
Métodos para probar la ICA
"Un coeficiente de acuerdo intercodificadores mide el grado en que se puede confiar en que los datos representen los fenómenos de interés analítico que se espera analizar en lugar de los fenómenos brutos" (Krippendorff, 2019).
ATLAS.ti ofrece actualmente tres métodos para probar el acuerdo intercodificadores:
-
Porcentaje de acuerdo simple
-
Índice de Holsti
-
Familia de coeficientes alpha de Krippendorff.
Todos los métodos pueden utilizarse con dos o más codificadores. Como la medida de porcentaje de acuerdo y el índice de Holsti no tienen en cuenta el acuerdo por azar, se recomiendan los coeficientes alpha de Krippendorff para informes científicos.
Porcentaje de acuerdo
El porcentaje de acuerdo es la medida más simple del acuerdo intercodificadores. Se calcula como el número de veces que un conjunto de valoraciones coincide, dividido por el número total de unidades de observación valoradas, multiplicado por 100.
Las ventajas del porcentaje de acuerdo son su sencillez de cálculo y su aplicabilidad a cualquier tipo de escala de medición. Veamos el siguiente ejemplo: hay diez segmentos de texto y dos codificadores solo necesitan decidir si un código es aplicable o no:
Ejemplo de codificación de dos codificadores
| Segmentos | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Codificador 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Codificador 2 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
1 = acuerdo, 0 = desacuerdo
Este es el cálculo:
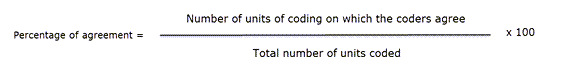
PA = 6 / 10
PA = 0,6 = 60%
Los codificadores 1 y 2 coinciden 6 de cada 10 veces, por lo que el porcentaje de acuerdo es del 60%.
Podría argumentarse que esto es bastante bueno. Sin embargo, este cálculo no tiene en cuenta el acuerdo por azar. Si los dos codificadores no leyeran los datos y simplemente codificaran los 10 segmentos de manera aleatoria, se esperaría que coincidieran en un cierto porcentaje de las veces por mera casualidad. La pregunta es: ¿cuánto supera ese 60% de acuerdo al acuerdo que se produciría por azar?
El acuerdo esperado por puro azar es del 56% = (9,6 + 1,6) / 20. Si le interesa el cálculo, consulte Krippendorff (2004, p. 224-226). El 60% de acuerdo ya no parece tan impresionante. En términos estadísticos, el rendimiento de los dos codificadores es equivalente a haber asignado 0 y 1 de forma arbitraria a 9 de los 10 segmentos, y solo 1 de los 10 segmentos está codificado de manera fiable.
Para calcular el porcentaje de acuerdo, puede agregar códigos individuales en lugar de dominios semánticos.
Índice de Holsti
El índice de Holsti (Holsti, 1969) es una variante de la medida de porcentaje de acuerdo para situaciones en las que los codificadores no codifican exactamente el mismo segmento de datos. Este es el caso cuando los codificadores establecen sus propias citas. Al igual que el porcentaje de acuerdo, el índice de Holsti tampoco tiene en cuenta el acuerdo por azar.
La fórmula del índice de Holsti es:
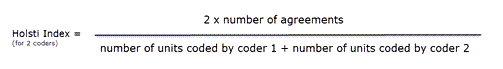
Los resultados del porcentaje de acuerdo y del índice de Holsti son iguales cuando todos los codificadores codifican los mismos segmentos de datos.
Para calcular el porcentaje de acuerdo, puede agregar códigos individuales en lugar de un dominio semántico, o utilizar dominios semánticos reales.
Kappa de Cohen
Reconocemos que la kappa de Cohen es una medida popular, pero hemos optado por no implementarla debido a las limitaciones identificadas en la literatura.
