
Intentional AI Coding
With this new AI-based coding tool, we're giving you more control, more transparency, and better results. Simply input your research goals, and let ATLAS.ti code your documents with the answers you need.
Intentional AI Coding is an improved version of our groundbreaking AI Coding tool, offering better results tailored to your research questions, more transparency, and it can even help you find pertinent questions to ask. As with AI Coding, you can review and refine the codes that are generated to suit your research, leaving you, the researcher, in control.
Please note that Intentional AI Coding is a beta feature. You are welcome to use it freely, and we welcome your feedback on all aspects of it.
You can access Intentional AI Coding via the Search & Code ribbon, in the Analyze section of the document and document manager toolbars, or in the Analysis section in the document or document group context menus.
Quick Overview
- The first step is selecting the documents or document groups you want ATLAS.ti to code for you. If you invoked Intentional AI Coding on a document or set of documents, this step is skipped.
- Next, ATLAS.ti asks for your intention. Write your research question(s) or hypothesis here. Feel free to add some context, as this will help the AI make sense of the data.
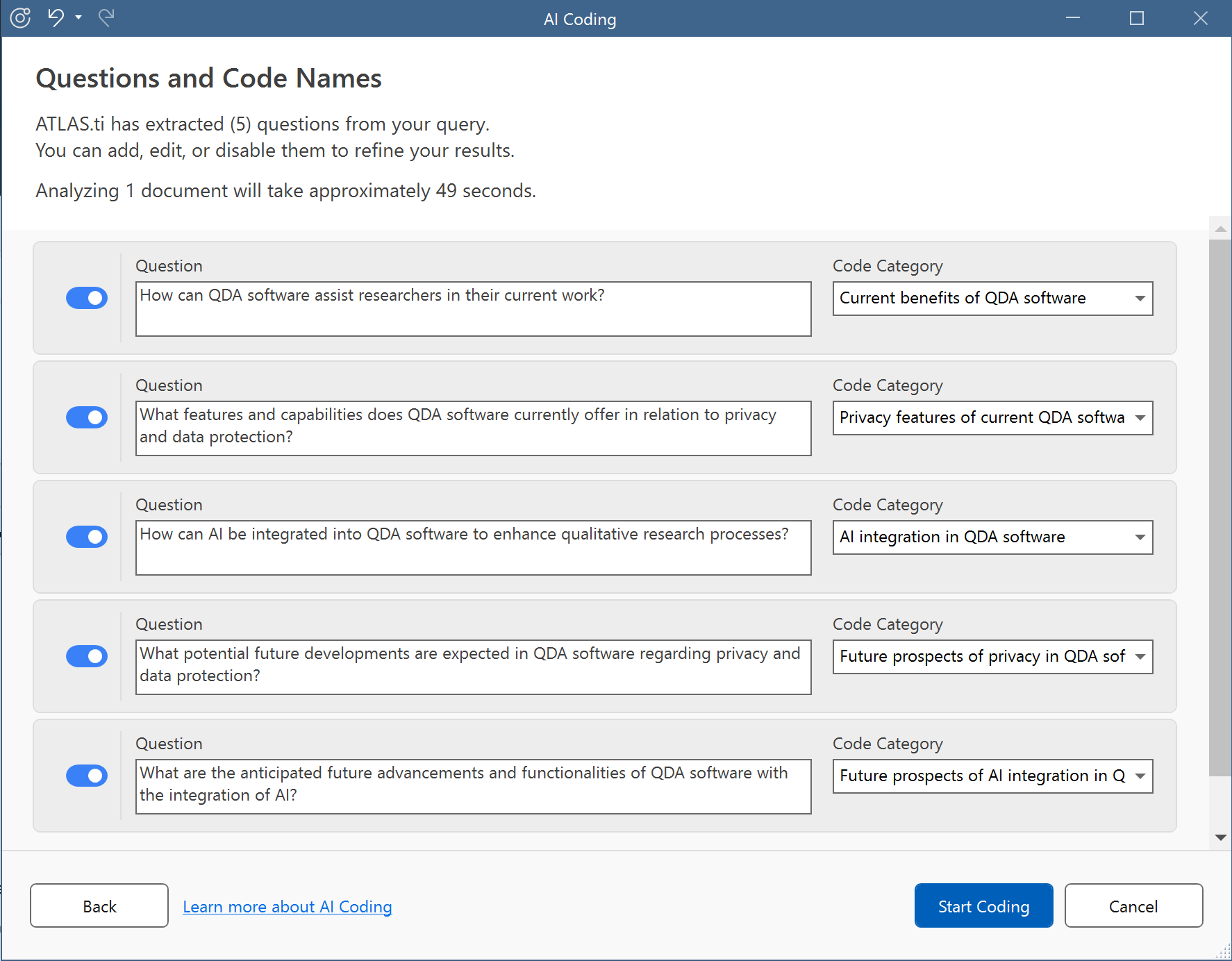
- In the next step, ATLAS.ti will generate concrete questions from your intention, along with pertinent code category names. Here, you can review and edit the questions and code category names, you can disable questions you're not interested in, and you can even add your own.
