
Análisis de sentimientos
Tutorial en video: Análisis de sentimientos.
El análisis de sentimientos es la interpretación y clasificación de emociones (positivas, negativas y neutras) dentro de datos de texto mediante técnicas de análisis de texto.
Esta función está disponible para los siguientes idiomas:
- Inglés
- Alemán
- Español
- Portugués
- Francés
- Neerlandés
- Ruso
- Chino simplificado
Ejemplos de aplicación
- Identificar y catalogar un fragmento de texto según el tono que transmite.
- Comprender el sentimiento social hacia una marca, producto o servicio.
- Identificar el sentimiento de los encuestados hacia el tema que se debate en conversaciones y comentarios en línea.
- Analizar las evaluaciones de los estudiantes sobre clases, seminarios o programas de estudio.
El análisis de sentimientos funciona mejor con datos estructurados, como preguntas abiertas en una encuesta, evaluaciones, conversaciones en línea, etc.
Cómo realizar un análisis de sentimientos
Para abrir la herramienta, seleccione Código > Buscar y codificar > Análisis de sentimientos en el menú principal.
Seleccione los documentos o grupos de documentos que desea buscar y haga clic en Continuar.
Seleccione la unidad base para la búsqueda y la codificación:
- párrafos
- oraciones
Seleccione el tipo de sentimiento que desea codificar:
- positivo
- neutro
- negativo
ATLAS.ti propone etiquetas de subcódigo para cada sentimiento: Positivo / Neutro / Negativo. Si desea utilizar nombres diferentes, puede cambiarlos aquí.
Administrar modelos: Si desea mejorar sus resultados, puede descargar e instalar un modelo más completo.
Haga clic en Administrar modelos si desea instalar o desinstalar un modelo extendido.
Haga clic en Continuar para comenzar a buscar en los documentos seleccionados. En la siguiente pantalla se presentan los resultados de la búsqueda y puede revisarlos.
La página de resultados le muestra un Lector de citas que indica dónde se encuentran las citas al codificar los datos con el código propuesto. Si ya existe una codificación en la cita, también se mostrará.
Haciendo clic en el icono del ojo, puede alternar entre vistas previas pequeñas, medianas y grandes.