"Es bastante desconcertante por qué la kappa de Cohen ha sido tan popular a pesar de tanta controversia. Los investigadores comenzaron a señalar problemas con la kappa de Cohen hace más de tres décadas (Kraemer, 1979; Brennan y Prediger, 1981; Maclure y Willett, 1987; Zwick, 1988; Feinstein y Cicchetti, 1990; Cicchetti y Feinstein, 1990; Byrt, Bishop y Carlin, 1993). En una serie de dos artículos, Feinstein y Cicchetti (1990) y Cicchetti y Feinstein (1990) dieron a conocer las siguientes dos paradojas de la kappa de Cohen: (1) Un valor bajo de kappa puede darse con un acuerdo elevado; y (2) Las distribuciones marginales desequilibradas producen valores más altos de kappa que las distribuciones más equilibradas. Aunque las dos paradojas no se mencionan en libros de texto más antiguos (p. ej., Agresti, 2002), se presentan íntegramente como limitaciones de kappa en un libro de texto de posgrado reciente (Oleckno, 2008). Además de las dos paradojas mencionadas, Zhao (2011) describe doce paradojas adicionales de kappa y sugiere que la kappa de Cohen no es en absoluto una medida general de la fiabilidad entre evaluadores, sino una medida de fiabilidad bajo condiciones especiales que raramente se cumplen. Krippendorff (2004) sostiene que la kappa de Cohen no está cualificada como medida de fiabilidad en el análisis de fiabilidad, ya que su definición de acuerdo por azar se deriva de medidas de asociación debido a su supuesto de independencia entre evaluadores. Argumenta que en el análisis de fiabilidad los evaluadores deben ser intercambiables en lugar de independientes, y que la definición de acuerdo por azar debe derivarse de proporciones estimadas como aproximaciones a las proporciones verdaderas en la población de datos de fiabilidad. Krippendorff (2004) demuestra matemáticamente que el desacuerdo esperado de kappa no es una función de las proporciones estimadas a partir de los datos de la muestra, sino una función de las preferencias individuales de dos evaluadores por las dos categorías." (Xie, 2013).
Además, la kappa de Cohen solo puede utilizarse con 2 codificadores y asume un tamaño de muestra infinito. Consulte también el artículo en nuestro blog de investigación: Por qué la kappa de Cohen no es una buena opción.
Familia de coeficientes alpha de Krippendorff
La familia de coeficientes alpha ofrece diversas medidas que permiten realizar cálculos a diferentes niveles. Pueden utilizarse con más de dos codificadores, son sensibles a distintos tamaños de muestra y también pueden emplearse con muestras pequeñas.
Alpha binario
En el nivel más general, se puede medir si distintos codificadores identifican las mismas secciones de los datos como relevantes para los temas de interés representados por los códigos. Se tienen en cuenta todas las unidades de texto para este análisis, tanto los datos codificados como los no codificados.
En este nivel es posible, aunque no obligatorio, utilizar dominios semánticos. También es posible introducir un único código por dominio. Se obtiene un valor de alpha binario para cada código (o cada dominio semántico) incluido en el análisis, y un valor global para todos los códigos (o todos los dominios) del análisis.
El valor global de alpha binario puede ser el que se desee publicar en un artículo como valor general del acuerdo intercodificadores para el proyecto.
Los valores de cada código o dominio semántico ofrecen retroalimentación sobre qué códigos o dominios son satisfactorios en términos de acuerdo intercodificadores, y cuáles son interpretados de manera diferente por los distintos codificadores. Estos son los códigos o dominios que deben mejorarse y volver a probarse, con codificadores diferentes.
Si trabaja con citas predefinidas, el coeficiente binario será 1 para un dominio semántico si solo se han aplicado códigos del mismo dominio semántico, independientemente de qué código dentro del dominio se haya aplicado.
El valor de alpha binario global siempre será 1 cuando se trabaje con citas predefinidas, ya que todos los segmentos codificados son los mismos.
cu-alpha
Los coeficientes cu-alpha/Cu-alpha solo pueden utilizarse en combinación con dominios semánticos. ¡No pueden utilizarse para probar el acuerdo/desacuerdo de códigos individuales!
Otra opción es probar si distintos codificadores fueron capaces de distinguir entre los códigos de un dominio semántico. Por ejemplo, si tiene un dominio semántico llamado "tipo de emociones" con los subcódigos:
- emociones::satisfacción
- emociones::entusiasmo
- emociones::vergüenza
- emociones::alivio
El coeficiente indica si los codificadores fueron capaces de distinguir de manera fiable entre, por ejemplo, "satisfacción" y "entusiasmo", o entre "vergüenza" y "alivio". El cu-alpha proporciona un valor para el rendimiento global del dominio semántico, pero no indica cuál de los subcódigos puede ser problemático. Para ello es necesario examinar las citas y determinar dónde se produce la confusión.
