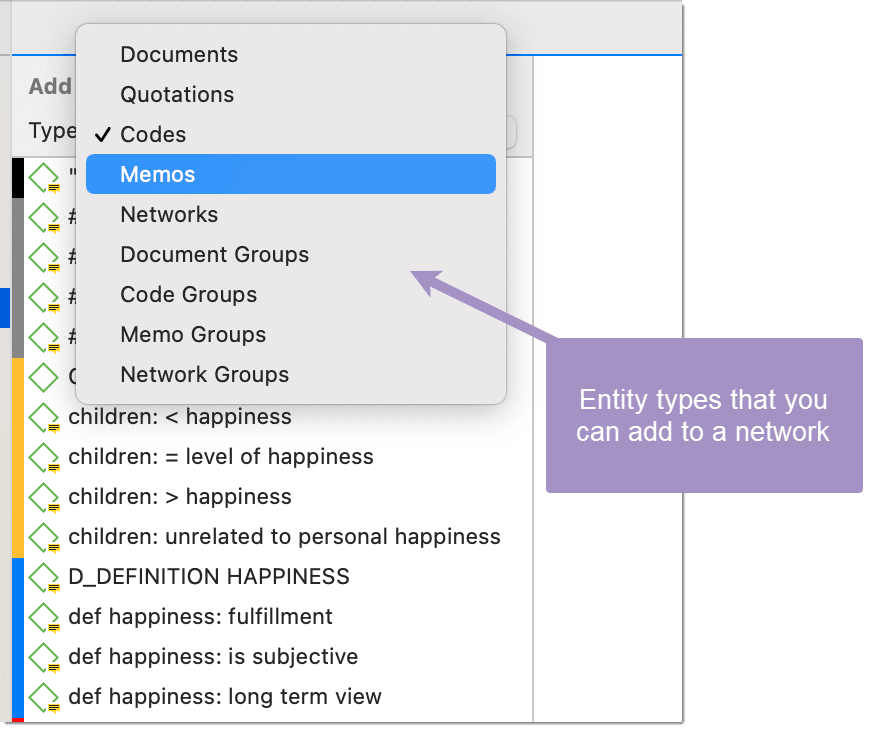
Agregar nodos mediante arrastrar y soltar
Puede agregar nodos arrastrando entidades al editor de redes desde los administradores de entidades, los administradores de grupos, el margen, el explorador de proyectos o cualquiera de los navegadores.
Abra una red y colóquela, por ejemplo, junto al Explorador de proyectos.
Seleccione los nodos que desea importar a la red y arrástrelos y suéltelos en el editor.
Seleccionar nodos
Seleccionar nodos es un primer paso importante para todas las operaciones posteriores dirigidas a entidades individuales dentro de una red.
Seleccionar un único nodo
Mueva el puntero del ratón sobre el nodo y haga clic izquierdo.
Todos los nodos seleccionados previamente se deseleccionan.

Seleccionar múltiples nodos
Método 1
Mantenga presionada la tecla cmd del teclado, mueva el puntero del ratón sobre el nodo y haga clic izquierdo. Repita esto para cada nodo que desee seleccionar.
Método 2 Este método es muy eficiente si los nodos que se desean seleccionar caben dentro de un rectángulo imaginario.
Mueva el puntero del ratón por encima y a la izquierda de uno de los nodos que desea seleccionar. Mantenga presionado el botón izquierdo del ratón y arrastre el puntero hacia abajo y a la derecha para cubrir con el marco de selección todos los nodos que desea seleccionar. Suelte el botón del ratón.
Abrir redes ad hoc
Una red ad hoc se crea al abrir una red sobre una entidad. Esto mostrará la entidad en una red con todos los vecinos directamente vinculados, excepto cuando se abre una red para un documento o múltiples elementos. En estos dos últimos casos, solo las entidades seleccionadas se abren en una red. Se pueden agregar más nodos a dichas redes usando diferentes técnicas. Consulte Agregar nodos a una red y Agregar vecinos.
Seleccione una entidad en el área de margen, un administrador, el explorador de proyectos o cualquier navegador, haga clic derecho y seleccione Mostrar en red.

Los nodos se colocan inicialmente usando un procedimiento de disposición predeterminado, pero pueden reorganizarse manualmente o usando cualquiera de los otros procedimientos de disposición. Consulte Disposición y enrutamiento.
A continuación se muestra una red ad hoc de una carpeta que contiene tres categorías y sus subcódigos.
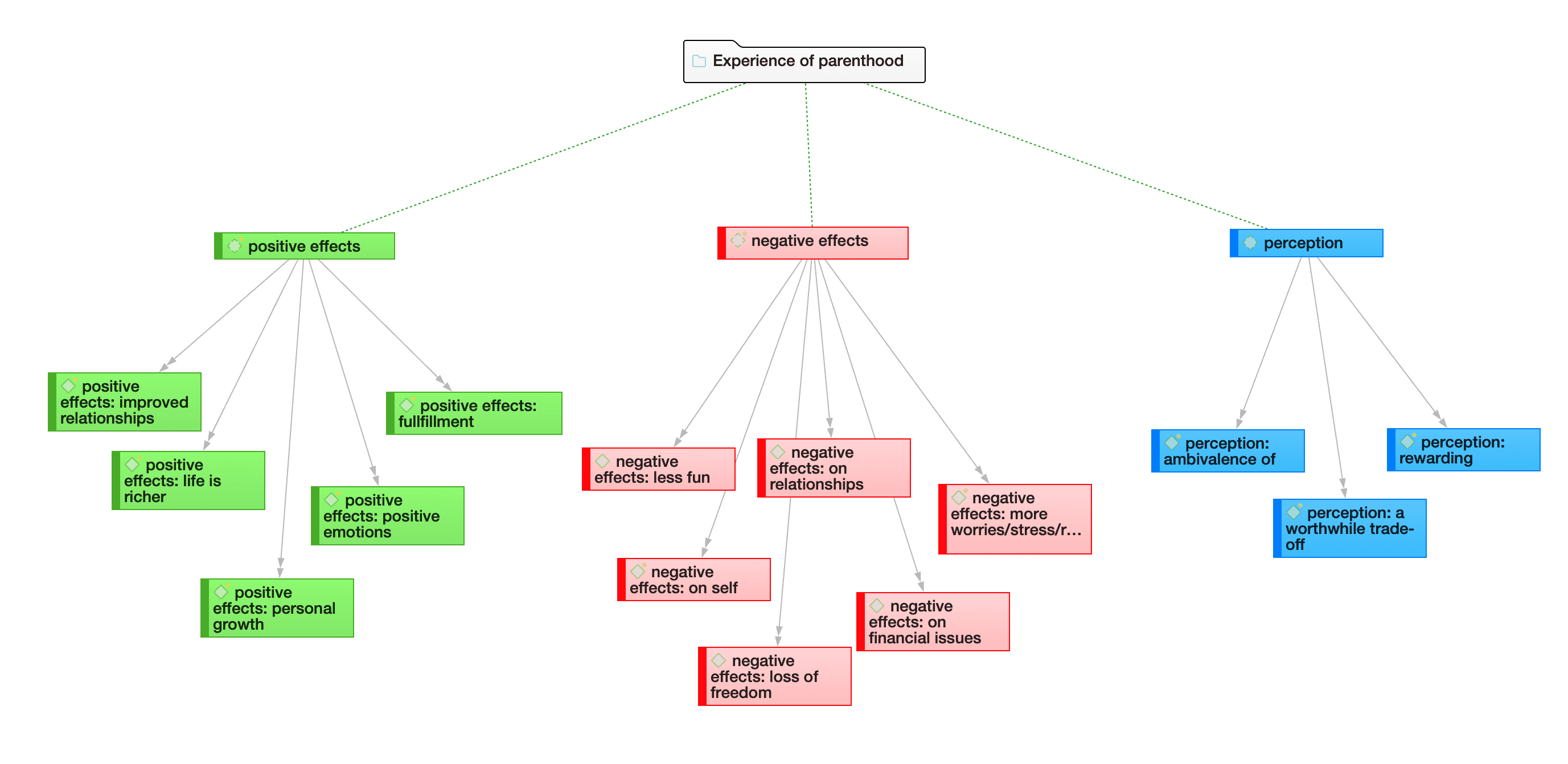
Vincular nodos y entidades
Seleccione uno o más nodos. Aparece un punto en la esquina superior izquierda del nodo o los nodos. Haga clic en el punto con el botón izquierdo del ratón y arrastre el puntero hacia el nodo que desea vincular. Si ha resaltado más de un nodo, debe seleccionar el punto de uno de los nodos.
Suelte el botón izquierdo del ratón sobre el nodo. Si vincula códigos con códigos o citas con citas, se abre una lista de relaciones. Seleccione una relación.
Los dos nodos quedan ahora vinculados entre sí. Si vinculó dos códigos o dos citas entre sí, el nombre de la relación se muestra encima de la línea.
Si ninguna de las relaciones existentes es adecuada, seleccione Crear relación y cree una nueva relación. La nueva relación se aplicará inmediatamente al vínculo.
Editar un vínculo
Haga clic en un vínculo. Si el vínculo tiene una relación, haga clic en la relación, ya que esto facilita su selección. Un vínculo seleccionado se muestra en azul.
Haga clic derecho para abrir el menú secundario. Para una relación con nombre, dispone de las siguientes opciones:
-
Editar comentario: Use el campo de comentario para explicar por qué estos dos nodos están vinculados.
-
Invertir vínculo: Use esta opción si desea cambiar la dirección de un vínculo transitivo o asimétrico.
-
Abrir en el Administrador de vínculos: El Administrador de vínculos para códigos lista todos los vínculos código-código; el Administrador de vínculos para citas lista todos los hipervínculos. En el Administrador de vínculos puede revisar todos los vínculos, filtrar por relaciones, escribir comentarios o modificar relaciones.
-
Cambiar relación: Seleccione una relación diferente de la lista de relaciones disponibles o cree una nueva y aplíquela.
-
Abrir relación en el Administrador: para revisar y modificar relaciones existentes, o para crear nuevas relaciones.
-
Copiar: Crea una descripción en texto plano de la relación entre las dos entidades, que puede pegarse en un comentario, memo o editor de texto.
-
Desvincular: Elimina el vínculo entre los dos nodos.
Vincular códigos con códigos, citas con citas y memos con memos en administradores y navegadores
Las citas, los códigos y los memos también pueden vincularse entre sí en otros lugares, por ejemplo, en el Administrador, el Explorador de proyectos o los navegadores de entidades correspondientes.
Seleccione uno o más elementos de origen en el panel de lista del Administrador, en las subramificaciones correspondientes del Explorador de proyectos, o en los navegadores de entidades y arrástrelos al elemento de destino en el mismo panel.
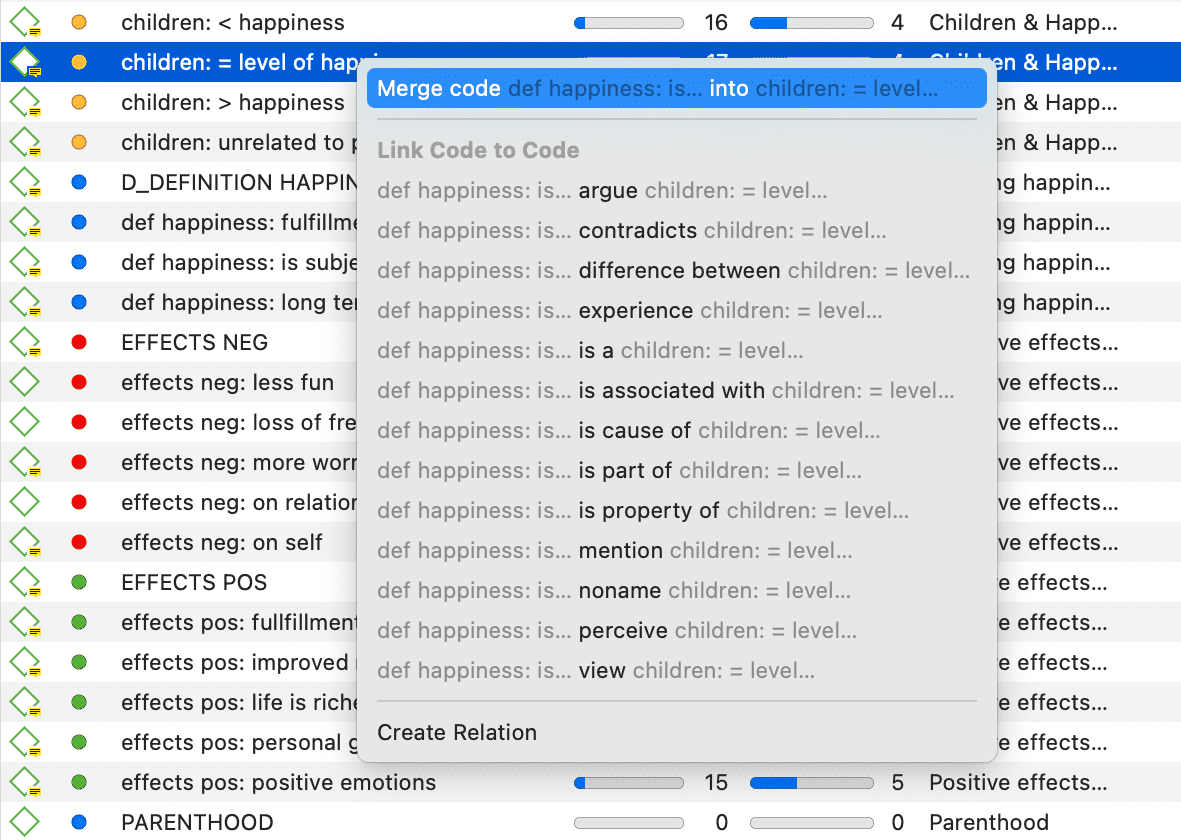
Vinculación de dos códigos en el Administrador de códigos
Seleccione una relación de la lista de relaciones si vincula dos códigos o dos citas, o seleccione Crear relación y cree una nueva relación.
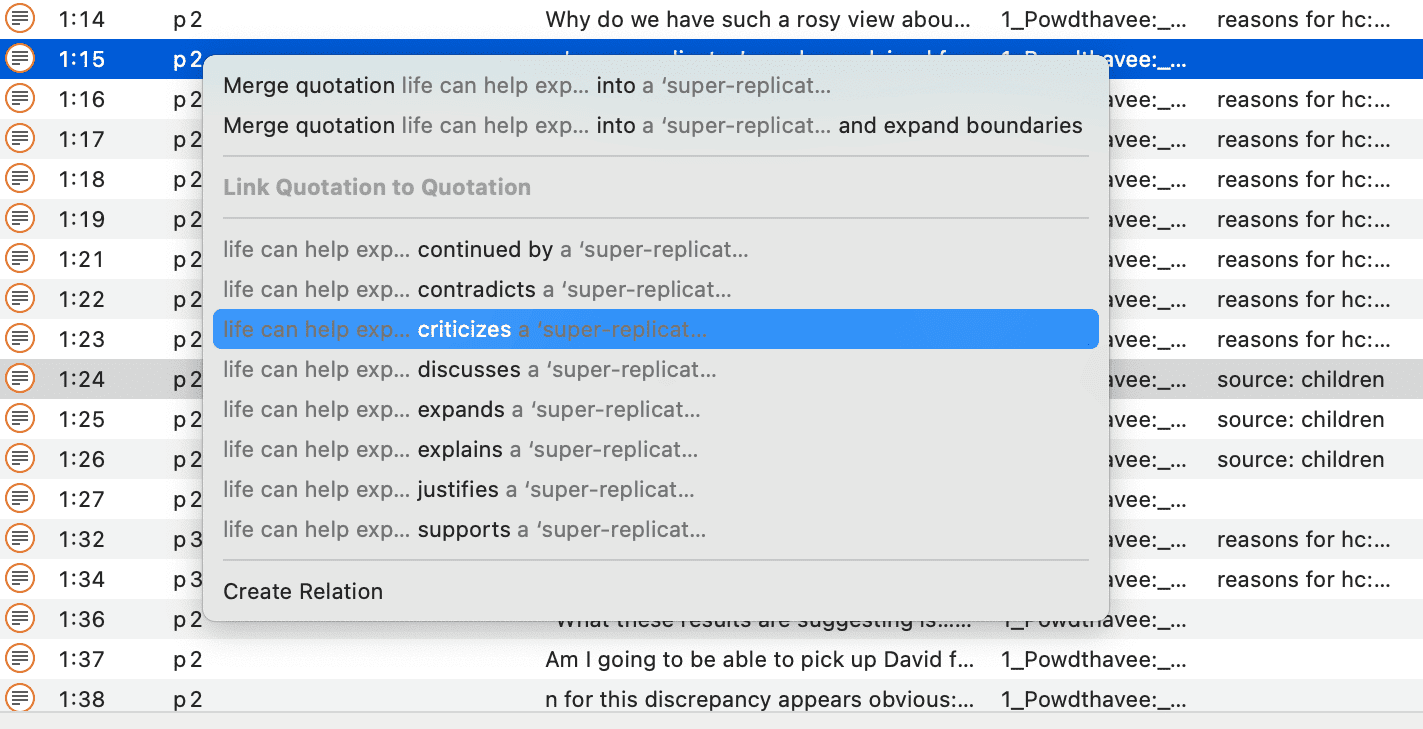
Vinculación de dos citas en el Administrador de citas - Crear un hipervínculo
Vincular entidades de distintos tipos
Cuando codifica sus datos leyendo un documento, escuchando datos de audio o visualizando un archivo de imagen o video, está vinculando códigos a citas. También puede vincular citas a códigos en una red, aunque esto es más excepcional que un procedimiento habitual.
Vincular un memo a un código en una red, o un memo a una cita puede ser algo que se haga con mayor frecuencia. Funciona básicamente igual que vincular dos códigos entre sí. La diferencia es que no se puede nombrar el vínculo entre memos y códigos, o memos y citas, o memos y memos. Estos son vínculos de segunda clase, como se explica en la sección Acerca de los nodos y vínculos.
Tenga en cuenta que las siguientes entidades no pueden vincularse entre sí:
- citas con documentos
- memos con documentos (use un comentario de documento en su lugar)
- códigos con documentos (sin embargo, puede ver las conexiones código-documento; consulte las opciones de Vista)
- códigos con grupos de códigos, documentos con grupos de documentos, o memos con grupos de memos (si lo hace, el código / documento / memo se convertirá en miembro del grupo correspondiente)
- grupos entre sí (ya que un código puede ser miembro de múltiples grupos de códigos, esto podría crear relaciones circulares)
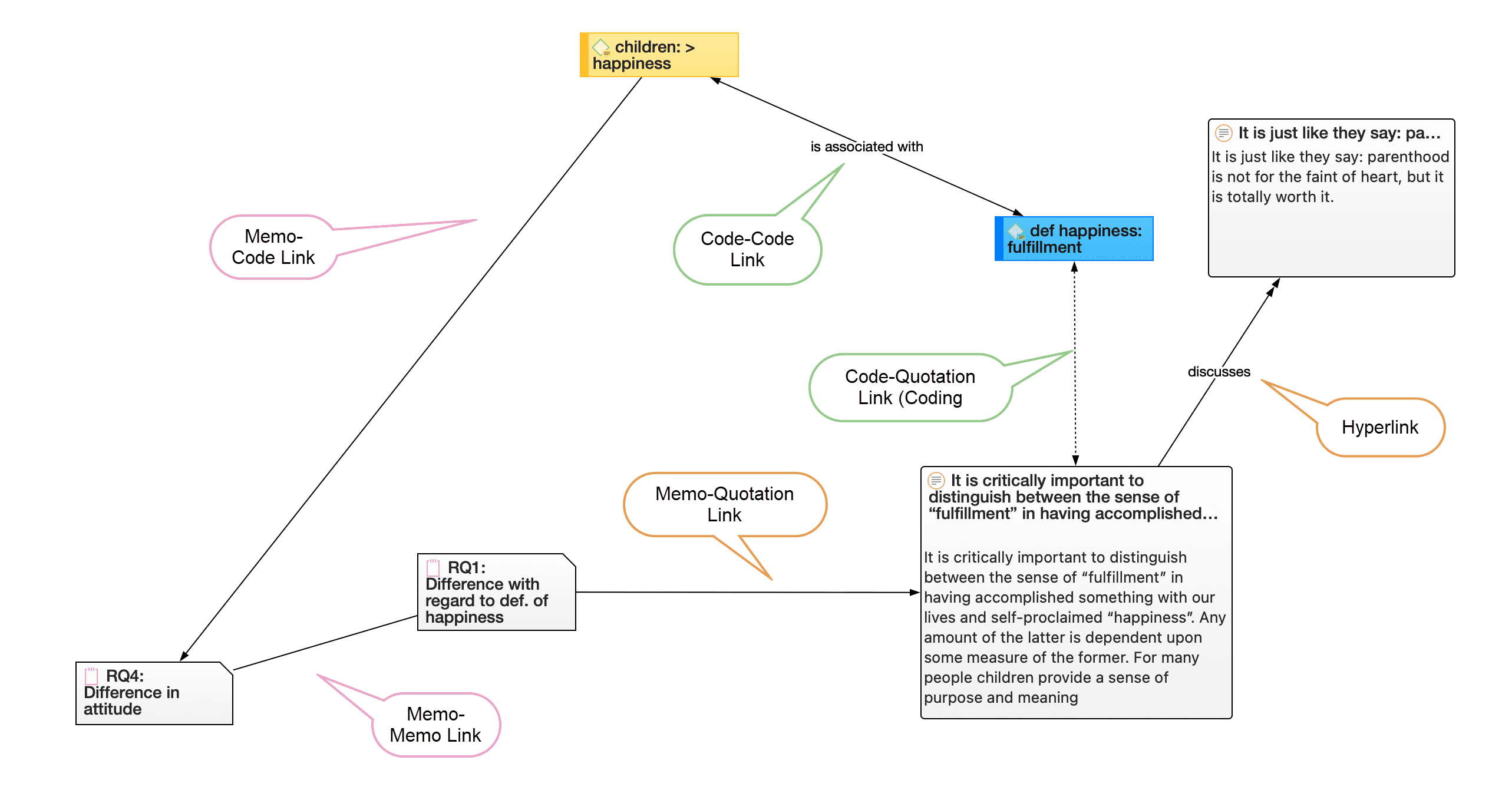
Crear y modificar relaciones
Las relaciones definidas por el usuario están disponibles para los vínculos código-código y cita-cita. El resto de los vínculos no pueden nombrarse.
Las nuevas relaciones se crean en el Administrador de relaciones. Se puede definir el aspecto de una relación en términos de color, grosor y estilo de línea. Además, se puede seleccionar la dirección de disposición y la propiedad. La propiedad define si una relación es dirigida (transitiva, asimétrica) o no dirigida (simétrica). Consulte Acerca de las relaciones.
Crear nuevas relaciones para vínculos código-código
En el menú principal, seleccione Código > Mostrar administrador de relaciones.
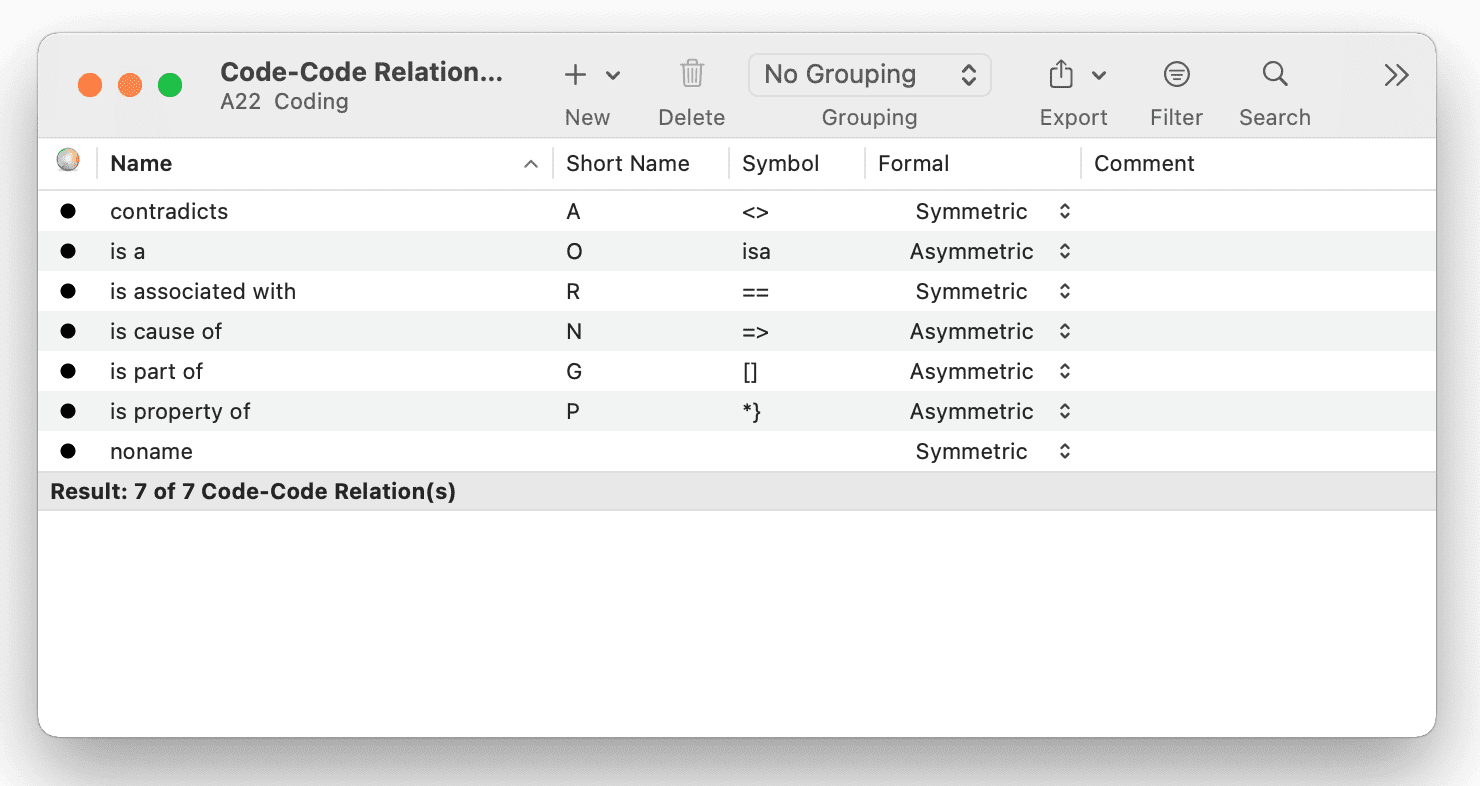
Haga clic en el botón más e ingrese un nombre para la relación.
En el lado derecho del inspector, puede definir la relación:
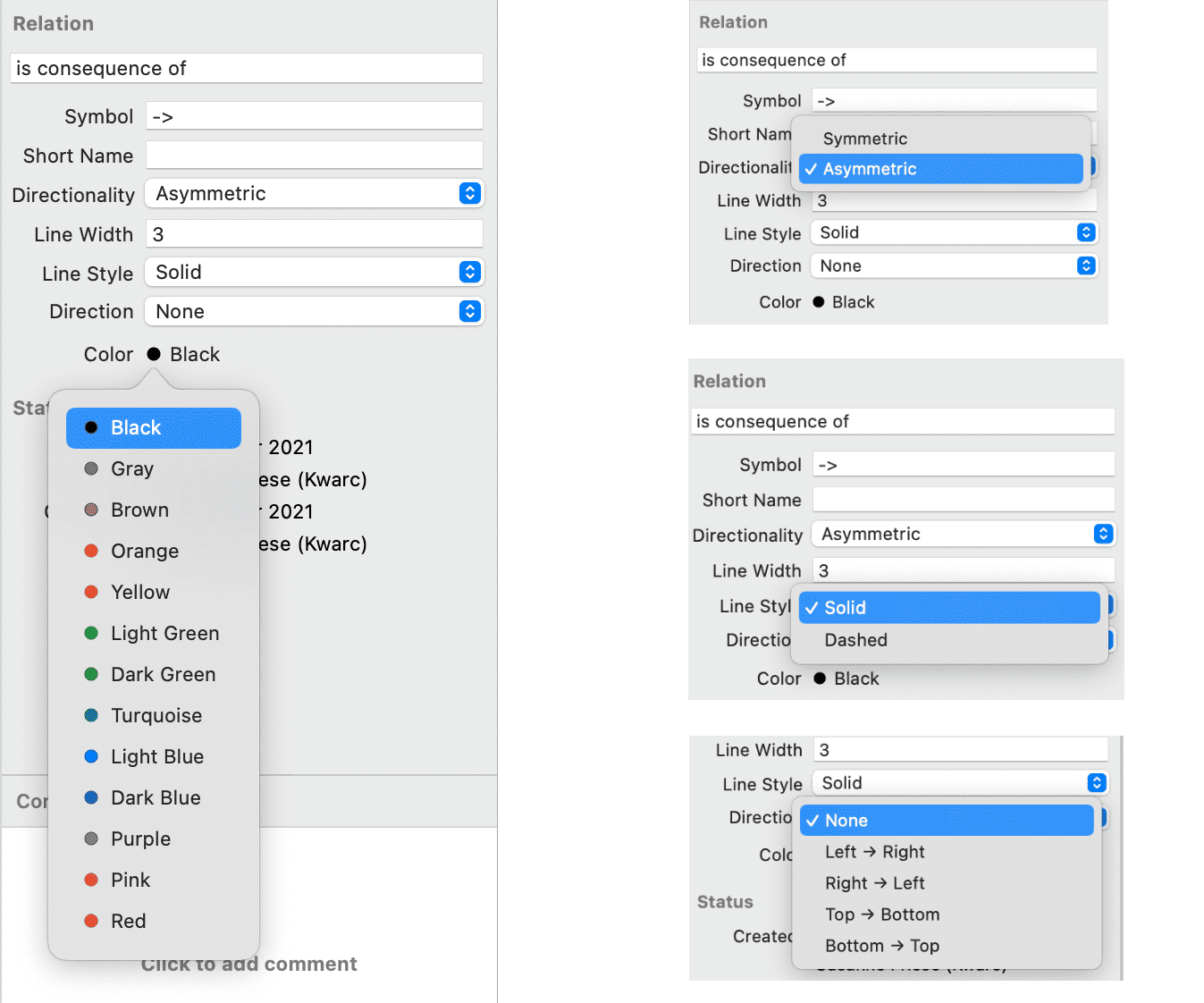
-
ingrese un nombre simbólico o corto. Estos pueden usarse como opciones de visualización alternativas. En lugar del nombre corto, también puede ingresar un nombre en un idioma diferente en casos en que tenga proyectos en distintos idiomas. De esta manera, no es necesario crear un nuevo conjunto de relaciones para cada idioma que utilice.
-
Defina una propiedad formal: simétrica o asimétrica. Consulte Acerca de las relaciones para más información.
-
Establezca un grosor de línea, por ejemplo para indicar la fuerza de una relación.
-
Seleccione un estilo de línea, dirección y color.
Crear nuevas relaciones para hipervínculos
En el menú principal, seleccione Cita > Mostrar administrador de relaciones.
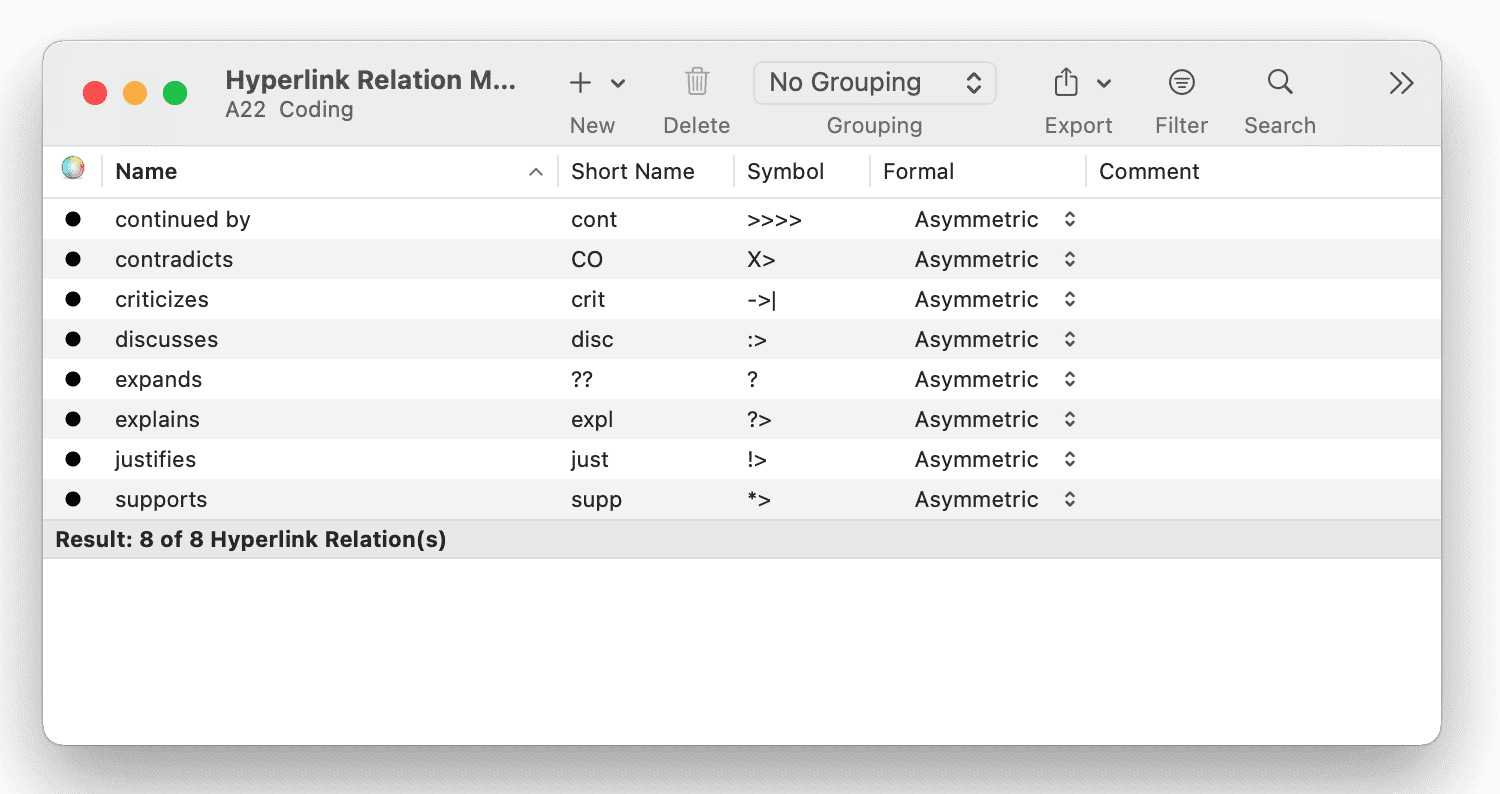
Haga clic en el botón más e ingrese un nombre para la relación.
En el lado derecho del inspector, puede definir la relación:
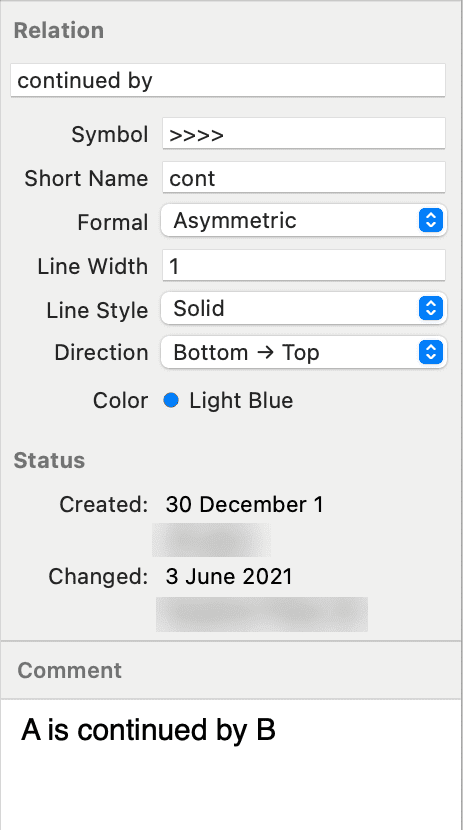
-
ingrese un nombre simbólico o corto. Estos pueden usarse como opciones de visualización alternativas. En lugar del nombre corto, también puede ingresar un nombre en un idioma diferente en casos en que tenga proyectos en distintos idiomas. De esta manera, no es necesario crear un nuevo conjunto de relaciones para cada idioma que utilice.
-
Defina una propiedad formal: simétrica o asimétrica. Consulte Acerca de las relaciones para más información.
-
Establezca un grosor de línea; por ejemplo, puede usar diferentes grosores para indicar la fuerza de una relación.
-
Seleccione un estilo de línea, dirección y color.
Las nuevas relaciones se almacenan junto con el proyecto en el que se utilizan. Por lo tanto, se puede crear un conjunto único de relaciones para cada proyecto.
Editar relaciones existentes
Para modificar una relación existente, abra el Administrador de relaciones para códigos o citas (ver arriba).
Seleccione la relación que desea modificar y cambie sus propiedades, como el color de línea, el grosor de línea, el estilo de línea, la dirección de disposición o la propiedad. También puede cambiar el nombre de la relación. Todas las opciones se encuentran en el inspector en el lado derecho.
Si la relación que se está modificando ya está en uso en el proyecto cargado actualmente, los cambios tendrán efecto inmediato y se almacenarán junto con el proyecto al guardarlo.
Funciones analíticas en redes
La herramienta de redes es en sí misma una herramienta analítica. Al construir redes conceptuales se aprende mucho sobre los datos. Las dos opciones que se presentan aquí son:
- Agregar vecinos
- Agregar códigos co-ocurrentes
Estas dos opciones son el equivalente visual de la Tabla código-documento y la Tabla de co-ocurrencia de códigos.
Para ambas opciones, a menudo resulta útil establecer primero un filtro global, ya que de lo contrario se importan demasiados elementos. Esto genera una red muy saturada que puede ser visualmente atractiva, pero tiene poco valor analítico. Consulte Aplicar filtros globales.
Agregar vecinos
La opción agregar vecinos permite construir una red conectada paso a paso. Importa todos los vecinos directos de los nodos seleccionados a la red.
-
Al aplicarla a nodos de documentos, es el equivalente visual de la Tabla código-documento. ATLAS.ti traza líneas azules entre los códigos y los documentos o grupos de documentos en los que aparecen.
-
Al aplicarla a hipervínculos, permite traer a la red todas las citas conectadas.
-
Al aplicarla a códigos, permite incorporar sucesivamente códigos conectados para apoyar el modelado de datos y la construcción de teorías.
Cómo agregar vecinos
Seleccione uno o más nodos, haga clic derecho y seleccione la opción Agregar vecinos en el menú contextual; luego elija el tipo de entidad que desea importar.
Para los documentos al agregar códigos, asegúrese de que Mostrar conexiones código-documento esté seleccionado en Vista en la barra de herramientas.
 .
.
Dependiendo del tipo de entidad, los vecinos posibles son:
- Documentos
- Citas
- Códigos
- Memos
- Grupos
La opción todos los comunes importa todos los que sean aplicables.
Aplicación: comparación de casos
Agregar vecinos de código a un nodo de documento o a un nodo de grupo de documentos permite crear una red basada en casos. Se pueden plantear preguntas como: ¿cuáles de los códigos se han aplicado en qué documento o grupos de documentos? ATLAS.ti traza líneas azules entre los códigos y los documentos o grupos de documentos en los que aparecen. Asegúrese de que Mostrar conexiones código-documento esté seleccionado en las opciones de Vista.
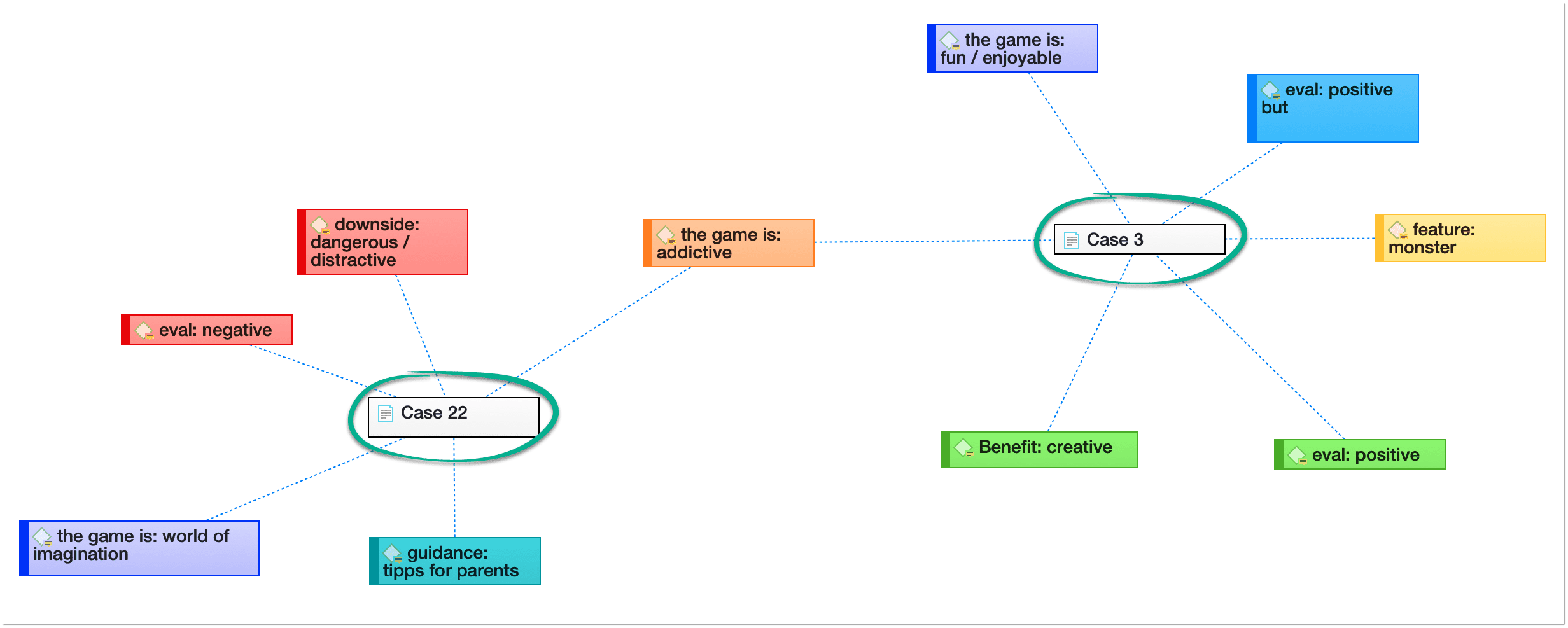
Cuando se han aplicado muchos códigos a un documento, es útil establecer un filtro global al agregar códigos. De lo contrario, la red estará demasiado saturada y será difícil interpretarla o identificar patrones significativos. Consulte Aplicar filtros globales.
Agregar códigos co-ocurrentes
La opción agregar códigos co-ocurrentes es el equivalente visual de las Herramientas de co-ocurrencia de códigos. Permite explorar la co-ocurrencia de códigos de forma espacial, lo cual es diferente a observar números en una tabla o explorar la co-ocurrencia en un diagrama de Sankey. Se recomienda usar estas funciones en combinación para examinar los datos desde distintas perspectivas en el sentido de una triangulación.
Los códigos co-ocurrentes son aquellos que codifican las mismas citas o citas superpuestas. Al importar códigos co-ocurrentes, ATLAS.ti verifica las cinco formas posibles en que un código puede co-ocurrir:
-
las citas codificadas con el código A se superponen con las citas codificadas con el código B
-
las citas codificadas con el código A son solapadas por las citas codificadas con el código B
-
las citas codificadas con el código A aparecen dentro de las citas codificadas con el código B
-
las citas codificadas con el código A engloban las citas codificadas con el código B
-
las citas codificadas con el código A codifican las mismas citas que el código B
Consulte Operadores disponibles > Operadores de proximidad.
Seleccione uno o más códigos en un editor de redes, haga clic derecho y seleccione Agregar códigos co-ocurrentes.
Es posible ver los códigos co-ocurrentes sin agregarlos a la red haciendo clic derecho sobre los códigos de interés y eligiendo una de las opciones de co-ocurrencia en el submenú Análisis.
Para obtener resultados significativos, a menudo es útil establecer primero un grupo de códigos como filtro global. Piense en qué conceptos desea relacionar entre sí y agréguelos a un grupo de códigos. Consulte Aplicar filtros globales.
A continuación se muestra una red con configuración de filtro global. Solo los nodos con color completo pasan el filtro. Esto ayuda a concentrarse en lo que es relevante en la red:
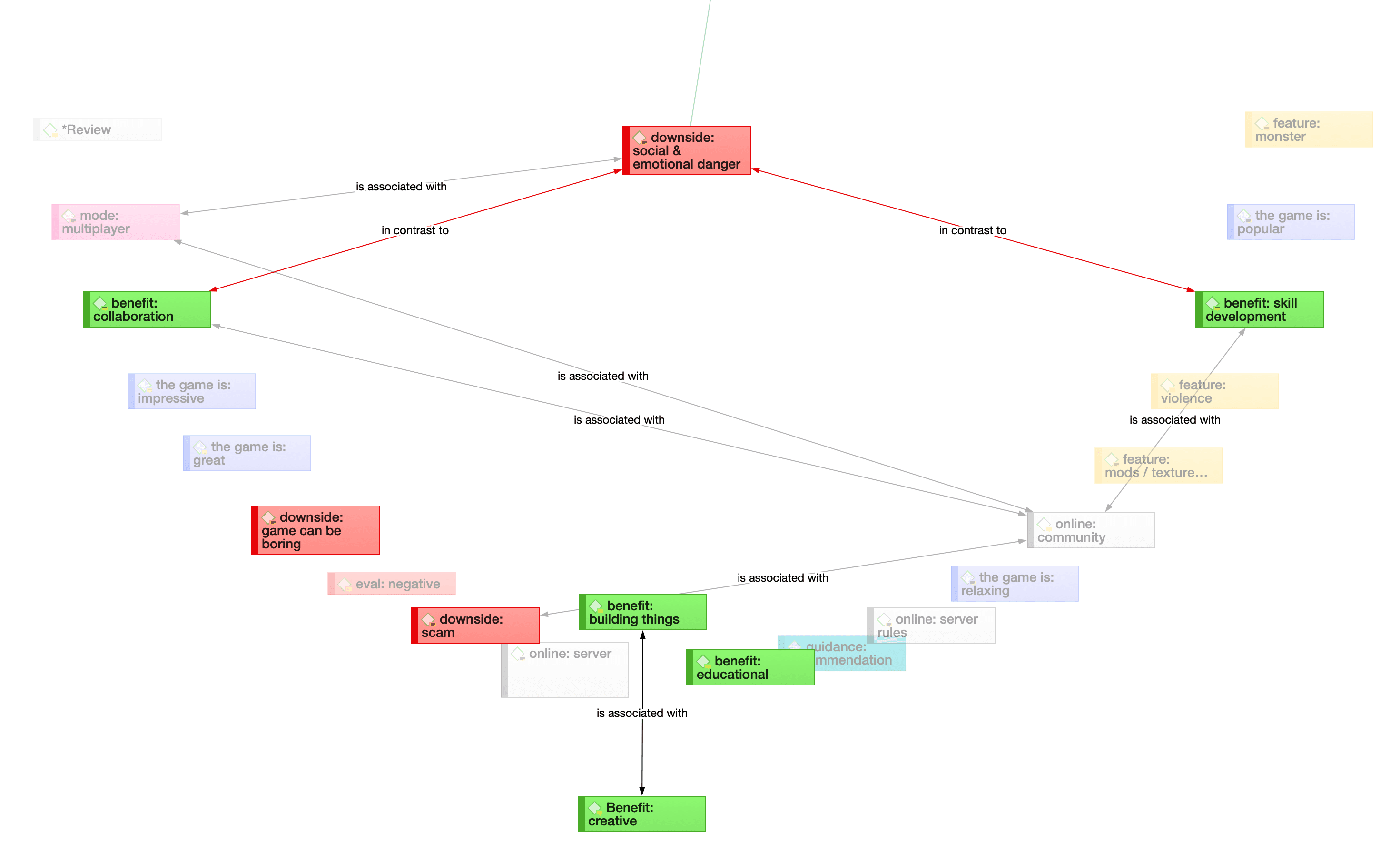
Exportar redes
Las redes pueden imprimirse o guardarse como archivo PDF.
Abra la red.
En el menú principal, seleccione Proyecto > Imprimir. Haga clic en Mostrar detalles para cambiar la orientación y otras opciones. Seleccione la opción de imprimir o de PDF.
Editor de redes - Opciones adicionales
Cambiar el color de un código
Seleccione un nodo de código. En la cinta principal de la red, haga clic en la flecha desplegable debajo de la paleta de colores y seleccione un color.
Fusionar códigos