Puede codificar todos los resultados con uno de los códigos propuestos o con todos los códigos propuestos a la vez; o puede revisar cada segmento de datos y luego codificarlo haciendo clic en el más junto al nombre del código.
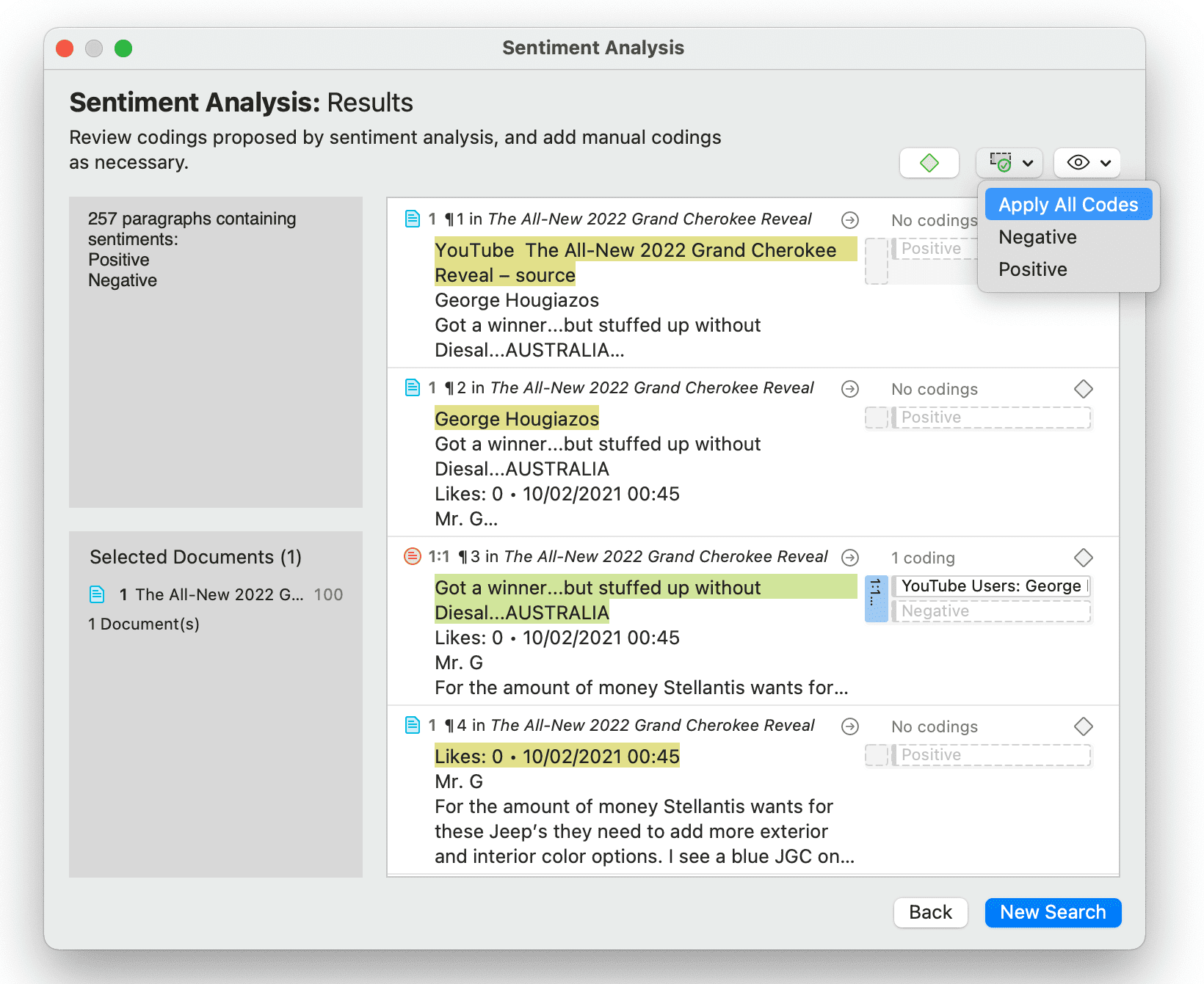
Según el área que haya seleccionado al principio, se codificará la oración o el párrafo.
El Diálogo de codificación habitual también está disponible para agregar o eliminar códigos.
El motor de búsqueda detrás del análisis de sentimientos
Utilizamos spaCy como nuestro motor de procesamiento del lenguaje natural. Puede encontrar información más detallada aquí.
Los datos de entrada se procesan en una cadena de procesamiento: paso a paso para mejorar el conocimiento derivado del paso anterior. Haga clic aquí para obtener más detalles.
El primer paso es un tokenizador para dividir un texto dado en partes significativas y reemplazar elipsis, etc. Por ejemplo, la oración:
"I should've known(didn't back then)." se tokenizará como: "I should have known ( did not back then )."
El tokenizador utiliza un vocabulario para cada idioma y asigna un vector a cada palabra. Este vector fue aprendido previamente mediante el uso de un corpus y representa un tipo de similitud de uso en el corpus utilizado. Haga clic aquí para obtener más información.
El siguiente componente es un etiquetador que asigna etiquetas de categoría gramatical a cada token y lexema si el token es una palabra. La secuencia de caracteres "mine" (en inglés), por ejemplo, tiene significados bastante diferentes dependiendo de si es un sustantivo o un pronombre.
Por lo tanto, no se usa simplemente una lista de palabras como referencia. En consecuencia, tampoco existe la opción de agregar sus propias palabras a una lista ni de ver la lista de palabras que se utiliza.
La cadena de procesamiento del análisis de sentimientos está entrenada con una variedad de textos que van desde discusiones en redes sociales hasta opiniones de personas sobre diferentes temas y productos. Utilizamos modelos preentrenados modificados o construidos desde cero, según el idioma.