- After clicking "Start Coding," ATLAS.ti will go through your documents and collect coding suggestions. This may take some minutes. You can continue working in ATLAS.ti while this process is running, but take care not to edit the documents that are under AI analysis, as that will make the results inapplicable.
- When you're satisfied, click "Apply", and ATLAS.ti will apply the coding and show you a summary. You can close this window now; the coding is done.
Intentional AI Coding will upload your intent, your questions, chosen category code names, and your document content to ATLAS.ti and OpenAI servers. We will never upload your data without your explicit consent. If you wish to proceed, toggle the checkbox where you acknowledge that you agree to our EULA and Privacy Policy. OpenAI will NOT use ATLAS.ti user data to train OpenAI’s models.
How to get the Best Out of Intentional AI Coding
It’s best to submit documents that belong together thematically in the same round of Intentional AI Coding. This will improve coding quality and enable ATLAS.ti to ignore repeating patterns across documents, such as interview questions.
Intentional AI Coding works per paragraph. For best results, interview questions or participant names in transcripts should be on their own paragraph, and the paragraph structure of a document should be well-defined. When editing your document, use the numbers on the left margin to determine separation between paragraphs.
PDF documents do not contain paragraphs, even if they look like they do, so results from PDF documents will likely be poor.
Intentional AI Coding skips very short paragraphs.
Intentional AI Coding only looks at the plain text of your documents. Existing codes, quotations, images, and formatting have no bearing on its results.
AI Coding In Depth
Intentional AI Coding works with the GPT family of large language models. These models are based on vast amounts of different texts and additional training by human researchers, enabling them to be used in a general-purpose way.
We at ATLAS.ti offer easy access to these capable models with our AI Coding feature without the need to understand and navigate the technical details and limitations. ATLAS.ti automatically splits your text into chunks that are handled by the AI and passes them to the GPT models for repeated analysis. The results of the analysis are algorithmically combined to offer the best mix of codes covering different topics without producing an overwhelming amount of codes.
Here is an in-depth view on these steps:
In the first step, your provided intent is analyzed by AI, and questions are identified, along with a code category name based on the question. The user can review and edit both the questions and the code categories.
Next, the documents are segmented. Large language models are sensitive to the surrounding text as they have a window of attention, also called the context. Choosing the right context is key in working with a large language model. A short context can mean that not a lot information can be processed, because some words or even sentences only make sense in a larger context. Choosing a context that is too large overflows the model with information and makes it harder for code-extraction algorithms to find meaningful codes. ATLAS.ti choses contexts that are no less than 100 characters long, but breaks at natural paragraphs boundaries. We found that these confines have a positive impact on coding quality while leaving out most headings and titles which are of less importance to qualitative researchers. As a further step to reduce noise in the analysed data, ATLAS.ti removes paragraphs from analysis that have more than one occurrence, as these are likely recurring phrases from interviews or speaker names.
The documents are then analyzed segment by segment. In practice, this most often means paragraph by paragraph. Each question is applied to every segment. If it applies and yields a sensible answer, this answer is shortened into a code, and the code applied as a proposed coding to the segment. The code is grouped under the question's code category.
ATLAS.ti presents all proposed codings to the user before applying them.
Keep in mind that, while it is generally beneficial that the GPT models were trained on vast amounts of text, this may in some situations result in incorrect output that does not accurately reflect real people, places, or facts. In some cases, GPT models may encode social biases such as stereotypes or negative sentiment towards certain groups. You should evaluate the accuracy of any output as appropriate for your use case.