Seleccione todos los nodos de código que deben fusionarse con otro código. Si selecciona varios nodos de código, mantenga presionada la tecla Ctrl.
Seleccione la pestaña Nodos y haga clic en el botón Fusionar. Mueva el puntero del ratón al nodo con el que desea fusionar los códigos seleccionados. Verá un marco verde claro alrededor de este nodo. Al hacer clic izquierdo sobre el nodo, todos los demás nodos de código seleccionados se fusionarán.
Duplicar códigos
Un código duplicado es un clon exacto del código original, incluyendo color, comentario, vínculos código-cita, vínculos código-memo y vínculos código-código. Duplicar un código puede ser una opción útil para limpiar o modificar un sistema de códigos.
Seleccione uno o más códigos en una red, seleccione la pestaña Nodos y desde allí la opción Duplicar código(s). Los códigos duplicados tienen el mismo nombre más un número consecutivo, es decir, (2).
Crear grupos
También es posible crear grupos en las redes. Como en cualquier otra parte del software, un grupo está compuesto por entidades del mismo tipo. Por lo tanto, se puede crear un grupo de documentos basado en nodos de documentos, un grupo de códigos basado en nodos de códigos, un grupo de memos basado en nodos de memos y un grupo de redes basado en nodos de redes. No es posible crear un grupo que contenga tipos de entidades diferentes.
Seleccione uno o más nodos del mismo tipo de entidad y haga clic en la opción Nuevo grupo en la pestaña Nodos.
Ingrese un nombre para el grupo y haga clic en Crear. El grupo se agregará a la red y se mostrarán los vínculos con sus miembros.
Recorrer hipervínculos en redes
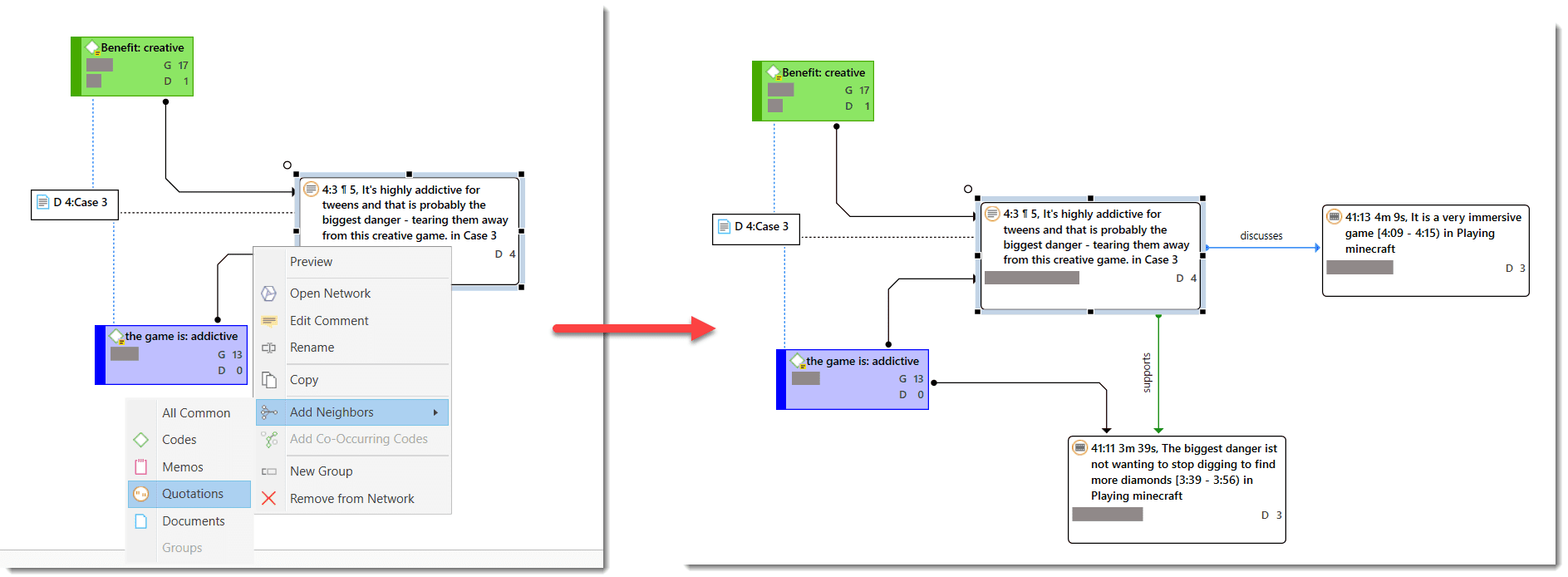
Para expandir los hipervínculos visibles en una red, o para ver qué otras entidades están vinculadas a una cita con hipervínculo, puede importar sus vecinos:
Haga clic derecho sobre un hipervínculo y seleccione Importar vecinos > Citas.
Trabajo en equipo
El tipo de trabajo en equipo que se admite es la codificación y el análisis compartidos de forma asincrónica. Esto significa que si tiene una gran cantidad de datos, puede distribuir el trabajo de codificación entre los diferentes miembros del equipo. Cada miembro codifica partes de los datos, y el trabajo de todos los codificadores se integra mediante la fusión de los distintos subproyectos.
Cada miembro del equipo debe trabajar en su propia copia del proyecto. La ubicación donde se almacenan los datos del proyecto para cada usuario puede seleccionarse. Sin embargo, siempre es un espacio personal, no compartido. Consulte Trabajar con bibliotecas de ATLAS.ti.
Al trabajar en un proyecto de equipo, los miembros del equipo no deben editar los documentos (a menos que cada uno trabaje en documentos diferentes). Si los miembros del equipo editan los mismos documentos, estos no podrán fusionarse; en cambio, serán duplicados. Si es necesario editar documentos, esto debe hacerlo el administrador del proyecto en el proyecto maestro.
Flujo de trabajo
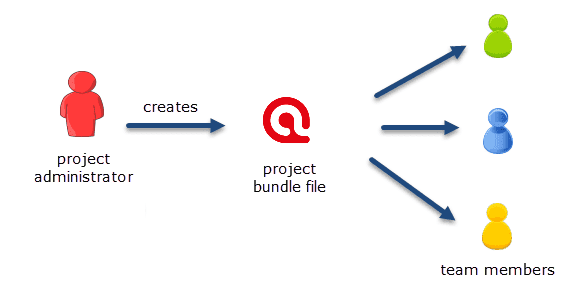
-
El administrador del proyecto configura un proyecto maestro. Consulte Crear un nuevo proyecto.
-
El administrador del proyecto agrega documentos al proyecto y posiblemente una lista de códigos.
-
El administrador del proyecto guarda el proyecto y lo exporta. Esto significa crear un archivo de paquete de proyecto
-
Todos los miembros del equipo importan el archivo de paquete de proyecto y comienzan su trabajo.
-
Para combinar el trabajo de todos los miembros del equipo, cada miembro crea un archivo de paquete de proyecto y se lo envía al administrador del proyecto.
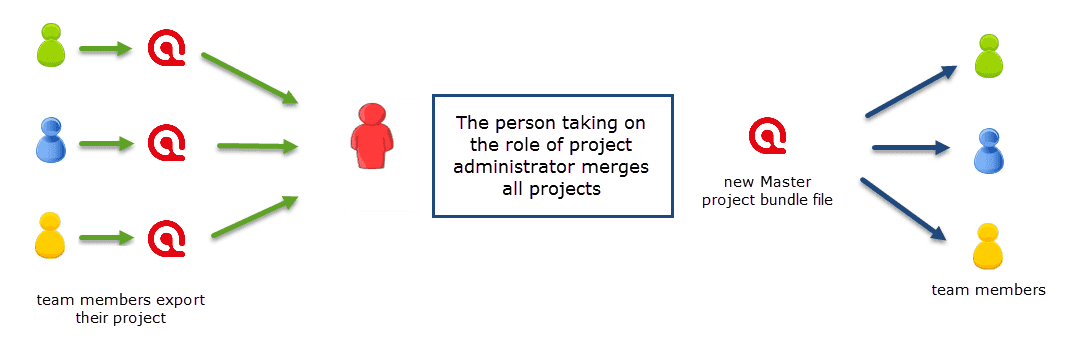
-
El administrador del proyecto fusiona todos los subproyectos y crea un nuevo archivo maestro.
-
El administrador del proyecto exporta el nuevo archivo maestro y lo distribuye a todos los miembros del equipo. Consulte Transferir proyectos.
-
Los miembros del equipo continúan con su trabajo.
Este ciclo continúa. Si es necesario agregar nuevos documentos al proyecto, esto debe hacerlo el administrador del proyecto. Un buen momento para hacerlo es después de fusionar y antes de crear el nuevo archivo maestro.
Aquí encontrará instrucciones paso a paso:
Aspectos importantes a tener en cuenta
-
Si todos los miembros del equipo deben trabajar en los mismos documentos, es fundamental que solo el administrador del proyecto configure el proyecto agregando todos los documentos. De lo contrario, los documentos se duplicarán o multiplicarán durante el proceso de fusión. Consulte Agregar documentos.
-
Los miembros del equipo no deben editar los documentos. Si lo hacen, los documentos editados no podrán fusionarse y se obtendrán duplicados. Si es necesario editar documentos, esto debe hacerlo el administrador del proyecto en el proyecto maestro.
-
La ubicación donde ATLAS.ti almacena los datos relacionados con el proyecto puede ser determinada por cada usuario. Consulte Trabajar con bibliotecas de ATLAS.ti.
-
Las bibliotecas de documentos NO pueden compartirse. Cada persona siempre trabaja con su propia copia del conjunto de datos dentro de su propio entorno de ATLAS.ti.
Nuestro equipo de soporte rechazará cualquier solicitud de reparación causada por intentos de compartir bibliotecas.
Cuentas de usuario
ATLAS.ti crea automáticamente una cuenta de usuario basada en el nombre que utiliza en su computadora.
Para verificar quién ha iniciado sesión actualmente:
Desde el menú principal, seleccione Proyecto > Administración de usuarios > Mostrar administrador de usuarios.
Crear una nueva cuenta de usuario
Un motivo para crear una nueva cuenta de usuario es, por ejemplo, si dos personas de un equipo tienen el mismo nombre, o si desea utilizar un nombre diferente al asignado automáticamente.
En el Administrador de usuarios, haga clic en el botón más (+) e ingrese un nombre de usuario. Puede establecer una contraseña, pero no es obligatorio. Haga clic en Aceptar para guardar el nuevo usuario.
Fusionar usuarios
Si ha trabajado en diferentes computadoras y utiliza nombres de usuario distintos, podrían existir dos o más nombres de usuario que hagan referencia a la misma persona. Puede fusionarlos fácilmente en el Administrador de usuarios arrastrando la cuenta de usuario que no desea conservar sobre la cuenta de usuario que desea conservar.
Cuentas de usuario
Desde el menú principal, seleccione Proyecto > Administración de usuarios > Cambiar usuario. Abra el menú desplegable junto al nombre de usuario y seleccione un usuario diferente. Haga clic en Aceptar.
Al fusionar proyectos provenientes de diferentes computadoras que utilizan el mismo nombre de usuario, el nombre de usuario se duplicará, p. ej., Tom y Tom (2). Esto significa que aún puede distinguir a los dos usuarios. Sin embargo, puede resultar algo incómodo tener que recordar siempre quién es quién.
Configurar un proyecto de equipo
Cuando trabaja en equipo con documentos y códigos compartidos, debe comenzar con un proyecto MAESTRO que contenga todos los documentos y códigos que desea compartir con su equipo. Consulte Flujo de trabajo. Si todos los miembros del equipo comienzan de forma independiente, se obtendrán documentos y códigos duplicados al fusionar los proyectos.
Las instrucciones están organizadas por las distintas tareas que implica trabajar en equipo. A continuación encontrará instrucciones operativas para el administrador del proyecto. Para las instrucciones de los miembros del equipo, consulte Tareas para los miembros del equipo.
Tareas del administrador del proyecto
Crear y distribuir el proyecto
Si abre ATLAS.ti, seleccione el botón Nuevo proyecto en la pantalla de bienvenida.
Alternativamente:
Si ya hay un proyecto abierto, seleccione Proyecto > Nuevo desde el menú principal.
Ingrese un nombre de proyecto y haga clic en Crear.
A continuación, agregue todo lo que debe ser compartido por el equipo:
-
agregue documentos. Consulte Agregar documentos a un proyecto.
-
cree grupos de documentos. Consulte Trabajar con grupos.
-
agregue códigos y grupos de códigos. Puede preparar una lista de códigos que incluya descripciones de códigos, grupos de códigos y colores en Excel e importar el archivo de Excel. Consulte Importar una lista de códigos.
Si se va a utilizar un conjunto común de códigos y grupos de códigos, deben agregarse al proyecto en esta etapa. Si cada miembro del equipo agregara de forma individual códigos y grupos de códigos a cada subproyecto, todos los códigos y grupos se multiplicarán durante la fusión.
Para guardar un proyecto, haga clic en el ícono Guardar en la barra de herramientas de acceso rápido, o seleccione Archivo > Guardar (atajo: cmd+S).
Para exportar el proyecto y distribuirlo a todos los miembros del equipo, seleccione Proyecto > Exportar > Proyecto. Consulte también Transferir proyecto.
Distribuya el archivo de paquete de proyecto a todos los miembros del equipo: por ejemplo, por correo electrónico, en una carpeta de un servidor al que todos puedan acceder, o también mediante un enlace o carpeta en la nube.
El archivo de paquete de proyecto muestra el ícono de ATLAS.ti, tiene la extensión de archivo .atlproj y puede ser leído tanto por ATLAS.ti para Windows como por ATLAS.ti para Mac.
El nombre predeterminado del paquete es el nombre del proyecto. Se recomienda agregar la fecha al nombre del archivo de paquete de proyecto, para que siempre sepa cuándo fue creado. Si sube el archivo en algún lugar o lo envía por correo electrónico, la fecha de descarga del archivo será diferente a la fecha de creación.
Sin embargo, cambiar el nombre del archivo de paquete no modifica el nombre del proyecto contenido en el paquete. Piense en el archivo de paquete de proyecto como una caja que contiene su proyecto de ATLAS.ti más todos los documentos que desea analizar. Colocar una etiqueta diferente en el exterior de la caja no cambiará el nombre del archivo de proyecto que está contenido dentro de la caja.
Solicite a cada miembro del equipo que cambie el nombre del archivo de proyecto al importar el paquete de proyecto, es decir, que agregue su nombre o iniciales al nombre del proyecto, para que los proyectos de los distintos miembros del equipo puedan identificarse fácilmente.
Los archivos de paquete de proyecto pueden compartirse a través de servicios en la nube como Dropbox, OneDrive, GoogleDrive, etc. Otra opción es subir el archivo de paquete de proyecto a un servidor de su elección y enviar un enlace a todos los miembros del equipo para que puedan descargar el archivo.
Proyecto de equipo: tareas para los miembros del equipo
Como miembro del equipo, no debe editar los documentos en un proyecto de equipo. Si lo hace, el documento no podrá fusionarse más adelante; en cambio, será duplicado. Si es necesario modificar texto, esto debe hacerse en el proyecto maestro por el administrador del proyecto.
ATLAS.ti crea automáticamente una cuenta de usuario basada en su inicio de sesión en la computadora cuando inicia ATLAS.ti.
Verifique su nombre de usuario antes de comenzar a trabajar. ¿Es este el nombre que desea utilizar en el proyecto de equipo? Si no es así, modifique el nombre o cree una nueva cuenta de usuario e inicie sesión con la nueva cuenta. Consulte Cuentas de usuario.
Como miembro del equipo, recibe un paquete de proyecto del administrador del proyecto.
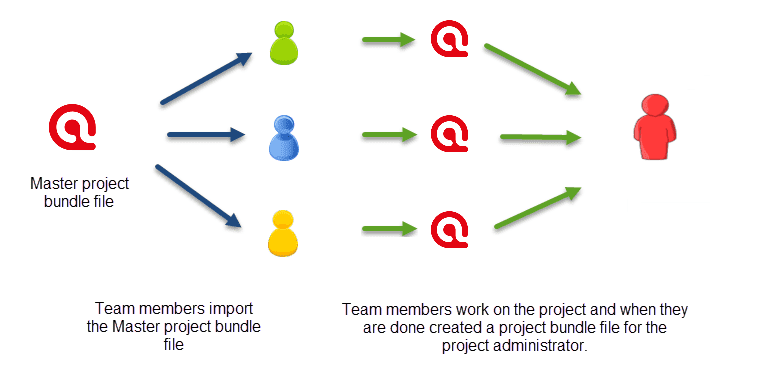
Guarde el archivo de paquete de proyecto en su computadora o en su espacio personal en un servidor.
Abra ATLAS.ti y seleccione el botón Importar proyecto. Si hay otro proyecto abierto actualmente, seleccione Proyecto > Importar proyecto desde el menú principal.
Cambie el nombre del proyecto agregando su nombre o iniciales al nombre del proyecto. Esto es importante para el administrador del proyecto cuando fusione los proyectos de todos los miembros del equipo. Si olvida este paso, consulte a continuación cómo puede cambiar el nombre de un proyecto después de haberlo importado.
Si esta es la segunda o tercera vez que importa el proyecto maestro, el nombre del proyecto con el nombre/iniciales del codificador ya existe. ATLAS.ti lo reconocerá y ofrecerá las siguientes dos opciones:
- Conservar el proyecto actual como instantánea.
- Sobrescribir el proyecto existente.
Como ya exportó su proyecto para enviárselo al administrador del proyecto, ya tiene una copia de seguridad de su proyecto. Por lo tanto, en la mayoría de los casos será correcto sobrescribir el proyecto existente.
Seleccione la opción adecuada y haga clic en Importar.
Después de haber realizado algún trabajo en el proyecto, debe enviárselo al administrador del proyecto para su fusión. Esto es lo que debe hacer:
Seleccione Proyecto > Exportar > Proyecto. Consulte Transferir proyecto.
Continúe el ciclo de intercambio y fusión de proyectos entre el administrador del proyecto y los miembros del equipo según sea necesario.
Cambiar el nombre de los proyectos después de importar
Si olvidó cambiar el nombre del proyecto al importarlo, puede modificarlo después de haberlo importado:
Desde el menú principal, seleccione Proyecto > Cambiar nombre del proyecto.
Fusionar proyectos
El proyecto maestro es el proyecto en el que se fusiona otro proyecto, denominado proyecto de importación. El proyecto maestro debe cargarse primero antes de invocar la opción Fusionar proyecto.
La opción predeterminada es unificar todas las entidades que son idénticas y agregar todos los demás elementos que aún no existen en el proyecto maestro.
Solo puede fusionar proyectos de ATLAS.ti para escritorio y ATLAS.ti Web si los proyectos contienen documentos y códigos diferentes. Al fusionar entidades, deben tener el mismo ID, lo cual solo se da si se parte de un proyecto maestro común. Dado que actualmente no es posible importar un proyecto de escritorio en la versión Web, no puede compartir un proyecto maestro con una persona que use la versión Web. Por lo tanto, incluso si agrega los mismos documentos y códigos a los proyectos de escritorio y Web, los ID de todas las entidades serán diferentes. Al fusionar estos proyectos, todas las entidades se duplicarán porque tienen IDs diferentes en lugar de fusionarse. Los códigos pueden fusionarse manualmente por el usuario, pero no es posible fusionar documentos manualmente.
Explicación de las entidades idénticas
Cuando se crea una entidad en ATLAS.ti — ya sea un documento, un código, una cita, un memo, una red, un grupo o un comentario — dicha entidad recibe un ID único, comparable a una huella dactilar.
Al fusionar proyectos, ATLAS.ti compara los IDs de las distintas entidades. Si tienen el mismo ID, se unifican. Si el ID no es el mismo, se agregan. Por lo tanto, el nombre de una entidad no es el factor determinante.
Por ejemplo: si el usuario Tom ha creado un código con el nombre sunshine, y la usuaria Anne también ha creado un código con el mismo nombre sunshine en su proyecto, estos dos códigos no son idénticos ya que fueron creados en diferentes computadoras y en diferentes proyectos. Por lo tanto, tendrán un ID diferente.
Si fusiona el proyecto de Tom y el de Anne, el proyecto fusionado contendrá dos códigos: sunshine y sunshine (2). Si el significado de ambos códigos es el mismo y desea conservar solo un código sunshine, puede fusionar los dos códigos manualmente. Consulte también Mantenimiento a continuación.
Los grupos son aditivos
Un Grupo B con documentos {1, 2, 3} en el proyecto maestro fusionado con un Grupo B que contiene documentos {3, 4} en el proyecto de importación dará como resultado Grupo B = {1, 2, 3, 4} en el proyecto fusionado.
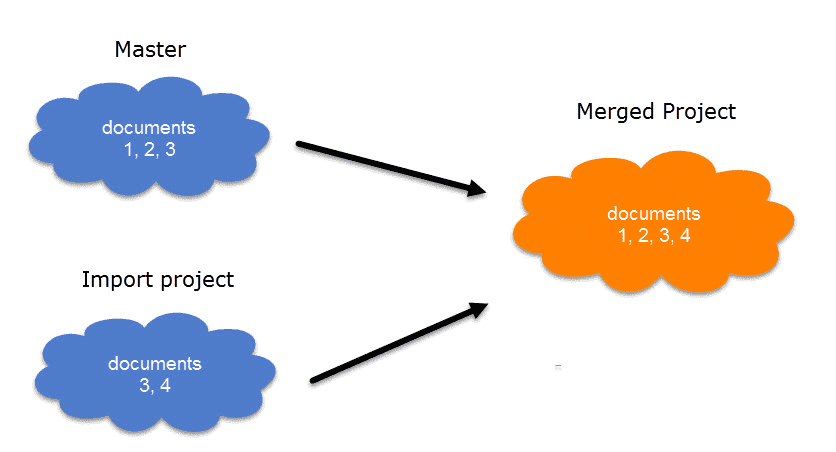
Entidades con y sin comentarios
Si hay un código C en el proyecto maestro que no tiene comentario, y un código C en el proyecto de importación que sí tiene comentario, el procedimiento de fusión agregará este comentario al proyecto fusionado.
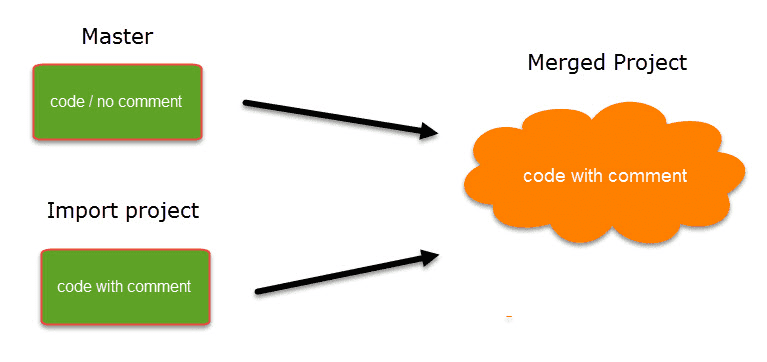
En caso de un conflicto irresoluble — el código C en el proyecto maestro tiene un comentario y el código C en el proyecto de importación también tiene un comentario — el usuario puede definir cuál de las dos entidades en conflicto prevalecerá.
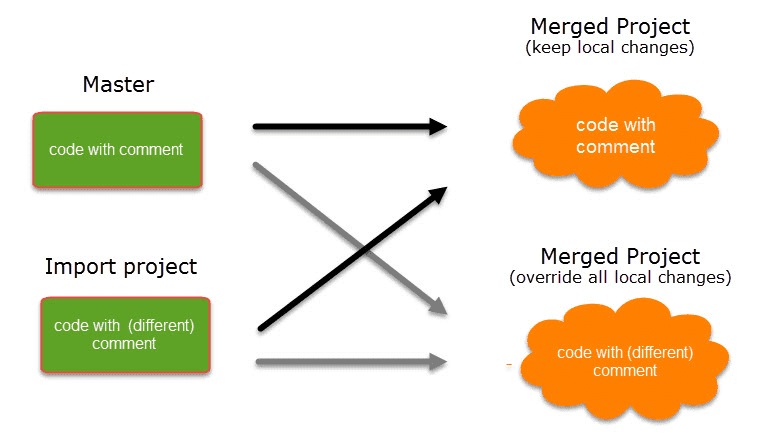
Si debe conservarse el comentario del proyecto maestro, seleccione la opción Conservar. Si debe conservarse el comentario del proyecto de importación, seleccione la opción Reemplazar.
Actualmente solo puede decidir, para todos los conflictos, si el proyecto maestro debe "ganar" o el proyecto de importación.
Manejo de entidades eliminadas
No es posible "restar" entidades.
Si un miembro del equipo ha eliminado un código o algunas codificaciones, y estas entidades aún existen en otro proyecto, el proyecto fusionado volverá a contener esos códigos o codificaciones.
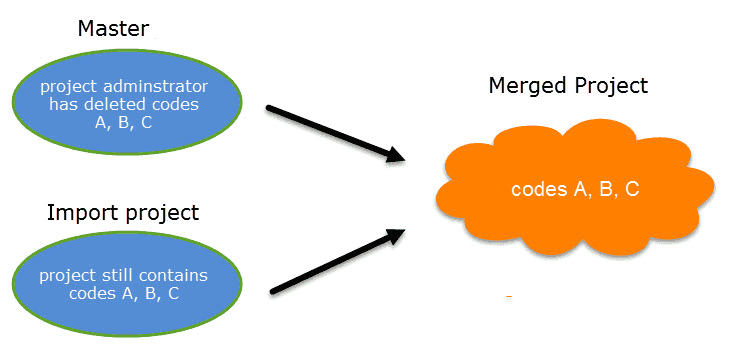
Si desea limpiar un proyecto, lo mejor es hacerlo en un proyecto maestro nuevo después de fusionar y antes de distribuir el nuevo archivo maestro a todos los miembros del equipo.
Cómo fusionar
La herramienta de fusión reúne proyectos que originalmente fueron divididos por razones analíticas o económicas. Integra las contribuciones de los diferentes miembros de un equipo de investigación.
Antes de fusionar, se recomienda importar primero todos los archivos de paquete de proyecto y revisar los proyectos. Si surge un conflicto durante el proceso de fusión, deberá decidir si conservar la versión del proyecto maestro o del proyecto de importación. Si no sabe qué contiene el proyecto de importación, no podrá tomar una decisión informada. En principio, es posible fusionar archivos de paquete de proyecto sin importarlos previamente.
En ATLAS.ti para Mac, siempre se fusiona un archivo de paquete de proyecto.
Para iniciar el proceso de fusión:
Abra el proyecto maestro.
Seleccione Proyecto > Fusionar con proyecto. Seleccione un archivo de paquete de proyecto y haga clic en Abrir. El proceso de fusión comienza.
ATLAS.ti verifica los dos proyectos en busca de elementos idénticos y diferentes. Una vez completado este proceso, verá un resumen.
Si hay conflictos entre el proyecto maestro y el proyecto que está importando, puede resolver el conflicto de dos maneras:
-
Conservar versión actual: el proyecto maestro "gana" y los cambios realizados en el proyecto de importación se ignoran.
-
Sobrescribir: la versión del proyecto maestro será sobrescrita y los cambios realizados en el proyecto de importación "ganan".
Si todos los miembros del equipo han codificado documentos diferentes, es poco probable que se produzcan conflictos de fusión.
Un conflicto podría surgir, por ejemplo, si alguien ha modificado un documento o un grupo de códigos, o ha modificado un comentario. Como administrador del proyecto, deberá decidir si acepta o no estos cambios.
Actualmente no puede elegir para cada conflicto cómo resolverlo. Todos los conflictos deben resolverse seleccionando la estrategia "conservar versión actual" o la estrategia "sobrescribir".
Después de fusionar, verifique el informe final de fusión y el proyecto fusionado para comprobar su coherencia. Si está satisfecho con los resultados, guarde el proyecto. Si no, siempre puede seleccionar Deshacer.
Si corresponde, continúe con la fusión del siguiente subproyecto o archivo de paquete de proyecto.
Un error común es que los miembros del equipo configuren sus propios proyectos, agregando documentos y códigos. Esto resultará en documentos y códigos duplicados después de la fusión. Los problemas derivados de códigos duplicados puede resolverlos usted mismo fusionando esos códigos (consulte Mantenimiento a continuación). Sin embargo, no puede fusionar documentos duplicados. Siga el flujo de trabajo recomendado descrito en Trabajo en equipo.
Mantenimiento
Después de fusionar todos los proyectos, el administrador del proyecto puede necesitar realizar algunas tareas de mantenimiento, como:
- limpiar la lista de códigos
- agregar o modificar grupos de códigos
- agregar un memo con información para el equipo
- agregar nuevos documentos y grupos de documentos
Fusionar códigos duplicados
Es necesario realizar tareas de mantenimiento si se encuentran códigos duplicados en el proyecto fusionado. Esto puede ocurrir, por ejemplo, si los miembros del equipo han agregado de forma independiente códigos con el mismo nombre. Como estos códigos se crearon en proyectos diferentes, tienen IDs distintos y, por lo tanto, se agregan en lugar de fusionarse. La convención de nomenclatura para los códigos duplicados es la siguiente:
- código A
- código A (2)
Los códigos duplicados se pueden fusionar de la siguiente manera:
Abra el Administrador de códigos. Seleccione el o los códigos que desea fusionar y arrástrelos al código que desea conservar. Seleccione Fusionar código... en... del menú que aparece.
Acuerdo intercodificadores (ICA)
Es posible probar el acuerdo intercodificadores en documentos de texto, audio y vídeo. Los documentos de imagen no son compatibles. Esto también se aplica a las citas de imagen en documentos PDF de texto.
Como es necesario partir de un proyecto maestro común al configurar un proyecto para el análisis ICA, no es posible comprobar el acuerdo intercodificadores si uno de los codificadores utiliza la versión web. Todos los codificadores deben usar la versión de escritorio (Mac o Windows). Para una explicación más detallada, consulte Fusión de proyectos.
Por qué es importante
El propósito de recopilar y analizar datos es que los investigadores encuentren respuestas a las preguntas de investigación que motivaron el estudio en primer lugar. Por lo tanto, los datos son el fundamento confiable de cualquier razonamiento y discusión de los resultados. Por ello, los investigadores deben tener la certeza de que sus datos han sido generados tomando precauciones contra distorsiones y sesgos, intencionales o accidentales, y de que significan lo mismo para cualquier persona que los utilice. La fiabilidad fundamenta esta confianza empíricamente (Krippendorff, 2004).
Richards (2009) escribió: "Pero ser fiable (para usar el adjetivo) supera ser poco fiable. Si una categoría se usa de distintas maneras, no se podrá confiar en ella para obtener todos los datos relevantes. Por lo tanto, puede que se desee asegurarse de que uno mismo interpreta un código de la misma manera a lo largo del tiempo, o que se puede confiar en que los colegas lo utilizan del mismo modo" (p. 108).
Existen dos maneras de racionalizar la fiabilidad: una se basa en la teoría de la medición, que es menos relevante para el tipo de datos que utilizan los usuarios de ATLAS.ti. La segunda es una concepción interpretativista de la fiabilidad. Al recopilar cualquier tipo de datos de entrevistas u observaciones, los fenómenos de interés suelen desaparecer justo después de haber sido registrados u observados. Por lo tanto, la capacidad del analista para examinar los fenómenos depende en gran medida de una lectura y uso consensuados de los datos que representan los fenómenos de interés. Los investigadores deben presumir que sus datos pueden considerarse con el mismo significado por todos quienes los utilizan.
Esto significa "que la lectura de los datos textuales, así como de los resultados de la investigación, es replicable en otros contextos, que los investigadores demuestran claramente estar hablando de lo mismo. Aquí, entonces, la fiabilidad es el grado en que los miembros de una comunidad designada coinciden en las lecturas, interpretaciones, respuestas o usos de textos o datos determinados. [...] Los investigadores necesitan demostrar la confiabilidad de sus datos midiendo su fiabilidad" (Krippendorff, 2004, p. 212).
Probar la fiabilidad de los datos es un primer paso. Solo después de establecer que la fiabilidad es suficientemente elevada tiene sentido proceder con el análisis de los datos. Si existe una duda considerable sobre el significado de los datos, será difícil justificar el análisis posterior y sus resultados.
La herramienta de acuerdo intercodificadores de ATLAS.ti permite evaluar el grado de acuerdo entre múltiples codificadores al codificar un conjunto de datos determinado. En el desarrollo de la herramienta trabajamos estrechamente con el Prof. Klaus Krippendorff, uno de los principales expertos en este campo, autor del libro Content Analysis: An Introduction of Its Methodology y creador del coeficiente alpha de Krippendorff para medir el acuerdo intercodificadores.
La necesidad de una herramienta de este tipo como elemento integrado en ATLAS.ti ha sido evidente durante mucho tiempo y ha sido solicitada con frecuencia por los usuarios. Sin embargo, por su naturaleza, no puede ni podría ser una solución mágica del tipo "haz clic en un botón y espera lo mejor". Si se hace clic aleatoriamente en cualquiera de las opciones que ofrece ATLAS.ti para calcular un coeficiente de acuerdo intercodificadores, ATLAS.ti calculará algo. Que el número obtenido sea significativo y útil depende de cómo se haya configurado el proyecto y la codificación.
Esto significa que, si se desea probar el acuerdo intercodificadores, se requiere al menos una disposición mínima a explorar los fundamentos teóricos básicos de qué es el acuerdo intercodificadores, qué hace y puede hacer, y qué no puede hacer. En este manual se ofrecen algunos conceptos básicos, pero esto no puede sustituir a la lectura de la literatura y a la comprensión de los supuestos y requisitos subyacentes para ejecutar un análisis de acuerdo intercodificadores.
Téngase en cuenta que la herramienta de acuerdo intercodificadores cruza la divisoria entre lo cualitativo y lo cuantitativo. El establecimiento del acuerdo intercodificadores tiene su origen en el análisis de contenido cuantitativo (véase, por ejemplo, Krippendorff, 2018; Schreier, 2012). Si se desea aplicarlo y cumplir con los estándares científicos, es necesario seguir algunas reglas que son mucho más estrictas que las de la codificación cualitativa.
Si se desea desarrollar un sistema de códigos en equipo, sí es posible comenzar a codificar de forma independiente y luego ver los resultados. Pero este enfoque solo puede ser, en el mejor de los casos, una lluvia de ideas inicial. No puede utilizarse para probar el acuerdo intercodificadores.
Un buen momento para comprobar el acuerdo intercodificadores es cuando el investigador principal ha construido un sistema de códigos estable y todos los códigos están definidos. Entonces dos o más codificadores adicionales, independientes de la persona que desarrolló el sistema de códigos, codifican un subconjunto de los datos. Esto significa que se está en algún punto intermedio del proceso de codificación. Una vez alcanzado un coeficiente ICA satisfactorio, el investigador principal tiene la certeza de que sus códigos pueden ser comprendidos y aplicados por otras personas, y puede continuar trabajando con el sistema de códigos.
Literatura
Guba, Egon G. and Lincoln, Yvonna S. (2005). Competing paradigms in qualitative research, in Denzin, N. and Lincoln, Y.S. (eds) The Sage Handbook of Qualitative Research, 191–225. London: Sage.
Harris, Judith, Pryor, Jeffry and Adams, Sharon (2006). The Challenge of Intercoder Agreement in Qualitative Inquiry. Working paper.
Krippendorff, Klaus (2018). Content Analysis: An Introduction to Its Methodology. 4th edition. Thousand Oaks, CA: Sage.
MacPhail, Catherine, Khoza, Nomhle, Abler, Laurie and Ranganathan, Meghna (2015). Process guidelines for establishing Intercoder Reliability in qualitative studies. Qualitative Research, 16 (2), 198-212.
Rolfe, Gary (2006). Validity, trustworthiness and rigour: quality and the idea of qualitative research. Methodological Issues in Nursing Research, 304-310.
Richards, Lyn (2009). Handling Qualitative Data: A Practical Guide, 2nd edn. London: Sage.
Schreier, Margrit (2012). Qualitative Content Analysis in Practice. London: Sage.
ICA - Requisitos para la codificación
Si aún no está familiarizado con el proceso de codificación en ATLAS.ti, consulte Codificación de datos
Las fuentes de datos poco fiables son las inconsistencias intracodificador y los desacuerdos intercodificadores.
Para detectarlas, el proceso de codificación debe poder replicarse. La replicabilidad puede garantizarse cuando varios codificadores que trabajan de forma independiente (al menos dos) coinciden:
- en el uso de las instrucciones de codificación escritas
- en la selección de los mismos segmentos textuales a los que se aplican las instrucciones de codificación
- en la codificación de esos segmentos con los mismos códigos, o en la identificación de los mismos dominios semánticos que los describen y la codificación con los mismos códigos para cada dominio semántico.
Dominios semánticos
Un dominio semántico se define como un conjunto de conceptos distintos que comparten significados comunes. También pueden entenderse como una categoría con subcódigos.
Ejemplos de dominios semánticos:
EMOCIONES
- emociones: alegría
- emociones: entusiasmo
- emociones: sorpresa
- emociones: tristeza
- emociones: ira
- emociones: miedo
ESTRATEGIAS
- estrategias: aceptar que son naturales
- estrategias: tener un plan B
- estrategias: ajustar las expectativas
- estrategias: tomárselo con humor
- estrategias: pedir ayuda
ACTOR
- actor: pareja
- actor: madre
- actor: padre
- actor: hijo/a
- actor: hermano/a
- actor: vecino/a
- actor: colega
Cada dominio semántico abarca conceptos mutuamente excluyentes indicados por un código. Si codifica un segmento de datos con "emociones: sorpresa", no puede codificarlo también con "emociones: miedo". Si ambos se mencionan en una misma zona, es necesario crear dos citas y codificarlas por separado. Sin embargo, es posible aplicar códigos de distintos dominios semánticos a una misma cita. Consulte codificación multivaluada más adelante.