El coeficiente cu-alpha solo puede calcularse si los códigos de un dominio semántico se han aplicado de manera mutuamente excluyente. Esto significa que solo se aplica uno de los subcódigos por dominio a una cita determinada. Consulte también Requisitos para la codificación.
Cu-alpha
Cu-alpha es el coeficiente global para todos los cu-alphas. Tiene en cuenta que es posible aplicar códigos de múltiples dominios semánticos a las mismas citas o a citas superpuestas. Consulte codificación multivaluada. Por lo tanto, Cu-alpha no es simplemente el promedio de todos los cu-alphas.
Si los códigos de un dominio semántico "A" se han aplicado a segmentos de datos que también están codificados con códigos de un dominio semántico "B", esto no afecta al coeficiente cu-alpha de ninguno de los dos dominios, pero sí afecta al coeficiente Cu-alpha global.
El coeficiente Cu-alpha puede interpretarse como indicador del grado en que los codificadores coinciden en la presencia o ausencia de los dominios semánticos en el análisis. Formulado como pregunta: ¿pudieron los codificadores identificar de manera fiable que los segmentos de datos pertenecen a un dominio semántico específico, o los distintos codificadores aplicaron códigos de otros dominios semánticos?
En el cálculo tanto del coeficiente cu-alpha como del Cu-alpha, solo se incluyen en el análisis los segmentos de datos codificados.
Cálculo del alpha de Krippendorff
Para una explicación matemática completa sobre cómo se calculan los coeficientes alpha, consulte el Apéndice ICA.
La fórmula básica para todos los coeficientes alpha de Krippendorff es la siguiente:
alpha = 1 - desacuerdo observado (Do) / desacuerdo esperado (De)

donde "De" es el desacuerdo esperado por azar.
α = 1 indica fiabilidad perfecta. α = 0 indica ausencia de fiabilidad. Las unidades y los valores asignados a ellas no están relacionados estadísticamente. α < 0 cuando los desacuerdos son sistemáticos y superan lo que cabría esperar por azar.
Cuando los codificadores no prestan atención al texto, es decir, aplican los códigos de manera arbitraria, su codificación no guarda relación con el contenido del texto, y el desacuerdo observado es 1. En otras palabras, el desacuerdo observado (Do) es igual al máximo desacuerdo esperado (De), que es 1. Si introducimos esto en la fórmula, obtenemos:
α = 1 – 1/1 = 0,000.
Si, por el contrario, el acuerdo es perfecto, es decir, el desacuerdo observado (Do) = 0, entonces:
α = 1 – 0 / desacuerdo esperado = 1,000.