Los dominios semánticos dependen del contexto
En ocasiones, el nombre del dominio puede dejar claro cuál es el contexto. El subcódigo "apoyarse mutuamente" del ejemplo anterior pertenece al contexto "beneficios de la amistad" y no hace referencia al apoyo entre compañeros de trabajo. Si el contexto sigue siendo poco claro y puede interpretarse de distintas maneras, es necesario aclararlo en la definición del código.
Los dominios semánticos deben ser conceptualmente independientes
La independencia conceptual significa:
- un subcódigo de un dominio solo es específico de ese dominio y no aparece en ningún otro dominio.
- por lo tanto, cada código aparece una sola vez en el sistema de códigos.
Esta es también una regla que debe aplicarse de manera general al construir un sistema de códigos. Consulte Desarrollo de un sistema de códigos.
Por lo tanto, como los dominios semánticos son lógica o conceptualmente independientes entre sí, es posible aplicar códigos de distintos dominios semánticos a las mismas citas o a citas superpuestas. Por ejemplo, en una sección de los datos puede encontrarse algo sobre los beneficios de la amistad y algunos aspectos emocionales que se mencionan. Como estos códigos provienen de dominios semánticos distintos (BENEFICIOS y EMOCIONES), ambos pueden aplicarse.
Dominios semánticos
Los dominios semánticos pueden desarrollarse de manera deductiva o inductiva. En la mayoría de los estudios que aplican un enfoque de análisis cualitativo de datos, el desarrollo probablemente sea inductivo. Esto significa que los códigos se desarrollan mientras se leen los datos paso a paso. Por ejemplo, en un estudio de entrevistas sobre la amistad, se pueden haber codificado algunos segmentos de datos como "cuidarse mutuamente", "apoyarse mutuamente" y "mejorar la salud y la longevidad". Luego se observa que estos códigos pueden resumirse en un nivel superior como "BENEFICIOS DE LA AMISTAD". Se establece entonces un dominio semántico BENEFICIOS con los subcódigos:
- beneficios: cuidarse mutuamente
- beneficios: apoyarse mutuamente
- beneficios: mejorar la salud y la longevidad
Se continúa codificando y se encuentran otros segmentos que se codifican como "aprender el uno del otro". Como esto también encaja en el dominio BENEFICIOS, se añade al dominio con el nombre:
- beneficios: aprender el uno del otro
Y así sucesivamente. De esta manera se pueden construir dominios semánticos paso a paso de forma inductiva mientras se desarrolla el sistema de códigos.
Una vez que el sistema de códigos está listo y las definiciones de los códigos están escritas en los campos de comentarios, se puede preparar el proyecto para la prueba de acuerdo intercodificadores. En este punto ya no es posible ampliar un dominio semántico. Consulte Configuración del proyecto.
Al desarrollar un sistema de códigos, el objetivo es cubrir la variabilidad de los datos de modo que no quede sin incluir ningún aspecto relevante para la pregunta de investigación. Esto se denomina exhaustividad. A nivel de dominio, esto significa que todos los temas principales están cubiertos. A nivel de subcódigo, esto significa que los códigos de un dominio semántico cubren todos los aspectos del dominio y los datos pueden clasificarse en los códigos disponibles sin forzarlos. Una solución práctica es incluir un código "misceláneos" en cada dominio en el que los codificadores puedan incluir todos los datos que no encajen en ningún otro lugar. Sin embargo, hay que tener en cuenta que estos códigos de tipo "cajón de sastre" aportarán poco para responder a las preguntas de investigación.
Reglas para aplicar códigos
- Los códigos de un dominio deben aplicarse de manera mutuamente excluyente.
- Los códigos de múltiples dominios semánticos pueden aplicarse a los mismos segmentos de datos o a segmentos superpuestos.
Exclusividad mutua: Solo se puede aplicar uno de los subcódigos de un dominio semántico a una cita o a citas superpuestas. El uso del mismo color para todos los códigos de un dominio semántico ayudará a detectar posibles errores.
Si se detecta que una cita ha sido codificada con dos códigos del mismo dominio semántico, se puede corregir dividiendo la cita. Esto implica cambiar la longitud de la cita original y crear una nueva cita, de modo que sea posible aplicar los dos códigos a dos citas distintas.

Si los códigos de un dominio semántico no se aplican de manera mutuamente excluyente, el coeficiente ICA queda inflado y, en la implementación actual de la herramienta, no puede calcularse.
Codificación multivaluada: Esto significa que se pueden aplicar múltiples códigos de distintos dominios semánticos a la misma cita. Por ejemplo, si un entrevistado habla de ira al tratar con su madre y menciona que tuvo que ajustar sus expectativas, esto puede codificarse con códigos de los tres dominios semánticos EMOCIONES, ACTOR y ESTRATEGIAS.
O como se muestra en el ejemplo a continuación: CONSECUENCIA, PERSONAS INVOLUCRADAS y EVENTO RECIENTE.

La codificación con códigos de múltiples dominios semánticos permite analizar cómo se relacionan los distintos dominios semánticos en otros análisis además del acuerdo intercodificadores. Por ejemplo, qué tipo de emociones se mencionan en relación con qué actor y qué estrategias se utilizan para manejarlas. Para ello se pueden utilizar las herramientas de coocurrencia de códigos. Consulte Herramientas de coocurrencia de códigos.
Instrucciones para los codificadores
Un requisito fundamental para el análisis de acuerdo intercodificadores es la independencia de los codificadores. Por lo tanto, la persona que ha desarrollado el sistema de códigos no puede ser uno de los codificadores cuya codificación entre en el análisis ICA. Además del investigador principal que desarrolla el sistema de códigos, se necesitan dos o más personas que apliquen los códigos.
Los codificadores recibirán un paquete de proyecto del investigador principal (consulte Configuración del proyecto). Se recomienda proporcionar a los codificadores las siguientes instrucciones:
- Al importar el proyecto recibido del investigador principal, agregue su nombre o iniciales al nombre del proyecto.
- Tras abrir el proyecto, verifique su nombre de usuario.
- Aplique todos los códigos de un dominio semántico de manera mutuamente excluyente.
- Si es pertinente, puede aplicar códigos de múltiples dominios semánticos a las mismas citas o a citas superpuestas.
- No realice ningún cambio en los códigos: no modifique la definición del código, no cambie el nombre del código ni el color del código.
- Si no comprende una definición de código o considera que una etiqueta de código no es adecuada, cree un memo y nómbrelo "Comentarios del codificador (nombre)". Escriba en este memo todos sus comentarios, los problemas que encuentre y las ideas que tenga.
- No consulte con otros codificadores. Esto es importante para que su codificación permanezca sin sesgos. Los datos deben ser codificados por todos los codificadores de manera independiente.
- Una vez finalizada la codificación, cree un paquete de proyecto y envíelo de vuelta al investigador principal.
Cómo se mide el acuerdo y el desacuerdo
Los coeficientes disponibles miden el grado de acuerdo o desacuerdo entre distintos codificadores. A partir de esta medida se puede inferir la fiabilidad, pero los coeficientes no la miden directamente. Por lo tanto: lo que se mide es el acuerdo intercodificadores y no la fiabilidad intercodificadores.
El acuerdo es lo que medimos; la fiabilidad es lo que inferimos de él.
Supongamos que se entrega un texto a dos codificadores para que lo codifiquen siguiendo las instrucciones proporcionadas. Una vez finalizado, entregan el siguiente registro de su codificación:

-
En el primer par de segmentos hay acuerdo en cuanto a longitud y ubicación (acuerdo: 10 unidades).
-
En el segundo par coinciden en la longitud pero no en la ubicación. Hay acuerdo en la intersección de los datos (acuerdo: 12 unidades, desacuerdo: 2 + 2 unidades).
-
En el tercer par, el codificador "A" considera relevante un segmento que el codificador "B" no reconoce (desacuerdo: 4 unidades).
-
El mayor desacuerdo se observa en el último par de segmentos. El codificador "A" adopta una visión más estrecha que el codificador "B" (acuerdo: 4 unidades, desacuerdo: 6 unidades).
En cuanto a la codificación en ATLAS.ti, es necesario concebir el documento como un continuo textual. Cada carácter del texto es una unidad de análisis para la ICA, comenzando en el carácter 1 y terminando, por ejemplo, en el carácter 17.500. Para documentos de audio y vídeo, la unidad de análisis es el segundo. Las imágenes no pueden utilizarse actualmente en un análisis ICA.
La cita en sí no entra en el análisis, sino los caracteres o segundos que han sido codificados. En otras palabras, si cada codificador crea citas, no supone un desacuerdo total que no hayan seleccionado exactamente el mismo segmento. La parte de las citas que se superpone entra en el análisis como acuerdo; las demás partes, como desacuerdo.
Otra opción es trabajar con citas predefinidas, de modo que los codificadores solo necesiten aplicar los códigos. Para más información, consulte Configuración del proyecto.
Es posible probar el acuerdo intercodificadores en documentos de texto, audio y vídeo. Los documentos de imagen no son compatibles. Esto también se aplica a las citas de imagen en documentos PDF de texto.
Ejemplo de aplicación
Why are many business instilling a DevOps culture into their organization? escrito por: Jessica Diaz, Daniel López-Fernández, Jorge Perez y Ángel González-Prieto.
Métodos para probar la ICA
"Un coeficiente de acuerdo intercodificadores mide el grado en que se puede confiar en que los datos representen los fenómenos de interés analítico que se espera analizar en lugar de los fenómenos brutos" (Krippendorff, 2019).
ATLAS.ti ofrece actualmente tres métodos para probar el acuerdo intercodificadores:
-
Porcentaje de acuerdo simple
-
Índice de Holsti
-
Familia de coeficientes alpha de Krippendorff.
Todos los métodos pueden utilizarse con dos o más codificadores. Como la medida de porcentaje de acuerdo y el índice de Holsti no tienen en cuenta el acuerdo por azar, se recomiendan los coeficientes alpha de Krippendorff para informes científicos.
Porcentaje de acuerdo
El porcentaje de acuerdo es la medida más simple del acuerdo intercodificadores. Se calcula como el número de veces que un conjunto de valoraciones coincide, dividido por el número total de unidades de observación valoradas, multiplicado por 100.
Las ventajas del porcentaje de acuerdo son su sencillez de cálculo y su aplicabilidad a cualquier tipo de escala de medición. Veamos el siguiente ejemplo: hay diez segmentos de texto y dos codificadores solo necesitan decidir si un código es aplicable o no:
Ejemplo de codificación de dos codificadores
| Segmentos | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Codificador 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Codificador 2 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
1 = acuerdo, 0 = desacuerdo
Este es el cálculo:
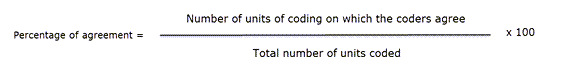
PA = 6 / 10
PA = 0,6 = 60%
Los codificadores 1 y 2 coinciden 6 de cada 10 veces, por lo que el porcentaje de acuerdo es del 60%.
Podría argumentarse que esto es bastante bueno. Sin embargo, este cálculo no tiene en cuenta el acuerdo por azar. Si los dos codificadores no leyeran los datos y simplemente codificaran los 10 segmentos de manera aleatoria, se esperaría que coincidieran en un cierto porcentaje de las veces por mera casualidad. La pregunta es: ¿cuánto supera ese 60% de acuerdo al acuerdo que se produciría por azar?
El acuerdo esperado por puro azar es del 56% = (9,6 + 1,6) / 20. Si le interesa el cálculo, consulte Krippendorff (2004, p. 224-226). El 60% de acuerdo ya no parece tan impresionante. En términos estadísticos, el rendimiento de los dos codificadores es equivalente a haber asignado 0 y 1 de forma arbitraria a 9 de los 10 segmentos, y solo 1 de los 10 segmentos está codificado de manera fiable.
Para calcular el porcentaje de acuerdo, puede agregar códigos individuales en lugar de dominios semánticos.
Índice de Holsti
El índice de Holsti (Holsti, 1969) es una variante de la medida de porcentaje de acuerdo para situaciones en las que los codificadores no codifican exactamente el mismo segmento de datos. Este es el caso cuando los codificadores establecen sus propias citas. Al igual que el porcentaje de acuerdo, el índice de Holsti tampoco tiene en cuenta el acuerdo por azar.
La fórmula del índice de Holsti es:
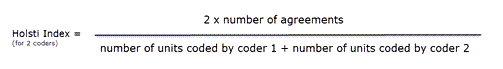
Los resultados del porcentaje de acuerdo y del índice de Holsti son iguales cuando todos los codificadores codifican los mismos segmentos de datos.
Para calcular el porcentaje de acuerdo, puede agregar códigos individuales en lugar de un dominio semántico, o utilizar dominios semánticos reales.
Kappa de Cohen
Reconocemos que la kappa de Cohen es una medida popular, pero hemos optado por no implementarla debido a las limitaciones identificadas en la literatura.
"Es bastante desconcertante por qué la kappa de Cohen ha sido tan popular a pesar de tanta controversia. Los investigadores comenzaron a señalar problemas con la kappa de Cohen hace más de tres décadas (Kraemer, 1979; Brennan y Prediger, 1981; Maclure y Willett, 1987; Zwick, 1988; Feinstein y Cicchetti, 1990; Cicchetti y Feinstein, 1990; Byrt, Bishop y Carlin, 1993). En una serie de dos artículos, Feinstein y Cicchetti (1990) y Cicchetti y Feinstein (1990) dieron a conocer las siguientes dos paradojas de la kappa de Cohen: (1) Un valor bajo de kappa puede darse con un acuerdo elevado; y (2) Las distribuciones marginales desequilibradas producen valores más altos de kappa que las distribuciones más equilibradas. Aunque las dos paradojas no se mencionan en libros de texto más antiguos (p. ej., Agresti, 2002), se presentan íntegramente como limitaciones de kappa en un libro de texto de posgrado reciente (Oleckno, 2008). Además de las dos paradojas mencionadas, Zhao (2011) describe doce paradojas adicionales de kappa y sugiere que la kappa de Cohen no es en absoluto una medida general de la fiabilidad entre evaluadores, sino una medida de fiabilidad bajo condiciones especiales que raramente se cumplen. Krippendorff (2004) sostiene que la kappa de Cohen no está cualificada como medida de fiabilidad en el análisis de fiabilidad, ya que su definición de acuerdo por azar se deriva de medidas de asociación debido a su supuesto de independencia entre evaluadores. Argumenta que en el análisis de fiabilidad los evaluadores deben ser intercambiables en lugar de independientes, y que la definición de acuerdo por azar debe derivarse de proporciones estimadas como aproximaciones a las proporciones verdaderas en la población de datos de fiabilidad. Krippendorff (2004) demuestra matemáticamente que el desacuerdo esperado de kappa no es una función de las proporciones estimadas a partir de los datos de la muestra, sino una función de las preferencias individuales de dos evaluadores por las dos categorías." (Xie, 2013).
Además, la kappa de Cohen solo puede utilizarse con 2 codificadores y asume un tamaño de muestra infinito. Consulte también el artículo en nuestro blog de investigación: Por qué la kappa de Cohen no es una buena opción.
Familia de coeficientes alpha de Krippendorff
La familia de coeficientes alpha ofrece diversas medidas que permiten realizar cálculos a diferentes niveles. Pueden utilizarse con más de dos codificadores, son sensibles a distintos tamaños de muestra y también pueden emplearse con muestras pequeñas.
Alpha binario
En el nivel más general, se puede medir si distintos codificadores identifican las mismas secciones de los datos como relevantes para los temas de interés representados por los códigos. Se tienen en cuenta todas las unidades de texto para este análisis, tanto los datos codificados como los no codificados.
En este nivel es posible, aunque no obligatorio, utilizar dominios semánticos. También es posible introducir un único código por dominio. Se obtiene un valor de alpha binario para cada código (o cada dominio semántico) incluido en el análisis, y un valor global para todos los códigos (o todos los dominios) del análisis.
El valor global de alpha binario puede ser el que se desee publicar en un artículo como valor general del acuerdo intercodificadores para el proyecto.
Los valores de cada código o dominio semántico ofrecen retroalimentación sobre qué códigos o dominios son satisfactorios en términos de acuerdo intercodificadores, y cuáles son interpretados de manera diferente por los distintos codificadores. Estos son los códigos o dominios que deben mejorarse y volver a probarse, con codificadores diferentes.
Si trabaja con citas predefinidas, el coeficiente binario será 1 para un dominio semántico si solo se han aplicado códigos del mismo dominio semántico, independientemente de qué código dentro del dominio se haya aplicado.
El valor de alpha binario global siempre será 1 cuando se trabaje con citas predefinidas, ya que todos los segmentos codificados son los mismos.
cu-alpha
Los coeficientes cu-alpha/Cu-alpha solo pueden utilizarse en combinación con dominios semánticos. ¡No pueden utilizarse para probar el acuerdo/desacuerdo de códigos individuales!
Otra opción es probar si distintos codificadores fueron capaces de distinguir entre los códigos de un dominio semántico. Por ejemplo, si tiene un dominio semántico llamado "tipo de emociones" con los subcódigos:
- emociones::satisfacción
- emociones::entusiasmo
- emociones::vergüenza
- emociones::alivio
El coeficiente indica si los codificadores fueron capaces de distinguir de manera fiable entre, por ejemplo, "satisfacción" y "entusiasmo", o entre "vergüenza" y "alivio". El cu-alpha proporciona un valor para el rendimiento global del dominio semántico, pero no indica cuál de los subcódigos puede ser problemático. Para ello es necesario examinar las citas y determinar dónde se produce la confusión.
El coeficiente cu-alpha solo puede calcularse si los códigos de un dominio semántico se han aplicado de manera mutuamente excluyente. Esto significa que solo se aplica uno de los subcódigos por dominio a una cita determinada. Consulte también Requisitos para la codificación.
Cu-alpha
Cu-alpha es el coeficiente global para todos los cu-alphas. Tiene en cuenta que es posible aplicar códigos de múltiples dominios semánticos a las mismas citas o a citas superpuestas. Consulte codificación multivaluada. Por lo tanto, Cu-alpha no es simplemente el promedio de todos los cu-alphas.
Si los códigos de un dominio semántico "A" se han aplicado a segmentos de datos que también están codificados con códigos de un dominio semántico "B", esto no afecta al coeficiente cu-alpha de ninguno de los dos dominios, pero sí afecta al coeficiente Cu-alpha global.
El coeficiente Cu-alpha puede interpretarse como indicador del grado en que los codificadores coinciden en la presencia o ausencia de los dominios semánticos en el análisis. Formulado como pregunta: ¿pudieron los codificadores identificar de manera fiable que los segmentos de datos pertenecen a un dominio semántico específico, o los distintos codificadores aplicaron códigos de otros dominios semánticos?
En el cálculo tanto del coeficiente cu-alpha como del Cu-alpha, solo se incluyen en el análisis los segmentos de datos codificados.
Cálculo del alpha de Krippendorff
Para una explicación matemática completa sobre cómo se calculan los coeficientes alpha, consulte el Apéndice ICA.
La fórmula básica para todos los coeficientes alpha de Krippendorff es la siguiente:
alpha = 1 - desacuerdo observado (Do) / desacuerdo esperado (De)

donde "De" es el desacuerdo esperado por azar.
α = 1 indica fiabilidad perfecta. α = 0 indica ausencia de fiabilidad. Las unidades y los valores asignados a ellas no están relacionados estadísticamente. α < 0 cuando los desacuerdos son sistemáticos y superan lo que cabría esperar por azar.
Cuando los codificadores no prestan atención al texto, es decir, aplican los códigos de manera arbitraria, su codificación no guarda relación con el contenido del texto, y el desacuerdo observado es 1. En otras palabras, el desacuerdo observado (Do) es igual al máximo desacuerdo esperado (De), que es 1. Si introducimos esto en la fórmula, obtenemos:
α = 1 – 1/1 = 0,000.
Si, por el contrario, el acuerdo es perfecto, es decir, el desacuerdo observado (Do) = 0, entonces:
α = 1 – 0 / desacuerdo esperado = 1,000.
Para comprender mejor la relación entre el acuerdo real, el observado y el esperado, examinemos la siguiente tabla de contingencia:
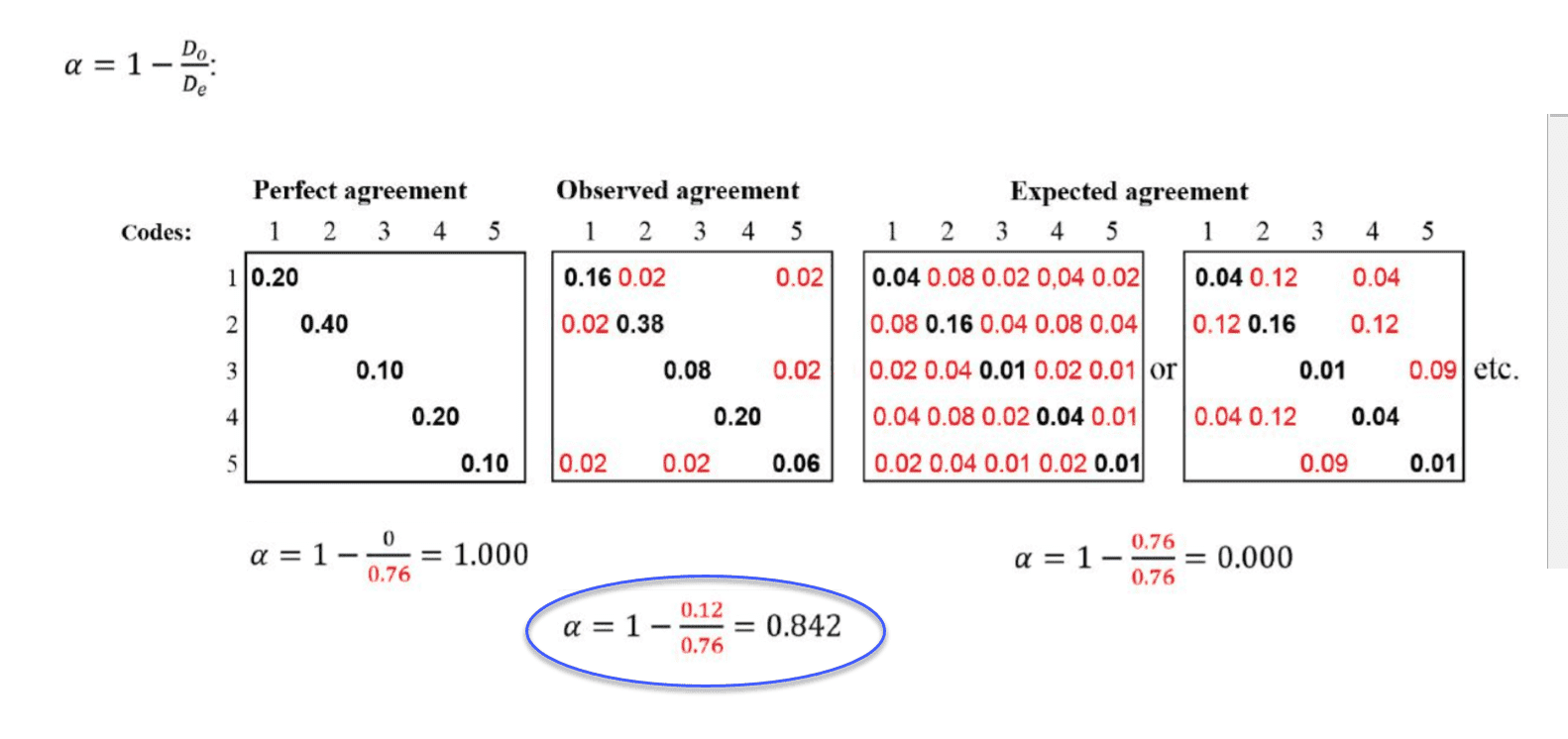
En el ejemplo anterior, las tablas representan un dominio semántico con cinco códigos. Las matrices de acuerdo/desacuerdo perfecto y esperado sirven como referencia de lo que podría haber ocurrido si el acuerdo hubiera sido perfecto o si los codificadores hubieran aplicado los códigos de manera aleatoria. Hay dos matrices de acuerdo/desacuerdo esperado, lo que indica que estadísticamente existen muchas posibilidades para una atribución aleatoria de los códigos.
Los números en negro muestran el acuerdo; los números en rojo, el desacuerdo.
En la tabla de contingencia del acuerdo observado, se puede ver que los codificadores coinciden en la aplicación del código 4. No hay números en rojo, es decir, no hay desacuerdo.
Hay cierto desacuerdo respecto a la aplicación del código 2. El acuerdo es del 38%. En el 2% de los casos se aplicó el código 1 en lugar del código 2.
Hay algo más de confusión en cuanto a la aplicación del código 5. Los codificadores también aplicaron el código 1 y el código 3.
Si esto fuera un ejemplo real, habría que revisar las definiciones de los códigos 5 y 2 y reflexionar sobre por qué los codificadores tuvieron dificultades para aplicarlos de manera fiable. Sin embargo, el coeficiente es aceptable. Consulte Reglas de decisión. No es necesario repetir la prueba.
Referencias
Banerjee, M., Capozzoli, M., McSweeney, L., Sinha, D. (1999). Beyond kappa: A review of interrater agreement measures. The Canadian Journal of Statistics, Vol. 27 (1), 3-23.
Cohen, Jacob (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement. 20 (1): 37–46. doi:10.1177/001316446002000104.
Holsti, O. R. (1969). Content analysis for the social sciences and humanities, Reading, MA: Addison-Wesley.
Krippendorff, Klaus (2004/2012/2018). Content Analysis: An Introduction to Its Methodology. 2ed /3rd /4th edition. Thousand Oaks, CA: Sage.
Zwick, Rebecca (1988). Another look at interrater agreement. Psychological Bulletin, 103, 347-387.
Xie, Q. (2013). Agree or disagree? A demonstration of an alternative statistic to Cohen's kappa for measuring the extent and reliability of agreement between observer. In Proceedings of the Federal Committee on Statistical Methodology Research Conference, The Council of Professional Associations on Federal Statistics, Washington, DC, USA, 2013.
Tamaño de muestra y reglas de decisión
Al probar el acuerdo intercodificadores es necesario tomar varias decisiones. Por ejemplo, qué cantidad de material de datos debe utilizarse, cuántas instancias deben codificarse con un código determinado para que el cálculo sea posible, y cómo evaluar el coeficiente obtenido.
Tamaño de muestra
Los datos utilizados para el análisis ICA deben ser representativos de la cantidad total de datos recopilados, es decir, de aquellos datos cuya fiabilidad está en cuestión. Además, el número de codificaciones por código debe ser suficientemente elevado. Como regla general, las codificaciones por código deben producir al menos cinco acuerdos por azar.
Krippendorff (2019) utiliza la fórmula 3.7 de Bloch y Kraemer (1989:276) para obtener el tamaño de muestra requerido. La tabla siguiente indica el tamaño de muestra necesario cuando se trabaja con dos codificadores:
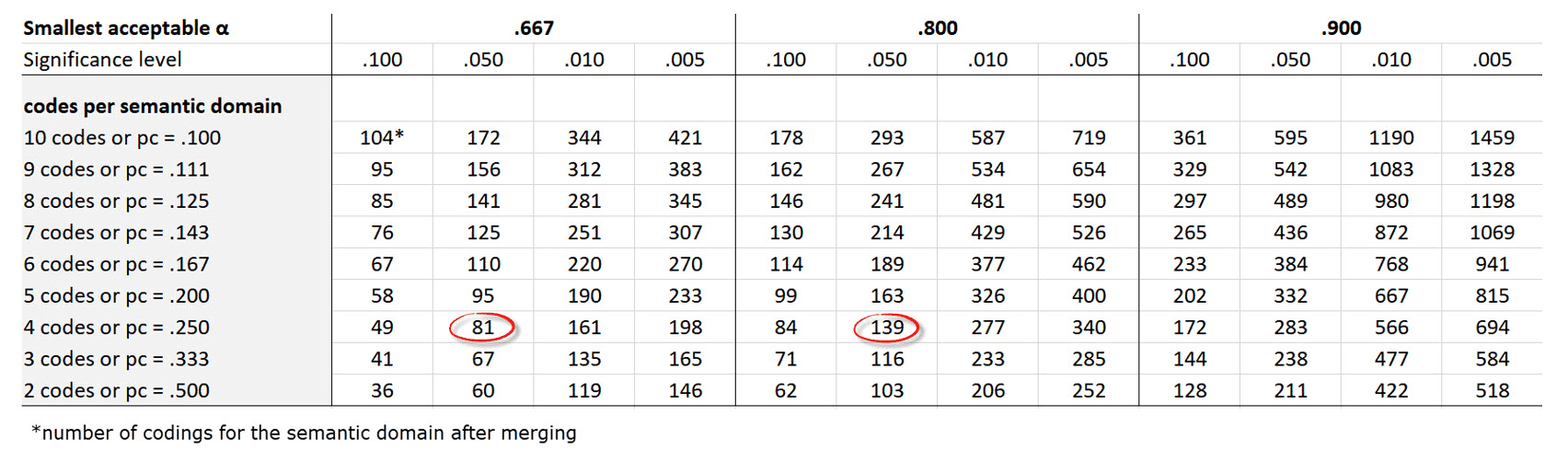
-
Las tres fiabilidades mínimas aceptables α mín.: 0,667 / 0,800 / 0,900
-
Para cuatro niveles de significación estadística: 0,100 / 0,050 / 0,010 / 0,005
-
Para dominios semánticos de hasta 10 códigos (= probabilidad pc):
Ejemplo: Si tiene un dominio semántico con 4 códigos y cada uno de los códigos está igualmente distribuido (pc = 1/4 = 0,25), y si el alpha mínimo debe ser 0,800 con un nivel de significación estadística de 0,05, necesita un mínimo de 139 codificaciones para este dominio semántico. Para un alpha inferior de 0,667, necesita un mínimo de 81 codificaciones con el mismo nivel de significación estadística.
Esta fórmula se aplica a 2 codificadores y a dominios semánticos de hasta 10 subcódigos. Si tiene más de dos codificadores, más de 10 subcódigos en un dominio, o una distribución desigual dentro de un dominio, deberá ajustar la ecuación y calcular usted mismo el tamaño de muestra necesario.
-
Más de dos codificadores: Es necesario multiplicar Z al cuadrado por el número de codificadores.
-
Más de 10 subcódigos por dominio: Es necesario ajustar el valor de pc. El valor de pc = 1/número de subcódigos.
-
Distribución desigual de codificaciones dentro de un dominio: Con 4 códigos en un dominio semántico, la proporción estimada pc de todos los valores c en la población es 0,250 (¼); con 5 códigos, es 0,200 (1/5); con 6 códigos, 0,167 (1/6), y así sucesivamente. Si la distribución de los códigos en un dominio semántico es desigual, es necesario hacer una nueva estimación del tamaño de muestra utilizando en la fórmula un valor de pc correspondientemente menor que 1/4, 1/5, 1/6, etc.
El valor de z correspondiente puede consultarse en una tabla de distribución normal estándar. Para un valor p de 0,05, z = 1,65.
Nivel aceptable de fiabilidad
La última cuestión a considerar es cuándo aceptar o rechazar los datos codificados en función del coeficiente ICA. Krippendorff (2019) recomienda:
- Aspirar a alcanzar α = 1,000, aunque esto sea solo un ideal.
- No aceptar datos con valores de fiabilidad por debajo de α = 0,667.
- En la mayoría de los casos, un dominio semántico puede considerarse fiable si α ≥ 0,800.
- Seleccionar al menos 0,05 como nivel de significación estadística para minimizar el riesgo de un error de tipo 1, que consiste en aceptar datos como fiables cuando no lo son.
El punto de corte que se elija depende siempre de los requisitos de validez que se exigen a los resultados de la investigación. Si el resultado del análisis afecta o incluso pone en riesgo la vida de alguien, deben utilizarse criterios más estrictos. Un punto de corte de α = 0,800 significa que el 80% de los datos está codificado con un grado superior al azar. Si se acepta α = 0,500, esto significa que el 50% de los datos está codificado con un grado superior al azar, lo que se asemeja un poco a lanzar una moneda al aire.
Configuración de un proyecto para el análisis de acuerdo intercodificadores
Es posible probar el acuerdo intercodificadores en documentos de texto, audio y vídeo. Los documentos de imagen no son compatibles. Esto también se aplica a las citas de imagen en documentos PDF de texto.
Cuando se desea ejecutar un análisis de acuerdo intercodificadores, se trabaja en equipo. Por lo tanto, es necesario saber cómo configurar un proyecto de equipo, distribuir y recopilar los proyectos de equipo para su fusión. Consulte el capítulo sobre Trabajo en equipo para obtener más información. Aquí encontrará la información específica del análisis de acuerdo intercodificadores.