Para comprender mejor la relación entre el acuerdo real, el observado y el esperado, examinemos la siguiente tabla de contingencia:
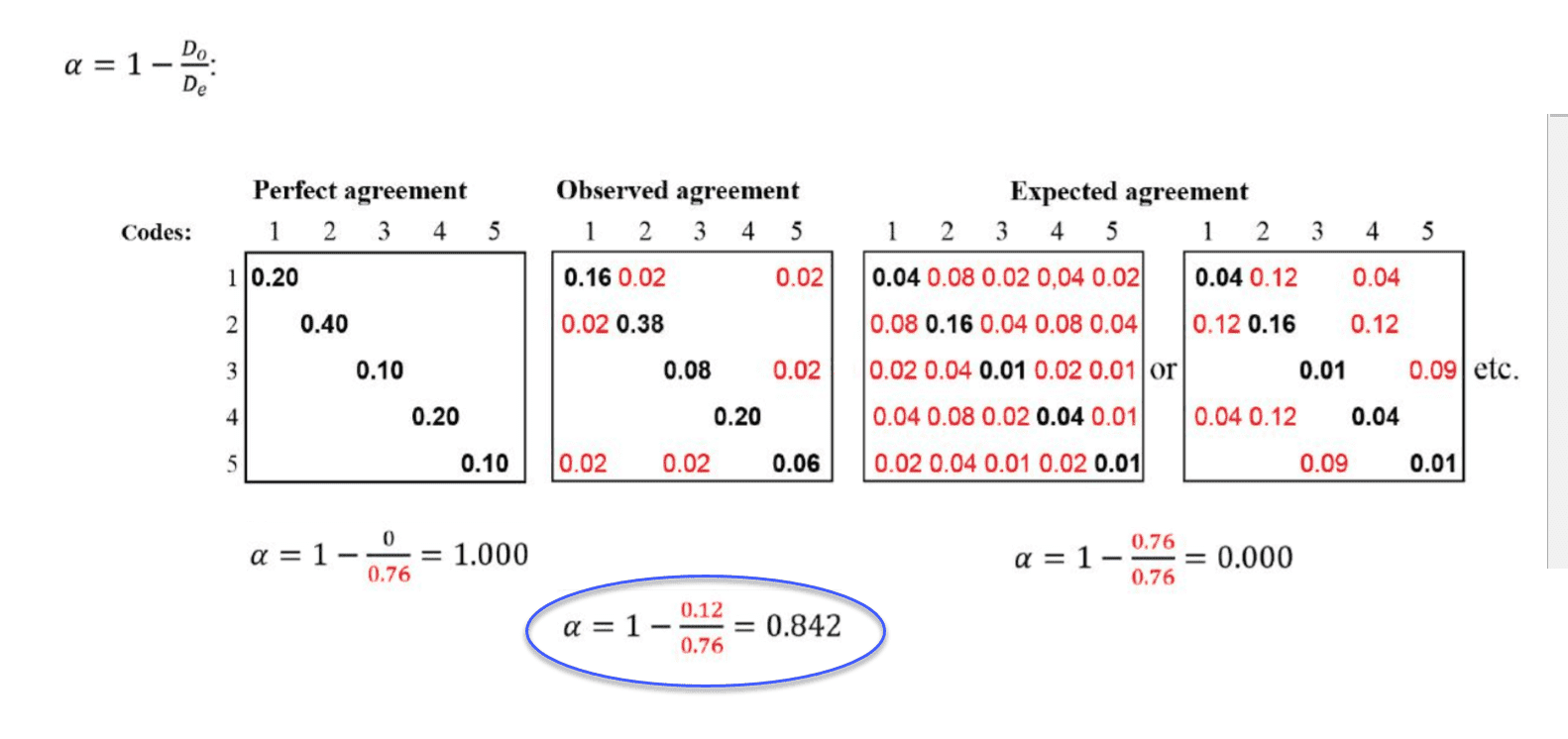
En el ejemplo anterior, las tablas representan un dominio semántico con cinco códigos. Las matrices de acuerdo/desacuerdo perfecto y esperado sirven como referencia de lo que podría haber ocurrido si el acuerdo hubiera sido perfecto o si los codificadores hubieran aplicado los códigos de manera aleatoria. Hay dos matrices de acuerdo/desacuerdo esperado, lo que indica que estadísticamente existen muchas posibilidades para una atribución aleatoria de los códigos.
Los números en negro muestran el acuerdo; los números en rojo, el desacuerdo.
En la tabla de contingencia del acuerdo observado, se puede ver que los codificadores coinciden en la aplicación del código 4. No hay números en rojo, es decir, no hay desacuerdo.
Hay cierto desacuerdo respecto a la aplicación del código 2. El acuerdo es del 38%. En el 2% de los casos se aplicó el código 1 en lugar del código 2.
Hay algo más de confusión en cuanto a la aplicación del código 5. Los codificadores también aplicaron el código 1 y el código 3.
Si esto fuera un ejemplo real, habría que revisar las definiciones de los códigos 5 y 2 y reflexionar sobre por qué los codificadores tuvieron dificultades para aplicarlos de manera fiable. Sin embargo, el coeficiente es aceptable. Consulte Reglas de decisión. No es necesario repetir la prueba.
Referencias
Banerjee, M., Capozzoli, M., McSweeney, L., Sinha, D. (1999). Beyond kappa: A review of interrater agreement measures. The Canadian Journal of Statistics, Vol. 27 (1), 3-23.
Cohen, Jacob (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement. 20 (1): 37–46. doi:10.1177/001316446002000104.
Holsti, O. R. (1969). Content analysis for the social sciences and humanities, Reading, MA: Addison-Wesley.
Krippendorff, Klaus (2004/2012/2018). Content Analysis: An Introduction to Its Methodology. 2ed /3rd /4th edition. Thousand Oaks, CA: Sage.
Zwick, Rebecca (1988). Another look at interrater agreement. Psychological Bulletin, 103, 347-387.
Xie, Q. (2013). Agree or disagree? A demonstration of an alternative statistic to Cohen's kappa for measuring the extent and reliability of agreement between observer. In Proceedings of the Federal Committee on Statistical Methodology Research Conference, The Council of Professional Associations on Federal Statistics, Washington, DC, USA, 2013.