Al preparar los subproyectos para los distintos codificadores, no los ponga en "Modo intercodificadores". Esto debe hacerse por primera vez al fusionar los subproyectos de los codificadores.
Como es necesario partir de un proyecto maestro común, no es posible realizar un análisis ICA si uno de los codificadores utiliza la versión web. Todos los codificadores deben usar la versión de escritorio (Mac o Windows). Para más información, consulte Fusión de proyectos.
Instrucciones para el investigador principal (IP)
-
El IP desarrolla el sistema de códigos añadiendo definiciones claras para cada código. Esto implica que el IP probablemente también ha codificado los datos. Consulte también Requisitos para la codificación. Este es el Proyecto maestro.
-
A partir del proyecto maestro, el IP crea un subproyecto para el análisis ICA. La manera más sencilla es duplicar un proyecto.
Por lo general, los codificadores para el análisis ICA codifican entre el 10 y el 20% del material. Otro enfoque consiste en determinar el número de codificaciones necesario para alcanzar un cierto nivel de significación. Consulte Tamaño de muestra y reglas de decisión.
- El IP elimina del proyecto de instantánea todos los documentos que los codificadores no deban codificar. Consulte Gestión de documentos.
A continuación, el IP puede eliminar todas las citas, de modo que el proyecto de instantánea para los codificadores solo contenga los documentos a codificar y los códigos con sus definiciones (opción A). Los codificadores deberán entonces encontrar y marcar los segmentos de texto que consideren relevantes y aplicar uno o más códigos de la lista. Esta opción es la más adecuada para documentos más extensos en los que interesa comprobar si otros codificadores encuentran los mismos fragmentos relevantes para un tema determinado. Por ejemplo, si se dispone de varios informes y el objetivo es identificar todos los segmentos relacionados con estrategias empresariales, leyes laborales y cuestiones de género, es necesario que todos los codificadores establezcan sus propias citas (Opción A: Eliminar todas las citas).
Otra opción es dejar las citas en el proyecto pero eliminar todas las codificaciones. Esto significa que los codificadores reciben un proyecto que contiene los documentos a codificar, citas predefinidas y una lista de códigos (opción B). Esta opción es útil cuando el objetivo es comprobar si distintos codificadores entienden los códigos de la misma manera y los aplican a los mismos segmentos de datos. Garantiza que el sistema de códigos sea replicable y que otros también vean en los datos lo mismo o algo similar a lo que ve el investigador principal (Opción B: Eliminar todas las codificaciones).
Opción A: Eliminar todas las citas
- Opción A: El IP elimina todas las citas: Abra el Administrador de citas, seleccione todas las citas, haga clic derecho y seleccione Eliminar.
Opción B: Eliminar todas las codificaciones
- Opción B: El IP elimina solo las codificaciones: En el menú principal, seleccione Citas > Desvincular todos los códigos de todas las citas.
Instrucciones para los codificadores
Un requisito fundamental para el análisis de acuerdo intercodificadores es la independencia de los codificadores. Por lo tanto, la persona que ha desarrollado el sistema de códigos no puede ser uno de los codificadores cuya codificación entre en el análisis ICA.
Se recomienda proporcionar a los codificadores las siguientes instrucciones.
-
Como codificador, recibirá un paquete de proyecto del investigador principal.
-
Tras importar el proyecto, renómbrelo y agregue su nombre o iniciales al nombre del proyecto.
-
Tras abrir el proyecto, verifique su nombre de usuario.
-
Abra el Administrador de códigos y familiarícese con el sistema de códigos. Lea todas las definiciones de los códigos.
-
Según el objetivo del análisis y la configuración del proyecto, deberá establecer sus propias citas y aplicar los códigos, o aplicar códigos a citas predefinidas.
-
Al aplicar códigos, nunca aplique más de un código de un dominio semántico específico a una cita individual o a citas superpuestas. Esto se denomina codificación mutuamente excluyente.
-
Si es pertinente, puede aplicar códigos de múltiples dominios semánticos a las mismas citas o a citas superpuestas (codificación multivaluada).
-
No realice ningún cambio en los códigos: no modifique la definición del código, no cambie el nombre del código ni el color del código.
-
Si no comprende una definición de código o considera que una etiqueta de código no es adecuada, cree un memo y nómbrelo "Comentarios del codificador (su nombre)". Escriba en este memo todos sus comentarios, los problemas que encuentre y las ideas que tenga.
-
No consulte con otros codificadores. Esto es importante para que su codificación permanezca sin sesgos. Los datos deben ser codificados por todos los codificadores de manera independiente.
-
Una vez finalizada la codificación, cree un paquete de proyecto y envíelo de vuelta al investigador principal.
Flujo de trabajo continuo
-
Una vez que los codificadores hayan terminado su trabajo, preparan un paquete de proyecto y lo envían de vuelta al IP.
-
El IP importa los paquetes de proyecto de cada codificador, revisa el trabajo de cada uno y lee el memo que han escrito (si lo hay).
-
A continuación, los proyectos deben fusionarse. Consulte Fusión de proyectos para el análisis ICA.
-
Luego el IP puede ejecutar el análisis ICA.
Fusionar proyectos para el análisis ICA
Las siguientes instrucciones asumen 2 codificadores independientes. Si trabaja con más codificadores, deberá repetir el proceso de fusión. Solo se pueden fusionar dos proyectos a la vez.
Se recomienda importar los paquetes de proyecto de los codificadores 1 y 2 antes de fusionarlos para revisarlos. ¿Los codificadores hicieron lo que debían? ¿Enviaron el proyecto correcto?
Cree una copia del proyecto del codificador 1. Asigne a la copia un nombre como "Proyecto para ICA XY codificadores 1 y 2". Fusione el proyecto del codificador 2 en esta versión del proyecto.
Antes de fusionar el proyecto, configúrelo en modo intercodificadores:
En el menú principal, seleccione Análisis > Modo de acuerdo intercodificadores.
A continuación, seleccione Proyecto > Fusionar con proyecto en el menú principal y elija el proyecto del codificador 2 para fusionarlo. Este es el proyecto de importación. Siga las instrucciones en pantalla. No debería haber conflictos de fusión. Para más detalles, consulte Fusión de proyectos.
Cuando el proyecto está configurado correctamente y todos los codificadores hicieron lo que debían, no debería haber ningún conflicto de fusión. Si lo hay, haber revisado los proyectos previamente le dará una idea de qué salió mal y cómo actuar.
Tras la fusión en modo ICA, las codificaciones de todos los codificadores serán visibles.
Abra un documento y examine el área de margen. Si ve los mismos códigos aplicados a las mismas citas, es una buena señal: significa que los dos codificadores están de acuerdo. Si pasa el cursor sobre el código, verá el nombre del codificador que lo aplicó.
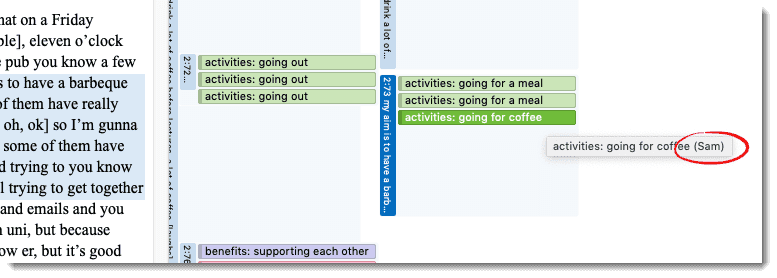
La capacidad de ver quién ha codificado qué en el área de margen resulta útil para algunos propósitos, por ejemplo, si desea analizar los segmentos de datos donde los codificadores no estuvieron de acuerdo. Sin embargo, no es necesario revisar manualmente todas las codificaciones en el margen. Para ello puede ejecutar el análisis de acuerdo intercodificadores. Consulte Ejecutar un análisis de acuerdo intercodificadores.
Una codificación es el vínculo entre un código y una cita. En modo ICA, puede ver qué codificador ha aplicado cada código a una cita.
Ejecutar un análisis ICA
Un buen momento para que otros codificadores revisen la codificación es cuando se ha construido un sistema de códigos estable y todos los códigos están definidos. Esto significa que se está en algún punto intermedio del proceso de codificación. Una vez alcanzado un coeficiente ICA satisfactorio, el investigador principal tiene la certeza de que sus códigos pueden ser comprendidos y aplicados por otras personas, y puede continuar trabajando con el sistema de códigos.
En el menú principal, seleccione Análisis > Calcular acuerdo intercodificadores.
Haga clic en el botón Agregar usuario y seleccione dos o más codificadores.
Haga clic en el botón Agregar documentos y seleccione los documentos que se incluirán en el análisis. Solo se muestran los documentos que han sido codificados por todos los codificadores seleccionados.
Haga clic en el botón Agregar dominio semántico y agregue uno o más códigos al dominio. También puede arrastrar y soltar códigos desde el Explorador del proyecto o la lista de códigos al campo del dominio semántico. Esto funciona mejor si coloca la ventana ICA junto a la ventana principal.
Repita este proceso para cada dominio semántico.
Si no sabe qué es un dominio semántico, encontrará más información aquí.
La elección de agregar dominios semánticos o un único código en lugar de un dominio afecta al tipo de análisis que se puede ejecutar. Si solo agrega un código por dominio semántico, no podrá calcular los coeficientes Cu/cu-alpha. Consulte Métodos para probar la ICA.
Después de haber agregado codificadores, documentos y códigos, la pantalla tendrá un aspecto similar al que se muestra en:
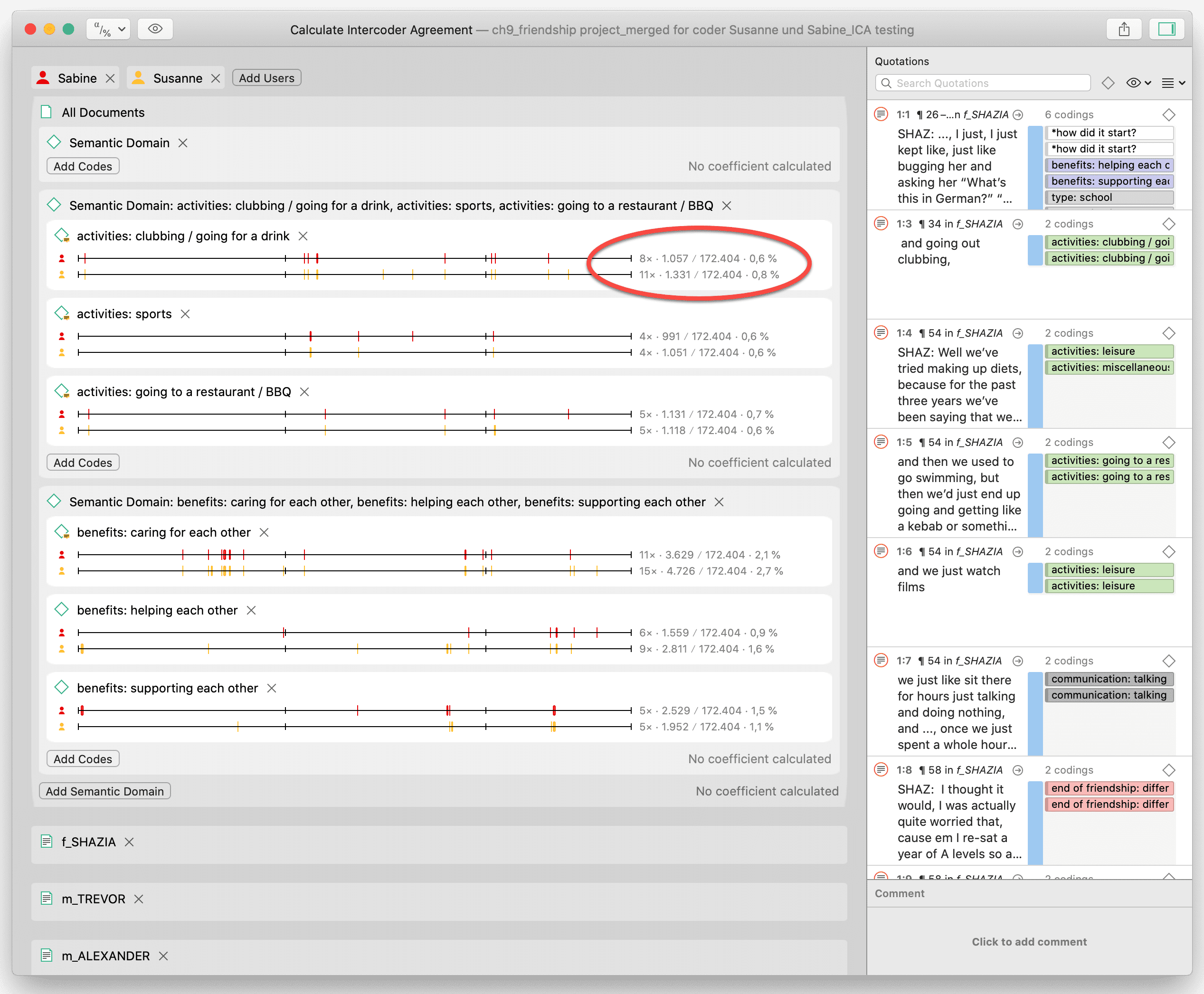
-
Los documentos se representan con una línea por cada codificador y código. Si se han agregado varios documentos al análisis, aparece una línea vertical negra que marca el inicio del siguiente documento.
-
Las citas del código se marcan en la línea con el mismo color que el icono del codificador.
-
A la derecha de cada línea de codificador se muestran algunas estadísticas descriptivas: La codificadora Susanne (amarillo) ha aplicado el código "actividades: salir de copas / ir a bares" 11 veces. El número de caracteres codificados con este código es 1.331 de un total de 172.404 caracteres en los tres documentos seleccionados, lo que corresponde al 0,8%. La codificadora Sabine (rojo) ha aplicado el código "actividades: salir de copas / ir a bares" 8 veces. El número de caracteres codificados con este código es 1.057 de un total de 172.404 caracteres en los tres documentos seleccionados, lo que corresponde al 0,6%.
En el lado derecho se encuentra el Lector de citas, que muestra todas las citas de todos los documentos y códigos seleccionados.
-
Si hace clic en el área con las dos líneas de los dos codificadores para un código, solo se mostrarán las citas del código seleccionado.
-
Si selecciona un dominio semántico, solo se mostrarán las citas del dominio en el Lector de citas.
Puede eliminar codificadores, códigos o documentos del análisis haciendo clic en la x.
Calcular un coeficiente ICA
Para calcular la ICA, haga clic en el botón Medidas de acuerdo en la barra de herramientas (junto al botón Vista) y seleccione uno de los cuatro métodos. Consulte Métodos para probar la ICA para más detalles.

Al seleccionar el coeficiente Cu/cu-alpha de Krippendorff para el ejemplo anterior, se obtienen los siguientes resultados:
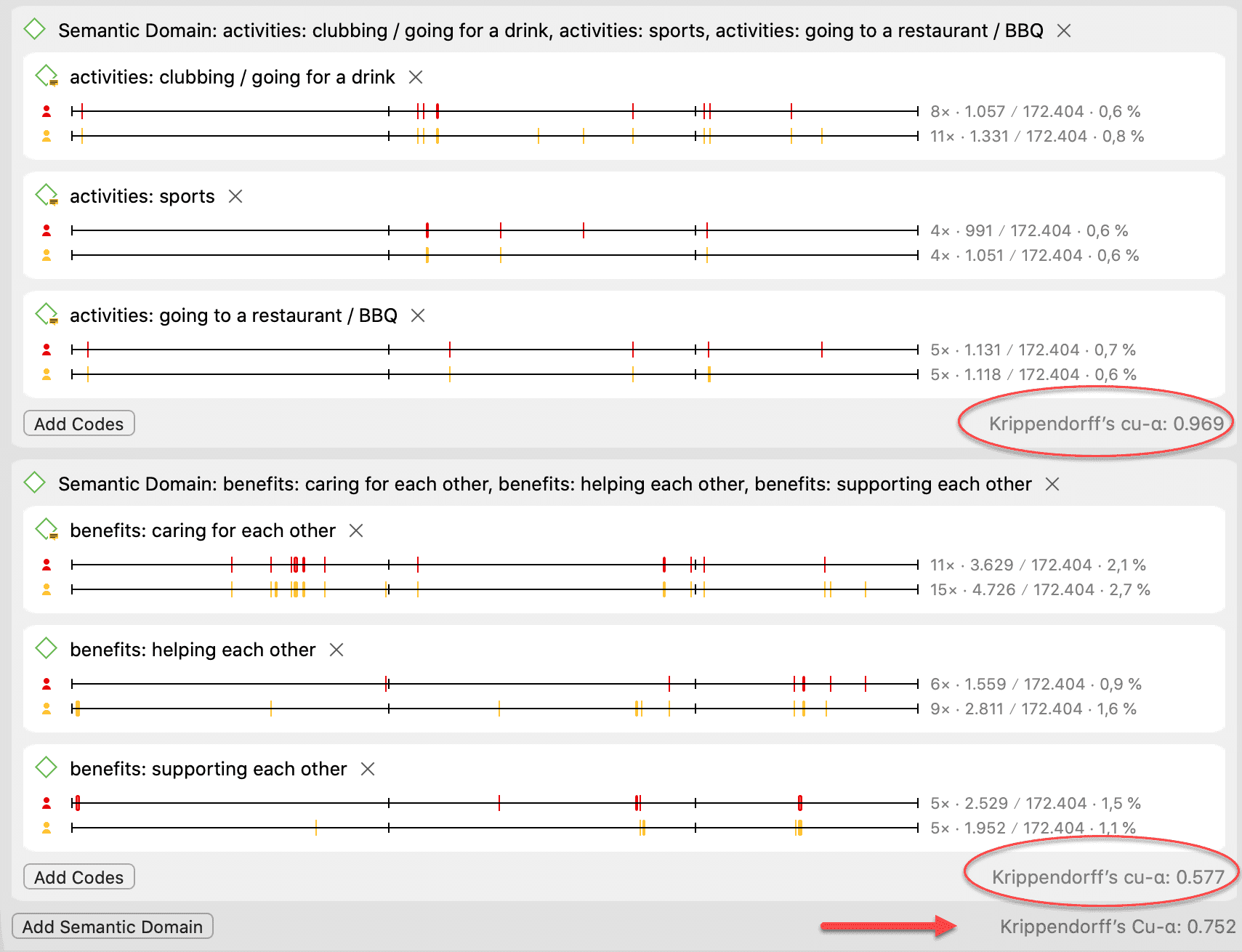
Herramientas
Las siguientes herramientas están disponibles:
El analizador de codificaciones redundantes encuentra citas superpuestas o anidadas que están asociadas con el mismo código. Es posible que haya codificado un segmento largo, p. ej., del párrafo 5 al 15, y luego un segmento más corto dentro de esa sección del párrafo 7 al 8, sin darse cuenta de que ya había adjuntado el mismo código al segmento circundante. Esto lleva a resultados confusos o incluso incorrectos si está contando segmentos. El analizador de codificaciones redundantes encuentra estos segmentos y le permite corregirlo.
La herramienta de búsqueda en el proyecto permite buscar en todas las entidades de su proyecto. Puede especificar si desea buscar una palabra o expresión en todas las entidades, o solo en documentos, solo en códigos, solo en memos, solo en los nombres, solo en los comentarios, etc. Los términos de búsqueda pueden incluir expresiones regulares.
Búsqueda en el proyecto
Use la herramienta Búsqueda en el proyecto para buscar texto y patrones en todos los elementos de su proyecto, no solo en los documentos que ha agregado. La búsqueda puede restringirse a determinados campos, como nombre, autor, fecha, comentarios y contenido. Los términos de búsqueda pueden contener expresiones regulares (GREP). Consulte Expresiones regulares (GREP).
Puede abrir la herramienta en el Explorador de proyectos en el lado izquierdo. Haga clic en la lupa.
Ingrese un término de búsqueda. Si utiliza expresiones regulares, active la opción Usar RegEx. También puede seleccionar si el término de búsqueda debe distinguir entre mayúsculas y minúsculas o no.
Seleccione las entidades en las que desea buscar y elija si desea buscar solo en el nombre de la entidad, en el comentario o en el contenido completo del texto.
Seleccione si los resultados de la búsqueda deben expandirse a palabras, oraciones, párrafos, capítulos (= al menos una línea vacía entre párrafos) o el documento completo.
Los resultados de la búsqueda son visibles de inmediato. Al hacer doble clic en un resultado, este se mostrará en su proyecto.
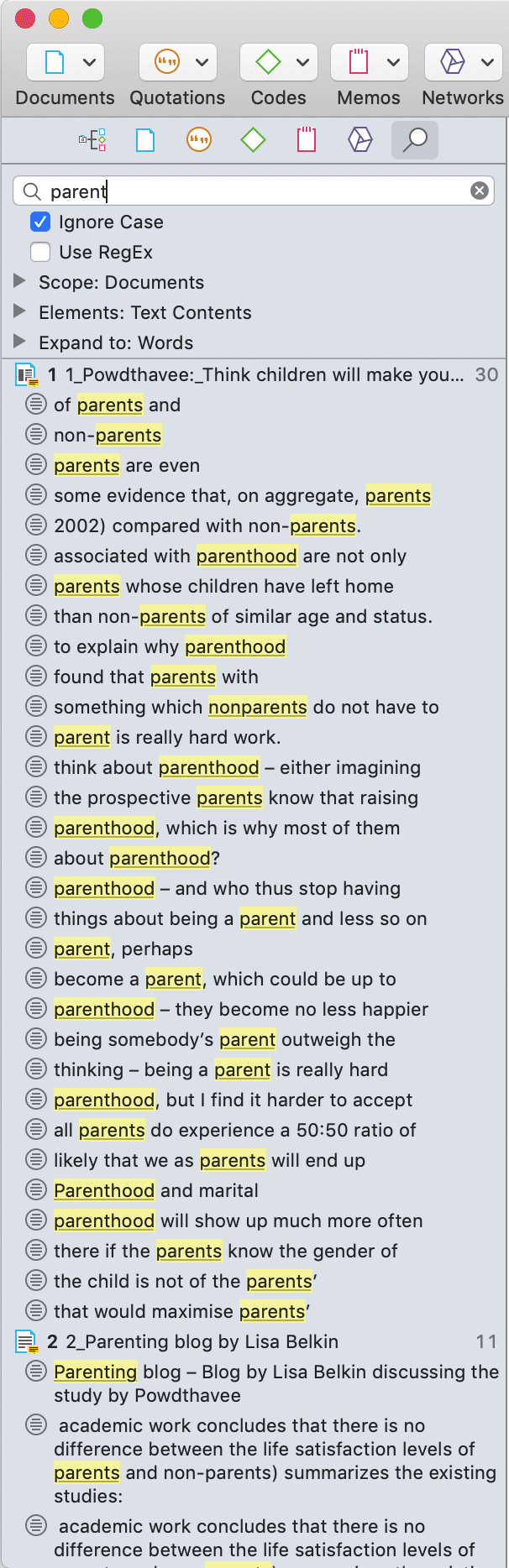
Encontrar codificaciones redundantes
Las codificaciones redundantes son citas superpuestas o anidadas que están asociadas con el mismo código. Estas codificaciones pueden resultar de una codificación normal, pero también pueden pasar desapercibidas durante un proceso de fusión cuando se trabaja en equipo. El Analizador de codificaciones encuentra todas las codificaciones redundantes y ofrece los procedimientos adecuados para corregirlas. A continuación se muestra un ejemplo de una codificación redundante.
Para encontrar todas las codificaciones redundantes, seleccione Cita > Buscar codificaciones redundantes desde el menú principal.
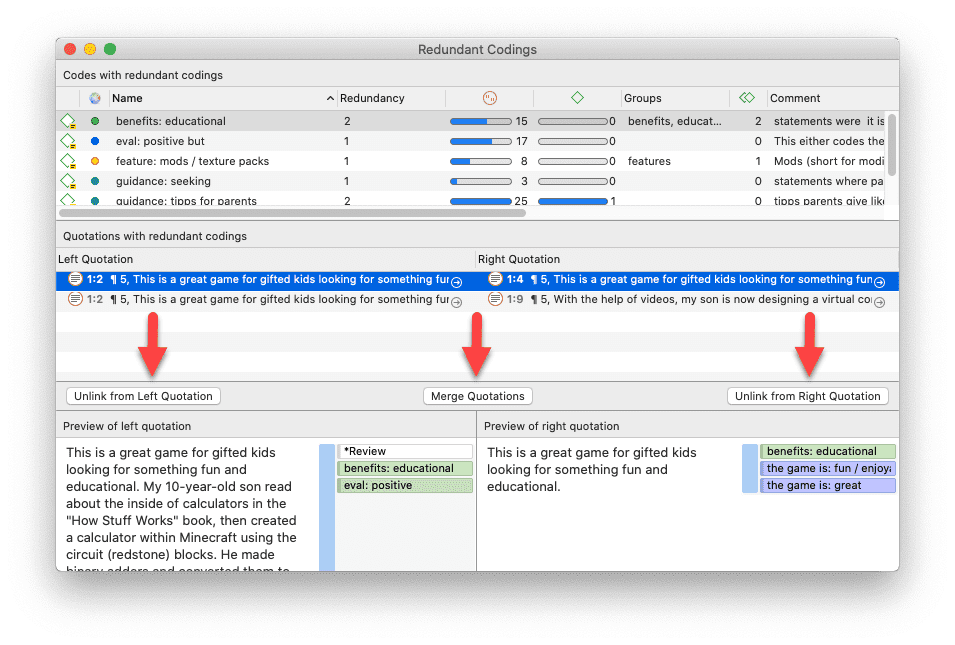
El panel superior lista todos los códigos para los que se encontraron codificaciones redundantes. La columna Redundancia muestra el número de pares de citas redundantes encontradas para los códigos. Si selecciona uno de los códigos, las citas redundantes se listan por pares en el panel central. Si selecciona un par, verá una vista previa de la cita en el panel inferior. Al hacer doble clic en una cita listada, esta se muestra en contexto.
Puede corregir la redundancia de las siguientes maneras:
Desvincular de la cita izquierda elimina el código seleccionado de la cita que se muestra en el lado izquierdo.
Fusionar citas combina las dos citas que se muestran en el lado derecho e izquierdo. Todas las referencias hacia y desde la cita fusionada son "heredadas" por la otra. Si las dos citas se superponen, la cita resultante incluye todos los datos de ambas citas.
Desvincular de la cita derecha elimina el código seleccionado de la cita que se muestra en el lado derecho.
Si ve una cita listada más de una vez, significa que tres o más citas están involucradas en una codificación redundante. Notará que fusionar un par de citas puede hacer que otros pares también se eliminen de la lista, ya que la afirmación de redundancia ya no se cumple para los pares de citas restantes de este código.
Crear informes
Exportar como hoja de cálculo
En cada administrador encontrará un botón (el icono rectangular con una flecha hacia arriba) para exportar el contenido como hoja de cálculo. La exportación es de tipo WYSIWYG (lo que se ve es lo que se obtiene). Se exportan todas las columnas que se muestran actualmente.
Desde los administradores
Para excluir una columna del informe, haga clic en el encabezado de la columna y deselecciónela.
Para crear un informe, abra el menú desplegable del botón de informe en la barra de herramientas y seleccione Exportar como hoja de cálculo.
Use las opciones de agrupación para crear diferentes hojas para cada entidad seleccionada; por ejemplo, si agrupa un informe de citas por códigos, ATLAS.ti crea una hoja separada para cada código y sus citas en la hoja de cálculo o archivo Excel.
Desde la herramienta de consulta
Para crear un informe, abra el menú desplegable del botón de informe en la barra de herramientas y seleccione Exportar como hoja de cálculo.
Desde el Lector de citas
Para exportar las citas listadas en un Lector de citas como hoja de cálculo, abra el menú desplegable del botón de opciones en la barra de herramientas y seleccione Exportar como hoja de cálculo. El contenido del informe es el mismo que desde el Administrador de citas. Contiene todas las columnas del Administrador de citas.
Hoja de información para informes de hoja de cálculo / Excel
Todos los informes de hoja de cálculo / Excel tienen una hoja adicional que muestra metainformación como el tipo de informe, el nombre del proyecto, la fecha de exportación y el nombre del usuario que exportó.
Las hojas de información para informes basados en la Tabla de documentos por código, la Tabla de co-ocurrencia de códigos y el Análisis de acuerdo entre codificadores contienen información adicional.
-
abreviaturas utilizadas
-
Tabla de documentos por código: información sobre qué recuento de frecuencia relativa se utiliza
-
Tabla de co-ocurrencia de códigos: si se seleccionó el coeficiente c
-
Informes de AEC: nombres de los codificadores
Exportar como informe
Al usar esta opción, se obtiene un informe en formato de texto o PDF. Está disponible desde todos los administradores y la herramienta de consulta. El informe es configurable, es decir, se puede seleccionar qué debe contener. Antes de crear el informe, se ve una previsualización.
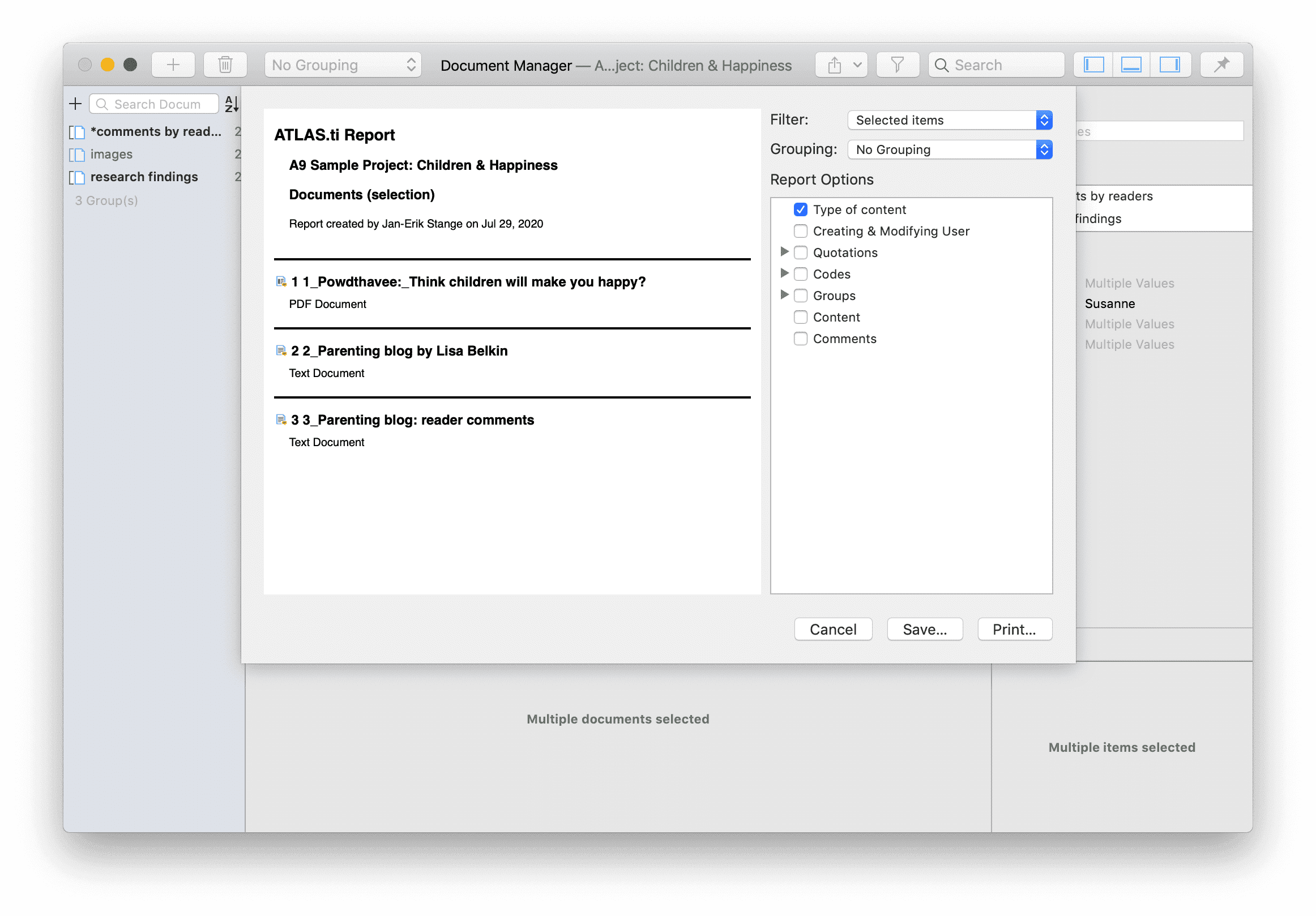
Abra un administrador. Haga clic en el menú desplegable del botón de informe en la barra de herramientas y seleccione Exportar como informe.
En el lado izquierdo se ve cómo quedará el informe con las selecciones actuales. En el lado derecho se pueden seleccionar más opciones:
-
Filtro: Si seleccionó elementos antes de hacer clic en el botón de informe, puede alternar entre crear un informe solo para los elementos seleccionados o para todos.
-
Agrupación: Dependiendo del tipo de entidad, hay diferentes opciones de agrupación, por ejemplo, por código, grupo de códigos o documento. Seleccione una opción de agrupación si corresponde.
Si selecciona agrupar citas por código, y una cita está codificada con varios grupos de códigos, las citas para ese código aparecerán varias veces en el informe.
Si selecciona agrupar por grupos de códigos, y un código es miembro de varios grupos de códigos, las citas para ese código aparecerán varias veces en el informe.
-
Opciones del informe: En este campo, se puede seleccionar qué contenido debe mostrarse en el informe. Tan pronto como se selecciona una opción, la previsualización muestra cómo quedará en el informe. Véase más detalles a continuación.
-
Guardar: Esto guarda el informe como documento Word. Seleccione un nombre para el informe y una ubicación.
-
Imprimir: Se puede enviar el informe directamente a una impresora, o guardarlo como archivo PDF. Otras opciones son:
- Guardar como PostScript
- Enviar por correo
- Enviar por Mensajes
- Guardar en iCloud Drive
- Guardar en Recibos web
Opciones en el Administrador de documentos
-
Tipo de contenido: texto, imagen, geo, audio o video
-
Agregar el Usuario que creó y modificó al informe.
-
Citas: Agrega las citas que se encuentran en el documento (ID, referencia, nombre de cita y nombre del documento). Si se selecciona, se puede agregar más información sobre las citas desde el subárbol, por ejemplo, su contenido y los códigos aplicados.
-
Códigos: Agrega los códigos aplicados a las citas del documento. Si se selecciona, se puede agregar más información sobre los códigos desde el subárbol.
-
Grupos: Agrega los grupos de documentos de los que forma parte el documento. Si se selecciona, se puede agregar más información sobre los grupos desde el subárbol.
-
Contenido: Agrega el contenido del documento.
-
Comentarios: Agrega al informe el comentario escrito para un documento.
Opciones en el Administrador de citas
-
Tipo de contenido: texto, imagen, geo, audio o video
-
Agregar el Usuario que creó y modificó al informe.
-
En documento: Agrega el nombre del documento al informe. Si se selecciona, se puede agregar más información sobre el documento desde el subárbol.
-
Codificación: Agrega al informe los códigos aplicados a la cita. Si se selecciona, se puede agregar más información sobre los códigos desde el subárbol.
-
Hipervínculos: Agrega al informe las citas vinculadas a una cita. Si se selecciona, se puede agregar más información sobre las citas vinculadas desde el subárbol, como su contenido.
-
Memos vinculados: Agrega al informe los memos vinculados a la cita. Si se selecciona, se puede agregar más información sobre el memo desde el subárbol, como el contenido del memo.
-
Contenido: Está seleccionado de forma predeterminada. Si está seleccionado, se muestra el contenido de la cita.
-
Comentarios: Agrega al informe el comentario escrito para una cita.
Opciones en el Administrador de códigos
-
Agregar el Usuario que creó y modificó al informe.
-
Usado en documentos: Agrega los documentos donde se ha aplicado el código. Si se selecciona, se puede agregar más información sobre los documentos desde el subárbol.
-
Grupos: Agrega los grupos de los que forma parte un código. Si se selecciona, se puede agregar más información sobre los grupos desde el subárbol.
-
Códigos vinculados: Agrega los códigos vinculados a un código. Si se selecciona, se puede agregar más información sobre los códigos vinculados desde el subárbol.
-
Citas: Agrega una lista de citas codificadas con el código (ID, referencia, nombre de cita y nombre del documento). Si se selecciona, se puede agregar más información sobre las citas desde el subárbol, por ejemplo, su contenido.
-
Memos vinculados: Agrega al informe los memos vinculados a un código. Si se selecciona, se puede agregar más información sobre el memo desde el subárbol, como el contenido del memo.
-
Comentarios: Agrega al informe el comentario escrito para un código.
Opciones en el Administrador de memos
-
Agregar el Usuario que creó y modificó al informe.
-
Grupos: Agrega los grupos de los que forma parte un memo. Si se selecciona, se puede agregar más información sobre los grupos desde el subárbol.
-
Códigos vinculados: Agrega los códigos vinculados a un memo. Si se selecciona, se puede agregar más información sobre los códigos vinculados desde el subárbol.
-
Citas vinculadas: Agrega una lista de citas vinculadas al memo (ID, referencia, nombre de cita y nombre del documento). Si se selecciona, se puede agregar más información sobre las citas desde el subárbol, por ejemplo, su contenido.
-
Memos vinculados: Agrega al informe los memos vinculados a un memo. Si se selecciona, se puede agregar más información sobre el memo desde el subárbol, como el contenido del memo.
-
Contenido: Agrega el contenido del memo al informe.
-
Comentarios: Agrega al informe el comentario escrito para un memo.
Opciones en el Administrador de redes
-
Agregar el Usuario que creó y modificó al informe.
-
Grupos: Agrega los grupos de los que forma parte una red. Si se selecciona, se puede agregar más información sobre los grupos desde el subárbol.
-
Comentarios: Agrega al informe el comentario escrito para una red.
Informes predefinidos
Los informes predefinidos son esencialmente un atajo para crear informes de texto o PDF desde los administradores. Encontrará una entrada de menú Generar informe en el menú principal para Documento, Cita, Código, Memo y Red.
Después de seleccionar una opción, aparece la misma ventana que al seleccionar la opción Exportar como informe en los administradores, tal como se describe anteriormente. La única diferencia es que las opciones adecuadas ya han sido seleccionadas previamente. Se pueden agregar más opciones al informe.
Para documentos
Para las citas, se dispone de los siguientes informes predefinidos:
- Documentos y grupos: Un informe que contiene todos los documentos, su tipo y los grupos de los que son miembros.
- Grupos de documentos y miembros: Un informe que contiene todos los grupos de documentos y sus miembros.
Para citas
Para las citas, se dispone de los siguientes informes predefinidos:
- Citas por documento: Un informe que contiene todas las citas con su contenido y comentarios, incluido el nombre del documento.
- Citas por códigos: Un informe que contiene todas las citas con su contenido, incluido el nombre del documento para cada código.
- Hipervínculos con comentarios: Un informe que contiene todos los hipervínculos. Se incluyen el ID de cita, la referencia, el nombre de la cita y del documento tanto para la cita de origen como para la de destino, y la relación que las vincula.
Para códigos
Para los códigos, se dispone de los siguientes informes predefinidos:
-
Libro de códigos: Un informe que contiene todos los códigos y sus comentarios. Si desea agregar un libro de códigos al apéndice de una tesis o un informe, se recomienda usar la opción de hoja de cálculo.
-
Códigos por documentos: Un informe que contiene todos los códigos y sus comentarios, ordenados por los documentos en que aparecen.
-
Grupos de códigos y miembros: Un informe que contiene todos los grupos de códigos y sus miembros.
Para memos
Para los memos, se dispone de los siguientes informes predefinidos:
- Crea un informe que contiene una lista de todos los documentos y su pertenencia a grupos.
- Crea un informe que contiene todos los grupos de documentos con sus miembros.
Para redes
Para los memos, se dispone de los siguientes informes predefinidos:
- Crea un informe que contiene una lista de todos los documentos y su pertenencia a grupos.
- Crea un informe que contiene todos los grupos de documentos con sus miembros.
Tipos de informe
Dispone de las siguientes opciones de exportación:
Informes
- Informes desde los administradores en formato de texto o PDF, o como hoja de cálculo.
- Informes desde el Lector de citas como hoja de cálculo.
- Informes desde la herramienta de consulta como hoja de cálculo.
Véase Crear informes para más información.
Exportación de datos
- Se pueden exportar todos los documentos
- Se pueden exportar todos los datos para su uso posterior en SPSS en forma de archivo de sintaxis.
- Se puede crear una exportación genérica de todos los datos para su uso posterior en un software estadístico como R, SAS, etc. en forma de hoja de cálculo.
Exportación de proyectos
-
Se puede exportar el proyecto completo en formato QDPX para su uso en otro software QDAS (software de análisis cualitativo de datos) que admita la importación de QDPX.
-
Se puede exportar el proyecto completo en formato XML.
Tablas
- Todas las tablas y la lista de palabras pueden exportarse como hoja de cálculo. Véase Tabla de documentos por código y Tabla de co-ocurrencia de códigos.
Exportaciones en formato PDF
- El documento con margen y las redes pueden exportarse en formato PDF a través de la opción de menú Proyecto > Imprimir.
Exportaciones como documento de imagen
- Los diagramas de Sankey y las nubes de palabras pueden exportarse como archivo gráfico.
Crear informes en Word / PDF
Crear informes desde el Administrador de códigos
Si se desea un informe de texto con las citas de los códigos seleccionados, la mejor opción es crear el informe desde el Administrador de códigos.
Abra el Administrador de códigos. Seleccione uno o varios códigos, o establezca un grupo de códigos como filtro si no desea crear un informe para todos los códigos.
Seleccione una opción de filtro: Si seleccionó algunos códigos o estableció un grupo de códigos como filtro, aún puede cambiar y exportar todos los códigos.
Puede agrupar el informe por:
Si selecciona "Códigos inteligentes", las citas de los códigos inteligentes aparecen primero en el informe.
Al seleccionar una opción de agrupación, se presentan más opciones, por ejemplo, si también desea exportar el comentario del grupo de códigos o del documento.
Si un código seleccionado pertenece a varios grupos de códigos, las citas de ese código aparecerán varias veces en el informe.
A continuación, seleccione qué debe incluirse en el informe.
Al seleccionar Grupos, Citas, Memos o Códigos, se pueden seleccionar más opciones. Para ello, haga clic en el pequeño triángulo delante del elemento para abrir la rama. Para crear un informe de citas, es necesario seleccionar "contenido"; de lo contrario, el informe solo incluirá los nombres de las citas. Véase las opciones seleccionadas a continuación.
En el lado izquierdo se ve una previsualización que muestra cómo quedará el informe final. La previsualización cambia tan pronto como se selecciona o deselecciona una opción.
Si el informe contiene todo lo que desea, haga clic en Guardar para guardar el informe como documento Word. Haga clic en Imprimir para imprimir el informe o guardarlo como archivo PDF.
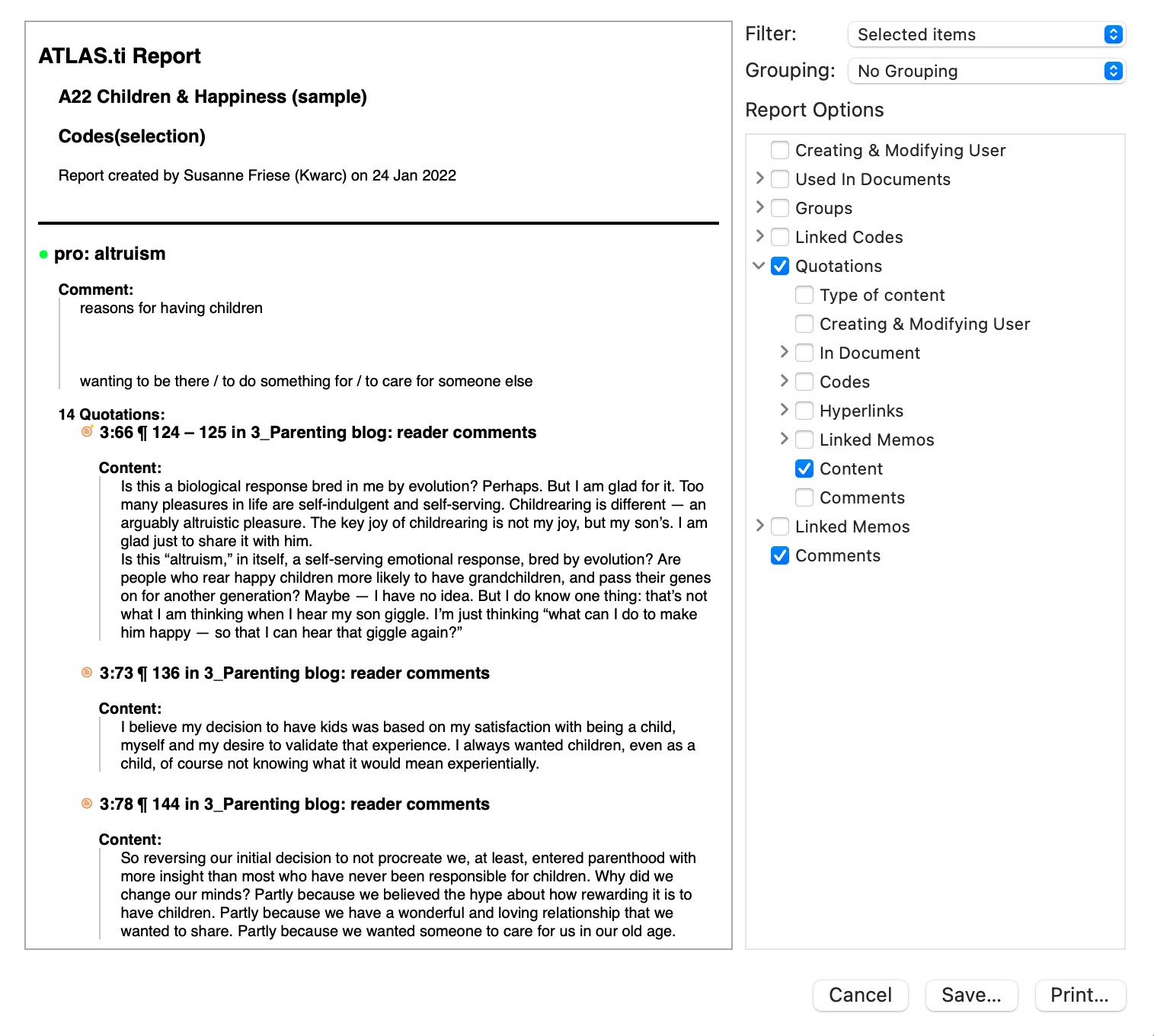
La creación de informes desde los demás administradores funciona esencialmente de la misma manera. A continuación solo se muestran las opciones disponibles en cada administrador. La idea básica es que se puede crear de forma flexible cualquier tipo de informe con cualquier tipo de contenido que se necesite.
Informes del Administrador de citas

Informes del Administrador de documentos

Informes del Administrador de memos

Informes del Administrador de redes

Crear informes de Excel
Hoja de información para informes de Excel
Todos los informes de Excel tienen una hoja adicional que muestra metainformación como el tipo de informe, el nombre del proyecto, la fecha de exportación y el nombre del usuario que exportó.
Las hojas de información para informes basados en la Tabla de documentos por código, la Tabla de co-ocurrencia de códigos y el Análisis de acuerdo entre codificadores contienen información adicional.
-
abreviaturas utilizadas
-
Tabla de documentos por código: información sobre qué recuento de frecuencia relativa se utiliza
-
Tabla de co-ocurrencia de códigos: si se seleccionó el coeficiente c
-
Informes de AEC: nombres de los codificadores
Hoja de información en Excel
En cada administrador encontrará un botón para crear un informe de Excel. El informe de Excel contiene todas las columnas del administrador que están visibles actualmente en el modo de vista detallada. De forma predeterminada, todo estará visible.
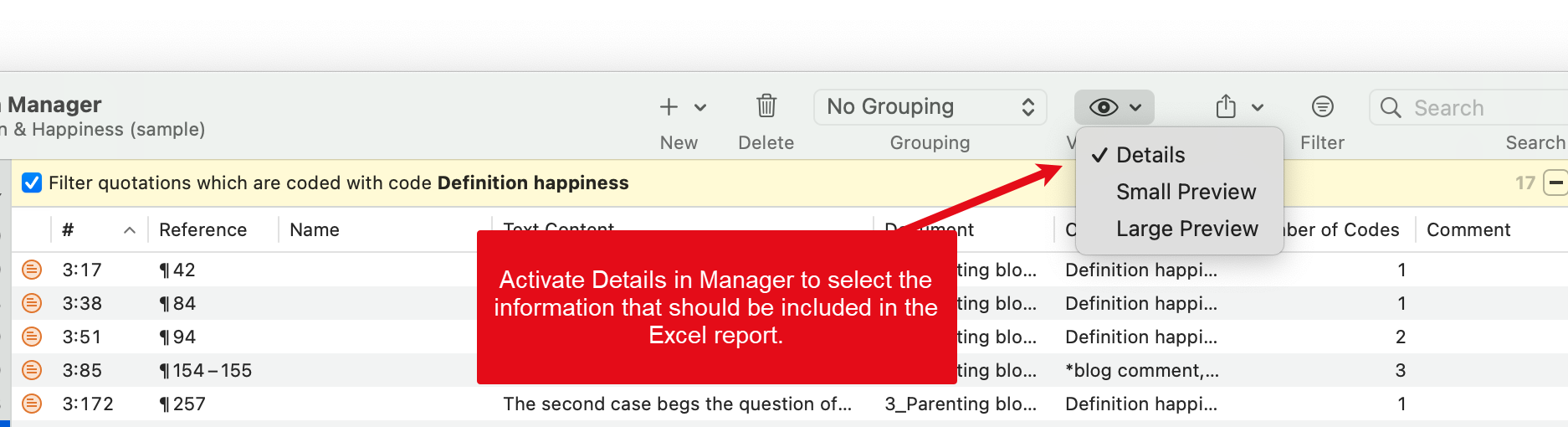
Si no desea incluir toda la información, haga clic derecho en una columna y deseleccione lo que no quiera incluir:
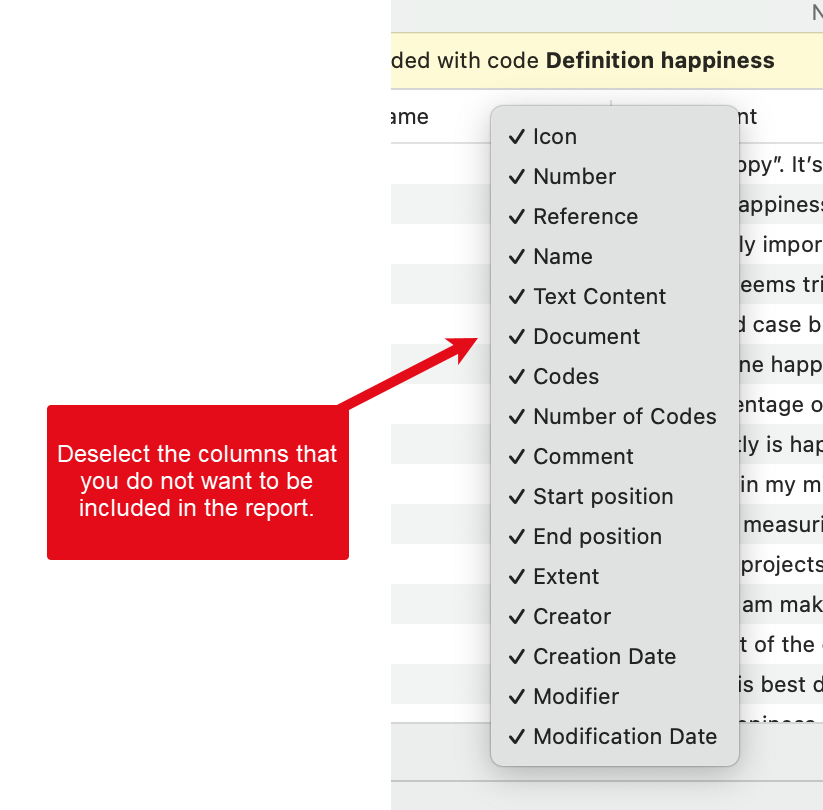
Para crear, por ejemplo, un informe que contenga todas las citas de un código, abra el Administrador de citas y seleccione un código o una categoría cuyas citas desee exportar.
Seleccione el botón Exportar y desde allí Exportar como hoja de cálculo:
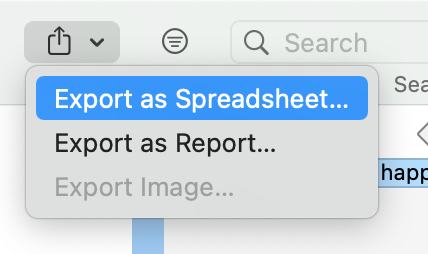
Se abre el cuadro de diálogo de archivo. Seleccione una ubicación donde desee guardar el archivo. Cambie el nombre predeterminado del archivo para reflejar lo que está exportando, por ejemplo, el nombre del código, grupo de códigos o categoría. Si desea abrir el informe de inmediato, seleccione Abrir en Numbers (Excel)
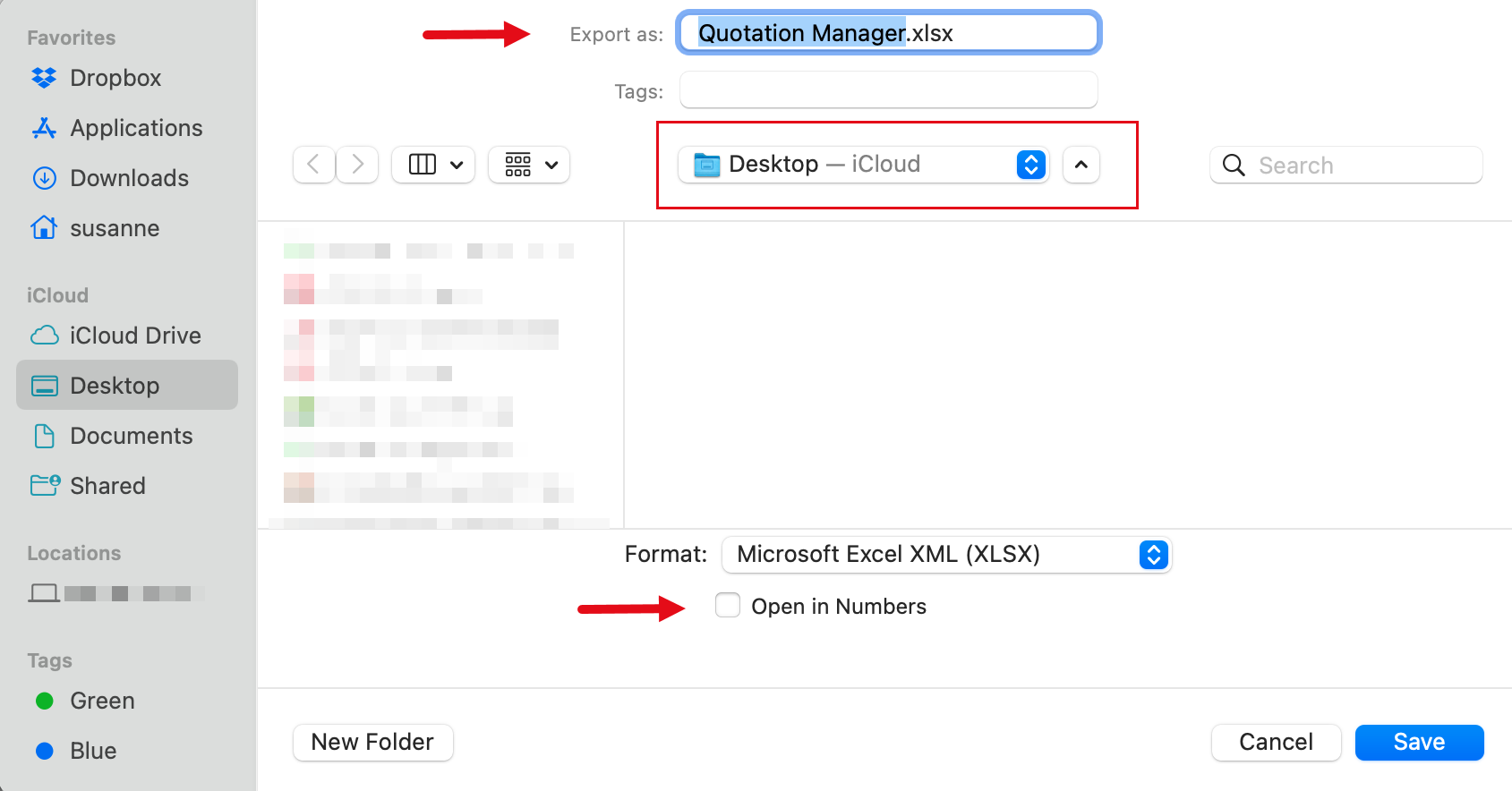
Tan pronto como haga clic en Guardar, se crea el informe. A continuación se muestra un informe de ejemplo:
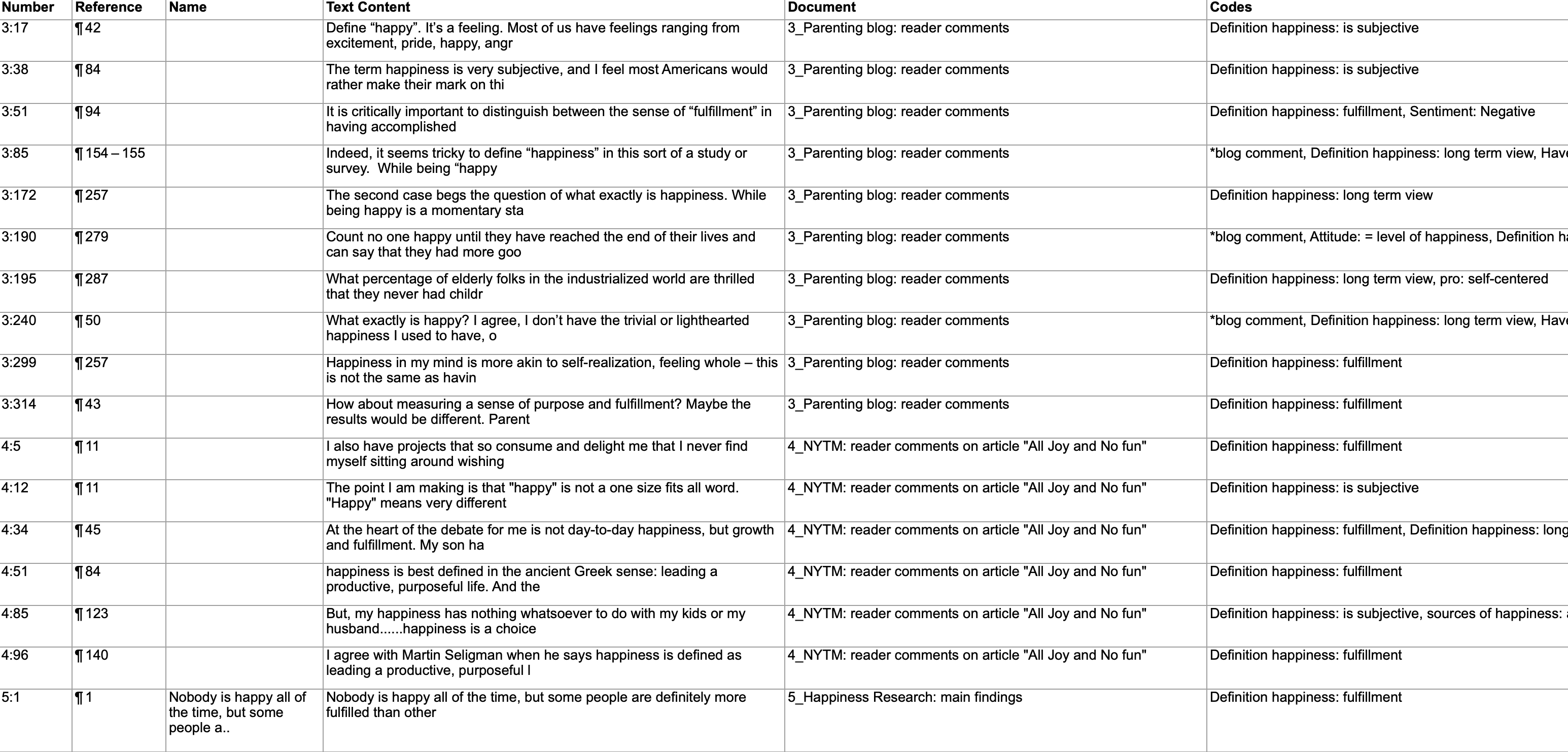
Ejemplos de informes
Todas las citas de uno o varios códigos (informe de Excel)
Abra el Administrador de citas. Seleccione uno o varios códigos en el área de filtro de la izquierda. Para seleccionar varios códigos, mantenga presionada la tecla cmd.
Haga clic en el botón Exportar y seleccione Exportar como hoja de cálculo.
ATLAS.ti exporta todas las columnas que se ven en la "Vista detallada". La vista predeterminada es "Previsualización pequeña". Para cambiar esto, haga clic en el botón Modo de vista. Si hace clic derecho en el encabezado de una columna, puede seleccionar qué columnas se muestran.
Todas las citas de uno o varios códigos (informe de texto)
Abra el Administrador de códigos. Seleccione uno o varios códigos. Para seleccionar varios códigos, mantenga presionada la tecla cmd.
Haga clic en el botón Exportar y seleccione Exportar como informe.
Se ve una previsualización como la que se muestra a continuación. Para crear un informe con "todas las citas de los códigos seleccionados", seleccione Citas y la opción Contenido del subárbol. Si también desea exportar el comentario de cada código, seleccione Comentarios como se muestra en el ejemplo a continuación.

Una vez que el informe tenga el aspecto deseado, haga clic en Guardar o Imprimir.
Informe: documentos y sus códigos
Abra el Administrador de documentos y seleccione todos los documentos que desee exportar con sus códigos.
Haga clic en el botón Exportar y seleccione Exportar como informe.
En la ventana de previsualización, seleccione Códigos y posiblemente otras opciones. Véase la imagen a continuación.
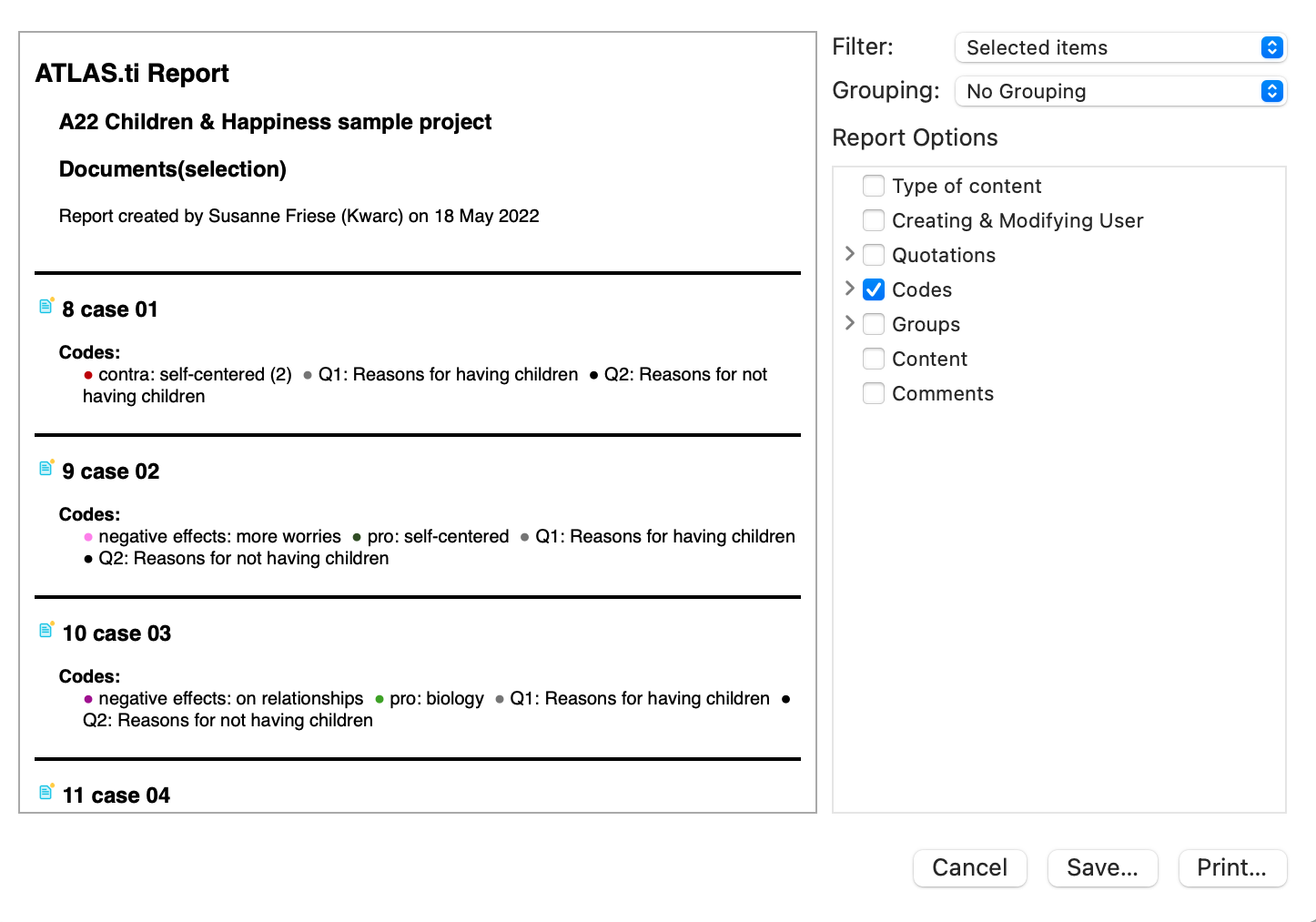
Una vez que el informe tenga el aspecto deseado, haga clic en Guardar o Imprimir.
Informe: para datos multimedia (Excel)
Si ha aprovechado el nivel de citas al trabajar con datos multimedia y ha reemplazado el nombre de cita predeterminado con resúmenes de lo que se puede ver o escuchar en las citas multimedia, así es como se crea un informe útil:
Seleccione citas multimedia en el Administrador de citas.
inst Haga clic en el botón Exportar y seleccione Exportar como hoja de cálculo.
El informe mostrará un resumen de todos los títulos creados para sus segmentos de imagen, audio o video (nombre), los comentarios escritos y los códigos aplicados. Además, proporciona la posición exacta dentro del archivo multimedia.

Informe: para datos multimedia (informe de texto)
inst Comience como se describe anteriormente seleccionando citas multimedia en el Administrador de citas. Luego haga clic en el botón Exportar y seleccione Exportar como informe.
En la ventana de previsualización, seleccione Comentarios y posiblemente otras opciones como Códigos, si desea ver qué códigos se han aplicado a una cita. Véase la imagen a continuación.
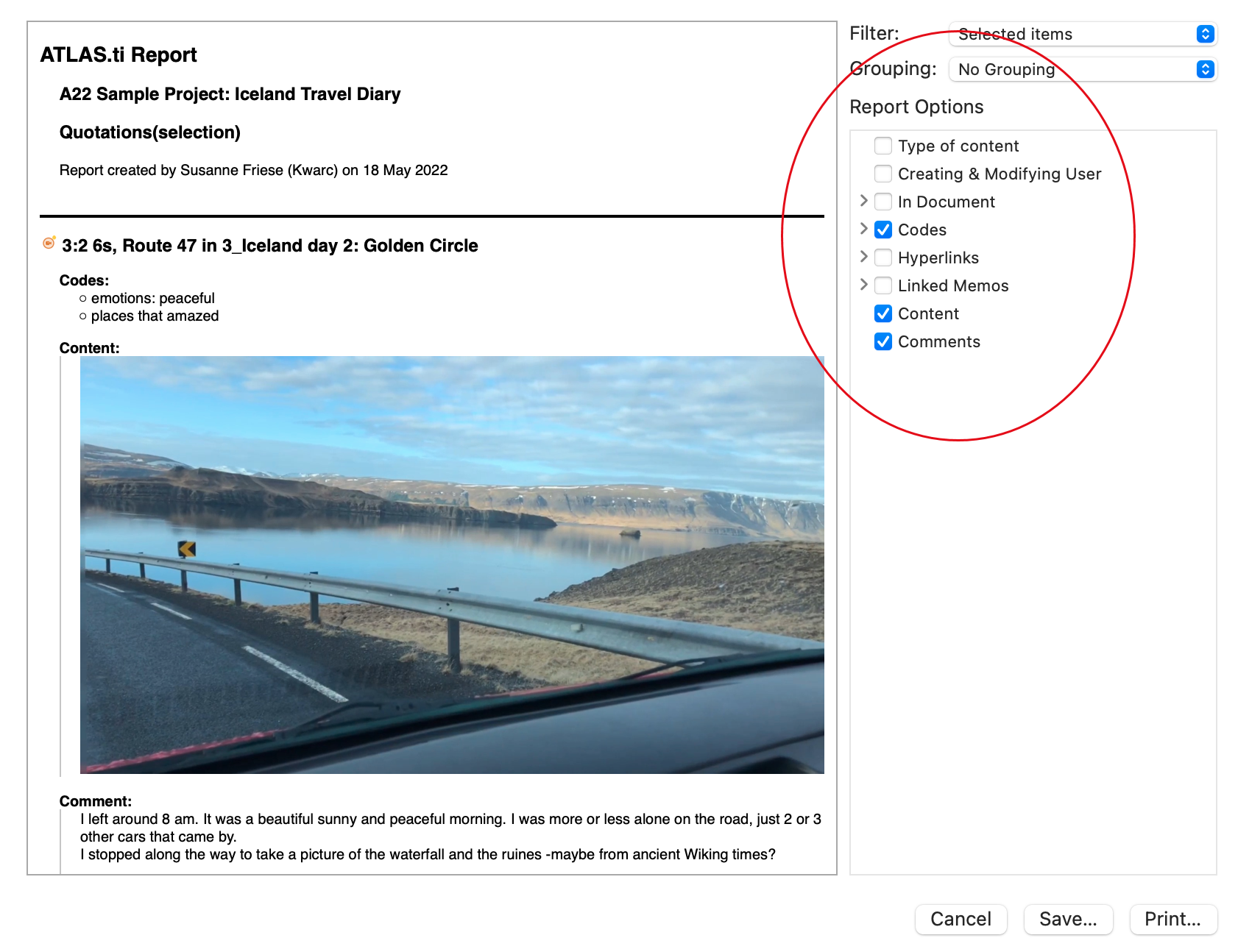
Una vez que el informe tenga el aspecto deseado, haga clic en Guardar o Imprimir.
Imprimir documentos con margen
Si desea imprimir un documento tal como aparece en pantalla, incluida el área de margen, seleccione la opción Imprimir en la cinta de opciones del documento.
A continuación se abre el siguiente cuadro de diálogo:
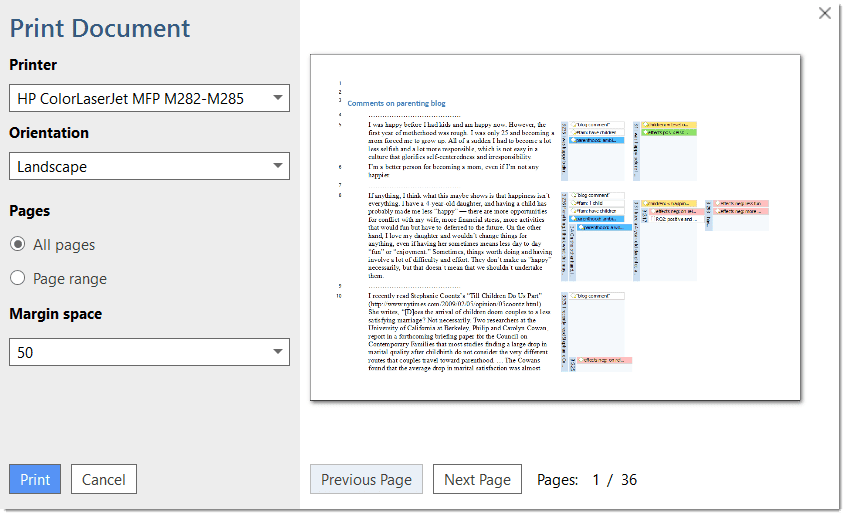
Impresora: Seleccione si desea enviar la salida a una impresora o guardarla como documento PDF.
Orientación: La selección predeterminada es "Horizontal", ya que probablemente sea la mejor opción para ver el documento y todos los códigos en el área de margen.
Espacio de margen: En "Espacio de margen" se puede ajustar el ancho del margen si se necesita más o menos espacio.
Páginas: Se pueden imprimir todas las páginas o un rango de páginas.
Con los botones "Página anterior" y "Página siguiente" se puede previsualizar todas las páginas.
La opción imprimir con margen está disponible para documentos de texto, PDF e imagen.
Informes predefinidos
Los informes predefinidos son esencialmente un atajo para crear informes de texto o PDF desde los administradores. Encontrará una entrada de menú Generar informe en el menú principal para Documento, Cita, Código, Memo y Red.
Después de seleccionar una opción, aparece la misma ventana que al seleccionar la opción Exportar como informe en los administradores, tal como se describe en Crear informes. La única diferencia es que las opciones adecuadas ya han sido seleccionadas previamente. Se pueden agregar más opciones al informe.
Para documentos
Para las citas, se dispone de los siguientes informes predefinidos:
- Documentos y grupos: Un informe que contiene todos los documentos, su tipo y los grupos de los que son miembros.
- Grupos de documentos y miembros: Un informe que contiene todos los grupos de documentos y sus miembros.
Para citas
Para las citas, se dispone de los siguientes informes predefinidos:
- Citas por documento: Un informe que contiene todas las citas con su contenido y comentarios, incluido el nombre del documento.
- Citas por códigos: Un informe que contiene todas las citas con su contenido, incluido el nombre del documento para cada código.
- Hipervínculos con comentarios: Un informe que contiene todos los hipervínculos. Se incluyen el ID de cita, la referencia, el nombre de la cita y del documento tanto para la cita de origen como para la de destino, y la relación que las vincula.
Para códigos
Para los códigos, se dispone de los siguientes informes predefinidos:
-
Libro de códigos: Un informe que contiene todos los códigos y sus comentarios. Si desea agregar un libro de códigos al apéndice de una tesis o un informe, se recomienda usar la opción de hoja de cálculo.
-
Códigos por documentos: Un informe que contiene todos los códigos y sus comentarios, ordenados por los documentos en que aparecen.
-
Grupos de códigos y miembros: Un informe que contiene todos los grupos de códigos y sus miembros.
Para memos
Para los memos, se dispone de los siguientes informes predefinidos:
- Memos con contenido: Crea un informe que contiene todos los memos, incluidos el usuario que los creó y modificó, el contenido y el comentario.
- Memos con contenido y citas vinculadas: Crea un informe que contiene todos los memos, incluidos el usuario que los creó y modificó, el contenido, el comentario y todas las citas vinculadas (ID, referencia, nombre y nombre del documento). También se puede agregar el contenido de la cita.
- Memos y grupos: Un informe que contiene todos los grupos de memos y sus miembros.
- Vínculos de memos: Un informe que contiene una lista de vínculos entre memos y códigos.
Para redes
Para las redes, se dispone de los siguientes informes predefinidos:
- Vínculos código-código con comentarios: Crea un informe que contiene una lista de vínculos entre códigos, incluidos el nombre de la relación y los comentarios.
Exportación de datos
ATLAS.ti ofrece diversas formas de exportar sus datos para su uso en otros programas.
-
un archivo Excel para su uso en otros programas estadísticos como R, STATA, etc.
-
una exportación de todos los documentos que se han agregado a un proyecto
-
su proyecto en formato XML para un uso personalizado (solo Mac)
Exportación de documentos
Puede exportar todos los documentos que haya agregado a un proyecto de ATLAS.ti.
-
Los archivos PDF y multimedia (audio, video, imágenes) se exportan en su formato original.
-
Los documentos de texto se exportan como archivos Word (docx). El formato del documento exportado puede diferir del original, ya que todos los documentos de texto se convierten a HTML cuando se importan.
Para exportar documentos:
Abra el Administrador de documentos y seleccione todos los documentos que desea exportar.
En el menú principal, seleccione Documento > Exportar > Documentos.
Exportación de datos para análisis estadístico posterior
ATLAS.ti está diseñado principalmente para apoyar los procesos de razonamiento cualitativo. Sin embargo, especialmente con grandes cantidades de datos, a veces es útil analizar los datos mediante enfoques estadísticos. ATLAS.ti puede exportar sus datos en forma de archivo de sintaxis para SPSS®, y un formato Excel genérico que puede importarse en programas como R, SAS, STATA y también SPSS.
Los componentes básicos de la estadística son los casos y las variables. La función de exportación estadística en ATLAS.ti trata los códigos como variables y los segmentos de datos (citas) como casos.
La noción de «caso» aquí es bastante detallada y difiere de la comprensión habitual de este término. Normalmente, los casos en la investigación cualitativa hacen referencia a personas, entrevistas o documentos. Optamos por tratar la unidad más pequeña como un caso para la exportación estadística, a fin de garantizar que no se pierda ningún dato. La información más amplia, p. ej., a qué documento o grupo de documentos pertenece una cita, se codifica en las diversas variables.
A diferencia del tratamiento dicotómico de los códigos dentro de ATLAS.ti, es posible utilizar los códigos para análisis estadístico posterior como variables ordinales o de escala de intervalo mediante el uso de una convención específica de nomenclatura de códigos.
Códigos escalados frente a dicotómicos
Dentro de ATLAS.ti, un código siempre es dicotómico, porque o bien hace referencia a una cita determinada («1»), o no lo hace («0»). Cada caso (= cita) puede, con respecto a los códigos, describirse como un vector de ceros y unos. El concepto de códigos/variables escalados requiere una sintaxis especial.
Si, por ejemplo, desea codificar tres niveles diferentes de evaluación de algo: muy bueno, bueno, ni bueno ni malo, malo, muy malo, es necesaria una convención de nomenclatura especial (nombre%valor) para que ATLAS.ti identifique los códigos escalados de los dicotómicos. Al codificar los datos, la categoría de código debe verse de la siguiente manera:
EVALUACIÓN
- evaluacion%1 muy malo
- evaluacion%2 malo
- evaluacion%3 ni bueno ni malo
- evaluacion%4 bueno
- evaluacion%5 muy bueno
Esta notación permite al sistema construir una variable a partir de todos los códigos con el mismo prefijo. El nombre de la variable será «evaluacion», y los valores para esta variable son:
- 1 muy malo
- 2 malo
- 3 ni bueno ni malo
- 4 bueno
- 5 muy bueno
En lugar del % como separador, también puede elegir un separador diferente. En ese caso, deberá indicarlo al preparar el archivo de sintaxis SPSS.
Puede usar valores de cadena o numéricos; todo lo que sigue al símbolo especial se interpreta como un valor.
Tenga en cuenta que los códigos ordinales solo tienen significado en el contexto del programa estadístico que está utilizando. Dentro de ATLAS.ti, los códigos con diferentes valores se tratan como cualquier otro código: como 0 o 1: ha sido aplicado o no ha sido aplicado.
No asigne más de un valor de variable escalada a la misma cita. Aunque ATLAS.ti permite adjuntar un número arbitrario de códigos a una cita, esto no tendría mucho sentido con valores mutuamente excluyentes de variables escaladas. Si lo hace, el generador de SPSS simplemente ignorará los valores adicionales después de procesar el primero que encuentre para una cita determinada. Dado que no se puede garantizar qué valor se detectará primero, esto muy probablemente producirá resultados impredecibles.
Exportación de sintaxis SPSS
ATLAS.ti puede exportar sus datos codificados en forma de un archivo de sintaxis SPSS como archivo de texto ASCII sin formato. Esto le permite modificar la sintaxis antes de ejecutarla en SPSS.
Al transformar sus datos en números, los códigos y grupos de códigos se convierten en variables y todas las citas se convierten en casos. Variables adicionales como números de documentos, grupos de documentos y tipos de documentos que indican a qué pertenece una cita y los grupos de documentos le permiten agregar sus datos en SPSS.
Crear un archivo de sintaxis
En el menú principal, seleccione Proyecto > Exportar > Archivo de sintaxis SPSS.
Se abre la ventana de generación de trabajo SPSS. Dispone de las siguientes opciones:
-
Usar archivo separado: Cuando está marcada, la matriz de datos se escribe en un archivo separado. Esto es obligatorio si el tamaño de la matriz supera un cierto tamaño. SPSS no puede manejar conjuntos de datos grandes dentro de un archivo de sintaxis. Para proyectos de tamaño normal, deje esta opción sin marcar.
-
Especifique el nombre del conjunto de datos. Este nombre se usa como nombre de archivo y como referencia FILE en la sección DATA LIST. Solo necesita ingresar un nombre aquí si genera archivos de datos separados.
-
Crear un archivo de datos nuevo durante la siguiente ejecución puede desmarcarse si los datos no han cambiado desde la última vez que se creó. Esto puede ahorrar algo de tiempo de procesamiento.
-
Incluir el autor de la cita. Marque esta opción si desea exportar una variable adicional que indica el autor de cada cita. Esto es útil, por ejemplo, si desea usar SPSS para calcular la fiabilidad entre codificadores.
-
El separador de valores es % por defecto, pero puede cambiarse a otro. Consulte Convención de nomenclatura para códigos escalados.
-
Crear sección de tareas. Active esta opción si desea que se incluyan plantillas para procedimientos al final del archivo de sintaxis.
-
Crear instrucción SAVE OUTFILE. Active esta opción si desea que SPSS guarde los datos como archivo *.sav después de ejecutar el archivo de sintaxis.
Especifique todas las propiedades deseadas y haga clic en Exportar SPSS.
Ahora puede ejecutar el archivo en SPSS, o realizar algunos cambios en el archivo de sintaxis antes de ejecutarlo.
Explicación del archivo de sintaxis
La salida del generador de SPSS es un archivo de sintaxis SPSS completo que contiene definiciones de variables, opcionalmente la matriz de datos y algunas declaraciones de trabajos predeterminadas:
Las ETIQUETAS DE VARIABLE se toman de los nombres de códigos y grupos de códigos.
Las ETIQUETAS DE VALOR para las variables creadas a partir de códigos son:
-
Sí (1) - el código está asignado
-
No (0) - el código no está asignado
Cada caso (cita) se describe por los códigos que están adjuntos a él, el documento, la posición en el documento (posición de inicio y fin), autor, tipo de medio y fecha de creación.
Posiciones de inicio y fin
Hay dos variables para la posición de inicio (SY y SX) y dos variables para la posición de fin (EY y EX) de una cita. Dependiendo del tipo de medio, se usan para diferentes coordenadas de inicio y fin.
| Tipo de dato | SY (inicio) | SX (inicio) | EY (fin) | EX (fin) |
|---|---|---|---|---|
| Texto (texto enriquecido) | párrafo | Carácter de columna, basado en cita | párrafo | Carácter de columna, basado en cita |
| página | recuento de caracteres, basado en página | página | recuento de caracteres, basado en página | |
| Audio | --- | milisegundos | --- | milisegundos |
| Video | --- | milisegundos | --- | milisegundos |
| Imagen | SX y SY indican la posición de la esquina superior izquierda de la imagen | EX y EY indican la posición de la esquina inferior derecha de la imagen | ||
| Geo | --- | --- | --- | --- |
Fecha de creación
La fecha de creación se muestra en formato de marca de tiempo Unix. Puede convertirla en tiempo legible por personas usando un convertidor, por ejemplo: https://www.epochconverter.com/
Etiquetas de variables
Un ejemplo:
VARIABLE LABELS D 'Document'.
VARIABLE LABELS QU 'Q-Index'.
VARIABLE LABELS SY 'Start y-Pos'.
VARIABLE LABELS SX 'Start x-Pos'.
VARIABLE LABELS EY 'End y-Pos'.
VARIABLE LABELS EX 'End x-Pos'.
VARIABLE LABELS TI 'Creation Date'.
VARIABLE LABELS C1 'Audio'.
VARIABLE LABELS C2 'just a name'.
VARIABLE LABELS C3 'Evaluation'.
VARIABLE LABELS C4 'Buddha'.
VARIABLE LABELS C5 'Code name with more than 40 characters'.
VARIABLE LABELS C6 'Fish'.
VARIABLE LABELS C7 'Geo Code'.
VARIABLE LABELS C8 'Octopus'.
VALUE LABELS C1 to C2 1 'YES' 0 'NO'.
VALUE LABELS C3 0 'NO' 1 'bad' 2 'good' 3 'not so good'.
VALUE LABELS C4 to C8 1 'YES' 0 'NO'.
VARIABLE LEVEL C3 (ORDINAL).
Declaración de tipo de documento.
IF (D = 5) MediaType = 1.
IF (D = 4) MediaType = 2.
IF (D = 6) MediaType = 3.
IF (D = 1) MediaType = 4.
IF (D = 3) MediaType = 5.
IF (D = 2) MediaType = 6.
VALUE LABELS
- 1 'text'
- 2 'PDF'
- 3 'graphic'
- 4 'audio'
- 5 'video'
- 6 'geo'
Tratamiento de los grupos de códigos
Los grupos de códigos en los trabajos SPSS cuentan cuántos de los códigos del grupo de códigos se han asignado a la cita.
Los grupos de códigos se denominan: CG1, CG2, etc.
Cálculo: COMPUTE CG1 = C10 + C11 + C12 + C13 + C14 + C15.
VARIABLE LABELS CG1 'name of code group'.
Los códigos escalados se ignoran en el cálculo de las variables de grupos de códigos. Consulte Exportación para análisis estadístico posterior.
Tratamiento de los grupos de documentos
Para cada caso (= cita) existe una variable de documento y de grupo de documentos. Si el documento al que pertenece una cita también forma parte de un grupo de documentos, el valor de la variable del grupo de documentos es 1.
Cálculo: COMPUTE DG1 = 0. IF (D = 5 or D = 4) DG1 = 1.
VARIABLE LABELS DG1 'DG_Document group name'.
Exportación genérica para análisis estadístico posterior
Si utiliza programas estadísticos como SAS, STATA o R, o no desea ejecutar un archivo de sintaxis en SPSS, puede crear una exportación genérica. El formato genérico debe importarse usando la opción de importación de Excel del programa que esté utilizando.
Para preparar una exportación genérica, seleccione Proyecto > Exportar > Datos estadísticos (XLSX) en el menú principal.
El archivo exportado contiene los siguientes datos:
-
CASENO: cada cita es un caso
-
D: número de documento
-
Nombre del documento: nombre del documento
-
Tipo de medio: tipo de documento
-
quote_start: posición de inicio de una cita de texto
-
quote_end: posición de fin de una cita de texto
-
start_time: posición de inicio de
-
end_time: posición de fin de una cita de audio o video
-
SY / SX / EY / EX: coordenadas de una cita de imagen
-
DG_name: cita que aparece en un documento del grupo de documentos
-
código: asignado / no asignado al código
-
CG_name: asignado / no asignado a un código del grupo de códigos
Para importar los datos, por ejemplo, a RStudio, seleccione Archivo/Importar conjunto de datos en RStudio.
QDPX - Intercambio universal de datos y proyectos

El formato de datos QDPX permite el intercambio completo de proyectos con otros paquetes CAQDAS. Este es un gran paso hacia un nuevo grado de libertad en la investigación y abre nuevas dimensiones para todos los practicantes del análisis cualitativo de datos.
"Estamos muy emocionados de ver que — después de quince años en los que ATLAS.ti fue el único fabricante en defender de manera constante el intercambio universal de datos — otros desarrolladores de software están empezando a reconocer el beneficio de no tener los datos de los usuarios como rehenes.
ATLAS.ti respondió tempranamente a los deseos de los investigadores ofreciendo un formato de exportación abierto e independiente de la aplicación para uso universal. Este compromiso de larga data con la apertura académica y el libre flujo de ideas está siendo ahora reconocido como un valor importante en sí mismo.
Estoy convencido de que poder mover proyectos sin problemas entre diferentes aplicaciones será de gran beneficio para la comunidad investigadora. Estamos extremadamente orgullosos de haber sido pioneros de este movimiento, y esperamos con entusiasmo los muchos avances que traerá." Thomas Muhr, 18 de marzo de 2019.
¿Qué es QDPX?
ATLAS.ti es miembro fundador de la Rotterdam Exchange Format Initiative (REFI), el consorcio que diseña y rige el estándar de interoperabilidad QDPX. En esencia, QDPX es un formato de datos estructurado basado en XML que no solo permite el almacenamiento a largo plazo e independiente del producto y el archivo de proyectos de investigación cualitativa, sino que también apunta al intercambio de proyectos entre diferentes productos de software.
ATLAS.ti ha sido durante mucho tiempo un defensor de la idea del intercambio universal de datos de investigación cualitativa entre diferentes aplicaciones y fue el primer fabricante en introducir una exportación completa de proyectos XML en su software ya en 2004. La idea de una exportación universal de datos siempre fue una característica muy obvia para nosotros, teniendo en cuenta el inmenso valor que se agrega a los datos que han sido procesados, analizados y estructurados en el proceso de análisis cualitativo.
En los últimos quince años, hemos demostrado a través de muchas aplicaciones ejemplares el valor adicional que tienen los datos cuando se usan y reutilizan mediante la transformación directa en formatos de presentación orientados visualmente, como páginas web, informes imprimibles o libros electrónicos, u otros formatos de datos como .rtf, csv o sql. A pesar del amplio espectro de estas aplicaciones de ejemplo, apenas rozan la superficie de los usos poderosos adicionales que aún serán posibles en el futuro.
El beneficio más inmediato de QDPX radica obviamente en el hecho de que permite a los usuarios de varios productos de software QDA migrar sus proyectos de investigación entre diferentes paquetes. A medida que más fabricantes se unan a la iniciativa e implementen el nuevo estándar, su utilidad para los investigadores sin duda crecerá exponencialmente.
¿Por qué QDPX es beneficioso para usted?
A continuación se presentan algunos argumentos generales a favor de QDPX y descripciones de algunos de sus beneficios prácticos:
- Porque no me gusta estar vinculado a una solución QDAS específica, especialmente si tiene problemas; no quiero que mis datos sean tomados como rehenes. La interoperabilidad me facilita la decisión de compra porque me preocupa menos quedar atrapado en algo que no me gusta.
- Ahora puedo cambiar a otro software por razones ajenas a mi control (p. ej., financiamiento, nuevo empleador, nuevos mandatos).
- Los datos y la codificación pueden ser los mismos, pero quiero usar diferentes tipos de resultados/representación/visualización que están disponibles en un programa pero no en otro.
- Estoy trabajando en mi tesis doctoral y quiero usar el software XY. Sin embargo, los miembros de mi comité están más familiarizados con el software Z. No hay problema. Simplemente transferiré mis datos en algunas fases clave, para que puedan entender y comentar la base de datos, o los resultados e informes. Además, podría ser capaz de demostrar por qué el software XY fue la mejor opción para mi proyecto.
- Como investigador que se ha familiarizado con un paquete CAQDAS particular como resultado del producto disponible a través de una licencia de sitio en mi institución, necesito poder continuar trabajando con mis datos de investigación en un producto diferente si me traslado a una institución que tiene una licencia de sitio diferente.
- Los organismos de financiamiento valoran cada vez más las propuestas que involucran múltiples socios de investigación. Esto plantea problemas para los usuarios que trabajan en diferentes instituciones y que están familiarizados con diferentes productos o tienen acceso a ellos. Como investigador, por lo tanto, necesito poder intercambiar mi análisis entre mi producto y los de mis colegas investigadores. Esto facilitará significativamente la investigación colaborativa. Por ejemplo, quiero colaborar con equipos en tres países diferentes; pero todos son expertos en un programa diferente. En mi propuesta de subvención quiero poder decir que esto no es un problema y que es parte de la razón por la que debería ser financiado.
- Cada paquete QDAS tiene sus propias fortalezas particulares. Los usuarios a menudo necesitan poder realizar una tarea analítica que no está soportada por su producto elegido, o que está habilitada de una manera más apropiada para sus necesidades en otro producto. Como investigador, poder cambiar a un producto alternativo para realizar una tarea específica facilitaría una investigación de mayor calidad.
Para más información sobre el estándar, consulte aquí.
Exportar un proyecto en formato QDPX
En el menú principal, seleccione Proyecto > Exportar > Proyecto REFI-QDA (QDPX).
Exportar un proyecto en formato XML
Si crea un archivo de salida XML, puede ser leído por otras aplicaciones que admitan XML. Una ventaja principal es que la aplicación puede definir de forma autónoma y completamente desvinculada de cualquier información de visualización contenida en el documento qué partes de la estructura se deben mostrar y cómo debe verse la presentación.
Para crear una versión XML de su proyecto:
Seleccione Proyecto > Exportar > XML en el menú principal.
¿Qué es XML?
XML, el Lenguaje de Marcado Extensible, es un estándar potente para el intercambio de información entre aplicaciones y ha sido utilizado por ATLAS.ti desde la versión 4.2. En caso de que no sepa qué es XML, la explicación breve es que XML, de manera similar a HTML, es un lenguaje de marcado de documentos.
XML se centra en estructurar la información. La información estructurada contiene tanto contenido (palabras reales, imágenes, etc.) como, generalmente, alguna indicación del papel que desempeña ese contenido (por ejemplo, el contenido de texto dentro de un «encabezado» tiene un significado diferente al contenido en una «nota al pie», el contenido en un «pie de foto» difiere del contenido en una «tabla de base de datos», etc.).
Casi todos los documentos tienen alguna estructura, y un lenguaje de marcado es un mecanismo para identificar esta estructura en un documento. La especificación XML define una forma estándar de agregar marcado a los documentos.
XML frente a HTML: una pequeña charla técnica
XML es la abreviatura de eXtensible Markup Language (Lenguaje de Marcado Extensible). Esta es ya una descripción bastante útil cuando se compara con su «competidor» o predecesor, HTML, abreviatura de HyperText Markup Language (Lenguaje de Marcado de Hipertexto).
El término crucial es «extensible», NO «extendido». HTML fue concebido para permitir que documentos e información de considerable complejidad se intercambiaran entre diferentes tecnologías, sistemas operativos, navegadores, etc. También estaba pensado como un lenguaje que describe la estructura lógica de los documentos.
Si observa el código HTML (haga clic derecho y seleccione «Ver código fuente» al navegar por cualquier página web), le resultará difícil identificar el contenido en el «ruido» caótico producido por etiquetas que representan tablas, marcos, botones, reglas, fuentes, imágenes, sangría, etc.
Tanto HTML como XML son descendientes de un lenguaje mucho más potente (y menos comprensible), SGML, el Standard Generalized Markup Language (Lenguaje de Marcado Generalizado Estándar). Lo que XML comparte con este último es que puede definir sus propios lenguajes nuevos, algo que HTML no permite. Mientras que HTML es en sí mismo un lenguaje prescrito, XML es un metalenguaje para definir nuevos lenguajes.
HTML no tiene una separación clara entre contenido y presentación. Con un conjunto fijo de etiquetas, no hay forma de marcar el contenido del documento de manera significativa.
Si alguna vez ha visto el código fuente de una página web codificada en HTML, puede reconocer fácilmente dos de las principales características de XML que los distinguen de HTML:
La presencia de etiquetas (p. ej., <MEMO>, <SPEECH TURN>) que no están disponibles en el conjunto fijo de etiquetas HTML (donde las nuevas etiquetas serían propietarias o al menos desviaciones de los estándares). Las etiquetas utilizadas en un archivo XML representan SUS datos sin invalidar ningún estándar. A continuación se muestra un archivo XML sin procesar.
La ausencia de información relacionada con la presentación (visualización, diseño) (tablas, fuentes, imágenes, reglas, etc.)
A continuación puede ver una versión XML de una sección de entrevista con información adicional:
<Trans version="1" trans_method="LING22" version_date="990120" audio_filename="au.wav" xml:lang="DE">
<Speakers>
<Speaker id="I" name="Interviewer"/>
<Speaker id="B" name="Herr Schultz" dialect="bavarian"/>
</Speakers>
<Turn speaker="I" tape_pos="2010">
Ja.
</Turn>
<Turn speaker="B" tape_pos="2314">
Wars doch eigentlich, ja da wars doch
glaub ich erst ein oder zwei Tage, oder
vielleicht einen Tag.
</Turn>
</Trans>
Si le interesa aprender más sobre XML, hay innumerables fuentes disponibles en línea.
Apéndice
La siguiente información ha sido recopilada para el apéndice:
-
Recursos útiles: Aquí encontrará vínculos al sitio web de ATLAS.ti, el servicio de asistencia, tutoriales en video, manuales en formato PDF para descargar, el blog de investigación y publicaciones sobre el uso de ATLAS.ti, incluyendo un artículo del Prof. Krippendorff sobre la implementación del acuerdo intercodificadores en ATLAS.ti.
Configuración de idioma
ATLAS.ti reconoce el idioma de su sistema operativo y establecerá el idioma correspondiente. Actualmente, están disponibles los siguientes idiomas de interfaz de usuario:
- Inglés
- Alemán
- Español
- Portugués
- Chino simplificado
Para todos los demás idiomas del sistema operativo que no se enumeran anteriormente, el idioma predeterminado es el inglés.
Requisitos del sistema
Los requisitos del sistema son:
Hardware: Cualquier Mac con CPU Intel o Apple Silicon y al menos 4 GB de RAM; se recomienda encarecidamente SSD. Sistemas operativos: macOS 10.15 "Catalina" o superior.
Para obtener mejores resultados en el procesamiento de lenguaje natural, ATLAS.ti puede utilizar opcionalmente modelos de aprendizaje automático más grandes, que requieren al menos 8 GB de RAM.
Opciones
Preferencias de la aplicación
Tiene las siguientes opciones:
- Cambiar el idioma de visualización
- Cambiar la ubicación donde ATLAS.ti almacena los datos. Consulte Cambiar de biblioteca.
- Administrar modelos para las herramientas de inteligencia artificial integradas. Consulte Reconocimiento de entidades nombradas y Análisis de sentimientos.
Preferencias del proyecto
Las siguientes configuraciones están disponibles:
- Puede especificar qué listas y administradores deben abrirse automáticamente al iniciar el programa
- Para las listas y el Explorador de proyectos puede especificar si deben abrirse anclados o flotantes, o si ATLAS.ti debe recordar su último estado.
- Para los Administradores puede especificar si deben abrirse anclados o flotantes, o si ATLAS.ti debe recordar su último estado.
- Para los archivos multimedia puede especificar si las vistas previas de documentos, citas o hipervínculos deben comenzar a reproducirse automáticamente.
- Al crear citas multimedia, una cita se crea inmediatamente al seleccionar un segmento de datos. Si prefiere crear citas manualmente, puede cambiar el comportamiento aquí.
Service Packs y parches - Actualización en vivo
Las actualizaciones del programa (parches y service packs) están disponibles periódicamente para actualizar su instalación. El programa descarga e instala estos service packs automáticamente.
Siempre que tenga derechos administrativos en su equipo, ATLAS.ti busca nuevos service packs al iniciar (esto requiere una conexión a Internet). Si se encuentra un nuevo service pack, se le informará y se le pedirá que lo instale.
Para actualizar ATLAS.ti manualmente, vaya a ATLAS.ti > Buscar actualizaciones en el menú principal.
Recursos útiles
La pantalla de bienvenida de ATLAS.ti contiene vínculos a manuales, proyectos de muestra y tutoriales en video. La sección de noticias le informa sobre los desarrollos actuales, las actualizaciones publicadas, artículos interesantes que hemos encontrado, casos de uso y nuestro boletín informativo.
El sitio web de ATLAS.ti
El sitio web de ATLAS.ti debe ser un lugar de visita habitual. Aquí encontrará información importante como tutoriales en video, documentación adicional de diversas funciones del software, anuncios de talleres, proveedores de servicios especiales y anuncios de service packs y parches recientes.
Obtener soporte
Desde dentro de ATLAS.ti, seleccione Ayuda > Recursos en línea / Contactar con soporte. O acceda al Centro de soporte directamente mediante la URL anterior.
Tutoriales en video
Si prefiere aprender mediante tutoriales en video, ofrecemos una variedad de videos que cubren aspectos tanto técnicos como metodológicos.
Tutoriales en video de ATLAS.ti
Proyectos de muestra
Puede descargar varios proyectos de muestra diferentes desde nuestro sitio web. Actualmente están disponibles proyectos en inglés y español. Los proyectos incluyen diferentes tipos de fuentes de datos:
- texto
- imagen
- video
- datos geográficos
.... y diferentes tipos de datos:
- transcripciones de entrevistas
- informes
- datos en línea
- datos de evaluación
- encuesta
- revisión de literatura
Puede utilizarlos para familiarizarse con ATLAS.ti o para fines de enseñanza. Cuando estén disponibles, también se proporcionan los datos sin procesar.
Manuales en PDF
Manual completo de ATLAS.ti y otra documentación.
Blog de investigación
El blog de investigación de ATLAS.ti desempeña un papel muy importante en el desarrollo y la consolidación de la comunidad internacional de usuarios. Consultores, académicos e investigadores publican artículos breves y prácticos que destacan funciones y procedimientos con el software, y recomiendan estrategias para incorporar ATLAS.ti de manera exitosa en un proceso de análisis de datos cualitativos. Le invitamos a enviar artículos breves que expliquen formas interesantes de aprovechar al máximo ATLAS.ti, así como describir cómo lo utiliza en su propia investigación. Para ello, contáctenos.
Acuerdo intercodificadores en ATLAS.ti por el Prof. Krippendorff
Hemos trabajado estrechamente con el Prof. Krippendorff en la implementación para hacer que el coeficiente alfa de Krippendorff original sea útil para el análisis de datos cualitativos. Esto requirió, por ejemplo, una extensión y modificación del cálculo matemático subyacente para tener en cuenta la codificación de valores múltiples.. Puede descargar un artículo escrito por el Prof. Krippendorff sobre la implementación de la familia de coeficientes alfa en ATLAS.ti.
Publicaciones
-
Friese, Susanne (2022). Role and Impact of CAQDAS Software for Designs in Qualitative Research. In Uwe Flick (ed). The SAGE Handbook of Qualitative Research Design. Chapter 19. London: Sage.
-
Friese, Susanne (2021).Grounded Theory Analysis and CAQDAS: A happy pairing or remodeling GT to QDA? In: Antony Bryant and Kathy Charmaz (eds.). The SAGE Handbook of Current Developments in Grounded Theory, 282-313. London: Sage.
-
Friese, Susanne (2019). Qualitative Data Analysis with ATLAS.ti. London: Sage. 3. edition.
-
Friese, Susanne (2019). Grounded Theory Analysis and CAQDAS: A happy pairing or remodelling GT to QDA? In: Antony Bryant and Kathy Charmaz (Eds.). The SAGE Handbook of Current Developments in Grounded Theory, 282-313. London: Sage.
-
Friese, Susanne (2018). Computergestütztes Kodieren am Beispiel narrativer Interviews. In: Pentzold, Christian; Bischof, Andreas & Heise, Nele (Hrsg.) Praxis Grounded Theory. Theoriegenerierendes empirisches Forschen in medienbezogenen Lebenswelten. Ein Lehr- und Arbeitsbuch, S. 277-309. Wiesbaden: Springer VS.
-
Friese, Susanne, Soratto, Jacks and Denise Pires (2018). Carrying out a computer-aided thematic content analysis with ATLAS.ti. MMG Working Paper 18-0.
-
Friese, Susanne (2016). Grounded Theory computergestützt und umgesetzt mit ATLAS.ti. In Claudia Equit & Christoph Hohage (Hrsg.), Handbuch Grounded Theory – Von der Methodologie zur Forschungspraxis (S.483-507). Weinheim: Beltz Juventa.
-
Friese, Susanne (2016). Qualitative data analysis software: The state of the art. Special Issue: Qualitative Research in the Digital Humanities, Bosch, Reinoud (Ed.), KWALON, 61, 21(1), 34-45.
-
Friese, Susanne (2016). CAQDAS and Grounded Theory Analysis. Working Papers WP 16-07
-
McKether, Will L. and Friese, Susanne (2016). Qualitative Social Network Analysis with ATLAS.ti: Increasing power in a blackcommunity.
-
Friese, Susanne & Ringmayr, Thomas, Hrsg (2016). ATLAS.ti User Conference proceedings: Qualitative Data Analysis and Beyond. Universitätsverlag TU Berlin. https://depositonce.tu-berlin.de/bitstream/11303/5404/3/ATLASti_proceedings_2015.pdf
-
Paulus, Trena M. and Lester, Jessica. N. (2021). Doing Qualitative Research in a Digital World. Thousand Oaks, CA: Sage.
-
Paulus, Trena M., Lester, Jessica. N. and Dempster, Paul (2013).Digital Tools for Qualitative Research. Thousand Oaks, CA: Sage.
-
Silver, Christina and Lewins, Ann (2014). Using Software in Qualitative Research. London: Sage.
-
Konopásek, Z. (2008). Making Thinking Visible with Atlas.ti: Computer Assisted Qualitative Analysis as Textual Practices. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 9(2).
-
Woolf,Nicholas H. and Silver, Christina (2018). Qualitative Analysis Using ATLAS.ti: The Five Level QDA Method. New York: Routledge.
Contacto
Enviar sugerencias
Nos interesa leer sus ideas y sugerencias. No dude en utilizarlo como una lista de deseos. Si bien no podemos conceder todos los deseos, conocer lo que necesita nos ayudará a mejorar continuamente el programa para satisfacer sus necesidades.
En el menú Ayuda, seleccione Enviar comentarios.